实现一个函数判断数据类型
function getType(obj) {
if (obj === null) return String(obj);
return typeof obj === 'object'
? Object.prototype.toString.call(obj).replace('[object ', '').replace(']', '').toLowerCase()
: typeof obj;
}
// 调用
getType(null); // -> null
getType(undefined); // -> undefined
getType({}); // -> object
getType([]); // -> array
getType(123); // -> number
getType(true); // -> boolean
getType('123'); // -> string
getType(/123/); // -> regexp
getType(new Date()); // -> date字符串查找
请使用最基本的遍历来实现判断字符串 a 是否被包含在字符串 b 中,并返回第一次出现的位置(找不到返回 -1)。
a='34';b='1234567'; // 返回 2
a='35';b='1234567'; // 返回 -1
a='355';b='12354355'; // 返回 5
isContain(a,b);function isContain(a, b) {
for (let i in b) {
if (a[0] === b[i]) {
let tmp = true;
for (let j in a) {
if (a[j] !== b[~~i + ~~j]) {
tmp = false;
}
}
if (tmp) {
return i;
}
}
}
return -1;
}实现千位分隔符
// 保留三位小数
parseToMoney(1234.56); // return '1,234.56'
parseToMoney(123456789); // return '123,456,789'
parseToMoney(1087654.321); // return '1,087,654.321'function parseToMoney(num) {
num = parseFloat(num.toFixed(3));
let [integer, decimal] = String.prototype.split.call(num, '.');
integer = integer.replace(/\d(?=(\d{3})+$)/g, '$&,');
return integer + '.' + (decimal ? decimal : '');
}实现 (5).add(3).minus(2) 功能
例: 5 + 3 - 2,结果为 6
Number.prototype.add = function(n) {
return this.valueOf() + n;
};
Number.prototype.minus = function(n) {
return this.valueOf() - n;
};实现add(1)(2) =3
// 题意的答案
const add = (num1) => (num2)=> num2 + num1;
// 整了一个加强版 可以无限链式调用 add(1)(2)(3)(4)(5)....
function add(x) {
// 存储和
let sum = x;
// 函数调用会相加,然后每次都会返回这个函数本身
let tmp = function (y) {
sum = sum + y;
return tmp;
};
// 对象的toString必须是一个方法 在方法中返回了这个和
tmp.toString = () => sum
return tmp;
}
alert(add(1)(2)(3)(4)(5))
无限链式调用实现的关键在于 对象的 toString 方法 : 每个对象都有一个 toString() 方法,当该对象被表示为一个文本值时,或者一个对象以预期的字符串方式引用时自动调用。
也就是我在调用很多次后,他们的结果会存在add函数中的sum变量上,当我alert的时候 add会自动调用 toString方法 打印出 sum, 也就是最终的结果
验证是否是邮箱
function isEmail(email) {
var regx = /^([a-zA-Z0-9_\-])[email protected]([a-zA-Z0-9_\-])+(\.[a-zA-Z0-9_\-])+$/;
return regx.test(email);
}创建10个标签,点击的时候弹出来对应的序号
var a
for(let i=0;i<10;i++){
a=document.createElement('a')
a.innerHTML=i+'
'
a.addEventListener('click',function(e){
console.log(this) //this为当前点击的
e.preventDefault() //如果调用这个方法,默认事件行为将不再触发。
//例如,在执行这个方法后,如果点击一个链接(a标签),浏览器不会跳转到新的 URL 去了。我们可以用 event.isDefaultPrevented() 来确定这个方法是否(在那个事件对象上)被调用过了。
alert(i)
})
const d=document.querySelector('div')
d.appendChild(a) //append向一个已存在的元素追加该元素。
}查找数组公共前缀(美团)
题目描述
编写一个函数来查找字符串数组中的最长公共前缀。
如果不存在公共前缀,返回空字符串 ""。
示例 1:
输入:strs = ["flower","flow","flight"]
输出:"fl"
示例 2:
输入:strs = ["dog","racecar","car"]
输出:""
解释:输入不存在公共前缀。答案
const longestCommonPrefix = function (strs) {
const str = strs[0];
let index = 0;
while (index < str.length) {
const strCur = str.slice(0, index + 1);
for (let i = 0; i < strs.length; i++) {
if (!strs[i] || !strs[i].startsWith(strCur)) {
return str.slice(0, index);
}
}
index++;
}
return str;
};参考:前端手写面试题详细解答
手写常见排序

冒泡排序
冒泡排序的原理如下,从第一个元素开始,把当前元素和下一个索引元素进行比较。如果当前元素大,那么就交换位置,重复操作直到比较到最后一个元素,那么此时最后一个元素就是该数组中最大的数。下一轮重复以上操作,但是此时最后一个元素已经是最大数了,所以不需要再比较最后一个元素,只需要比较到 length - 1 的位置。
function bubbleSort(list) {
var n = list.length;
if (!n) return [];
for (var i = 0; i < n; i++) {
// 注意这里需要 n - i - 1
for (var j = 0; j < n - i - 1; j++) {
if (list[j] > list[j + 1]) {
var temp = list[j + 1];
list[j + 1] = list[j];
list[j] = temp;
}
}
}
return list;
}快速排序
快排的原理如下。随机选取一个数组中的值作为基准值,从左至右取值与基准值对比大小。比基准值小的放数组左边,大的放右边,对比完成后将基准值和第一个比基准值大的值交换位置。然后将数组以基准值的位置分为两部分,继续递归以上操作
ffunction quickSort(arr) {
if (arr.length<=1){
return arr;
}
var baseIndex = Math.floor(arr.length/2);//向下取整,选取基准点
var base = arr.splice(baseIndex,1)[0];//取出基准点的值,
// splice 通过删除或替换现有元素或者原地添加新的元素来修改数组,并以数组形式返回被修改的内容。此方法会改变原数组。
// slice方法返回一个新的数组对象,不会更改原数组
//这里不能直接base=arr[baseIndex],因为base代表的每次都删除的那个数
var left=[];
var right=[];
for (var i = 0; i选择排序
function selectSort(arr) {
// 缓存数组长度
const len = arr.length;
// 定义 minIndex,缓存当前区间最小值的索引,注意是索引
let minIndex;
// i 是当前排序区间的起点
for (let i = 0; i < len - 1; i++) {
// 初始化 minIndex 为当前区间第一个元素
minIndex = i;
// i、j分别定义当前区间的上下界,i是左边界,j是右边界
for (let j = i; j < len; j++) {
// 若 j 处的数据项比当前最小值还要小,则更新最小值索引为 j
if (arr[j] < arr[minIndex]) {
minIndex = j;
}
}
// 如果 minIndex 对应元素不是目前的头部元素,则交换两者
if (minIndex !== i) {
[arr[i], arr[minIndex]] = [arr[minIndex], arr[i]];
}
}
return arr;
}
// console.log(selectSort([3, 6, 2, 4, 1]));插入排序
function insertSort(arr) {
for (let i = 1; i < arr.length; i++) {
let j = i;
let target = arr[j];
while (j > 0 && arr[j - 1] > target) {
arr[j] = arr[j - 1];
j--;
}
arr[j] = target;
}
return arr;
}
// console.log(insertSort([3, 6, 2, 4, 1]));递归反转链表
// node节点
class Node {
constructor(element,next) {
this.element = element
this.next = next
}
}
class LinkedList {
constructor() {
this.head = null // 默认应该指向第一个节点
this.size = 0 // 通过这个长度可以遍历这个链表
}
// 增加O(n)
add(index,element) {
if(arguments.length === 1) {
// 向末尾添加
element = index // 当前元素等于传递的第一项
index = this.size // 索引指向最后一个元素
}
if(index < 0 || index > this.size) {
throw new Error('添加的索引不正常')
}
if(index === 0) {
// 直接找到头部 把头部改掉 性能更好
let head = this.head
this.head = new Node(element,head)
} else {
// 获取当前头指针
let current = this.head
// 不停遍历 直到找到最后一项 添加的索引是1就找到第0个的next赋值
for (let i = 0; i < index-1; i++) { // 找到它的前一个
current = current.next
}
// 让创建的元素指向上一个元素的下一个
// 看图理解next层级 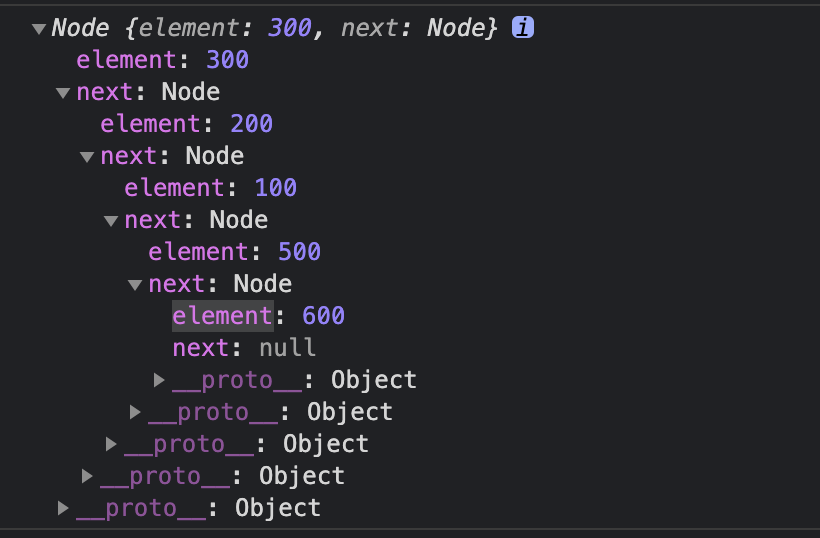
current.next = new Node(element,current.next) // 让当前元素指向下一个元素的next
}
this.size++;
}
// 删除O(n)
remove(index) {
if(index < 0 || index >= this.size) {
throw new Error('删除的索引不正常')
}
this.size--
if(index === 0) {
let head = this.head
this.head = this.head.next // 移动指针位置
return head // 返回删除的元素
}else {
let current = this.head
for (let i = 0; i < index-1; i++) { // index-1找到它的前一个
current = current.next
}
let returnVal = current.next // 返回删除的元素
// 找到待删除的指针的上一个 current.next.next
// 如删除200, 100=>200=>300 找到200的上一个100的next的next为300,把300赋值给100的next即可
current.next = current.next.next
return returnVal
}
}
// 查找O(n)
get(index) {
if(index < 0 || index >= this.size) {
throw new Error('查找的索引不正常')
}
let current = this.head
for (let i = 0; i < index; i++) {
current = current.next
}
return current
}
reverse() {
const reverse = head=>{
if(head == null || head.next == null) {
return head
}
let newHead = reverse(head.next)
// 从这个链表的最后一个开始反转,让当前下一个元素的next指向自己,自己指向null
// 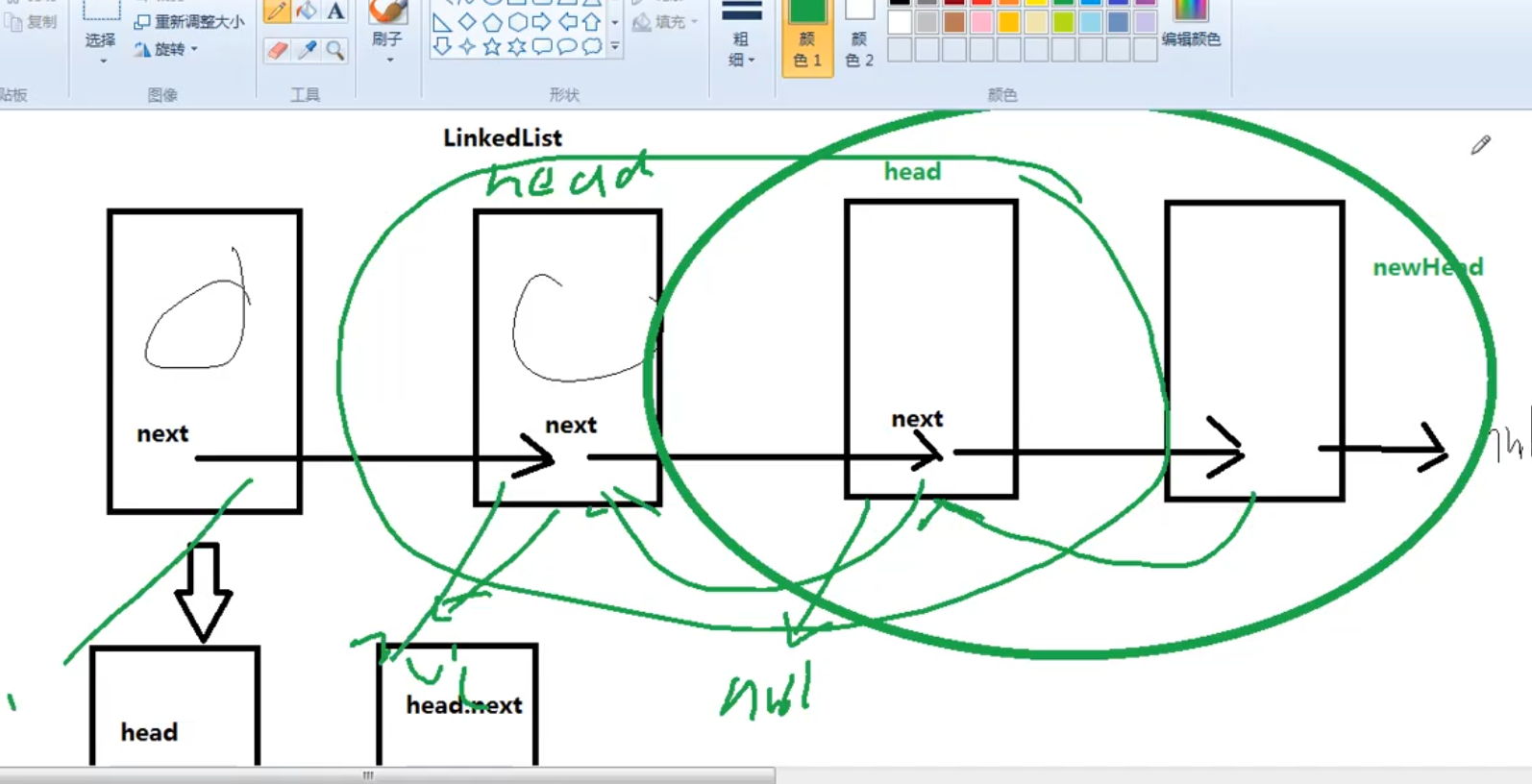
// 刚开始反转的是最后两个
head.next.next = head
head.next = null
return newHead
}
return reverse(this.head)
}
}
let ll = new LinkedList()
ll.add(1)
ll.add(2)
ll.add(3)
ll.add(4)
// console.dir(ll,{depth: 1000})
console.log(ll.reverse())交换a,b的值,不能用临时变量
巧妙的利用两个数的和、差:
a = a + b
b = a - b
a = a - b
实现instanceOf
// 模拟 instanceof
function instance_of(L, R) {
//L 表示左表达式,R 表示右表达式
var O = R.prototype; // 取 R 的显示原型
L = L.__proto__; // 取 L 的隐式原型
while (true) {
if (L === null) return false;
if (O === L)
// 这里重点:当 O 严格等于 L 时,返回 true
return true;
L = L.__proto__;
}
}
手写 Promise.then
then 方法返回一个新的 promise 实例,为了在 promise 状态发生变化时(resolve / reject 被调用时)再执行 then 里的函数,我们使用一个 callbacks 数组先把传给then的函数暂存起来,等状态改变时再调用。
那么,怎么保证后一个 **then** 里的方法在前一个 **then**(可能是异步)结束之后再执行呢? 我们可以将传给 then 的函数和新 promise 的 resolve 一起 push 到前一个 promise 的 callbacks 数组中,达到承前启后的效果:
- 承前:当前一个
promise完成后,调用其resolve变更状态,在这个resolve里会依次调用callbacks里的回调,这样就执行了then里的方法了 - 启后:上一步中,当
then里的方法执行完成后,返回一个结果,如果这个结果是个简单的值,就直接调用新promise的resolve,让其状态变更,这又会依次调用新promise的callbacks数组里的方法,循环往复。。如果返回的结果是个promise,则需要等它完成之后再触发新promise的resolve,所以可以在其结果的then里调用新promise的resolve
then(onFulfilled, onReject){
// 保存前一个promise的this
const self = this;
return new MyPromise((resolve, reject) => {
// 封装前一个promise成功时执行的函数
let fulfilled = () => {
try{
const result = onFulfilled(self.value); // 承前
return result instanceof MyPromise? result.then(resolve, reject) : resolve(result); //启后
}catch(err){
reject(err)
}
}
// 封装前一个promise失败时执行的函数
let rejected = () => {
try{
const result = onReject(self.reason);
return result instanceof MyPromise? result.then(resolve, reject) : reject(result);
}catch(err){
reject(err)
}
}
switch(self.status){
case PENDING:
self.onFulfilledCallbacks.push(fulfilled);
self.onRejectedCallbacks.push(rejected);
break;
case FULFILLED:
fulfilled();
break;
case REJECT:
rejected();
break;
}
})
}
注意:
- 连续多个
then里的回调方法是同步注册的,但注册到了不同的callbacks数组中,因为每次then都返回新的promise实例(参考上面的例子和图) - 注册完成后开始执行构造函数中的异步事件,异步完成之后依次调用
callbacks数组中提前注册的回调
实现Event(event bus)
event bus既是node中各个模块的基石,又是前端组件通信的依赖手段之一,同时涉及了订阅-发布设计模式,是非常重要的基础。
简单版:
class EventEmeitter {
constructor() {
this._events = this._events || new Map(); // 储存事件/回调键值对
this._maxListeners = this._maxListeners || 10; // 设立监听上限
}
}
// 触发名为type的事件
EventEmeitter.prototype.emit = function(type, ...args) {
let handler;
// 从储存事件键值对的this._events中获取对应事件回调函数
handler = this._events.get(type);
if (args.length > 0) {
handler.apply(this, args);
} else {
handler.call(this);
}
return true;
};
// 监听名为type的事件
EventEmeitter.prototype.addListener = function(type, fn) {
// 将type事件以及对应的fn函数放入this._events中储存
if (!this._events.get(type)) {
this._events.set(type, fn);
}
};
面试版:
class EventEmeitter {
constructor() {
this._events = this._events || new Map(); // 储存事件/回调键值对
this._maxListeners = this._maxListeners || 10; // 设立监听上限
}
}
// 触发名为type的事件
EventEmeitter.prototype.emit = function(type, ...args) {
let handler;
// 从储存事件键值对的this._events中获取对应事件回调函数
handler = this._events.get(type);
if (args.length > 0) {
handler.apply(this, args);
} else {
handler.call(this);
}
return true;
};
// 监听名为type的事件
EventEmeitter.prototype.addListener = function(type, fn) {
// 将type事件以及对应的fn函数放入this._events中储存
if (!this._events.get(type)) {
this._events.set(type, fn);
}
};
// 触发名为type的事件
EventEmeitter.prototype.emit = function(type, ...args) {
let handler;
handler = this._events.get(type);
if (Array.isArray(handler)) {
// 如果是一个数组说明有多个监听者,需要依次此触发里面的函数
for (let i = 0; i < handler.length; i++) {
if (args.length > 0) {
handler[i].apply(this, args);
} else {
handler[i].call(this);
}
}
} else {
// 单个函数的情况我们直接触发即可
if (args.length > 0) {
handler.apply(this, args);
} else {
handler.call(this);
}
}
return true;
};
// 监听名为type的事件
EventEmeitter.prototype.addListener = function(type, fn) {
const handler = this._events.get(type); // 获取对应事件名称的函数清单
if (!handler) {
this._events.set(type, fn);
} else if (handler && typeof handler === "function") {
// 如果handler是函数说明只有一个监听者
this._events.set(type, [handler, fn]); // 多个监听者我们需要用数组储存
} else {
handler.push(fn); // 已经有多个监听者,那么直接往数组里push函数即可
}
};
EventEmeitter.prototype.removeListener = function(type, fn) {
const handler = this._events.get(type); // 获取对应事件名称的函数清单
// 如果是函数,说明只被监听了一次
if (handler && typeof handler === "function") {
this._events.delete(type, fn);
} else {
let postion;
// 如果handler是数组,说明被监听多次要找到对应的函数
for (let i = 0; i < handler.length; i++) {
if (handler[i] === fn) {
postion = i;
} else {
postion = -1;
}
}
// 如果找到匹配的函数,从数组中清除
if (postion !== -1) {
// 找到数组对应的位置,直接清除此回调
handler.splice(postion, 1);
// 如果清除后只有一个函数,那么取消数组,以函数形式保存
if (handler.length === 1) {
this._events.set(type, handler[0]);
}
} else {
return this;
}
}
};
实现具体过程和思路见实现event
手写深度比较isEqual
思路:深度比较两个对象,就是要深度比较对象的每一个元素。=> 递归
递归退出条件:
- 被比较的是两个值类型变量,直接用“===”判断
- 被比较的两个变量之一为
null,直接判断另一个元素是否也为null
提前结束递推:
- 两个变量
keys数量不同 - 传入的两个参数是同一个变量
- 两个变量
- 递推工作:深度比较每一个
key
function isEqual(obj1, obj2){
//其中一个为值类型或null
if(!isObject(obj1) || !isObject(obj2)){
return obj1 === obj2;
}
//判断是否两个参数是同一个变量
if(obj1 === obj2){
return true;
}
//判断keys数是否相等
const obj1Keys = Object.keys(obj1);
const obj2Keys = Object.keys(obj2);
if(obj1Keys.length !== obj2Keys.length){
return false;
}
//深度比较每一个key
for(let key in obj1){
if(!isEqual(obj1[key], obj2[key])){
return false;
}
}
return true;
}实现字符串的repeat方法
输入字符串s,以及其重复的次数,输出重复的结果,例如输入abc,2,输出abcabc。
function repeat(s, n) {
return (new Array(n + 1)).join(s);
}
递归:
function repeat(s, n) {
return (n > 0) ? s.concat(repeat(s, --n)) : "";
}
深克隆(deepclone)
简单版:
const newObj = JSON.parse(JSON.stringify(oldObj));
局限性:
- 他无法实现对函数 、RegExp等特殊对象的克隆
- 会抛弃对象的constructor,所有的构造函数会指向Object
- 对象有循环引用,会报错
面试版:
/**
* deep clone
* @param {[type]} parent object 需要进行克隆的对象
* @return {[type]} 深克隆后的对象
*/
const clone = parent => {
// 判断类型
const isType = (obj, type) => {
if (typeof obj !== "object") return false;
const typeString = Object.prototype.toString.call(obj);
let flag;
switch (type) {
case "Array":
flag = typeString === "[object Array]";
break;
case "Date":
flag = typeString === "[object Date]";
break;
case "RegExp":
flag = typeString === "[object RegExp]";
break;
default:
flag = false;
}
return flag;
};
// 处理正则
const getRegExp = re => {
var flags = "";
if (re.global) flags += "g";
if (re.ignoreCase) flags += "i";
if (re.multiline) flags += "m";
return flags;
};
// 维护两个储存循环引用的数组
const parents = [];
const children = [];
const _clone = parent => {
if (parent === null) return null;
if (typeof parent !== "object") return parent;
let child, proto;
if (isType(parent, "Array")) {
// 对数组做特殊处理
child = [];
} else if (isType(parent, "RegExp")) {
// 对正则对象做特殊处理
child = new RegExp(parent.source, getRegExp(parent));
if (parent.lastIndex) child.lastIndex = parent.lastIndex;
} else if (isType(parent, "Date")) {
// 对Date对象做特殊处理
child = new Date(parent.getTime());
} else {
// 处理对象原型
proto = Object.getPrototypeOf(parent);
// 利用Object.create切断原型链
child = Object.create(proto);
}
// 处理循环引用
const index = parents.indexOf(parent);
if (index != -1) {
// 如果父数组存在本对象,说明之前已经被引用过,直接返回此对象
return children[index];
}
parents.push(parent);
children.push(child);
for (let i in parent) {
// 递归
child[i] = _clone(parent[i]);
}
return child;
};
return _clone(parent);
};
局限性:
- 一些特殊情况没有处理: 例如Buffer对象、Promise、Set、Map
- 另外对于确保没有循环引用的对象,我们可以省去对循环引用的特殊处理,因为这很消耗时间
原理详解实现深克隆
类数组转化为数组的方法
const arrayLike=document.querySelectorAll('div')
// 1.扩展运算符
[...arrayLike]
// 2.Array.from
Array.from(arrayLike)
// 3.Array.prototype.slice
Array.prototype.slice.call(arrayLike)
// 4.Array.apply
Array.apply(null, arrayLike)
// 5.Array.prototype.concat
Array.prototype.concat.apply([], arrayLike)手写类型判断函数
function getType(value) {
// 判断数据是 null 的情况
if (value === null) {
return value + "";
}
// 判断数据是引用类型的情况
if (typeof value === "object") {
let valueClass = Object.prototype.toString.call(value),
type = valueClass.split(" ")[1].split("");
type.pop();
return type.join("").toLowerCase();
} else {
// 判断数据是基本数据类型的情况和函数的情况
return typeof value;
}
}
实现Node的require方法
require 基本原理
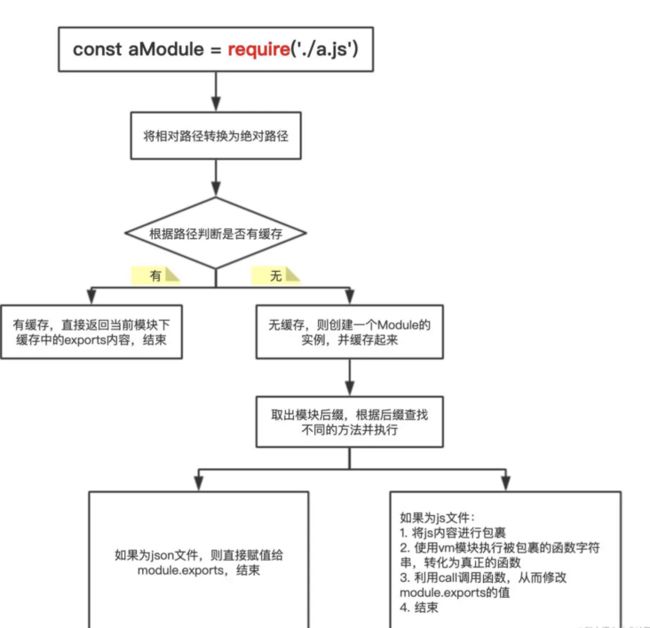
require 查找路径

require和module.exports干的事情并不复杂,我们先假设有一个全局对象{},初始情况下是空的,当你require某个文件时,就将这个文件拿出来执行,如果这个文件里面存在module.exports,当运行到这行代码时将module.exports的值加入这个对象,键为对应的文件名,最终这个对象就长这样:
{
"a.js": "hello world",
"b.js": function add(){},
"c.js": 2,
"d.js": { num: 2 }
}当你再次require某个文件时,如果这个对象里面有对应的值,就直接返回给你,如果没有就重复前面的步骤,执行目标文件,然后将它的module.exports加入这个全局对象,并返回给调用者。这个全局对象其实就是我们经常听说的缓存。所以require和module.exports并没有什么黑魔法,就只是运行并获取目标文件的值,然后加入缓存,用的时候拿出来用就行
手写实现一个require
const path = require('path'); // 路径操作
const fs = require('fs'); // 文件读取
const vm = require('vm'); // 文件执行
// node模块化的实现
// node中是自带模块化机制的,每个文件就是一个单独的模块,并且它遵循的是CommonJS规范,也就是使用require的方式导入模块,通过module.export的方式导出模块。
// node模块的运行机制也很简单,其实就是在每一个模块外层包裹了一层函数,有了函数的包裹就可以实现代码间的作用域隔离
// require加载模块
// require依赖node中的fs模块来加载模块文件,fs.readFile读取到的是一个字符串。
// 在javascrpt中我们可以通过eval或者new Function的方式来将一个字符串转换成js代码来运行。
// eval
// const name = 'poetry';
// const str = 'const a = 123; console.log(name)';
// eval(str); // poetry;
// new Function
// new Function接收的是一个要执行的字符串,返回的是一个新的函数,调用这个新的函数字符串就会执行了。如果这个函数需要传递参数,可以在new Function的时候依次传入参数,最后传入的是要执行的字符串。比如这里传入参数b,要执行的字符串str
// const b = 3;
// const str = 'let a = 1; return a + b';
// const fun = new Function('b', str);
// console.log(fun(b, str)); // 4
// 可以看到eval和Function实例化都可以用来执行javascript字符串,似乎他们都可以来实现require模块加载。不过在node中并没有选用他们来实现模块化,原因也很简单因为他们都有一个致命的问题,就是都容易被不属于他们的变量所影响。
// 如下str字符串中并没有定义a,但是确可以使用上面定义的a变量,这显然是不对的,在模块化机制中,str字符串应该具有自身独立的运行空间,自身不存在的变量是不可以直接使用的
// const a = 1;
// const str = 'console.log(a)';
// eval(str);
// const func = new Function(str);
// func();
// node存在一个vm虚拟环境的概念,用来运行额外的js文件,他可以保证javascript执行的独立性,不会被外部所影响
// vm 内置模块
// 虽然我们在外部定义了hello,但是str是一个独立的模块,并不在村hello变量,所以会直接报错。
// 引入vm模块, 不需要安装,node 自建模块
// const vm = require('vm');
// const hello = 'poetry';
// const str = 'console.log(hello)';
// wm.runInThisContext(str); // 报错
// 所以node执行javascript模块时可以采用vm来实现。就可以保证模块的独立性了
// 分析实现步骤
// 1.导入相关模块,创建一个Require方法。
// 2.抽离通过Module._load方法,用于加载模块。
// 3.Module.resolveFilename 根据相对路径,转换成绝对路径。
// 4.缓存模块 Module._cache,同一个模块不要重复加载,提升性能。
// 5.创建模块 id: 保存的内容是 exports = {}相当于this。
// 6.利用tryModuleLoad(module, filename) 尝试加载模块。
// 7.Module._extensions使用读取文件。
// 8.Module.wrap: 把读取到的js包裹一个函数。
// 9.将拿到的字符串使用runInThisContext运行字符串。
// 10.让字符串执行并将this改编成exports
// 定义导入类,参数为模块路径
function Require(modulePath) {
// 获取当前要加载的绝对路径
let absPathname = path.resolve(__dirname, modulePath);
// 自动给模块添加后缀名,实现省略后缀名加载模块,其实也就是如果文件没有后缀名的时候遍历一下所有的后缀名看一下文件是否存在
// 获取所有后缀名
const extNames = Object.keys(Module._extensions);
let index = 0;
// 存储原始文件路径
const oldPath = absPathname;
function findExt(absPathname) {
if (index === extNames.length) {
throw new Error('文件不存在');
}
try {
fs.accessSync(absPathname);
return absPathname;
} catch(e) {
const ext = extNames[index++];
findExt(oldPath + ext);
}
}
// 递归追加后缀名,判断文件是否存在
absPathname = findExt(absPathname);
// 从缓存中读取,如果存在,直接返回结果
if (Module._cache[absPathname]) {
return Module._cache[absPathname].exports;
}
// 创建模块,新建Module实例
const module = new Module(absPathname);
// 添加缓存
Module._cache[absPathname] = module;
// 加载当前模块
tryModuleLoad(module);
// 返回exports对象
return module.exports;
}
// Module的实现很简单,就是给模块创建一个exports对象,tryModuleLoad执行的时候将内容加入到exports中,id就是模块的绝对路径
// 定义模块, 添加文件id标识和exports属性
function Module(id) {
this.id = id;
// 读取到的文件内容会放在exports中
this.exports = {};
}
Module._cache = {};
// 我们给Module挂载静态属性wrapper,里面定义一下这个函数的字符串,wrapper是一个数组,数组的第一个元素就是函数的参数部分,其中有exports,module. Require,__dirname, __filename, 都是我们模块中常用的全局变量。注意这里传入的Require参数是我们自己定义的Require
// 第二个参数就是函数的结束部分。两部分都是字符串,使用的时候我们将他们包裹在模块的字符串外部就可以了
Module.wrapper = [
"(function(exports, module, Require, __dirname, __filename) {",
"})"
]
// _extensions用于针对不同的模块扩展名使用不同的加载方式,比如JSON和javascript加载方式肯定是不同的。JSON使用JSON.parse来运行。
// javascript使用vm.runInThisContext来运行,可以看到fs.readFileSync传入的是module.id也就是我们Module定义时候id存储的是模块的绝对路径,读取到的content是一个字符串,我们使用Module.wrapper来包裹一下就相当于在这个模块外部又包裹了一个函数,也就实现了私有作用域。
// 使用call来执行fn函数,第一个参数改变运行的this我们传入module.exports,后面的参数就是函数外面包裹参数exports, module, Require, __dirname, __filename
Module._extensions = {
'.js'(module) {
const content = fs.readFileSync(module.id, 'utf8');
const fnStr = Module.wrapper[0] + content + Module.wrapper[1];
const fn = vm.runInThisContext(fnStr);
fn.call(module.exports, module.exports, module, Require,__filename,__dirname);
},
'.json'(module) {
const json = fs.readFileSync(module.id, 'utf8');
module.exports = JSON.parse(json); // 把文件的结果放在exports属性上
}
}
// tryModuleLoad函数接收的是模块对象,通过path.extname来获取模块的后缀名,然后使用Module._extensions来加载模块
// 定义模块加载方法
function tryModuleLoad(module) {
// 获取扩展名
const extension = path.extname(module.id);
// 通过后缀加载当前模块
Module._extensions[extension](module);
}
// 至此Require加载机制我们基本就写完了,我们来重新看一下。Require加载模块的时候传入模块名称,在Require方法中使用path.resolve(__dirname, modulePath)获取到文件的绝对路径。然后通过new Module实例化的方式创建module对象,将模块的绝对路径存储在module的id属性中,在module中创建exports属性为一个json对象
// 使用tryModuleLoad方法去加载模块,tryModuleLoad中使用path.extname获取到文件的扩展名,然后根据扩展名来执行对应的模块加载机制
// 最终将加载到的模块挂载module.exports中。tryModuleLoad执行完毕之后module.exports已经存在了,直接返回就可以了
// 给模块添加缓存
// 添加缓存也比较简单,就是文件加载的时候将文件放入缓存中,再去加载模块时先看缓存中是否存在,如果存在直接使用,如果不存在再去重新,加载之后再放入缓存
// 测试
let json = Require('./test.json');
let test2 = Require('./test2.js');
console.log(json);
console.log(test2);实现数组的map方法
Array.prototype._map = function(fn) {
if (typeof fn !== "function") {
throw Error('参数必须是一个函数');
}
const res = [];
for (let i = 0, len = this.length; i < len; i++) {
res.push(fn(this[i]));
}
return res;
}