GhostNet: More Features from Cheap Operations
引言
深度卷积神经网络在各种计算机视觉任务上显示出出色的性能,例如图像识别 [30,13],对象检测 [43,444] 和语义分割 [4]。传统的cnn通常需要大量的参数和浮点运算 (FLOPs) 来达到令人满意的精度,例如ResNet-50 [16] 具有大约25.6m的参数,并且需要4.1B FLOPs来处理大小为224 × 224的图像。因此,深度神经网络设计的最新趋势是探索移动设备 (例如智能手机和自动驾驶汽车) 可接受性能的便携式和高效网络架构。

由ResNet-50中的第一残差组生成的一些特征图的可视化,其中用相同颜色的框注释三个相似的特征图对示例。可以通过廉价操作 (用spanners表示) 转换另一个来近似获得该对中的一个特征图。
特征图中的冗余可能是深度神经网络效果好的重要特征。我们没有避免多余的特征图,而是倾向于以经济高效的方式得到它们。
在本文中,我们提出了一种新颖的Ghost模块,通过使用更少的参数来生成更多的特征图。具体来说,深度神经网络中的普通卷积层将分为两部分。第一部分涉及普通卷积,但其总数将受到严格控制。给定第一部分的固有特征图,然后应用一系列简单的线性运算来生成更多的特征图。与香草卷积神经网络相比,在不改变输出特征图的大小的情况下,此模块中所需的参数总数和计算复杂度已降低。基于Ghost模块,我们建立了一个有效的神经体系结构,即GhostNet。我们首先在基准神经体系结构中替换原始的卷积层,以证明重影模块的有效性,然后在几个基准视觉数据集上验证我们的GhostNets的优越性。实验结果表明,所提出的Ghost模块能够降低通用卷积层的计算成本,同时保持相似的识别性能,并且GhostNets可以在移动设备上快速推理的各种任务上超越MobileNetV3 [20] 等最先进的高效深度模型。
相关工作
模型压缩
对于给定的神经网络,模型压缩旨在减少计算,能量和存储成本 [14,48,11,54]。修剪连接 [15,14,50] 切断了神经元之间不重要的连接。通道修剪 [51,18,31,39,59,23,35] 进一步的目标是去除无用的通道,以便在实践中更容易加速。模型量化 [42,24,26] 表示具有离散值的神经网络中的权重或激活,用于压缩和计算加速。具体来说,只有1位值的二值化方法 [24,42,38,45] 可以通过高效的二进制运算极大地加速模型。张量分解 [27,9] 通过利用权重中的冗余和低秩属性来减少参数或计算。知识蒸馏 [19,12,3] 利用较大的模型来教授较小的模型,从而提高了较小模型的性能。这些方法的性能通常取决于给定的预训练模型。对基本操作和体系结构的改进将使它们走得更远。
紧凑型模型设计
随着在嵌入式设备上部署神经网络的需要,近年来提出了一系列紧凑模型 [7,21,44,20,61,40,53,56]。Xception [7] 利用深度卷积运算来更有效地使用模型参数。MobileNets [21] 是一系列基于深度可分离卷积的轻量级深度神经网络。MobileNetV2 [44] 提出了反向残差块,MobileNetV3 [20] 进一步利用AutoML技术 [62、55、10],以更少的触发器实现更好的性能。ShuffleNet [61] 引入了通道混洗操作,以改善通道组之间的信息流交换。ShuffleNetV2 [40] 进一步考虑了目标硬件上的实际速度,以进行紧凑型模型设计。尽管这些模型用很少的FLOPs获得了很好的性能,但特征图之间的相关性和冗余从未得到很好的利用
方法
Ghost Module for More Features
深度卷积神经网络 [30,46,16] 通常由大量卷积组成,从而导致大量的计算成本。尽管最近的工作,如MobileNet [21,44] 和ShuffleNet [40] 已经引入了深度卷积或shuffle操作,以使用较小的卷积滤波器 (浮点数操作) 来构建有效的cnn,但剩余的1 × 1卷积层仍将占据相当大的内存和Flops。
考虑到如图1所示由主流cnn计算的中间特征图中的冗余,我们建议减少所需的资源,即用于生成它们的卷积滤波器。在实践中,给定输入数据X ∈ rc × h × w,其中c是输入通道的数量,h和w分别是输入数据的高度和宽度,用于产生n个特征图的任意卷积层的操作可以公式化为

其中 ∗ 是卷积运算,b是偏置项,Y ∈ rh × w × n是具有n个通道的输出特征图,f ∈ rc × k × n是该层中的卷积滤波器。此外,h 和w 是输出数据的高度和宽度,k × k分别是卷积滤波器f的核大小。在该卷积过程中,所需的FLOPs数量可以计算为nxh xw xcxkxk,由于滤波器数量n和信道数量c通常非常大 (例如256或512),因此通常多达数十万个。

根据公式1 可知,通道的维度c是冗余存在优化的可能。如图1所示,卷积层的输出特征图通常包含很多冗余,并且其中一些可能彼此相似。我们指出,不需要使用大量的Flops和参数逐个生成这些冗余特征图。假设输出特征图是具有少数固有特征图。这些固有特征图通常尺寸较小,并且由普通的卷积滤波器产生。具体来说,使用一次卷积生成m个本征特征图
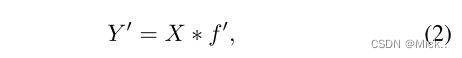
为了进一步获得所需的n个特征图,我们建议对y 中的每个固有特征应用一系列廉价的线性运算,以根据以下函数生成s个重影特征图。

请注意,线性运算 Φ 在每个计算成本比普通卷积小得多的通道上运行。实际上,在模块中可能会有几种不同的线性操作,例如3 × 3和5 × 5线性内核。
与现有方法的区别
Ghost模块与现有的有效卷积方案有很大不同。i) 与 [21,61] 中广泛使用1 × 1点卷积的单元相比,Ghost模块中的主要卷积可以具有自定义的内核大小。ii) 现有方法 [21,44,61,40] 采用逐点卷积处理跨通道的特征,然后采用深度卷积处理空间信息。相反,Ghost模块采用普通卷积首先生成一些固有特征图,然后利用廉价的线性操作来增强特征并增加通道。iii) 处理每个特征图的操作仅限于以前的高效架构 [21,61,53,28] 中的深度卷积或移位操作,而Ghost模块中的线性操作可以具有很大的多样性。iv) 此外,身份映射与Ghost模块中的线性变换并行,以保留固有特征图。
复杂性分析

构建高效的cnn
Ghost Bottlenecks
利用Ghost模块的优点,我们介绍了专门为小型cnn设计的Ghost bottle (G-bneck)。如图3所示,Ghost瓶颈似乎类似于ResNet [16] 中的基本残差块,其中集成了几个卷积层和快捷方式。所提出的幽灵瓶颈主要由两个堆叠的幽灵模块组成。第一个Ghost模块充当增加通道数量的扩展层。我们将输出通道数量与输入通道数量之间的比率称为扩展比率。第二个Ghost模块减少通道数量以匹配快捷路径。然后快捷方式连接在这两个重影模块的输入和输出之间。

GhostNet
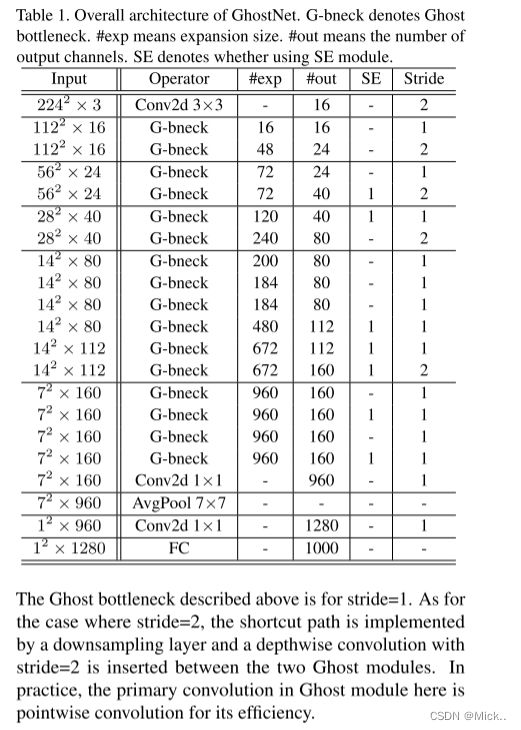
在幽灵瓶颈的基础上,我们提出了GhostNet,如表7所示。我们基本上遵循MobileNetV3 [20] 的体系结构,以获取其优势,并将MobileNetV3中的瓶颈块替换为我们的Ghost瓶颈。GhostNet主要由一堆以Ghost模块为构建块的Ghost瓶颈组成。第一层是带有16个过滤器的标准卷积层,然后跟随一系列逐渐增加通道的glost瓶颈。这些glost瓶颈根据其输入特征图的大小分为不同的阶段。所有重影瓶颈均以stride = 1应用,除了每个阶段的最后一个是stride = 2。最后,利用全局平均池化和卷积层将特征图变换为1280维特征向量,用于最终分类。如表7所示,挤压和激发 (SE) 模块 [22] 也应用于某些重影瓶颈中的残余层。与MobileNetV3相反,由于其较大的延迟,我们不使用硬的非线性函数。尽管进一步的超参数调整或基于自动架构搜索的ghost模块将进一步提高性能,但所提出的体系结构提供了可供参考的基本设计。
宽度倍增器
尽管表7中给定的体系结构已经可以提供低延迟和有保证的准确性,但是在某些情况下,我们可能需要更小,更快的模型或特定任务上的更高准确性。为了根据所需的需求定制网络,我们可以简单地在每一层均匀地将一个因子 α 乘以信道数。这个因子 α 被称为宽度倍增器,因为它可以改变整个网络的宽度。我们用宽度乘数 α 表示GhostNet-α ×。宽度乘数可以将模型大小和计算成本按二次方控制大致为 α2。通常较小的 α 会导致较低的延迟和较低的性能,反之亦然。
代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
__all__ = ['ghost_net']
def _make_divisible(v, divisor, min_value=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
def hard_sigmoid(x, inplace: bool = False):
if inplace:
return x.add_(3.).clamp_(0., 6.).div_(6.)
else:
return F.relu6(x + 3.) / 6.
class SqueezeExcite(nn.Module):
def __init__(self, in_chs, se_ratio=0.25, reduced_base_chs=None,
act_layer=nn.ReLU, gate_fn=hard_sigmoid, divisor=4, **_):
super(SqueezeExcite, self).__init__()
self.gate_fn = gate_fn
reduced_chs = _make_divisible((reduced_base_chs or in_chs) * se_ratio, divisor)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv_reduce = nn.Conv2d(in_chs, reduced_chs, 1, bias=True)
self.act1 = act_layer(inplace=True)
self.conv_expand = nn.Conv2d(reduced_chs, in_chs, 1, bias=True)
def forward(self, x):
x_se = self.avg_pool(x)
x_se = self.conv_reduce(x_se)
x_se = self.act1(x_se)
x_se = self.conv_expand(x_se)
x = x * self.gate_fn(x_se)
return x
class ConvBnAct(nn.Module):
def __init__(self, in_chs, out_chs, kernel_size,
stride=1, act_layer=nn.ReLU):
super(ConvBnAct, self).__init__()
self.conv = nn.Conv2d(in_chs, out_chs, kernel_size, stride, kernel_size//2, bias=False)
self.bn1 = nn.BatchNorm2d(out_chs)
self.act1 = act_layer(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn1(x)
x = self.act1(x)
return x
class GhostModule(nn.Module):
def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True):
super(GhostModule, self).__init__()
self.oup = oup
init_channels = math.ceil(oup / ratio)
new_channels = init_channels*(ratio-1)
self.primary_conv = nn.Sequential(
nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size//2, bias=False),
nn.BatchNorm2d(init_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
self.cheap_operation = nn.Sequential(
nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size//2, groups=init_channels, bias=False),
nn.BatchNorm2d(new_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
def forward(self, x):
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
out = torch.cat([x1,x2], dim=1)
return out[:,:self.oup,:,:]
class GhostBottleneck(nn.Module):
""" Ghost bottleneck w/ optional SE"""
def __init__(self, in_chs, mid_chs, out_chs, dw_kernel_size=3,
stride=1, act_layer=nn.ReLU, se_ratio=0.):
super(GhostBottleneck, self).__init__()
has_se = se_ratio is not None and se_ratio > 0.
self.stride = stride
# Point-wise expansion
self.ghost1 = GhostModule(in_chs, mid_chs, relu=True)
# Depth-wise convolution
if self.stride > 1:
self.conv_dw = nn.Conv2d(mid_chs, mid_chs, dw_kernel_size, stride=stride,
padding=(dw_kernel_size-1)//2,
groups=mid_chs, bias=False)
self.bn_dw = nn.BatchNorm2d(mid_chs)
# Squeeze-and-excitation
if has_se:
self.se = SqueezeExcite(mid_chs, se_ratio=se_ratio)
else:
self.se = None
# Point-wise linear projection
self.ghost2 = GhostModule(mid_chs, out_chs, relu=False)
# shortcut
if (in_chs == out_chs and self.stride == 1):
self.shortcut = nn.Sequential()
else:
self.shortcut = nn.Sequential(
nn.Conv2d(in_chs, in_chs, dw_kernel_size, stride=stride,
padding=(dw_kernel_size-1)//2, groups=in_chs, bias=False),
nn.BatchNorm2d(in_chs),
nn.Conv2d(in_chs, out_chs, 1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_chs),
)
def forward(self, x):
residual = x
# 1st ghost bottleneck
x = self.ghost1(x)
# Depth-wise convolution
if self.stride > 1:
x = self.conv_dw(x)
x = self.bn_dw(x)
# Squeeze-and-excitation
if self.se is not None:
x = self.se(x)
# 2nd ghost bottleneck
x = self.ghost2(x)
x += self.shortcut(residual)
return x
class GhostNet(nn.Module):
def __init__(self, cfgs, num_classes=1000, width=1.0, dropout=0.2):
super(GhostNet, self).__init__()
# setting of inverted residual blocks
self.cfgs = cfgs
self.dropout = dropout
# building first layer
output_channel = _make_divisible(16 * width, 4)
self.conv_stem = nn.Conv2d(3, output_channel, 3, 2, 1, bias=False)
self.bn1 = nn.BatchNorm2d(output_channel)
self.act1 = nn.ReLU(inplace=True)
input_channel = output_channel
# building inverted residual blocks
stages = []
block = GhostBottleneck
for cfg in self.cfgs:
layers = []
for k, exp_size, c, se_ratio, s in cfg:
output_channel = _make_divisible(c * width, 4)
hidden_channel = _make_divisible(exp_size * width, 4)
layers.append(block(input_channel, hidden_channel, output_channel, k, s,
se_ratio=se_ratio))
input_channel = output_channel
stages.append(nn.Sequential(*layers))
output_channel = _make_divisible(exp_size * width, 4)
stages.append(nn.Sequential(ConvBnAct(input_channel, output_channel, 1)))
input_channel = output_channel
self.blocks = nn.Sequential(*stages)
# building last several layers
output_channel = 1280
self.global_pool = nn.AdaptiveAvgPool2d((1, 1))
self.conv_head = nn.Conv2d(input_channel, output_channel, 1, 1, 0, bias=True)
self.act2 = nn.ReLU(inplace=True)
self.classifier = nn.Linear(output_channel, num_classes)
def forward(self, x):
x = self.conv_stem(x)
x = self.bn1(x)
x = self.act1(x)
x = self.blocks(x)
x = self.global_pool(x)
x = self.conv_head(x)
x = self.act2(x)
x = x.view(x.size(0), -1)
if self.dropout > 0.:
x = F.dropout(x, p=self.dropout, training=self.training)
x = self.classifier(x)
return x
def ghostnet(**kwargs):
"""
Constructs a GhostNet model
"""
cfgs = [
# k, t, c, SE, s
# stage1
[[3, 16, 16, 0, 1]],
# stage2
[[3, 48, 24, 0, 2]],
[[3, 72, 24, 0, 1]],
# stage3
[[5, 72, 40, 0.25, 2]],
[[5, 120, 40, 0.25, 1]],
# stage4
[[3, 240, 80, 0, 2]],
[[3, 200, 80, 0, 1],
[3, 184, 80, 0, 1],
[3, 184, 80, 0, 1],
[3, 480, 112, 0.25, 1],
[3, 672, 112, 0.25, 1]
],
# stage5
[[5, 672, 160, 0.25, 2]],
[[5, 960, 160, 0, 1],
[5, 960, 160, 0.25, 1],
[5, 960, 160, 0, 1],
[5, 960, 160, 0.25, 1]
]
]
return GhostNet(cfgs, **kwargs)
if __name__=='__main__':
model = ghostnet()
model.eval()
print(model)
input = torch.randn(32,3,320,256)
y = model(input)
print(y.size())参考文献:
huawei-noah/Efficient-AI-Backbones: Efficient AI Backbones including GhostNet, TNT and MLP, developed by Huawei Noah's Ark Lab. (github.com)