ICCV 华人团队提出会创作的Paint Transformer,网友反驳:这也要用神经网络?
来源:新智元
【导读】神经网络相关论文逐渐变成 AI 领域的主流,但那些任务真的需要神经网络这个技术吗?最近ICCV上一篇文章在reddit上分享后引发热议,网友吐槽最多的就是:明明50行代码就能搞定,为什么要用神经网络?
神经网络是个出色的绘画家早已不是什么大新闻,它能把一副草图变成风景画,两幅不同风格的画之间进行风格迁移。

但这类工作都是端到端的,也就是说你并不知道神经网络究竟是怎么画出来这幅画的。
神经绘画(Neural Painting)应运而生,它指的是为给定的图像生成一系列笔画,并用神经网络对其进行非照片式(non-photorealistically)再现的过程。
虽然基于强化学习的智能体可以为这个任务逐步生成一个笔画序列,但是要训练一个稳定的智能体却不容易。
另一方面,笔划优化方法需要在较大的搜索空间内迭代搜索一组笔划参数,这种低效率的搜索很明显会限制了基于强化学习方法的泛化性和实用性。
ICCV 2021上一篇文章提出,将该任务描述为一个集合预测问题,并提出了一种新的基于Transformer的框架,使用前馈网络预测一组笔画的参数,文中起名为Paint Transformer。
通过这种方式,文中提出的模型可以并行地生成一组笔画,并近乎实时地获得最终的大小为512 * 512的画作。

教机器如何作画并不是算是一个全新的研究课题,传统方法通常设计启发式绘画策略,或者贪婪地选择一个笔划,一步一步地缩小与目标图像的差异。

但近年来随着神经网络中RNN和强化学习的兴起,传统的方法的泛化性能就相形见绌了。
文中提出的模型将神经绘画描述为一个渐进的笔划预测过程。
在每一步,可以并行预测多个笔划,以前馈方式最小化当前画布和目标图像之间的差异。
Paint Transformer由两个模块组成:笔划预测器和笔划渲染器。给定目标图像和中间画布图像,笔划预测器生成一组参数以确定当前笔划集合。
然后,笔划渲染器为Sr中的每个笔划生成笔划图像,并将其绘制到画布上,生成预测图像。
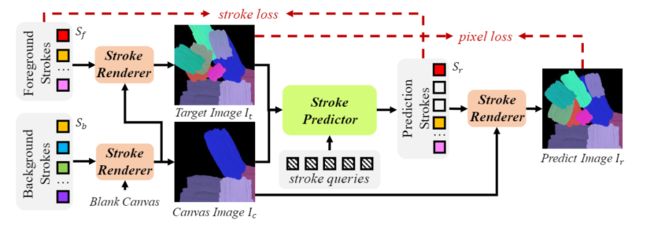
在Paint Transformer中,只有笔划预测器(Stroker Predictor)包含可训练的参数,而笔划渲染器(Stroker Renderer)是一个无参数且可微分的模块。
为了训练笔划预测器,又提出了一种利用随机合成笔划的新型自训练Pipeline。在训练期间的每次迭代中,首先随机抽取前景笔划集(foreground stroke set)和背景笔划集。
然后,我们使用笔划渲染器生成画布图像,将笔划渲染器作为输入,并通过将Sf渲染到Ic上生成目标图像。
最后笔划预测器可以预测笔划集Sr,生成以Sr和Ic为输入的预测图像Ir。
需要注意的是,用于监督训练的笔划是随机合成的,因此可以生成无限的训练数据,而不依赖任何现成的数据集。
笔画预测时主要考虑直线比划,可以用形状参数和颜色参数表示不同的直线。笔划的形状参数包括:中心点坐标x和y、高度h、宽度w和旋转角度θ。笔划的颜色参数包括RGB值表示为r、g和b。
自训练pipeline的主要优点是,可以同时最小化图像级和笔划级的地面真实值和预测之间的差异。损失函数主要由三部分构成,像素损失、笔划之间差异的测量以及笔划损失。
1、像素损失(pixel loss),神经绘画的直观目标是重建目标图像。因此,像素损失在图像级别上惩罚不精确的预测。

2、笔划距离(stroke distance),在笔划级别上,定义适当的度量标准以测量笔划间的差异是很重要的。

3、笔划损失(stroke loss),在训练期间,有效的真实笔划的数量是不同的。根据DETR模型,采用产生最小笔划水平匹配成本的笔划排列来计算最终损失,利用匈牙利算法计算最佳二部匹配。
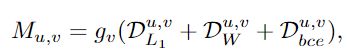
为了模仿人类画家,在推理过程中,研究人员设计了一种从粗到精的算法来在推理过程中生成绘画结果。给定一幅大小为H×W的真实图像,Paint Transformer按从粗到细的顺序在K尺度上运行。每种比例的绘画都取决于前一比例的结果。
目标图像和当前画布将被切割成几个不重叠的P×P块,然后输入到Stroke Predictor。
将文中的方法与两种最先进的基于笔划的绘制生成方法进行比较。与基于优化的方法(Optim)相比,Paint Transformer可以产生更吸引人和新颖的结果。
具体来说,在大的无纹理图像区域中,我们的方法可以生成具有相对较少和较大笔划的类人绘画的效果。
在小的纹理丰富的图像区域,Paint Transformer可以生成纹理更清晰的绘画,以保持内容结构。
进一步使用更多笔划实现Optim+MS,上述问题仍然存在。
与基于RL的方法相比,可以使用清晰的笔刷生成更生动的结果。同时,RL的结果有些模糊,缺乏艺术性,与原始图像也太相似。
在量化比较上(Quantitative Comparison),由于神经绘画的一个目标是重建原始图像,直接使用像素损失和感知损失作为评估指标。
对于真实图像,随机选择100幅风景画,从WikiArt中随机选择100幅艺术画,从FFHQ中随机选择100幅肖像画进行评估。实验结果与先前的定性分析一致:
(1)Paint Transformer具有生动的画笔纹理,可以呈现的原始内容优于Optim
(2) 实现了最佳的内容保真度,但其内容清晰度较弱。
然后,为了比较笔划预测性能,将合成的笔划图像输入给Paint Transformer和Optim,并使用与Sec相同的度量来评估它们生成的笔划。结果表明,该方法能够成功地预测笔划,并优于其他方法。

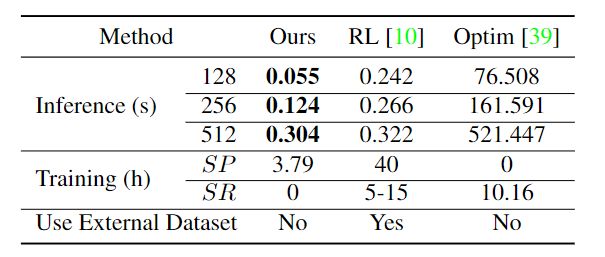
性能实验结果表明,该方法具有较好的绘制性能,且训练和推理成本较低。当使用单个Nvidia 2080Ti GPU测量训练或推理时间,由于Paint Transformer以前馈方式平行产生一组笔划,因此其运行速度明显快于优化Optim基线,略快于基于RL的基线模型。
至于训练过程,只需要几个小时就可以训练笔划预测参数,从总训练时间的角度来看。此外,无模型笔划渲染器和无数据笔划预测器效率高,使用方便。
目前代码和模型都已经提交到GitHub上了。

文中另一个重要的贡献是提供了一个数据集。由于没有可用于训练Paint Transformer的数据集,所以研究人员设计了一个自我训练的pipeline,这样它可以在没有任何现成的数据集的情况下进行训练,同时具有不错的泛化能力。
不过Reddit网友对此似乎有异议,认为这么简单的任务根本不需要使用机器学习技术!
下面有网友回复说他之前也做过,只需要50行Scala代码做的和这个就差不多了。

还有说不理解为什么要用神经网络来做这个。

参考资料:
https://www.reddit.com/r/MachineLearning/comments/p41hko/pr_paint_transformer_feed_forward_neural_painting/
推荐阅读
【重磅】斯坦福李飞飞《注意力与Transformer》总结,84页ppt开放下载!
周志华教授:如何做研究与写论文?(附完整的PPT全文)
【硕博士推荐】国内有哪些不错的CV(计算机视觉)团队?
台大李宏毅《机器学习》2021课程撒花完结!附视频、PPT,以及一本答疑书
清华姚班教师劝退文:读博,你真的想好了吗?
2021李宏毅老师最新40节机器学习课程!附课件+视频资料
最强通道注意力来啦!金字塔分割注意力模块,即插即用,效果显著,已开源!
登上更高峰!颜水成、程明明团队开源ViP,引入三维信息编码机制,无需卷积与注意力
常用 Normalization 方法的总结与思考:BN、LN、IN、GN
注意力可以使MLP完全替代CNN吗? 未来有哪些研究方向?
重磅!DLer-计算机视觉&Transformer群已成立!
大家好,这是计算机视觉&Transformer论文分享群里,群里会第一时间发布最新的Transformer前沿论文解读及交流分享会,主要设计方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、视频超分、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如Transformer+上交+小明)

???? 长按识别,邀请您进群!