目标检测算法——YOLOv5/YOLOv7改进之结合GAMAttention
目录
超越CBAM,全新注意力GAM:不计成本提高精度!
(一)前沿介绍
1.GAM结构图
2.相关实验结果
(二)YOLOv5/YOLOv7改进之结合GAMAttention
1.配置common.py文件
2.配置yolo.py文件
3.配置yolov5_GAM.yaml文件
超越CBAM,全新注意力GAM:不计成本提高精度!
(一)前沿介绍
论文题目:Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions
论文地址:https://paperswithcode.com/paper/global-attention-mechanism-retain-information

作者设计一种减少信息缩减并放大全局维度交互特征的机制,采用了CBAM中的顺序通道-空间注意机制,并对子模块进行了重新设计,具体结构如下图所示。实验结果表明,GAM能够稳定地提高不同架构和深度的CNN的性能,具有良好的数据拓展能力和鲁棒性。
1.GAM结构图
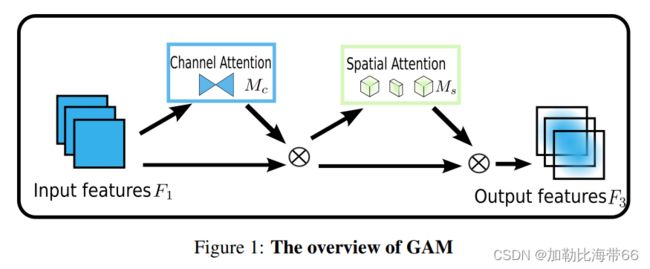
2.相关实验结果
对ImageNet-1K的评估如表2所示,它表明GAM可以稳定地提高不同神经体系结构的性能。特别是,对于ResNet18,GAM的性能优于ABN,参数更少,效率更高。

为了更好地理解空间注意和通道注意分别对消融的贡献,我们通过开启和关闭一种方式进行了消融研究。例如,ch表示空间注意力被关闭,而频道注意力被打开。SP表示通道关注已关闭,空间关注已打开。结果如表3所示。我们可以在两个开关实验中观察到性能的提高。结果表明,空间关注度和通道关注度对性能增益均有贡献。请注意,它们的组合进一步提高了性能。

将GAM与CBAM在使用和不使用ResNet18最大池化的情况下进行比较。表4显示了结果。可以观察到,在这两种情况下,我们的方法都优于CBAM。

(二)YOLOv5/YOLOv7改进之结合GAMAttention
改进方法和其他注意力机制一样,分三步走:
1.配置common.py文件
加入GAM代码。
#GAM
class GAM(nn.Module):
def __init__(self, c1, c2, group=True, rate=4):
super(GAM, self).__init__()
self.channel_attention = nn.Sequential(
nn.Linear(c1, int(c1 / rate)),
nn.ReLU(inplace=True),
nn.Linear(int(c1 / rate), c1)
)
self.spatial_attention = nn.Sequential(
nn.Conv2d(c1, c1 // rate, kernel_size=7, padding=3, groups=rate) if group else nn.Conv2d(c1, int(c1 / rate),
kernel_size=7,
padding=3),
nn.BatchNorm2d(int(c1 / rate)),
nn.ReLU(inplace=True),
nn.Conv2d(c1 // rate, c2, kernel_size=7, padding=3, groups=rate) if group else nn.Conv2d(int(c1 / rate), c2,
kernel_size=7,
padding=3),
nn.BatchNorm2d(c2)
)
def forward(self, x):
b, c, h, w = x.shape
x_permute = x.permute(0, 2, 3, 1).view(b, -1, c)
x_att_permute = self.channel_attention(x_permute).view(b, h, w, c)
x_channel_att = x_att_permute.permute(0, 3, 1, 2)
x = x * x_channel_att
x_spatial_att = self.spatial_attention(x).sigmoid()
x_spatial_att = channel_shuffle(x_spatial_att, 4) # last shuffle
out = x * x_spatial_att
return out
def channel_shuffle(x, groups=2): ##shuffle channel
B, C, H, W = x.size()
out = x.view(B, groups, C // groups, H, W).permute(0, 2, 1, 3, 4).contiguous()
out = out.view(B, C, H, W)
return out2.配置yolo.py文件
加入GAM模块。
#GAM
elif m is GAM:
c1, c2 = ch[f], args[0]
if c2 != no:
c2 = make_divisible(c2 * gw, 8)3.配置yolov5_GAM.yaml文件
添加方法灵活多变,Backbone或者Neck都可。示例如下:
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, C3, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 5], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 3], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 3, GAM, [256,256]], #18
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 3, GAM, [512,512]],
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[-1, 3, GAM, [1024,1024]],
[[18, 22, 26], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]