CVPR2021 | Transformer用于End-to-End视频实例分割
论文:End-to-End Video Instance Segmentation with Transformers
获取:在CV技术指南后台回复关键字“0005”获取该论文。
代码:https://git.io/VisTR
点个关注,专注于计算机视觉技术文章。
前言:
视频实例分割(VIS)是一项需要同时对视频中感兴趣的对象进行分类、分割和跟踪的任务。本文提出了一种新的基于 Transformers 的视频实例分割框架 VisTR,它将 VIS 任务视为直接的端到端并行序列解码/预测问题。
给定一个由多个图像帧组成的视频片段作为输入,VisTR 直接输出视频中每个实例的掩码序列。它的核心是一种新的、有效的实例序列匹配和切分策略,在序列层面对实例进行整体监控和切分。VisTR从相似性学习的角度对实例进行划分和跟踪,大大简化了整个过程,与现有方法有很大不同。
VisTR 在现有的 VIS 模型中速度最快,效果最好的是在 YouTubeVIS 数据集上使用单一模型的方法。这是研究人员首次展示了一种基于 Transformer 的更简单、更快的视频实例分割框架,实现了具有竞争力的准确性。
出发点
SOTA方法通常会开发复杂的pipeline来解决此任务。 Top-down的方法遵循tracking-by-detection范式,严重依赖图像级实例分割模型和复杂的人工设计规则来关联实例。 Bottom-up的方法通过对学习的像素嵌入进行聚类来分离对象实例。由于严重依赖密集预测质量,这些方法通常需要多个步骤来迭代地生成掩码,这使得它们很慢。因此,非常需要一个简单的、端到端可训练的 VIS 框架。
在这里,我们更深入地了解视频实例分割任务。 视频帧包含比单个图像更丰富的信息,例如运动模式和实例的时间一致性,为实例分割和分类提供有用的线索。 同时,更好地学习实例特征可以帮助跟踪实例。 本质上,实例分割和实例跟踪都与相似性学习有关:实例分割是学习像素级的相似性,实例跟踪是学习实例之间的相似性。 因此,在单个框架中解决这两个子任务并相互受益是很自然的。 在这里,我们的目标是开发这样一个端到端的 VIS 框架。该框架需要简单,在没有花里胡哨的情况下实现强大的性能。
主要贡献
-
我们提出了一种基于 Transformers 的新视频实例分割框架,称为 VisTR,它将 VIS 任务视为直接的端到端并行序列解码/预测问题。该框架与现有方法有很大不同,大大简化了整个流程。
-
VisTR从相似度学习的新角度解决了VIS。实例分割是学习像素级的相似性,实例跟踪是学习实例之间的相似性。因此,在相同的实例分割框架中无缝自然地实现了实例跟踪。
-
VisTR 成功的关键是实例序列匹配和分割的新策略,它是为我们的框架量身定制的。这种精心设计的策略使我们能够在序列级别作为一个整体来监督和分割实例。
-
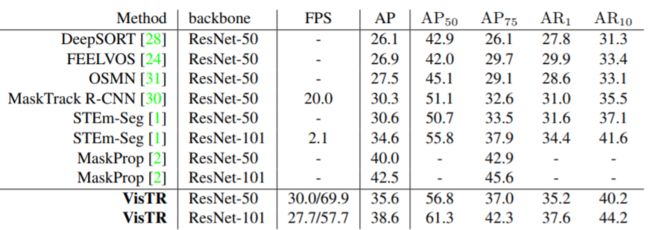
VisTR 在 YouTube-VIS 数据集上取得了强劲的成绩,在 57.7 FPS 的速度下实现了 38.6% 的 mask mAP,这是使用单一模型的方法中最好和最快的。
Methods
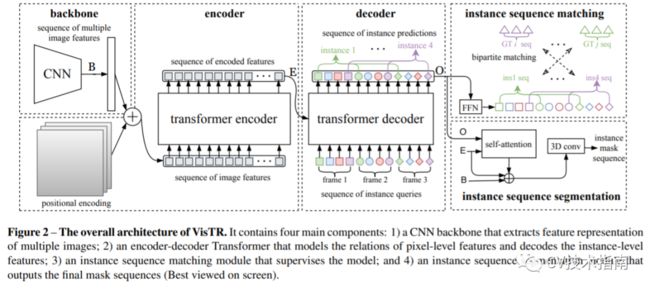
整个 VisTR 架构如图 2 所示。它包含四个主要组件:一个用于提取多个帧的紧凑特征表示的 CNN 主干,一个用于对像素级和实例级特征的相似性进行建模的编码器-解码器 Transformer,一个实例 用于监督模型的序列匹配模块,以及一个实例序列分割模块。
Transformer Encoder
Transformer 编码器用于对片段中所有像素级特征之间的相似性进行建模。 首先,对上述特征图应用 1×1 卷积,将维度从 C 减少到 d (d < C),从而产生新的特征图f1。
为了形成可以输入到 Transformer 编码器中的剪辑级特征序列,我们将 f1 的空间和时间维度展平为一维,从而得到大小为 d × (T·H·W) 的 2D 特征图。请注意,时间顺序始终与初始输入的顺序一致。每个编码器层都有一个标准架构,由一个多头自注意力模块和一个全连接前馈网络 (FFN) 组成。
Transformer Decoder
Transformer 解码器旨在解码可以表示每帧实例的顶部像素特征,称为实例级特征。受 DETR的启发,我们还引入了固定数量的输入嵌入来从像素特征中查询实例特征,称为实例查询。
假设模型每帧解码 n 个实例,那么对于 T 帧,实例查询数为 N = n · T。实例查询是模型学习的,与像素特征具有相同的维度。以编码器 E 的输出和 N 个实例查询 Q 作为输入,Transformer 解码器输出 N 个实例特征,在图 2 中用 O 表示。
整体预测遵循输入帧顺序,不同图像的实例预测顺序为相同的。因此,可以通过将相应索引的项直接链接来实现对不同帧中实例的跟踪。
Instance Sequence Matching
解码器输出的固定数量的预测序列是乱序的,每帧包含n个实例序列。本文与DETR相同,使用匈牙利算法进行匹配。
虽然是实例分割,但是在目标检测中需要用到bounding box,方便组合优化计算。通过FFN计算归一化的bounding box中心、宽度和高度,即全连接。
通过softmax计算bounding box的label。最终得到n×T个边界框。使用上面得到标签概率分布和边界框来匹配实例序列和gournd truth。
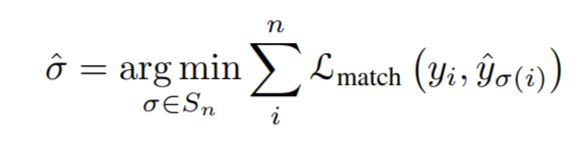
最后计算Hungarian算法的loss,考虑标签的概率分布和bounding box的位置。损失基本遵循DETR的设计,使用L1损失和IOU损失。以下公式是训练的损失。它由标签损失、边界框和实例序列组成。

Conclusion
下图展示了 VisTR 在 YouTube VIS 验证数据集上的可视化。每行包含从同一视频中采样的图像。VisTR 可以很好地跟踪和分割具有挑战性的实例,例如:(a) 重叠实例,(b) 实例之间的相对位置变化,© 由相同类型的相似实例引起的混淆,以及 (d) 不同姿势的实例。

本文来源于公众号 CV技术指南 的论文分享系列。
欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。
在公众号中回复关键字 “技术总结” 可获取以下文章的汇总pdf。

其它文章
CV技术指南--精华文章汇总分类
计算机视觉中的自注意力
综述专栏 | 姿态估计综述
漫谈CUDA优化
为什么GEMM是深度学习的核心
使用深度神经网络为什么8位足够?
经典论文系列--胶囊网络:新的深度学习网络
经典论文系列 | 目标检测--CornerNet & 又名 anchor boxes的缺陷
如何看待人工智能的泡沫
使用Dice loss实现清晰的边界检测
PVT--无卷积密集预测的多功能backbone
CVPR2021 | 开放世界的目标检测
Siamese network总结
视觉目标检测和识别之过去,现在及可能
在做算法工程师的道路上,你掌握了什么概念或技术使你感觉自我提升突飞猛进?
计算机视觉专业术语总结(一)构建计算机视觉的知识体系
欠拟合与过拟合技术总结
归一化方法总结
论文创新的常见思路总结
CV方向的高效阅读英文文献方法总结
计算机视觉中的小样本学习综述
知识蒸馏的简要概述
优化OpenCV视频的读取速度
NMS总结
损失函数技术总结
注意力机制技术总结
特征金字塔技术总结
池化技术总结
数据增强方法总结
CNN结构演变总结(一)经典模型
CNN结构演变总结(二)轻量化模型
CNN结构演变总结(三)设计原则
如何看待计算机视觉未来的走向
CNN可视化技术总结(一)特征图可视化
CNN可视化技术总结(二)卷积核可视化
CNN可视化技术总结(三)类可视化
CNN可视化技术总结(四)可视化工具与项目