实例分割------Yolact-minimal结构详解
yolact结构图

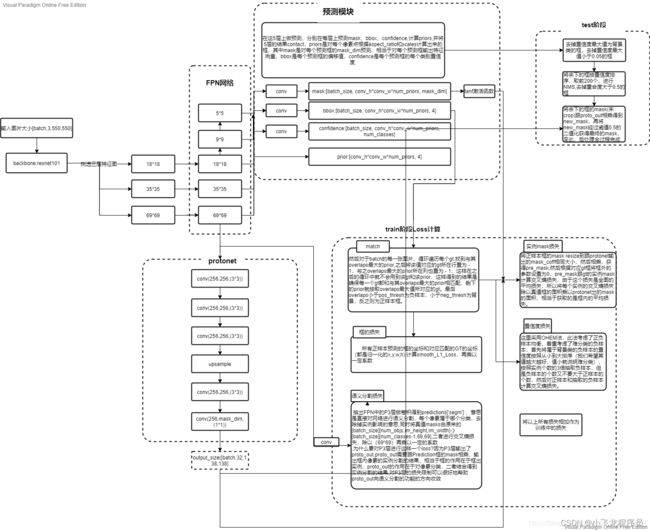
网络backbone可以采用resnet101,resnet50甚至vgg16等。然后有3个分支,1个分支输出目标位置,1个分支输出mask系数,1个分类的置信率,所以决定目标的有4(位置)+k(mask系数)+c(分类置信率)个参数。
检测的大致步骤为:
1.从backbone中取出C3,C4,C5;
2.通过FPN网络生成P3,P4,P5,通过P5生成P6和P7
3.P3通过Protonet生成k个138138的proto原型
4.P3~P7通过Prediction Head网络各生成WxHxa(a为anchor数)个位置(4),mask系数(k)以及置信率信息©:
loc:[None,WxHxa,4]
mask:[None,WxHxa,k]
conf:[None,WxHxa,81]
5.把上面的结果进行fast-nms处理
6.FastNMS的处理结果和Protonet输出的k个138*138的proto原型进行组合运算(叠加,裁切,阈值分割)即可获得最终的检测结果。
1.backbone网络结构
网络backbone可以采用resnet101,resnet50,vgg16网络结构.
import torch
import torch.nn as nn
from torchsummary import summary
import matplotlib.pyplot as plt
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, norm_layer=nn.BatchNorm2d):
super().__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = norm_layer(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = norm_layer(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = norm_layer(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
""" Adapted from torchvision.models.resnet """
def __init__(self, layers, block=Bottleneck, norm_layer=nn.BatchNorm2d):
super().__init__()
self.num_base_layers = len(layers)
self.layers = nn.ModuleList()
self.channels = []
self.norm_layer = norm_layer
self.inplanes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = norm_layer(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self._make_layer(block, 64, layers[0])
self._make_layer(block, 128, layers[1], stride=2)
self._make_layer(block, 256, layers[2], stride=2)
self._make_layer(block, 512, layers[3], stride=2)
self.backbone_modules = [m for m in self.modules() if isinstance(m, nn.Conv2d)]
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
self.norm_layer(planes * block.expansion))
layers = [block(self.inplanes, planes, stride, downsample, self.norm_layer)]
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes, norm_layer=self.norm_layer))
layer = nn.Sequential(*layers)
self.channels.append(planes * block.expansion)
self.layers.append(layer)
def forward(self, x):
""" Returns a list of convouts for each layer. """
print(x.shape)
x = self.conv1(x)
x = self.bn1(x)
print(x.shape)
x = self.relu(x)
print(x.shape)
x = self.maxpool(x)
print(x.shape)
outs = []
for i, layer in enumerate(self.layers):
x = layer(x)
print(i,x.shape)
outs.append(x)
return tuple(outs)
def init_backbone(self, path):
""" Initializes the backbone weights for training. """
state_dict = torch.load(path)
self.load_state_dict(state_dict, strict=True)
print(f'\nBackbone is initiated with {path}.\n')
if __name__ == '__main__':
model = ResNet(layers=[2,3,5,7]).cuda()
summary(model,(3,550,550))
2. fpn网络结构
class FPN(nn.Module):
def __init__(self, in_channels):
super().__init__()
self.in_channels = in_channels
self.lat_layers = nn.ModuleList([nn.Conv2d(x, 256, kernel_size=1) for x in self.in_channels])
self.pred_layers = nn.ModuleList([nn.Sequential(nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True)) for _ in self.in_channels])
self.downsample_layers = nn.ModuleList([nn.Sequential(nn.Conv2d(256, 256, kernel_size=3, padding=1, stride=2),
nn.ReLU(inplace=True)),
nn.Sequential(nn.Conv2d(256, 256, kernel_size=3, padding=1, stride=2),
nn.ReLU(inplace=True))])
self.upsample_module = nn.ModuleList([nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False),
nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False)])
def forward(self, backbone_outs):
p5_1 = self.lat_layers[2](backbone_outs[2])
p5_upsample = self.upsample_module[1](p5_1)
p4_1 = self.lat_layers[1](backbone_outs[1]) + p5_upsample
p4_upsample = self.upsample_module[0](p4_1)
p3_1 = self.lat_layers[0](backbone_outs[0]) + p4_upsample
p5 = self.pred_layers[2](p5_1)
p4 = self.pred_layers[1](p4_1)
p3 = self.pred_layers[0](p3_1)
p6 = self.downsample_layers[0](p5)
p7 = self.downsample_layers[1](p6)
return p3, p4, p5, p6, p7
3. protonet网络结构
原论文讲的YOLACT核心分支之一:Protonet。该分支可以看作是一个FCN网络。
Protonet 部分对于每张输入图像预测k个prototype masks。对于coco数据集,作者尝试了k取8,16,32,64,128,256,发现32效果最好。因此最终这部分输出的 mask 维度是 13813832,即 32 个 prototype mask,每个大小是 138*138。
注意:你会发现mask的数量 k 不依赖于类别数量,也就是类别可能比模板数量多。论文中说的是,YOLACT学习到的是一种分布式的表示,其中每个实例都由多个 prototype masks(模板原型)组合分割,这些模板在不同类别之间共享。

图5展示了六种不同的prototype mask对不同图像特征的响应,反映了不同 prototype mask 的效果。
1,4,5 可以清晰检测出目标的轮廓(尤其是图b,d,e,f,尤为明显);2 突出左下方向的特征 ; 3 区分前景和背景(图e,f比较明显);6 能够识别出背景。
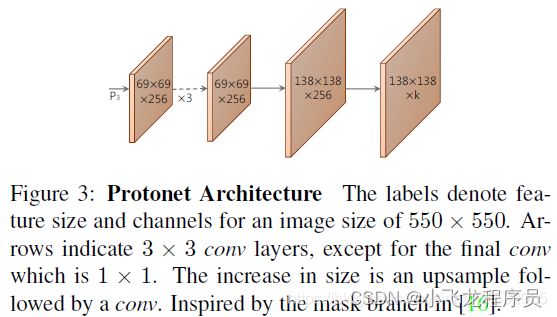
protonet是一个卷积网络,最终输出138138k的特征图(即proto),接下来,我们来简单的看下Protonet 的网络结构。其是一个全卷积网络,P3是该部分的输入。下面是一张protonet的的结构图:
关于mask系数,一开始我不是很理解,后来发现mask系数是用于给protonet产生的k个proto进行加权的。不管网络检测出几个目标,protonet都会输出k个138138的proto,这个很好理解;假设网络检测出8个目标,可以理解为网络会产生8个长度为k的向量,这8个k维向量的k个值分别和k个proto相乘,并再累加,就生成了8个对应的组合结果(即Assmebly),用公式表示如下。
M=μ(PCT)
P为poroto(138138k),C即某1个目标的mask系数(1k),M即为该目标的组合结果。
class ProtoNet(nn.Module):
def __init__(self, coef_dim):
super().__init__()
self.proto1 = nn.Sequential(nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True))
self.upsample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.proto2 = nn.Sequential(nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, coef_dim, kernel_size=1, stride=1),
nn.ReLU(inplace=True))
def forward(self, x):
x = self.proto1(x)
x = self.upsample(x)
x = self.proto2(x)
return x
4. 预测阶段
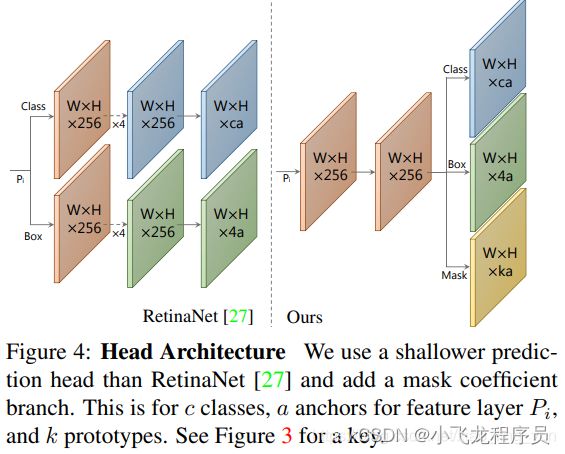
如上图所示,本文predition head 改自于Retina Net,同时采取共享卷积网络的trick,从而可以提高速度,达到实时分割的目的。
该分支的输入是 P3~P7 ,共计五个特征图,Prediction Head 也有五个共享参数的预测层与之一一对应。每个特征图先生成anchor,每个像素点生成3个anchor,比例是 1:1、1:2 和 2:1。五个特征图的anchor基本边长分别是24、48、96、192和384。
看代码,输入特征图 x,先经过一个upfeature,其结果作为三个并行分支(bbox_layer,conf_layer,mask_layer)的输入,每个像素点预测 3 个anchor ,最终为每个anchor预测(4 + c + k)个值,其实4:anchor坐标偏移,c:每个anchor一共有c个类,k:k个prototype mask的系数。对应上文 prototype mask ,k = 32时,模型效果最好。
class PredictionModule(nn.Module):
def __init__(self, cfg, coef_dim=32):
super().__init__()
self.num_classes = cfg.num_classes
self.coef_dim = coef_dim
self.upfeature = nn.Sequential(nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True))
self.bbox_layer = nn.Conv2d(256, len(cfg.aspect_ratios) * 4, kernel_size=3, padding=1)
self.conf_layer = nn.Conv2d(256, len(cfg.aspect_ratios) * self.num_classes, kernel_size=3, padding=1)
self.coef_layer = nn.Sequential(nn.Conv2d(256, len(cfg.aspect_ratios) * self.coef_dim,
kernel_size=3, padding=1),
nn.Tanh())
def forward(self, x):
x = self.upfeature(x)
conf = self.conf_layer(x).permute(0, 2, 3, 1).reshape(x.size(0), -1, self.num_classes)
box = self.bbox_layer(x).permute(0, 2, 3, 1).reshape(x.size(0), -1, 4)
coef = self.coef_layer(x).permute(0, 2, 3, 1).reshape(x.size(0), -1, self.coef_dim)
return conf, box, coef
5.mask assemble
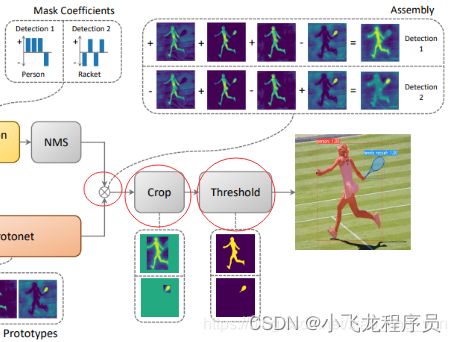
将 mask coefficient 和 prototype mask 做一个线性组合就得到了每个实例anchor 的分割图像。具体做法是采用如下的矩阵乘法:
M=sigmoid(PC^T)
其中 P:h×w×k的 prototype mask;C:n×k的mask系数矩阵;n:通过NMS和阈值过滤的 实例 / anchor,每个实例对应有 k 个mask 系数。
看公式很容易知道,每一个实例最终预测的mask,由 k 个 prototype mask(所以实例共享) 分别乘以 prototype mask 对应的mask系数(为每一个实例预测k个mask系数,并且该系数与其他实例独立),最终将k个结果线性组合而来。
需要注意的是,为了能够通过线性组合多个 prototype mask 来得到最终想要的mask,能够从最终的mask中减去原型mask是很重要的。换言之就是,mask系数必须有正有负。所以,在mask系数预测时使用了tanh函数进行非线性激活,因为tanh函数的值域是(-1,1)。
(1)对prototype mask P 和 mask系数矩阵C,做矩阵乘法。
(2)组合之后得到每一个目标实例的mask,对该mask进行crop操作,即将实例框之外的位置置零。训练时采用的是ground truth的检测框,测试时使用目标检测部分得到的检测框。
(3)最后以 threshold = 0.5 作为阈值,对输出的mask做二值化操作,将mask中值的范围限制在[0,1]之间。
6. Fast NMS
在得到位置偏移后,可以通过 预设anchor 的位置加上位置偏移得到 RoI 位置。然后通过NMS 算法筛出重叠ROI。但是因为NMS计算速度较慢,本文提出了一种NMS的简化版的 Fast NMS。
Fast NMS步骤:
(1)对于每个类别的前n个得分(Roi中目标是当前类的概率)最高的结果进行降序排列,然后计算它们两两之间的IoU得到一个C×n×n(其中C是类别总数)的矩阵 N,其中的每个n×n矩阵都为对角阵。
(2)同样针对某一类,剔除掉与得分更高结果重合的检测框Roi。
具体操作:删除矩阵N对角线以及下三角元素;然后取每一列的最大值,每一列的最大值大于阈值 t 的则被筛除,剩下的便是经过nms之后的检测结果。
下面的例子来自于博客:图像分割之YOLACT & YOLACT++
对于Person类,假设有 5 个RoI,按照置信度由高到低分别是 b1、b2、b3、b4 和 b5。接下来通过矩阵运算得出它们彼此之间的 IoU,假设结果如下图:

7. Loss
YOLACT在损失函数这一方面主要由四类别构成:
置信度损失(分类损失):交叉熵损失
Box损失:smooth_l1_loss
目标mask损失:这里用的是 二分类交叉熵loss。其中mask loss在计算时,因为mask的大小是138*138(mask结果是来自于prototype mask 和 mask系数矩阵,其中prototype mask的尺度是138 * 138 * k),因此需要先将原图的mask数据通过双线性插值缩小到这一尺寸。
语义分割损失:交叉熵损失
注:总损失=置信度损失+Box损失+语义分割损失+Mask损失

8. 实验
这个模型满足了实时的条件下实现了实例分割,还是有必要比较一下它和传统two-stage实力分割模型在性能上的差异。

我们核心来看一下红框部分,对比two-stage实例分割模型Mask-R-CNN,MS R-CNN,YOLACT的FPS是它们的4 倍;相对的,观察AP指标,大概和最好的MS R-CNN相比有10个点的差距;我们着重观察小目标分割,大概在AP上有8个点的差距,说实话在AP这方面差距还是挺大的。现在形如自动驾驶这方面确实需要实时的语义分割or实例分割,但是这一类任务对准确率和实时性的要求都很高,所以还是比较期待作者的进一步改进。
9. 核心优势/特色 以及 缺陷
YOLACT 三个显著的优势:
1)速度快:one-stage模、最终mask的预测是一个矩阵操作(可以利用现有的库)、FastNMS在略微牺牲性能的前提下基于矩阵操作完成Roi的筛选;
2)mask质量高,信息利用充分:不包含repooling类操作(主要体现在 protoNet)、残差网络+FPN的结构使得模型获得了充分的语义特征;
3)普适性强:这种生成原型mask和mask系数的思路可以应用在目前很多流行的检测器上。
yolact缺陷:
在2020年这个时间点,大多数任务都需要实时性和准确率兼并,YOLACT性能低于目前最好的实例分割方法(AP上10个点不少了!),那么这里面一定有原因!作者实验发现,错误大多数都是由检测器(predition head)引起的,比如检测错误,分类错误和边界框的位移等。这一部分详细可以去看看原论文中的 discussion 部分。
下面说明两个由YOLACT的mask生成方法造成的典型错误:
(1)定位误差(Localization Failure)
当在图像某个位置存在多个重叠的目标时(或者说prototype mask上某一个点存在的目标太多),网络可能无法通过自身学习到的 prototype mask 对每一个目标进行定位。在这种情况下,会输出更接近前景mask的内容,而不是某些目标的分割。
如下图所示,红色飞机下面的两辆卡车没有被正确分开(就是蓝色 truck:0.91)。

(2)泄露(Leakage)
泄露:噪声渗入实例掩码中,在某一个Roi中将另一个目标的部分误识别为当前目标的mask,如下图最右绿色滑雪者的anchor的左下角,你会发现预测出来的绿色 Roi 明显过大了,因为左下角包含了不属于绿色滑雪者的部分。
YOLACT 最终 mask 是在经过线性组合后crop(裁剪)得到的,该操作在 predition head 生成Roi后,所以没有抑制 Roi 外部噪声的功能。如果预测的Roi(也可以称为检测框)定位不准,那么就会导致mask泄露现象。
另外,当多个同类实例相隔较远但大小又很大的时候,也可能发生这种现象。因为网络可能认为(这个是学习到的特性)这几个实例已经离得很远了,自身不需要去分开定位它们,裁剪分支会负责处理这种情况。如下图所示,就属于这种情况。

论文最后,作者认为 该问题可以通过mask error down-weighting 机制得到缓解,如MS R-CNN(Mask Scoring R-CNN)中那样,其中显示这些错误的mask可以被忽略。
(3)论文实验解释 AP 差异的来源,Understanding the AP Gap
这部分不细说,作者对比mask-r-cnn经过相关实验说明了,AP的差异来自于预测anchor的准确率。
10. yolact-minimal调试步骤:
(1)环境:
PyTorch >= 1.1
Python >= 3.6
onnxruntime-gpu == 1.6.0 for CUDA 10.2
TensorRT == 7.2.3.4
tensorboardX
(2)prepare:
python setup.py build_ext --inplace
(3)打开config.py文件:
修改训练集和测试集的coco数据集的路径,修改后的路径如下:
(4)下载权重
(5)本人在windows上训练该代码:
python -m torch.distributed.launch --nproc_per_node=1 – train.py --train_bs=8
(6)用训练好的权重进行验证:
python eval.py --weight=weights/best_30.4_res101_coco_340000.pth
(7)用训练好的权重进行检测:
python detect.py --weight=weights/best_30.4_res101_coco_340000.pth --image=images
**(8)报错问题解决:**在config.py文件进行修改
RuntimeError: Distributed package doesn’t have NCCL built in
解决办法:在dist.init_process_group语句之前添加backend=‘gloo’,也就是在windows中使用GLOO替代NCCL。
11. 个人想法
(1)可以对网络模型进行改进:在backbone添加CBAM注意力机制。
(2) 在非极大值抑制上进行改性:把nms替换为fast nms,把Iou替换为Diou。