Pytorch基础知识(10)多目标分割
在目标分割任务中,我们的目标是在图像中找到目标物体的边界。图像中目标的分割有很多应用,如自动驾驶汽车和医学图像分析。在单目标分割章节中,我们学习了如何使用PyTorch构建一个单目标分割模型。在本章中,我们将重点关注使用PyTorch开发一个深度学习模型来执行多目标分割。在多目标分割中,我们感兴趣的是自动勾勒出图像中多个目标的边界。
图像中物体的边界通常由与图像大小相同的分割掩码来定义。在分割掩码中,根据预先定义的标签,所有属于同一目标的像素被标记为相同的标签。例如,在下面的截图中,你可以看到一个带有两种类型目标的示例图像:婴儿和椅子。对应的分割掩码显示在截图的中间。正如我们所看到的,属于婴儿和椅子的像素被标记为不同的颜色,分别用黄色和绿色表示。从分割掩码中,我们可以在图像上叠加边界轮廓,如截图的右边所示:

多目标分割的目标是在给定图像中预测分割掩码,使图像中的每个像素根据其所属的类别进行标记。在本章中,我们将学习如何开发一个算法来自动分割VOC(Visual Object Classes )数据集的20个目标类别。
在本章中,我们将介绍以下教程:
- 定义自己的数据集
- 定义与部署模型
- 定义损失函数和优化器
- 训练模型
定义自己的数据集
我们将使用torchvsion.datasets包中的VOC分割数据集。这个数据集由包含20个类别的轮廓图像组成。加上背景,这就产生了21个对象类,它们的标签从0到20:
- 背景:0
- 飞机:1
- 自行车:2
- 鸟:3
- 舟:4
- 瓶子:5
- 巴士:6
- 轿车:7
- 猫:8
- 椅子:9
- 奶牛:10
- 餐桌:11
- 狗:12
- 马:13
- 摩托:14
- 人:15
- 盆栽植物:16
- 羊:17
- 沙发:18
- 火车:19
- 电视/监视器:20
在本教程中,我们将学习如何使用torchvision包加载VOCSegmentation数据,并创建用于训练和验证模型的自定义数据集类。
#1. 导入需要的包
from torchvision.datasets import VOCSegmentation
from torchvision.transforms.functional import to_tensor, to_pil_image
from PIL import Image
#2. 定义VOCSegmentation类的子类
class myVOCSegmentation(VOCSegmentation):
def __getitem__(self, index):
img = Image.open(self.images[index]).convert("RGB")
target = Image.open(self.masks[index])
if self.transforms is not None:
augmented = self.transforms(image=np.array(img), mask=np.array(target))
img = augmented["image"]
target = augmented["mask"]
target[target>20]=0
img = to_tensor(img)
target = torch.from_numpy(target).type(torch.long)
return img, target
#3. 定义transform 函数
from albumentations import HorizontalFlip, Compose, Resize, Normalize
mean=[0.285,0.456,0.406]
std=[0.229,0.224,0.225]
h,w=520,520
transform_train=Compose([Resize(h,w),
HorizontalFlip(p=0.5),
Normalize(mean=mean,std=std)])
transform_val=Compose([Resize(h,w),
Normalize(mean=mean,std=std)])
#4. 为训练集和验证集分别定义一个myVOCSegmentation类的实例
path2data="./data/"
train_ds=myVOCSegmentation(path2data,
year="2012",
image_set="train",
download=True,
transforms=transform_train)
val_ds=myVOCSegmentation(path2data,
year="2012",
image_set="val",
download=True,
transforms=transform_val)
print(len(train_ds))
#1464
print(len(train_ds))
#1449
#5. 显示训练集上的样例和分割掩膜
import torch
import numpy as np
from skimage.segmentation import mark_boundaries
import matplotlib.pylab as plt
np.random.seed(0)
num_classes=21
COLORS=np.random.randint(0,2,size=(num_classes+1, 3), dtype="uint8")
# 定义show_img_target辅助函数
def show_img_target(img, target):
if torch.is_tensor(img):
img=to_pil_image(img)
target=target.numpy()
for ll in range(num_classes):
mask=(target==ll)
img=mark_boundaries(np.array(img),mask,outline_color=COLOR[ll], color=COLOR[ll])
plt.imshow(img)
# 定义re_normalize辅助函数
def re_normalize(x, mean=mean, std=std):
x_r=x.clone()
for c,(mean_c, std_c) in enumerate(zip(mean, std)):
x_r[c] *= std_c
x_r[c] += mean_c
return x_r
# 获取train_ds数据集中的一个样本和分割掩膜
img, mask=train_ds[6]
print(img.shape, img.type(), torch.max(img))
print(mask.shape, mask.type(), torch.max(mask))
# torch.Size([3, 520, 520]) torch.FloatTensor tensor(2.6400)
# torch.Size([520, 520]) torch.LongTensor tensor(4)
# 显示带有分割掩膜和轮廓的样例图像
plt.figure(figsize=(20,20))
img_r=re_normalize(img)
plt.subplot(1,3,1)
plt.imshow(to_pil_image(img_r))
plt.subplot(1,3,2)
plt.imshow(mask)
plt.subplot(1,3,3)
show_img_target(img_r, mask)
#6. 相似的,获取val_ds数据集的带有分割掩膜的样例
img, mask=val_ds[0]
print(img.shape, img.type(), torch.max(img))
print(mask.shape, mask.type(), torch.max(mask))
# torch.Size([3, 520, 520]) torch.FloatTensor tensor(2.6226)
# torch.Size([520, 520]) torch.LongTensor tensor(1)
# 显示带有分割掩膜和轮廓的样例图像
plt.figure(figsize=(20,20))
img_r=re_normalize(img)
plt.subplot(1,3,1)
plt.imshow(to_pil_image(img_r))
plt.subplot(1,3,2)
plt.imshow(mask)
plt.subplot(1,3,3)
show_img_target(img_r, mask)
#7. 定义数据加载器
from torch.utils.data import DataLoader
train_dl=DataLoader(train_ds, batch_size=4, shuffle=True)
val_dl=DataLoader(val_ds, batch_size=8, shuffle=False)
#8. 分别获取train_dl和val_dl的一小批量数据
for img_b, mask_b in train_dl:
print(img_b.shape, img_b.dtype)
print(mask_b.shape, mask_b.dtype)
break
# torch.Size([4,3,520,520]) torch.float32
# torch.Size([4, 520, 520]) torch.int64
for img_b, mask_b in val_dl:
print(img_b.shape, img_b.dtype)
print(mask_b.shape, mask_b.dtype)
break
# torch.Size([8,3,520,520]) torch.float32
# torch.Size([8, 520, 520]) torch.int64


代码解析:
在步骤1中,我们导入了所需的包。我们从torchvision.datasets数据集包中导入了VOCSegmentation,以便我们可以加载VOC数据集。我们还从torchvision.transform .functional导入to_tensor和to_pil_image方法来将PIL图像转换为PyTorch张量和将PyTorch张量转换为PIL图像。
在步骤2中,我们通过继承VOCSegmentation类定义了一个自定义数据集类。创建子类的原因是我们需要修改VOCSegmentation类的__getitem__方法。在该方法中,我们从文件中加载PIL类型的图像和目标。然后,我们对图像和目标应用变换。
注意,目标中的像素值应该在[0,20],因为在VOC数据集中有21个对象类。因此,我们将任何大于20的可能值设置为0,以便将其算为背景像素:target[target> 20]=0。
在步骤3中,我们使用albumentations包定义了转换函数。我们在单目标分割中学习了如何安装和使用这个包。对于训练数据,应用了三个转换:Resize、HorizontalFlip和Normalize。对于验证数据,应用了两个转换:Resize和Normalize。我们使用Resize来调整所有图像的大小,使它们的大小相同。我们使用HorizontalFlip通过水平翻转图像来增加训练数据。最后,我们使用Normalize对图像进行归一化。
在步骤4中,我们分别为训练和验证数据集定义了myVOCSegmentation类的两个对象。这个类的参数如下:
- path2data:下载后存储/加载VOC数据集的路径
- year:"2012"和"2017"二选一
- image_set:"train"和"val"二选一
- download:设置为True,第一次时候从互联网下载数据
- transforms:数据增强函数
如我们所见,train_ds和val_ds中分别有1446和1449个文件。
在第5步中,我们从train_ds中获得了一个样本图像和它的目标掩码。然后,我们打印张量的形状,并显示图像和掩模。注意,返回的图像是torch.FloatTensor的张量, 最大像素值为2.64。
to_tensor方法将PIL图像转换为PyTorch张量,其像素值范围为[0,1]。但是由于归一化函数的作用,最大像素值会超过1。
而且,返回的掩膜是最大值为4的LongTensor类型张量。图像中包含船只,船只在VOC数据集中被分配为标签4。
为了显示图像,我们使用re_normalize辅助函数将图像反标准化。函数的输入如下:
- x: 一个标准化的张量,形状为[3, Height, Width]
- mean:三个元素的元组或列表,默认值为[0.485, 0.456, 0.406]
- std:三个元素的元组或列表,默认值为[0.229, 0.224, 0.225]
您可能还记得,在myVOCSegmentation中使用normalize转换函数对图像进行标准化。使用re_normalize辅助函数,我们得到图像的原始像素值,仅用于显示目的。
为了显示图像及其目标掩码,我们定义了一个名为show_img_target的辅助函数。函数的输入如下:
- img:PIL图像或PyTorch张量
- target:numpy数组或者PyTorch张量
在这个函数中,我们使用了skimage.segmentation中的mark_boundaries函数在图像上画出目标的轮廓。注意,如果您重新运行这部分代码,由于HorizontalFlip转换,图像及其掩膜将被翻转。
在第6步中,我们从val_ds中获得一个样本图像及其目标掩模,打印出它们的形状,并显示它们。正如您所看到的,返回的掩码是一个最大值为1的整数值张量。图像中包含一架飞机,该飞机在VOC数据集中被分配为标签1。
在步骤7中,我们分别为训练数据集和验证数据集定义了train_dl和val_dl数据加载器。
在第8步中,我们分别从train_dl和val_dl中提取批数据。注意,返回张量的形状是(batch_size, 3, height, width)和(batch_size, height, width)。
定义和部署模型
在本教程中,我们将学习如何使用torchvision.models创建和部署语义分割模型。该模型被称为DeepLabV3Net101,它是基于在本教程中,我们将学习如何使用torchvision创建和部署语义分割模型。模型包。该模型被称为DeepLabV3Net101,它是基于Rethinking Atrous Convolution for Semantic Image Segmentation文章。
本文着重介绍了利用空洞卷积(类似于给卷积核插值,增加感受野)来克服常规卷积神经网络和池化层在语义分割方面的局限性。
该模型在COCO train2017数据集的一个子集上进行预训练。当我们导入模型时,我们可以选择加载预先训练的权重或使用随机权重。
该模型期望输入图像缩放到[0,1]的范围,然后通过减去mean=[0.485, 0.456, 0.406]和除以std= [0.229, 0.224,0.225]。同样,模型在大小为520 * 520的图像上训练。您可能还记得创建自定义数据集教程中,我们将所有这些转换应用到myVOCSegmentation类的输入中。因此,一旦从数据加载器中获取了批数据,它就为模型训练准备好了。
由于模型是使用COCO train2017数据集进行预训练的,所以我们可以立即在VOC数据集上部署模型。然而,为了获得更好的性能,我们也可以在部署VOC训练数据集之前对模型进行训练。我们将在训练模型教程中学习如何训练模型。
在这个教程中,我们将向您展示如何加载预训练的权重模型,然后将其部署到VOC验证数据集上。
#1. 导入需要的包
import torch
from torchvision.models.segmentation import deeplabv3_resnet101
#2. 定义deeplabv3_resnet101类的实例对象
model = deeplabv3_resnet101(pretrained=True, num_classes=21)
#3. 将模型移到GPU设备上
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model=model.to(device)
#4. 打印模型
print(model)
# DeepLabV3(
# (backbone): IntermediateLayerGetter(
# (conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
# (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (relu): ReLU(inplace=True)
# (maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
# (layer1): Sequential(
# (0): Bottleneck(
# (conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
# (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# ....
#5. 将模型部署到来自验证数据集的批数据上:
from torch import nn
model.eval()
with torch.no_grad():
for xb, yb in val_dl:
yb_pred = model(xb.to(device))
yb_pred = yb_pred["out"].cpu()
print(yb_pred.shape)
yb_pred = torch.argmax(yb_pred, axis=1)
break
print(yb_pred.shape)
# torch.Size([8,21,520,520])
# torch.Size([8,520,520])
#6. 显示样本图像以及对应的预测结果
plt.figure(figsize=(20,20))
n=4
img,mask=xb[n],yb_pred[n]
img_r=re_normalize(img)
plt.subplot(1,3,1)
plt.imshow(to_pil_image(img_r))
plt.subplot(1,3,2)
plt.imshow(mask)
plt.subplot(1,3,3)
show_img_target(img_r,mask)
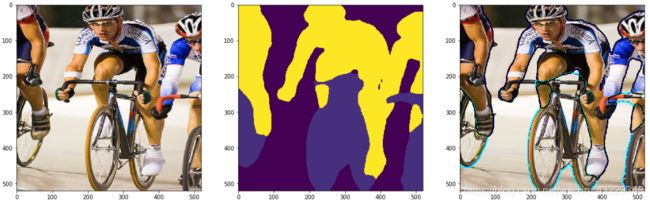
代码解析:
在步骤1中,我们导入了所需的包。在torchvision包中已经实现了deeplabv3_resnet101类。
在步骤2中,我们创建了deeplabv3_resnet101类的一个实例对象。该类的重要输入如下:
- pretrained:如果设置为True,自动下载预训练权重
- num_classes:类别数目(包含背景),对VOC数据集,类别是21
在步骤3中,如果有一个CUDA设备的话,将模型移动到CUDA设备中。
在步骤4中,我们打印了模型。模型很大,所以只显示了模型的一个片段。当您在计算机上执行打印命令时,您应该会在屏幕上看到整个模型.
在步骤5中,我们将模型部署在VOC验证数据集上。正如我们前面提到的,由于模型是在COCO 2017数据集的一个子集上进行预训练的,所以它应该在VOC数据集上表现良好。首先,我们使用.eval()方法设置模型在评估模式下。这是必要的,因为某些层,如dropout层和BN层,在训练和评估阶段实现不同。
在部署模型之前,使用.eval()方法设置模型在评估模式下。
接下来,我们从val_dl数据加载器获取一批数据,并将其提供给模型。好消息是不需要任何预处理。
要将模型部署在VOC数据集之外的单个图像或来自摄像机的图像流上,请确保在将图像输入模型之前对其进行预处理。
如我们所见,模型输出的形状是[batch_size, num_classes, height, width]。换句话说,该模型产生对应21个对象类的21个概率掩码。索引0处的第一个掩码对应于背景,而其余的掩码对应于20个对象。然后,对于每个像素,使用argmax()方法将21个掩模中概率最高的类分配给该像素。
在步骤6中,我们显示了从批数据中提取的样本图像,预测的分割掩模和目标轮廓。如我们所见,预训练模型在勾画物体轮廓方面做得很好。您可以尝试通过更改图像索引n来显示其他图像和预测。
你也可以使用其他分割模型,例如torchvision包中的fcn_resnet50。
定义损失函数
经典的多目标分割损失是交叉熵(CE)损失函数。CE损失是将每个像素的预测值与真实值进行比较。我们将使用torch.nn包中的CrossEntropyLoss类。
为了优化,我们将使用torch.optim.Adam优化器。由于模型是预训练的,所以学习率很小。如果您希望使用随机权重从头开始训练模型,请尝试使用更高的学习率,如3E-4。学习率是一个超参数。通常,您需要尝试一些不同的值,然后才能最终确定其值以获得最佳性能。
在本教程中,您将学习如何为多目标分割定义损失函数、优化器和学习率计划。
#1. 定义损失函数
from torch import nn
criterion=nn.CrossEntropyLoss(reduction="sum")
#2. 定义优化器
from torch import optim
opt=optim.Adam(model.parameters(), lr=1e-6)
#3. 定义一个计算每批次损失的辅助函数
def loss_batch(loss_func, output, target, opt=None):
loss=loss_func(output, target)
if opt is not None:
opt.zero_grad()
loss.backward()
opt.step()
return loss.item(), None
#4. 定义学习率策略
from torch.optim.lr_scheduler import ReduceLROnPlateau
lr_scheduler=ReduceLROnPlateau(opt, mode="min", factor=0.5, patience=20, verbose=1)
# 定义一个获取学习率的辅助函数
def get_lr(opt):
for param_group in opt.param_groups:
return param_group["lr"]
current_lr=get_lr(opt)
print("current lr={}".format(current_lr))
# current lr=1e-6
代码解析
在步骤1中,我们使用了来自torch.nn包中的CrossEntropyLoss损失函数。这个损失函数将nn.LogSoftmax()和nn.NLLLoss()合并为一个类。
由于数值稳定性的原因,PyTorch将softmax函数集成到CrossEnropyLoss损失中,而不是直接将其应用到模型输出中。
注意,我们设置了reduction=“sum”,因为我们想返回每个批数据的损失值之和。
在步骤2中,我们定义了优化器。我们用了torch.optim.Adam优化器。由于模型是预训练的,所以学习率很小。如果您想使用随机权重从头开始训练模型,尝试使用更高的学习率,如3E-4。
在第3步中,我们定义了loss_batch 辅助函数。辅助函数的输入如下:
- loss_func: 在步骤2中定义的损失函数
- output:形状为(batch_size, num_classes, height, width)的预测值
- target:形状为(batch_size,height, width)的真实值
- opt:优化器对象
在这个函数中,我们计算了每批数据的损失值。在训练期间,优化器对象被传递给辅助函数,使用opt.step()更新模型参数。
在步骤4中,我们定义了学习率计划,以便损失在出现平坦时自动降低训练过程中的学习率。
在第5步中,我们定义了一个辅助函数来读取当前的学习率。这将有助于在训练期间监测学习速率。
训练模型
到目前为止,我们已经学习了如何创建训练和验证数据集,建立模型,并定义损失函数和优化器。我们还部署了这个模型,因为它是在一个名为COCO 2017的大型数据集中进行预训练的。有时,我们希望在其他数据集上训练模型,以获得更好的性能。在这种情况下,最好的方法是在新的数据集上以较小的学习率训练模型。这种方法通常被称为模型微调。
训练是一个迭代的过程。在每次迭代中,我们从训练数据集中选择一批数据。然后,我们将数据提供给模型以获得模型输出。然后,我们计算损失值。接下来,我们计算损失函数相对于模型参数(也称为权重)的梯度。最后,优化器根据梯度更新参数。这个循环继续。我们还使用验证数据集在训练期间监控模型的性能。当表现趋于稳定时,我们就会停止训练过程。
在这个教程中,您将学习如何训练VOC数据集上的模型进行多目标分割任务。
#1. 定义loss_epoch辅助函数
def loss_epoch(model, loss_func, dataset_dl, sanity_check=False, opt=None):
running_loss=0.0
len_data=len(dataset_dl.dataset)
for xb, yb in dataset_dl:
xb=xb.to(device)
yb=yb.to(device)
output=model(xb)["out"]
loss_b,metric_b=loss_batch(loss_func,output,yb,opt)
running_loss += loss_b
if sanity_check is True:
break
loss=running_loss/float(len_data)
return loss, None
#2. 定义train_val辅助函数
import copy
def train_val(model, params):
num_epochs=params["num_epochs"]
loss_func=params["loss_func"]
opt=params["optimizer"]
train_dl=params["train_dl"]
val_dl=params["val_dl"]
sanity_check=params["sanity_check"]
lr_scheduler=params["lr_scheduler"]
path2weights=params["path2weights"]
loss_history={
"train":[],
"val":[]
}
best_model_wts=copy.deepcopy(model.state_dict())
best_loss=float("inf")
for epoch in range(num_epoch):
current_lr=get_lr(opt)
print("Epoch {}/{}, current lr={}".format(epoch, num_epochs-1, current_lr))
model.train()
train_loss,_=loss_epoch(model,loss_func,train_dl,sanity_check,opt)
loss_history["train"].append(train_loss)
model.eval()
with torch.no_grad():
val_loss,_=loss_epoch(model,loss_func,val_dl,sanity_check)
loss_history["val"].append(val_loss)
if val_loss < best_loss:
best_loss=val_loss
best_model_wts=copy.deepcopy(model.state_dict())
torch.save(model.state_dict(),path2weights)
print("Copied best model weights")
lr_scheduler.step(val_loss)
if current_lr != get_lr(opt):
print("Loading best model weights!")
model.load_state_dict(best_model_wts)
print("train loss:%.6f"%(train_loss))
print("val loss:%.6f"%(val_loss))
print("-"*10)
model.load_state_dict(best_model_wts)
return model, loss_history, None
#3. 调用train_val训练模型
import os
path2models="./models/"
if not os.path.exists(path2models):
os.mkdir(path2models)
params_train={
"num_epochs":100,
"optimizer":opt,
"loss_func":criterion,
"train_dl":train_dl,
"val_dl":val_dl,
"sanity_check":False,
"lr_scheduler":lr_scheduler,
"path2weights":path2models+"weights.pt",
}
model,loss_hist,_=train_val(model,params_train)
# Epoch 0/99, current lr=1e-06
# Copied best model weights!
# train loss: 88394.663371
# val loss: 60473.278360
# ----------
# Epoch 1/99, current lr=1e-06
# Copied best model weights!
# train loss: 72682.170562
# val loss: 56371.689775
# ...
#4. 训练完成,绘制训练和验证损失进展
num_epochs=params_train["num_epochs"]
plt.title("Train-Val Loss")
plt.plot(range(1,num_epochs+1), loss_hist["train"],label="train")
plt.plot(range(1,num_epochs+1), loss_hist["val"],label="val")
plt.ylabel("Loss")
plt.xlabel("Training Epochs")
plt.legend()
plt.show()
代码解析:
在步骤1中,我们定义了loss_epoch 函数。函数输入如下:
- model:模型对象
- loss_func:损失函数对象
- dataset_dl:数据加载器对象
- sanity_check:默认是False
- opt:优化器对象
在这个函数中,我们从数据加载器中提取批数据作为xb和yb张量。接下来,我们得到模型输出,并计算每批数据的损失值。我们对整个数据集重复这个过程,并返回每个epoch的平均损失值。
在步骤2中,我们定义了train_val函数。函数输入如下:
- model:模型对象
- params:包含训练参数的Python字典
在这个函数中,我们对模型进行num_epochs迭代训练。在每次迭代中,我们将模型设置为train模式,并对模型进行一个epoch的训练。然后,在验证数据集上对模型进行了评估。如果验证结果在每次迭代中得到改进,我们存储模型参数。此外,如果验证性能稳定,我们使用学习率计划来降低学习率。该函数返回经过训练的模型和一个包含每次迭代损失值的字典。
在第3步中,我们在params_train中设置训练参数,并调用train_val函数来训练模型。您可以将sanity_check标志设置为True,以快速执行训练循环的几个迭代,并修复任何可能的错误。还可以根据训练进度更改num_epochs。通常情况下,如果训练很快达到稳定状态,小的num_epochs值就足够了,因为你不会通过做任何额外的训练得到任何改进。
在步骤4中,我们绘制了训练结果和验证损失值,以查看我们在多个epochs的训练进展。