Hadoop集群安装和配置(完全分布式集群搭建)
1 虚拟机的环境准备
- 1.1 下载的软件

![]()
![]()
1、安装Vmware-workstation
主要步骤就不讲述,网上可以收到相关Linux虚拟机的相关密钥和安装步骤。
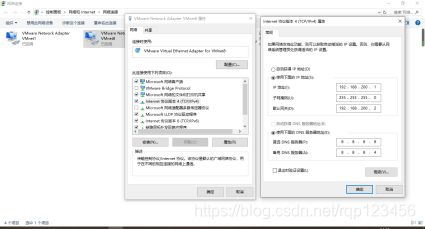
2、VM网络设置
打开电脑里面的控制面板——>网络和Internet——>网络和共享中心——>更改适配器设置——>VMnet8(右击鼠标,点击属性)—>IPv4(配置IP地址和DNS地址).我的电脑配置如下:
3、查看虚拟机的ip地址
打开Vmware Workstation 的编辑——>虚拟机网络编辑器(打开有点慢)——>点击右下角更改配置VMnet8(与上图的配置要一致的网段192.168.200.0),具体的配置如下:
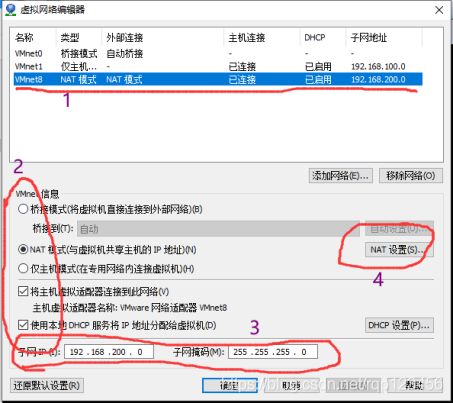
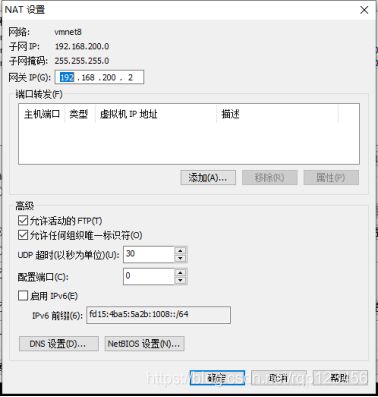
虚拟机编辑器中的网关ip:192.168.200.2要和自己电脑vmnet8的默认网关ip要一致。
4、安装虚拟机Centos(hadoop111)
打开Vmware点击新建虚拟机——>典型——>选择安装程序光盘映像文件(CentOS-7-x86_64-DVD-1708.iso)——>虚拟机名称(hadoop111:储存位置自己选择)——>最大磁盘大小20GB——>将虚拟磁盘拆分成多个文件——>自定义硬件(内存2GB、处理器2个、网络适配器NAT模式)——>完成(时间有点长,耐心等待)——>选择简体中文——>创建用户和密码(一定要记住,要登录到虚拟机)——重启——输入用户名和密码登录到虚拟机,虚拟机创建完成。
5、hadoop111网络设置
[root@hadoop111 ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33
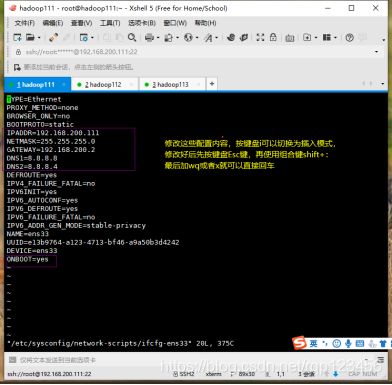
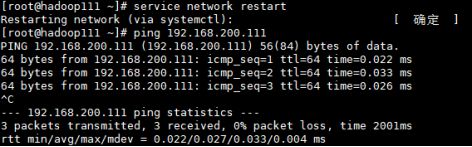
重启网路并ping自己的ip(若ip地址忘了,可以用ip a查看,ping通之后按Ctrl+C停止)
- 1.2 克隆虚拟机
1、鼠标右击刚刚配置好的hadoop111——>管理——>克隆——>虚拟机中的当前状态——>创建完整克隆——虚拟机名称(hadoop112)——>完成。依照这样的顺序,在克隆一个虚拟机hadoop113
2、同步时间:先把三台虚拟机关机,右击虚拟机——>设置——>选项——>Vmware Tools功能(开启时间同步)
- 1.3 Xshell和Xftp5安装
1、Xshell作用:可以同时连接多台服务器,将多台服务器连接在一台机器上操作,这样就不用在每台服务器上进行操作,方便远程操作服务器;主要是对服务器进行命令操作。
2、Xftp5作用:可以同时连接多台服务器,将多台服务器连接在一台机器上操作,这样就不用在每台服务器上进行操作,方便远程操作服务器;主要是对服务器进行文件传输操作。
3、安装:Xshell和Xftp5安装过程一直默认就好,自己选择安装路径。
4、Xshell连接虚拟机:名称(hadoop111)、协议(SSH)、主机ip(192.168.200.111),连接的时候一定要将虚拟机开机,连接的时候输入用户名和密码(最好记住勾选记住用户名和密码,方便下次不用再次输入),就可以连接到虚拟机了。其他两台和这操作一样,注意ip地址不要输错。
5、Xftp连接虚拟机:名称(hadoop111)、协议(SFTP)、主机ip(192.168.200.111),同样连接时输入密码和用户名,在新建对话的选项属性里面勾选“使用UTF-8编码”(否则会出现乱码现象),连接成功后就可以看见虚拟机里面的文件了。其他两台和这操作一样。
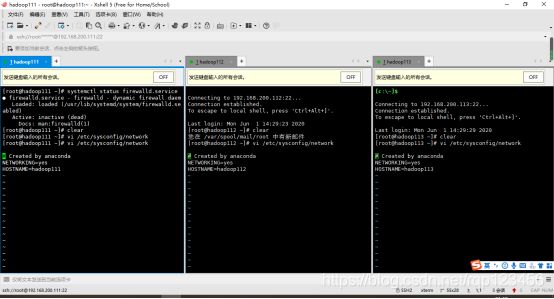
- 1.4 关闭防火墙
登录到hadoop111服务器,先查看防火墙状态,若是running,则要关闭防火墙(systemctl stop firewalld.service),这个命令不会永久关闭防火墙,所以防止重启服务器时防火墙还会开启,还需要输入(开机自启:systemctl disable firewalld.service),另外两台也是如此设置。

- 1.5 设置主机名
若只是修改network文件,下次重启虚拟机是,会发现修改后的名字又回到原始名字去了。原来network文件只修改了瞬态(Transient)主机名,并没有修改静态(Static)主机名。因此还要输入“vi /etc/hostname”在编辑器中输入如下代码hadoop111、hadoop112、hadoop113,记得一定要把原来的内容删掉,保存并退出。重新启动各个服务器,就发现主机名被修改了。
- 1.6 hosts设置
为了让计算机名进行网络访问,我们还需要修改hosts文件中的主机名和ip地址对照列表。注意:仍然需要在root用户下进行操作,保留文件已有代码,在后面添加新代码。
虚拟机hadoop110是我之前搭建hadoop伪分布式集群,可以忽略,为了能让四个服务器互相ping通并连接外网,所以将hadoop110的ip地址加了进来。最前面两行的#键是后面配置好集群之后,访问不了hadoop112:8088添加的,是禁止内网,访问外网的意思。此处的设置可以先别注释掉最初两行,保持代码原状,依次添加完全分布式集群的各个虚拟机的ip地址及其主机名(一定不要输错)。

2 安装文件
- 2.1 创建文件夹
(1)在/opt目录下创建module、software文件夹,我的software文件夹主要是放软件压缩包,而module文件夹主要是放压缩包解压之后的软件。
[root@hadoop111 ~]# cd /opt/
[root@hadoop111 opt]# mkdir module
[root@hadoop111 opt]# mkdir software
(2)修改module、software文件夹的所有者cd

- 2.2安装JDK(版本最好是在1.8以上)
2.2.1 卸载现有JDK
(1)查询是否安装Java软件:
[root@hadoop111 opt]# rpm -qa | grep java
(2)如果安装的版本低于1.7,卸载该JDK:
[root@hadoop111 opt]# rpm -e 软件包
(3)查看JDK安装路径:
[root@hadoop111 ~]# which java
2.2.2 用Xftp工具将JDK导入到/opt/software文件夹下
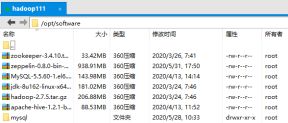
2.2.3 在Linux系统下的opt目录中查看软件包是否导入成功

2.2.4 解压JDK到/opt/module目录下
[root@hadoop111 software]$ tar -zxvf jdk-8u162-linux-x64.tar.gz -C /opt/module/
2.2.5配置JDK环境变量
(1)先获取JDK路径
[root@hadoop111 jdk1.8.0_162]# pwd
/opt/module/jdk1.8.0_162
(2)打开/etc/profile文件,在profile文件末尾添加JDK路径,保存后退出(:wq或:x)
[root@hadoop111 jdk1.8.0_162]# vi /etc/profile
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_162
export PATH= P A T H : PATH: PATH:JAVA_HOME/bin
(3)让修改后的文件生效
[root@hadoop111 jdk1.8.0_162]# source /etc/profile
2.2.6 测试JDK是否安装成功
[root@hadoop111 jdk1.8.0_162]# java -version
java version “1.8.0_162”
Java™ SE Runtime Environment (build 1.8.0_162-b12)
Java HotSpot™ 64-Bit Server VM (build 25.162-b12, mixed mode)
注意:重启虚拟机(如果java -version可以用就不用重启)
[root@hadoop111 jdk1.8.0_162]# sync
[root@hadoop111 jdk1.8.0_162]# reboot
- 2.3 安装Hadoop
2.3.1 Hadoop官网下载地址
https://archive.apache.org/dist/hadoop/common/hadoop-2.7.5/ (下载2.0版本以上的hadoop都可以)![]()
2.3.2 用Xftp工具将hadoop导入到/opt/software文件夹下
2.3.3 解压安装文件到/opt/module目录
[root@hadoop111 opt]# cd software
[root@hadoop111 software]# tar -zxvf hadoop-2.7.5.tar.gz -C /opt/module/
2.3.4 将Hadoop添加到环境变量
(1)获取Hadoop安装路径
[root@hadoop111 hadoop-2.7.5]# pwd
/opt/module/hadoop-2.7.5
(2)打开/etc/profile文件
[root@hadoop111 hadoop-2.7.5]# vi /etc/profile
在profile文件末尾添加JDK路径:(快捷键:shitf+g)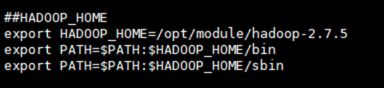
(3)让修改后的文件生效
[root@hadoop111 hadoop-2.7.5]# source /etc/profile
(4)测试是否安装成功

3 配置相关文件
- 3.1 集群配置的部署规划

- 3.2 核心配置文件core-site.xml
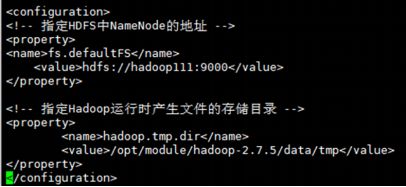
- 3.3 HDFS配置文件
3.3.1 配置hadoop-env.sh
[root@hadoop111 hadoop]$ vi hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_162
3.3.2 配置hdfs-site.xml
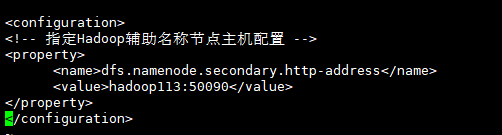
- 3.4 YARN配置文件
3.4.1 配置yarn-env.sh
配置一下JAVA_HOME: export JAVA_HOME=/opt/module/jdk1.8.0_162
3.4.2 配置yarn-site.xml
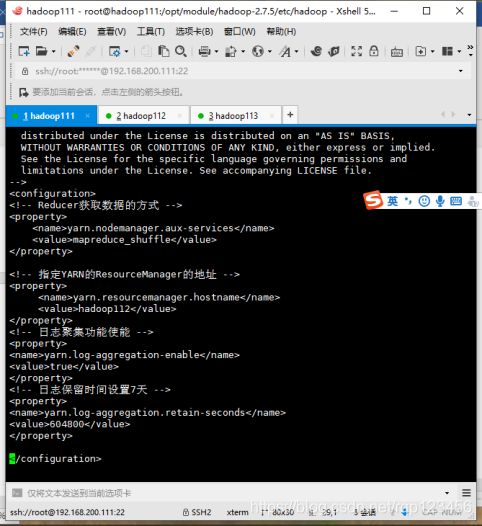
- 3.5 MapReduce配置文件
3.5.1 配置mpared-env.sh
遇到env文件就找JAVA_HOME,配置一下JAVA_HOME:
export JAVA_HOME=/opt/module/jdk1.8.0_162
3.5.2 配置mpared-site.xml
将mapred-site.xml.template重新命名为mapred-site.xml
[root@hadoop111 hadoop]# mv mapred-site.xml.template mapred-site.xml
[root@hadoop111 hadoop]# vi mapred-site.xml
注:指定MR运行在YARN上
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
- 3.6 拷贝文件分发到hadoop112、hadoop113
1、scp(secure copy)安全拷贝: scp可以实现服务器与服务器之间的数据拷贝。(from server1 to server2)。
(1)基本语法:scp -r p d i r / pdir/ pdir/fname u s e r @ h a d o o p user@hadoop user@hadoophost: p d i r / pdir/ pdir/fname
命令 递归 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
(2)将hadoop111中/opt/module目录下的软件拷贝到hadoop112、hadoop113上。
[root@hadoop111 ~]# scp -r /opt/module root@hadoop112:/opt/module
注意:拷贝过来的/opt/module目录,别忘了在hadoop112、hadoop113上修改所有文件的所有者和所有者组。chown root:root -R /opt/module
(3)将hadoop111中/etc/profile文件拷贝到hadoop112、hadoop113的/etc/profile上。
[root@hadoop111 ~]# scp /etc/profile root@hadoop112:/etc/profile
[root@hadoop111 ~]# scp /etc/profile root@hadoop113:/etc/profile
注意:拷贝过来的配置文件要source /etc/profile
2、rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
(1)基本语法
rsync -rvl p d i r / pdir/ pdir/fname u s e r @ h a d o o p user@hadoop user@hadoophost: p d i r / pdir/ pdir/fname
命令 选项参数 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
(2)在/home/root目录下创建bin目录,并在bin目录下xsync创建文件
[root@hadoop111 ~]# mkdir bin
[root@hadoop111 ~]# cd bin/
[root@hadoop111 bin]# touch xsync
[root@hadoop111 bin]# vi xsync
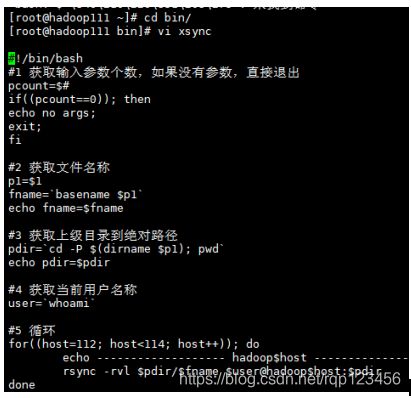
(3)修改脚本xsync具有执行权限
[root@hadoop111 bin]# chmod 777 xsync
(4)调用脚本形式:xsync文件名称
[root@hadoop111 bin]# xsync /home/root/bin
注意:如果将xsync放到/home/root/bin目录下仍然不能实现全局使用,可以将xsync移动到/usr/local/bin目录下。echo $PATH可表示文件能在那些路径目录文件下执行。
- 3.7 在集群上分发配置文件hadoop112、hadoop113
[root@hadoop111 hadoop]# xsync /opt/module/hadoop-2.7.5/
[root@hadoop112 hadoop]# cat /opt/module/hadoop2.7.5/etc/hadoop/core-site.xml
4 集群单点启动
- 4.1 如果集群是第一次启动,需要格式化NameNode
[root@hadoop111 hadoop-2.7.5]# bin/hdfs namenode -format或hadoop namenode -format
- 4.2 在hadoop111上启动NameNode
[root@hadoop111 hadoop-2.7.5]# sbin/hadoop-daemon.sh start namenode(namenode只有一个(主机)其余两个是辅助机则用datanode)
[root@hadoop111 hadoop-2.7.5]# jps
1573 NameNode

- 4.3 在三台虚拟机上分别启动DataNode

5 SSH无密登录配置
- 5.1 配置ssh
(1)基本语法:ssh另一台电脑的ip地址
(2)ssh连接时出现Host key verification failed的解决方法
[root@hadoop111 hadoop-2.7.5]# ssh 192.168.200.112 出现提示时直接输入yes
- 5.2 .ssh文件夹下(~/.ssh)的文件功能解释

- 5.3 生成公钥和私钥
因为我之前配置集群的时候已经生成过公钥和私钥,所以输入y。若第一次配置SSH免密登录时只需要[root@hadoop111 .ssh]# ssh-keygen -t rsa这个命令之后连续敲三次回车,就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)。

查看生成的两个文件:
![]()
- 5.4 将公钥拷贝到要免密登录的目标机器上
这一步骤只需要根据输入命令之后的提示输入密码即可,并且hadoop111服务器本身也要拷一份公钥,进行免密登录
[root@hadoop111 .ssh]# ssh-copy-id hadoop111
[root@hadoop111 .ssh]# ssh-copy-id hadoop112
[root@hadoop111 .ssh]# ssh-copy-id hadoop113
6 群起集群
- 6.1 配置slaves
到/opt/module/hadoop-2.7.5/etc/hadoop/slaves配置文件,注意该文件中添加的内容结尾不允许有空格,文件中不允许有空行。同步所有节点都要配置这一文件,配置如下:
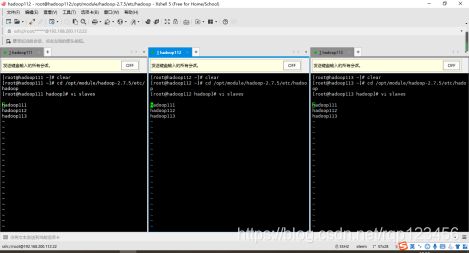
利用Xshell工具采取同步操作可以完成三台虚拟机的配置slaves,也可采用3.6节手动配置的xsync脚本,若用后者,命令如下:
[root@hadoop111 hadoop]# xsync slaves
- 6.2 启动集群
(1)如果集群是第一次启动,需要格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)。
因为我之前单点启动过集群,所以为避免冲突报错,一定要先查看每个虚拟机的进程(jps),若有则将其kill(杀死进程)。杀死之后应当重新格式化,启动之前一定要删除每个机子的data/ logs/
[root@hadoop111 hadoop-2.7.5]# bin/hdfs namenode -format
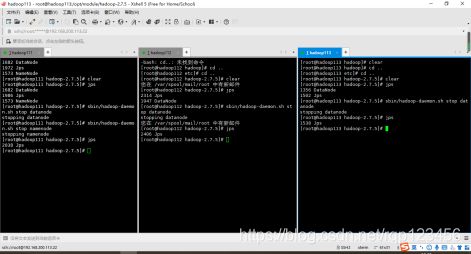
(2)启动HDFS
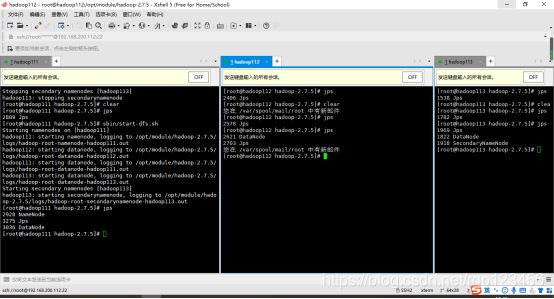
(3)启动YARN

注意:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动 YARN,应该在ResouceManager所在的机器上启动YARN(必须是hadoop112)。
(4)Web端查看SecondaryNameNode
(a)浏览器中输入:http://192.168.200.113:50090/status.html
(b)查看SecondaryNameNode信息

(5)Web端查看ResourceManager
(a)浏览器中输入:http://192.168.200.112:8088/cluster
(b)查看ResourceManager信息
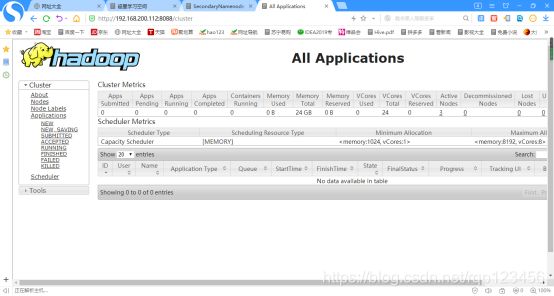
(6)Web端查看HDFS(NameNode节点的虚拟机)
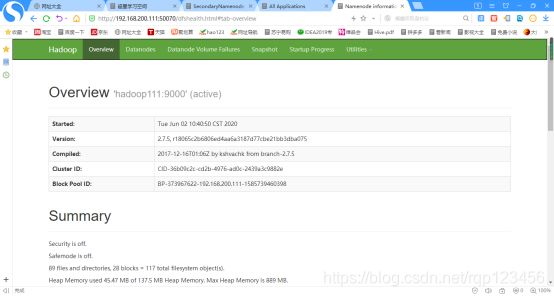
(a)浏览器中输入:http://192.168.200.111:50070/dfshealth.html#tab-overview
(b)查看HDFS信息
7 总结主要出错的地方如下:
1、设置主机名依旧还是克隆原虚拟机名称,检查发现是在/etc/hosts文件没修改的缘故。
2、hadoop启动后jps查不到namenode或者dataNode的办法:完全分布式集群搭建启动过程未发现错误,但是在/opt/hadoop/hadoop/etc/hadoop目录下用jps查看进程时,发现少了NameNode,而DataNode却存在。
干脆看启动日志,我们从启动脚本打印的日志可知启动NameNode的日志是放在hadoop下的logs目录下,进入这个目录可发现有一个hadoop-namenode.log(名字貌似根据用户名而定:格式如×××namenode×××.log),打开这个日志文件发现有这么一段:
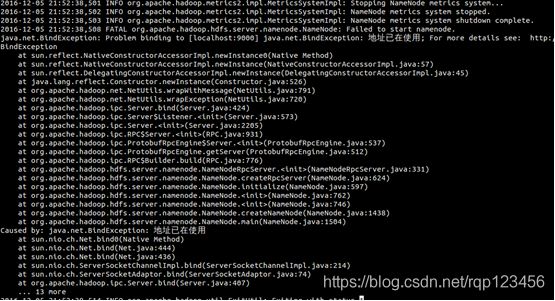
解决办法:原来是端口9000已经被占用,解决办法有两个,第一种:查找占用端口的进程,kill掉它。如果已占用进程需要使用9000端口,可用第二种方法:修改core-site.xml文件,把9000改成其他如9001. 我用的是第一种方法,首先找出占用9000端口的进程,然后kill掉它。
netstat -anp|grep 9000
tcp6 0 0 127.0.0.1:9000 127.0.0.1:43620 ESTABLISHED 7056/eclipse
kill -9 7056
3、Xshell连接不上Vmware虚拟机原因:IP地址是否正确(vi /etc/sysconfing/network-scripts/ifcfg-eth0将ip地址设置正确之后要将虚拟机网卡重置(即更新)——service network start)、或者是ssh协议勾选错误、或者检查主机的vi /etc/hosts添加虚拟机的ip地址是否与你的虚拟机名称一致(注意大小写、英文字符、空格等细节)
4、格式化集群未成功
![]()
格式化未成功的原因是$JAVA_HOME的位置没有修改,即/opt/module/hadoop-2.7.5/etc/hadoop下的env.sh文件配置未修改JAVE_HOME途径。
5、NameNode集群id:clusterID=CID-666775db-eea3-4f92-b827-f01610c1f6b7
DataNode集群id:clusterID=CID-666775db-eea3-4f92-b827-f01610c1f6b7
注:如果重复格式化,就会导致数据丢失,以至于以上序列号不对应,无法通讯,也就解决了之前的namenode和DataNode二选一而另一个不出来的缘故。
6、遇到权限不足的话则采用以下方法:去权限不足的目录或文件夹用chmod 777 +相应的权限不足的目录
[root@hadoop112 hadoop-2.7.5]# sbin/hadoop-daemon.sh start datanode
starting datanode, logging to /opt/module/hadoop-2.7.5/logs/hadoop-root-datanode-hadoop112.out
nice: /opt/module/hadoop-2.7.5/bin/hdfs: 权限不够
[root@hadoop112 hadoop-2.7.5]# cd bin/
[root@hadoop112 bin]# ll
[root@hadoop112 bin]# chmod 777 hdfs
[root@hadoop112 bin]# cd …
[root@hadoop112 hadoop-2.7.5]# sbin/hadoop-daemon.sh start datanode
starting datanode, logging to /opt/module/hadoop-2.7.5/logs/hadoop-root-datanode-hadoop112.out
[root@hadoop112 hadoop-2.7.5]# jps
1414 DataNode
1448 Jps