数据分析---基于pandas的数据清洗
一、处理丢失的数据(删除所在行或列、覆盖)
- 原始数据中可能存在两种缺失值(空值): 可能会产生重复值和异常值。
- 有两种缺失数据: None 和 np.nan(NaN)
- 两种丢失数据的区别: 两种数据的类型不同,None是对象类型(Nonetype),np.nan是float类型。
- 因此在数据分析中需要用浮点类型np.nan,可以对该空值进行算术运算且不报错,不会干扰、中断对原始数据的运算。NaN可以参与运算,None不可以参与运算。
- 在pandas中如果遇到None形式的空值,则pandas会将其强制转化为NaN形式。
import pandas as pd
from pandas import DataFrame,Series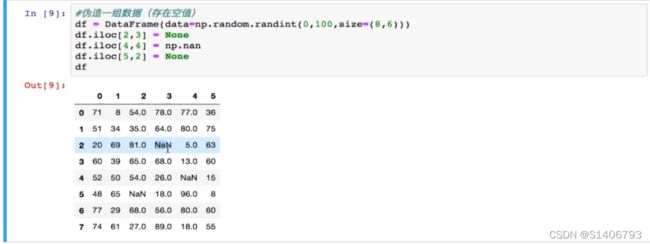
(1)方式一:对空值进行过滤(删除空所在的行数据)
- isnull : 是否存在空值,True对应空值;和any搭配
- notnull : False对应空值;和all搭配
- any :检测行或者列中是否存在True,只要存在一个True就返回True
- all :如果一行中全为 True就返回True,只要有一个False就返回False
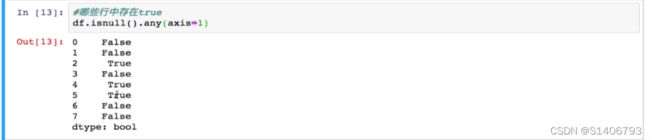
使用方法一,我们首先要知道哪些行存在空值,以isnull为例,哪些行存在True 。用any来检测行或者列中是否存在True;
将这组bool值作为源数据的行索引,得到那些满足条件的行数据;
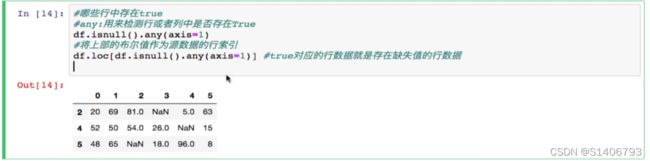
拿到这些数据的行索引,这些行就是我们将要删除的行索引;
![]()
删除这些行就得到了清洗之后的数据 。
以notnull为例_flase代表空值,用all检测哪些行存在缺失值。
(2)方法二:dropna(直接删除缺失值所在行或列)
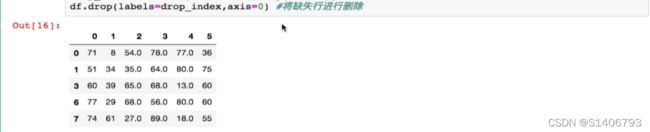
可以直接将缺失的行或者列进行删除,drop中axis的用法相反,axis=0为行

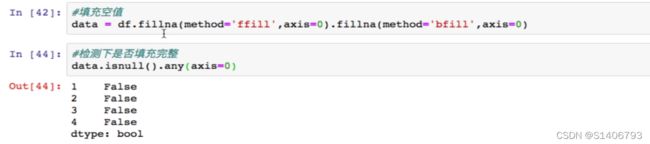
(3)方法三:对缺失值进行覆盖:fillna
当删除的成本太高的时候选择覆盖,一般情况下用旁边的值进行覆盖。
- df.fillna(value=666) #用value值覆盖所有的空值;意义不大
- df.fillna( method=‘ffill’,axis=0) #ffill表示向前填充,axis=0用上一列值覆盖空值
- df.fillna(method='bfill',axis=1) #bfill表示向后填充,axis=1用前一行的数据覆盖空值。

面试题

预估5-7对应的数据需要机器学习,暂时不看。源数据的删除成本不高。

dropna和notnull拿到的数据一样。![]()
也可以做覆盖fillna :
这里先向前填充一次,但是如果前一个值也是空值,那么处理后的数据仍然含有空值,所以再向后填充一次
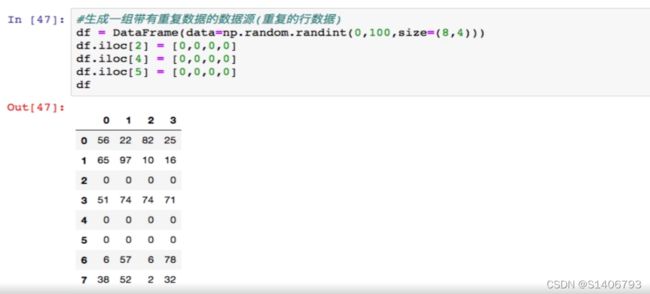
二、处理重复数据
df.drop_duplicates(keep='last') #直接删除重复数据的行,保留最后一行;first保留第一行
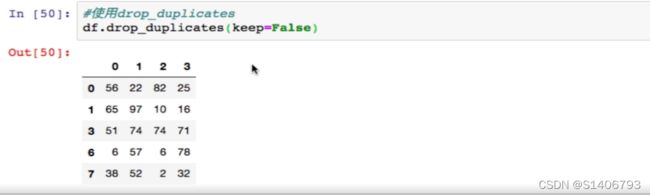
df.drop_duplicates(keep=False) #把所有重复行数据都删除
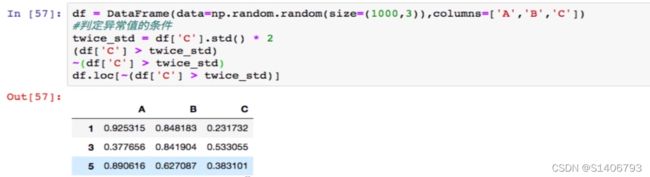
三、处理异常数据
![]()

首先要判断异常值的条件,计算C列的两倍标准差: df['C'].std() * 2
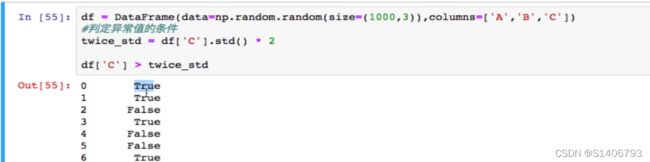
True表示异常值,那么把该布尔值作为源数据的行索引只能保留True的数据(将要删除的),那么需要对bool值进行取反,得到的数据就是删除了异常值的数据。