U-Net实现医学图像分割(pytorch)
刚开始学习pytorch框架时候,在github上下载过大佬的图像分割代码来训练自己数据集,但是却经常报错。后面在kaggle上下载了一个比较简洁易理解的分割代码,又根据自己的需求进行了修改评价指标、网络框架搭建以及可视化功能编写。
本文的主干代码来自:kaggle
数据集网址:https://www.kaggle.com/datasets/tawsifurrahman/covid19-radiography-database
评价指标参考:https://blog.csdn.net/sinat_29047129/article/details/103642140
自己的github网址:xiaoyu955
第一次写博客,如有错误欢迎大家指出。
步骤
1.库导入
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms as T
import torchvision
import torch.nn.functional as F
from torch.autograd import Variable
from utils.RAdam import RAdam
from PIL import Image
import cv2
import albumentations as A
import time
import os
from tqdm.notebook import tqdm
#评价指标计算去除了背景
from utils.pingjia import SegmentationMetric
import segmentation_models_pytorch as smp
2.数据读入及预处理
数据集分成训练集和测试集,选取840张肺部图片进行训练,160进行测试
# 训练集图像和标签
IMAGE_PATH = "F:\\unet2\\train\\image\\"
MASK_PATH ="F:\\unet2\\train\\label\\"
# 测试集图像和标签
IMAGE_PATH1 = "F:\\unet2\\test\\image\\"
MASK_PATH1 = "F:\\unet2\\test\\label\\"
# 读取图片序号
def create_df():
name = []
for dirname, _, filenames in os.walk(IMAGE_PATH):
for filename in filenames:
name.append(filename.split('.')[0])
return pd.DataFrame({'id': name}, index=np.arange(0, len(name)))
def create_df1():
name = []
for dirname, _, filenames in os.walk(IMAGE_PATH1):
for filename in filenames:
name.append(filename.split('.')[0])
return pd.DataFrame({'id': name}, index=np.arange(0, len(name)))
df = create_df()
df1 = create_df1()
print('Total Images: ', len(df))
X_train = df['id'].values
X_val = df1['id'].values
print('Train Size : ', len(X_train))
print('Test Size : ', len(X_val))
class DroneDataset(Dataset):
def __init__(self, img_path, mask_path, X, mean, std, transform=None, patch=False):
self.img_path = img_path
self.mask_path = mask_path
self.X = X
self.transform = transform
self.patches = patch
self.mean = mean
self.std = std
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
img = cv2.imread(self.img_path + self.X[idx] + '.png')
# print("image",img)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# mask = cv2.imread(self.mask_path + self.X[idx] + '.png')
mask = cv2.imread(self.mask_path + self.X[idx] + '.png', cv2.IMREAD_GRAYSCALE)
# mask = cv2.cvtColor(mask, cv2.COLOR_BGR2RGB)
# print("mask",mask)
if self.transform is not None:
aug = self.transform(image=img, mask=mask)
img = Image.fromarray(aug['image'])
mask = aug['mask']
if self.transform is None:
img = Image.fromarray(img)
t = T.Compose([T.ToTensor(), T.Normalize(self.mean, self.std)])
img = t(img)
mask = torch.from_numpy(mask).long()
if self.patches:
img, mask = self.tiles(img, mask)
return img, mask
mean=[0.485, 0.456, 0.406]
std=[0.229, 0.224, 0.225]
#使用裁剪、旋转、镜像、缩放等方式进行数据增强
t_train = A.Compose([
A.Resize(256, 256, interpolation=cv2.INTER_NEAREST),
A.HorizontalFlip(p=0.25),
A.VerticalFlip(p=0.25),
A.ShiftScaleRotate(shift_limit=0.05, scale_limit=0, rotate_limit=5, p=0.2)])
t_test = A.Resize(256, 256, interpolation=cv2.INTER_NEAREST)
#datasets
train_set = DroneDataset(IMAGE_PATH, MASK_PATH, X_train, mean, std, t_train, patch=False)
val_set = DroneDataset(IMAGE_PATH1, MASK_PATH1, X_val,mean, std, t_test, patch=False)
batch_size = 8
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_set, batch_size=1, shuffle=True)
3.可视化
将标签与原图覆盖,检查是否重合
for i in range(1000):
print("num",i)
# img = Image.open(IMAGE_PATH + df['id'][i] + '.png')
# mask = Image.open(MASK_PATH + df['id'][i] + '.png')
img = cv2.imread(IMAGE_PATH + df['id'][i] + '.png')
mask = cv2.imread(MASK_PATH + df['id'][i] + '.png')
# print("mask",img.shape)
print('Image Size', np.asarray(img).shape)
print('Mask Size', np.asarray(mask).shape)
plt.imshow(img)
plt.imshow(mask1, alpha=0.5)
plt.title('Picture with Mask Appplied')
plt.show()
4.模型选用及参数设置
4.1模型调用
pytorch已经封装好了FCN、U-Net、Deeplab三个经典分割模型,可以通过下载预训练权重进行调用。也可以自己写一个分割模型从头开始训练。
model = smp.Unet('densenet121', # U-Net编码部分模型
encoder_weights='imagenet', #预训练数据集
classes=2, activation=None, #预测的种类数目
encoder_depth=5, #网络深度
decoder_channels=[1024, 512, 256, 128, 64])
# model = torchvision.models.segmentation.deeplabv3_resnet50(pretrained=True, progress=True, num_classes=21, aux_loss=None)
# model = torchvision.models.segmentation.fcn_resnet50(pretrained=True, progress=True, num_classes=21, aux_loss=None)
for param in model.parameters(): # 训练时更新网络参数
param.requires_grad = True
print("model",model) #打印模型信息
4.2 优化器和损失
n_classes = 3
max_lr = 1e-3
epoch =100
weight_decay = 1e-4
#损失函数
criterion = nn.CrossEntropyLoss()
#不同优化策略
# AdaW+OneCycleLR
optimizer = torch.optim.AdamW(model.parameters(), lr=max_lr, weight_decay=weight_decay)
sched = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr, epochs=epoch,
steps_per_epoch=len(train_loader))
# RAdam+OneCycleLR
# optimizer = RAdam(model.parameters(), lr=0.001,weight_decay=weight_decay)
# sched = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr, epochs=epoch,
# steps_per_epoch=len(train_loader))
# RAdam+ReduceLROnPlateau
# optimizer = RAdam(model.parameters(), lr=0.001)
# sched = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, factor=0.2, patience=15, cooldown=10)
# optimizer = RAdam(model.parameters(), lr=0.1,weight_decay=weight_decay)
# sched = torch.optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
# 返回学习率大小
def get_lr(optimizer):
for param_group in optimizer.param_groups:
return param_group['lr']
5.模型训练
在训练模型时,训练一轮网络,测试一轮分割效果,并保存分割指标最好的一次模型权重。
def fit(epochs, model, train_loader, val_loader, criterion, optimizer, scheduler, patch=False):
torch.cuda.empty_cache()
train_losses = []
test_losses = []
beset_miou = []
val_iou = []
val_acc = []
train_iou = []
train_acc = []
lrs = []
train_cpa = []
val_cpa = []
min_loss = np.inf
min_miou = 0
min_cpa = 0
min_recall = 0
best = 0
decrease = 1
not_improve = 0
train_miou = []
val_miou = []
train_recall = []
val_recall = []
train_f1 = []
val_f1 = []
model.to(device)
fit_time = time.time()
for e in range(epochs):
since = time.time()
running_loss = 0
cpa = 0
miou1 = 0
recall = 0
f1 = 0
# training loop
model.train()
for i, data in enumerate(tqdm(train_loader)):
# training phase
image_tiles, mask_tiles = data
# print("image_tiles",image_tiles.shape)
# print("mask_tiles", mask_tiles.shape)
if patch:
bs, n_tiles, c, h, w = image_tiles.size()
image_tiles = image_tiles.view(-1, c, h, w)
mask_tiles = mask_tiles.view(-1, h, w)
# forward
# print("image",image.size())
image = image_tiles.to(device)
mask = mask_tiles.to(device)
output = model(image)
# loss
loss = criterion(output,mask)
# evaluation metrics
metric = SegmentationMetric(2) # ()里面表示分类
metric.addBatch(output, mask_tiles)
cpa += metric.meanPixelAccuracy()
miou1 += metric.meanIntersectionOverUnion()
recall += metric.recall()
f1 += metric.F1Score()
accuracy += metric.pixelAccuracy()
# backward
loss.backward()
optimizer.step() # update weight
optimizer.zero_grad() # reset gradient
# step the learning rate
lrs.append(get_lr(optimizer))
scheduler.step()
running_loss += loss.item()
else:
model.eval()
test_loss = 0
val_cpa_score = 0
test_miou = 0
val_Recall = 0
val_F1 = 0
# validation loop
with torch.no_grad():
for i, data in enumerate(tqdm(val_loader)):
image_tiles, mask_tiles = data
if patch:
bs, n_tiles, c, h, w = image_tiles.size()
image_tiles = image_tiles.view(-1, c, h, w)
mask_tiles = mask_tiles.view(-1, h, w)
image = image_tiles.to(device)
mask = mask_tiles.to(device)
output = model(image)
output2 = output.data.cpu().numpy()
# loss
loss = criterion(output, mask)
test_loss += loss.item()
metric = SegmentationMetric(2)
metric.addBatch(output, mask_tiles)
val_cpa_score += metric.meanPixelAccuracy()
test_miou += metric.meanIntersectionOverUnion()
val_Recall += metric.recall()
val_F1 += metric.F1Score()
test_accuracy += metric.pixelAccuracy()
# calculatio mean for each batch
train_losses.append(running_loss / len(train_loader))
test_losses.append(test_loss / len(val_loader))
# 保存精确率最高的权重
if val_cpa_score / len(val_loader) > min_cpa:
min_cpa = val_cpa_score / len(val_loader)
torch.save(model.state_dict(), "F:\\unet2\\weight\\focal2_0.25\\" + "best_cpa1.pth")
torch.save(model, "F:\\unet2\\weight\\focal2_0.25\\" + "best_cpa1.pt")
print("best cpa has saved:{:.3f} --- > {:.3f}".format(min_cpa, (val_cpa_score / len(val_loader))))
if val_Recall / len(val_loader) > min_recall:
min_recall = val_Recall / len(val_loader)
torch.save(model.state_dict(), "F:\\unet2\\weight\\focal2_0.25\\" + "best_recall1.pth")
torch.save(model, "F:\\unet2\\weight\\focal2_0.25\\" + "best_recall1.pt")
print("best recall has saved:{:.3f} --- > {:.3f}".format(min_recall, (val_Recall / len(val_loader))))
train_cpa.append(cpa / len(train_loader))
val_cpa.append(val_cpa_score / len(val_loader))
train_miou.append(miou1 / len(train_loader))
val_miou.append(test_miou / len(val_loader))
train_recall.append(recall / len(train_loader))
val_recall.append(val_Recall / len(val_loader))
train_f1.append(f1 / len(train_loader))
val_f1.append(val_F1 / len(val_loader))
print("Epoch:{}/{}..".format(e + 1, epochs),
"Train Loss: {:.4f}..".format(running_loss / len(train_loader)),
"Val Loss: {:.4f}..".format(test_loss / len(val_loader)),
"train_cpa:{:.4f}..".format(cpa / len(train_loader)),
"val_cpa:{:.4f}..".format(val_cpa_score / len(val_loader)),
"train_miou:{:.4f}..".format(miou1 / len(train_loader)),
"val_miou:{:.4f}..".format(test_miou / len(val_loader)),
"train_recall:{:.4f}..".format(recall / len(train_loader)),
"val_recall:{:.4f}..".format(val_Recall / len(val_loader)),
"train_f1:{:.4f}..".format(f1 / len(train_loader)),
"val_f1:{:.4f}..".format(val_F1 / len(val_loader)),
"Time: {:.4f}m".format((time.time() - since) / 60))
# 每隔50轮保存一次权重
if e % 50 == 0:
print('saving model...')
torch.save(model.state_dict(), "F:\\unet2\\weight\\focal2_0.25\\" + "unet" + "%03d" % (e) + ".pth")
torch.save(model, "F:\\unet2\\weight\\focal2_0.25\\" + "UNet" + "%03d" % (e) + ".pt")
history = {'train_loss': train_losses, 'val_loss': test_losses,
'train_miou': train_iou, 'val_miou': val_iou,
'train_cpa': train_cpa, 'val_cpa': val_cpa,
'train_miou1': train_miou, 'val_miou1': val_miou,
'train_recall': train_recall, 'val_recall': val_recall,
'train_f1': train_f1, 'val_f1': val_f1,
'lrs': lrs}
print('Total time: {:.3f} m'.format((time.time() - fit_time) / 60))
return history
开始训练
history = fit(epoch, model, train_loader, val_loader, criterion, optimizer, sched)
绘制曲线
将训练结果转为Numpy格式并保存,方便下次调用。
recall0 = np.array(history['train_recall'])
recall1 = np.array(history['val_recall'])
np.save("F:\\unet2\\contrast\\train_loss_1000{}".format(epoch),recall0)
np.save("F:\\unet2\\contrast\\train_loss_1000{}".format(epoch),recall1)
def plot_loss(history):
plt.plot(history['val_loss'], label='val', marker='.')
plt.plot( history['train_loss'], label='train', marker='.')
plt.title('Loss per epoch'); plt.ylabel('loss');
plt.xlabel('epoch')
plt.legend(), plt.grid()
plt.show()
def plot_score(history):
plt.plot(history['train_miou'], label='train_mIoU', marker='.')
plt.plot(history['val_miou'], label='val_mIoU', marker='.')
plt.title('mIoU'); plt.ylabel('mean IoU')
plt.xlabel('epoch')
plt.legend(), plt.grid()
plt.show()
def pca(history):
plt.plot(history['train_cpa'], label='train_cpa', marker='.')
plt.plot(history['val_cpa'], label='val_cpa', marker='.')
plt.title('mpa per epoch'); plt.ylabel('mpa')
plt.xlabel('epoch')
plt.legend(), plt.grid()
plt.show()
def plot_miou1(history):
plt.plot(history['train_miou1'], label='train_miou', marker='.')
plt.plot(history['val_miou1'], label='val_miou', marker='.')
plt.title('Miou per epoch'); plt.ylabel('miou')
plt.xlabel('epoch per epoch')
plt.legend(), plt.grid()
plt.show()
def recall(history):
plt.plot(history['train_recall'], label='train_recall', marker='.')
plt.plot(history['val_recall'], label='val_reacall', marker='.')
plt.title('reacll per epoch'); plt.ylabel('miou')
plt.xlabel('epoch')
plt.legend(), plt.grid()
plt.show()
def f1(history):
plt.plot(history['train_f1'], label='train_f1', marker='.')
plt.plot(history['val_f1'], label='val_f1', marker='.')
plt.title('f1_score per epoch'); plt.ylabel('f1_score')
plt.xlabel('epoch')
plt.legend(), plt.grid()
plt.show()
plot_loss(history)
plot_score(history)
plot_acc(history)
pca(history)
plot_miou1(history)
recall(history)
f1(history)
精确率
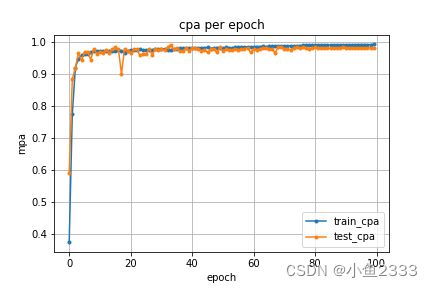
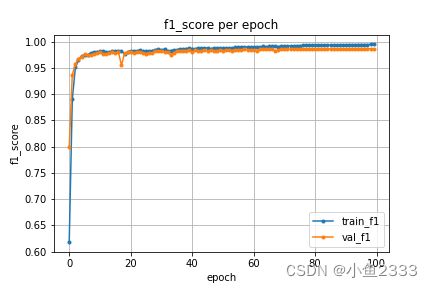
召回率

f1得分
分割效果


医学数据集
如果有想做医学影像识别的小伙伴想找数据集的话有以下两个途径可供参考:
1.kaggle。kaggle上有一些CT、MRI数据集,并且有代码可供参考。
2.美国癌症医学影像档案中心:https://www.cancerimagingarchive.net/。这个网站有大量癌症医学图像可供下载,不过需要填写申请协议。