Hadoop伪分布式集群配置
一、虚拟机准备工作
每台服务器的配置
1.配置动态ip
配置文件 ifcfg-ens33
vim /etc/sysconfig/network-scripts/ifcfg-ens33

BOOTPROTO="static" 将ip改为动态
IPADDR=192.168.47.130 设置ip地址
GATEWAY=192.168.47.2 设置网关
NETMASK=255.255.255.0 子网掩码
DNS1=192.168.47.2 域名解析器
2.更改服务器名字
vim /etc/hostname
3.配置ip映射
vim /etc/hosts

192.168.47.130 hadoop
192.168.47.130 hadoop01
192.168.47.130 hadoop02
192.168.47.130 hadoop03
4.安装epel-release
yun install -y epel-release
5.关闭防火墙,关闭防火墙自动开机
systemctl stop firewalld.service
systemctl disable firewalld.service
重启虚拟机
reboot
6.在windows上操作(这是为了在进入网站时,可以直接输入服务器名,不用输入ip地址)
进入hosts文件
C:WindowsSystem32driversetc

192.168.47.130 hadoop
192.168.47.130 hadoop01
192.168.47.130 hadoop02
192.168.47.130 hadoop03
卸载虚拟机自带的JDK(如果是最小安装则不需要执行这一步)
rpm -qa | grep -i java | xargs -n1 rpm -e –nodeps
rpm -qa 查询所安装的所有rpm软件包
grep -i 筛选关键字,并忽略大小写
xargs -n1 表示每次只传递一个参数
rpm -e –nodeps 强制卸载软件
因为把带jdk文件都删除了所以有以下操作
设置jdk软链接到 /bin/java
ln -s jdk的存放路径/bin/java /bin/java
重启虚拟机
reboot
安装rz命令 yum install -y lrzsz
用rz命令把jdk和hadoop软件压缩包传输到服务器上
解压jdk和hadoop到指定文件
tar -zxvf JDK压缩文件 -C 指定目录
配置环境变量
vim /etc/profile

这是一个启动事件
我们在/etc/profile.d创建并打开一个文件my_env.sh,在这个文件里配置环境变量
vim /etc/profile.d/my_env.sh

#JAVA_HOME
export JAVA_HOME=/hadoop/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/hadoop/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
然后刷新/etc/profile文件
source /etc/profile
然后输入java 和hadoop检查是否环境变量是否配置成功
自定义hadoop的配置文件
集群部署规划
注意事项:
1.NameNode 和 SecondaryNameNode 尽量不要安装在同一台服务器,因为NameNode和
SecondaryNameNode都比较耗内存
2.ResourceManager也很耗内存,不要和NameNode,SecondaryNameNode配置在同一台机器
| hadoop |
hadoop01 |
hadoop02 |
hadoop03 |
|
| HDFS |
NameNode DataNode |
DataNode |
Secondary NameNode DataNode |
DataNode |
| YARN |
NodeManager |
ResourceManager NodeManager |
NodeManager |
NodeManager |
核心配置文件
vim core-site.xml

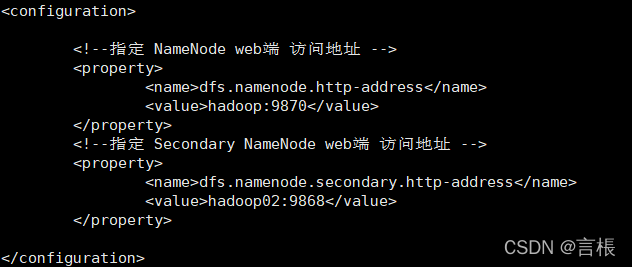
HDFS配置文件
vim hdfs-site.xml
YARN配置文件
vim yarn-site.xml

MapReduce 配置文件
vim mapred-site.xml

配置workers文件
vim workers

把集群所有服务器的名字写入
配置历史服务(用来查看程序历史运行情况)
vim mapred-site.xml
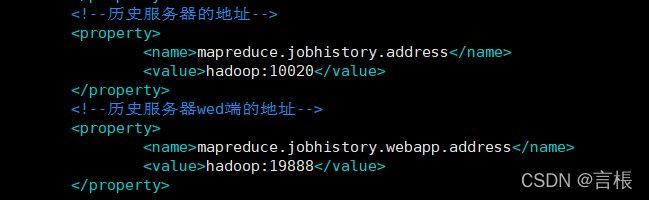
开启这个功能
mapred --daemon start historyserver
配置日志聚集功能(方便我们在wed查看日志)
vim yarn-site.xml

在命令行下输入如下命令,并将返回的地址复制。(后面运行mapreduce后有问题用以下操作)
hadoop classpath
# 编辑yarn-site.xml
vim yarn-site.xml
添加如下内容
SSH免密登录设置(如果不同的用户要登陆就要另外设置免密)
1.创建一对密钥<密钥存放位置在该用户目录下的 /.ssh 文件下>(私钥
ssh-keygen -t rsa
![]()

2.将公钥分别拷贝给自己和别的服务器
ssh-copy-id 主机名
![]()
![]()
3.验证免密是否成功
ssh 主机名

4.当全部免密设置完成后的 .ssh 文件有4个文件

id_rsa 存放私钥
id_rsa.pub 存放公钥
authorized_keys 存放了谁可以免密登入自己的服务器名
known_hosts 存放了自己被免密登入的记录
scp & rsync 拷贝命令
1.scp可以实现服务器与服务器之间的数据拷贝
2.rsync主要用于备份和镜像,具有速度快、可以避免拷贝相同内容和支持符号链接的优点
3. scp & rsync的区别:rsync只对有差异的文件做更新<速度快>,而scp是把所有文件复制过去。
4.基本语法
scp -r
命令 递归 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称
![]()
rsync -av
命令 a:全部v:显示执行过程 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称

登入https://hadoop:9870查看HDFS
登入https://hadoop01:8088查看YARN
进行mapreduce程序测试
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount 被测文件路径 测试数据存放的文件路径
常用端口号
hadoop3.x
HDFS NameNode 内部通常端口:8020、9000、9820
HDFS NameNode 对用户端的查询端口:9870
YARN查看任务运行情况端口:8088
历史服务器端口:19888
hadoop2.x
HDFS NameNode 内部通常端口:8020、9000
HDFS NameNode 对用户端的查询端口:50070
YARN查看任务运行情况端口:8088
历史服务器端口:19888
常用的配置文件
3.x:core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml workers
2.x:core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml slaves