汽车产品聚类分析(分析向)
目录
1. 项目介绍
2. 使用工具
3. 项目分析
3.1 原数据查看、清洗
3.2 数据处理
3.3 数据降维
3.4 聚类分析
3.5 详细聚类结果提取
1. 项目介绍
数据car_price.csv包括了205款车的26个字段,以竞品分析为背景,通过数据的聚类,为汽车提供聚类分类。对于指定的车型,可以通过聚类分析找到其竞品车型。通过这道赛题,鼓励学习者利用车型数据,进行车型画像的分析,为产品的定位,竞品分析提供数据决策。
数据来源【教学赛】数据分析达人赛3:汽车产品聚类分析赛题与数据-天池大赛-阿里云天池 (aliyun.com) https://tianchi.aliyun.com/competition/entrance/531892/information
https://tianchi.aliyun.com/competition/entrance/531892/information
2. 使用工具
- 环境——Python3
- 相关方法——独热编码(One Hot Encoder)、数据归一化min-max标准化(Min-Max Normalization)、PCA降维、聚类分析K-Means(基于欧式距离的聚类算法)
3. 项目分析
3.1 原数据查看、清洗
导入需要的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.decomposition import PCA
from sklearn.preprocessing import MinMaxScaler
import difflib as dl #读取数据
data = pd.read_csv('car_price.csv')
#查看数据大小
print(data.shape)
#查看数据大致情况
data.head()
(205, 26)
#是否有重复值,一般也是没有的
data.duplicated().sum()
0
# 查看数据的空值与类型情况
data.info()
RangeIndex: 205 entries, 0 to 204
Data columns (total 26 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 car_ID 205 non-null int64
1 symboling 205 non-null int64
2 CarName 205 non-null object
3 fueltype 205 non-null object
4 aspiration 205 non-null object
5 doornumber 205 non-null object
6 carbody 205 non-null object
7 drivewheel 205 non-null object
8 enginelocation 205 non-null object
9 wheelbase 205 non-null float64
10 carlength 205 non-null float64
11 carwidth 205 non-null float64
12 carheight 205 non-null float64
13 curbweight 205 non-null int64
14 enginetype 205 non-null object
15 cylindernumber 205 non-null object
16 enginesize 205 non-null int64
17 fuelsystem 205 non-null object
18 boreratio 205 non-null float64
19 stroke 205 non-null float64
20 compressionratio 205 non-null float64
21 horsepower 205 non-null int64
22 peakrpm 205 non-null int64
23 citympg 205 non-null int64
24 highwaympg 205 non-null int64
25 price 205 non-null float64
dtypes: float64(8), int64(8), object(10)
memory usage: 41.8+ KB
#查看描述统计信息
print(data.describe()) car_ID symboling wheelbase carlength carwidth carheight \
count 205.000000 205.000000 205.000000 205.000000 205.000000 205.000000
mean 103.000000 0.834146 98.756585 174.049268 65.907805 53.724878
std 59.322565 1.245307 6.021776 12.337289 2.145204 2.443522
min 1.000000 -2.000000 86.600000 141.100000 60.300000 47.800000
25% 52.000000 0.000000 94.500000 166.300000 64.100000 52.000000
50% 103.000000 1.000000 97.000000 173.200000 65.500000 54.100000
75% 154.000000 2.000000 102.400000 183.100000 66.900000 55.500000
max 205.000000 3.000000 120.900000 208.100000 72.300000 59.800000
curbweight enginesize boreratio stroke compressionratio \
count 205.000000 205.000000 205.000000 205.000000 205.000000
mean 2555.565854 126.907317 3.329756 3.255415 10.142537
std 520.680204 41.642693 0.270844 0.313597 3.972040
min 1488.000000 61.000000 2.540000 2.070000 7.000000
25% 2145.000000 97.000000 3.150000 3.110000 8.600000
50% 2414.000000 120.000000 3.310000 3.290000 9.000000
75% 2935.000000 141.000000 3.580000 3.410000 9.400000
max 4066.000000 326.000000 3.940000 4.170000 23.000000
horsepower peakrpm citympg highwaympg price
count 205.000000 205.000000 205.000000 205.000000 205.000000
mean 104.117073 5125.121951 25.219512 30.751220 13276.710571
std 39.544167 476.985643 6.542142 6.886443 7988.852332
min 48.000000 4150.000000 13.000000 16.000000 5118.000000
25% 70.000000 4800.000000 19.000000 25.000000 7788.000000
50% 95.000000 5200.000000 24.000000 30.000000 10295.000000
75% 116.000000 5500.000000 30.000000 34.000000 16503.000000
max 288.000000 6600.000000 49.000000 54.000000 45400.000000
项目的目的是寻找出vokswagen(大众汽车)品牌的对应竞品,汽车名字在CarName中,需要提取出来。并且有些名字有错误。提取汽车品牌名,只要第一列
carbrand = data['CarName'].str.split(expand=True)[0]
print(set(carbrand))#名字情况
print('名字情况——',carbrand.unique())
#把无效的汽车ID删除
data = data.drop(['car_ID'],axis=1)
data.head()
这里使用difflib文本差异对比库找出不正确的名字
error_list = []
for i in set(carbrand):
for j in set(carbrand):
X = dl.SequenceMatcher(a = i, b = j).quick_ratio()
if X > 0.7 and X < 1: #结果测试设定为0.7以上最合适
error_list.append(i)
error_list.append(j)
error_brand = pd.DataFrame(error_list)
error_brand = error_brand[error_brand.duplicated()].reset_index(drop = True)
print(error_brand)0 0 maxda 1 mazda 2 toyota 3 toyouta 4 porcshce 5 porsche 6 nissan 7 Nissan 8 volkswagen 9 vokswagen
名称修正
new_name = {'Nissan':'nissan','maxda':'mazda','toyouta':'toyota','vokswagen':'volkswagen','vw':'volkswagen','porcshce':'porsche'}
carbrand = carbrand.replace(new_name)
print(set(carbrand))
#正确的名字替换进去
data['CarName'] = carbrand
data.head()
3.2 数据处理
需要将数据转化为可识别的数值类型,看情况数据情况为类别,类别数量也不是很多。这里采用独热编码(One Hot Encoder)。用pandas里面的get_dummies方法。
这里先复制一份,用来去掉暂时用不到的CarName 。
data1 = data.copy()
data1 = data1.drop(['CarName'],axis=1)
#提取字符类型
car_object = data1.select_dtypes(include='object').columns
#转化
car_data = pd.concat([data1.drop(car_object,axis=1),pd.get_dummies(data1[car_object])],axis=1) # 按照列拼接
car_data.head()
为了提升模型的速度与精度,将数据归一化,这里采用min-max标准化(Min-Max Normalization)
car_data = pd.DataFrame(MinMaxScaler().fit_transform(car_data))
car_data.head()
3.3 数据降维
因为独热编码处理,维度较多,需要结合PCA降维。对于n_components要选择多少,降维后保留的特征的数目,这里采用可视化获取可解释性方差的贡献率来选取。
pca = PCA()
pca_data = pca.fit(car_data)
pca_var_ratio = pca.explained_variance_ratio_
pca_cumsum_var_ratio = np.cumsum(pca.explained_variance_ratio_)
#选取特征数目的增加,获取原始数据的信息也会随之增加
list1 = list(range(1,53+1))
plt.plot(list1, pca_cumsum_var_ratio* 100) #
plt.xlabel('The number of features after dimension')
plt.ylabel('The sum of explained_variance_ratio_')
plt.show()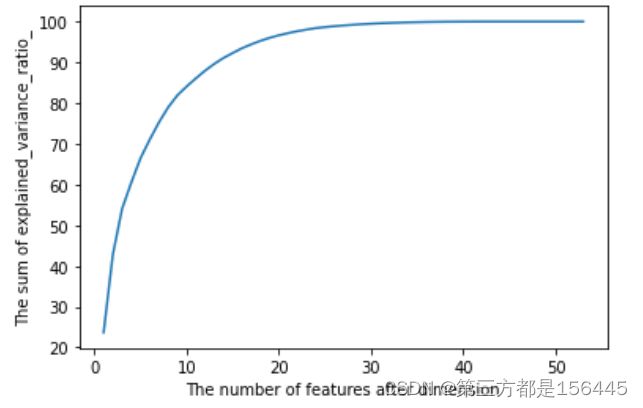
为了具体确定多少维度,为了不主观选择,这里选择大于90%的方差性解释。
pca = PCA(n_components=0.9)
pca_car_data = pca.fit_transform(car_data)
pca_var_ratio1 = pca.explained_variance_ratio_
print(pca_car_data)
print(sum(pca_var_ratio1))
print(pca.n_components_)[[ 0.62663242 1.26857717 -0.25429826 ... -0.16575793 -0.59764184 0.31190006] [ 0.63834831 1.27162601 -0.25419496 ... -0.16783075 -0.58829481 0.31747487] [ 0.91042674 1.69024806 -0.2630416 ... 0.06211814 0.04592683 -0.51016574] ... [ 1.82460158 -0.08240348 -0.84712439 ... -0.113876 0.24725055 -0.35836385] [ 1.49431335 -1.01817521 1.69100053 ... 0.27315214 -0.01560505 -0.18447697] [ 1.29111955 -0.58546888 0.33354861 ... 0.11555268 0.0867841 -0.04556614]] 0.9108363907594454 14
3.4 聚类分析
维度确定为14。维度选定后开始进行k-means聚类。确定聚类簇的个数,有多种方法、这里用手肘法探查一下。
SSE = []
for i in range(1,15):
kmeans = KMeans(n_clusters=i,random_state=2022)
kmeans.fit(pca_car_data)
SSE.append(kmeans.inertia_)
X = range(1,15)
plt.plot(X,SSE,'o-')
plt.xlabel('k')
plt.ylabel('SSE')
plt.show()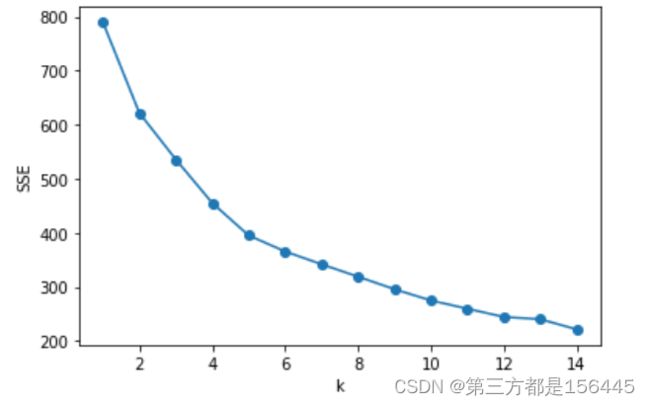
拐点确定为6点处,确定簇的数量为6。
chu = KMeans(n_clusters=6,random_state=2022)
label1 = chu.fit_predict(pca_car_data)+1
#生成相应的标签
# label1 = chu.predict(pca_car_data)
print(label1)
# 将聚合后的类并列到对应的原数据中
data_label = data.copy()
data_label.insert(2,'label',label1)
#data_label['label'] = label1
#把原来的汽车名字一栏再弄回来。之前修改是为了方便后面对应品牌名称匹配
x = pd.read_csv('car_price.csv')
#data_label['oldcarname'] = x['CarName']
data_label.insert(3,'oldcarname',x['CarName'])
data_label.head() 
在簇划分的基础之上,可根据特征列找出volkswagen车型对应的标签
volkswagen_data = data_label[[i.find('volkswagen')==0 for i in data_label['CarName']]][['CarName','carbody','oldcarname','label','price','horsepower','peakrpm', 'compressionratio','citympg','highwaympg']]
volkswagen_data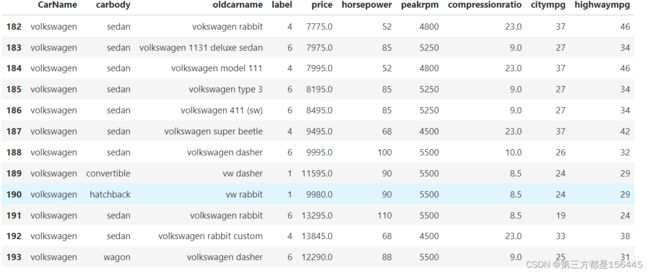
3.5 详细聚类结果提取
可知volkswagen的簇有1、4、6三个。由上表可再对车型具体划分,可以分为轿车(sedan),货车(wagon),活动顶篷式汽车(convertible),掀背式汽车(hatchback)。
对各聚类竞品具体查看分析。先查看分类1的。根据上表,可以看出1类的volkswagen牌车型(carbody)有两种——掀背式汽车(hatchback),活动顶篷式汽车(convertible)。剩下的都是轿车(sedan)和货车(wagon)
对各簇调出具体情况,可以为做更加进一步的分析做准备 。
label_1_shape = data_label.loc[data_label['label'].isin([1])]
label_1_shape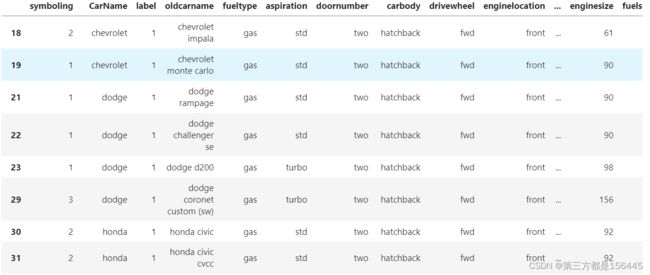
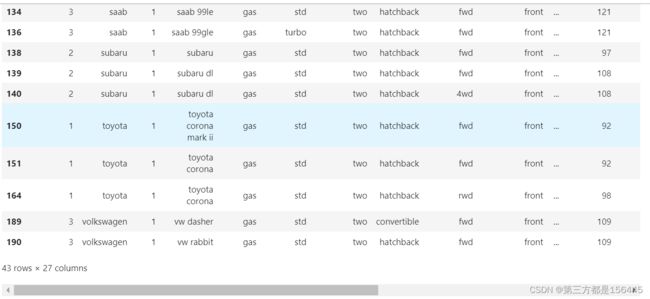
对1类的品牌名称去重,查看详细情况
label_1_name = data_label.loc[data_label['label'].isin([1])]['CarName'].unique().tolist()
label_1_name.remove('volkswagen')
print('去重的总品牌情况\n',label_1_name)
print('\n一共有',len(label_1_name),'种\n')
print('原名称情况\n',data_label.loc[data_label['label'].isin([1])]['oldcarname'].unique().tolist())去重的总品牌情况 ['chevrolet', 'dodge', 'honda', 'mazda', 'mitsubishi', 'nissan', 'plymouth', 'renault', 'saab', 'subaru', 'toyota'] 一共有 11 种 原名称情况 ['chevrolet impala', 'chevrolet monte carlo', 'dodge rampage', 'dodge challenger se', 'dodge d200', 'dodge coronet custom (sw)', 'honda civic', 'honda civic cvcc', 'honda accord cvcc', 'honda accord', 'honda civic 1300', 'maxda rx3', 'maxda glc deluxe', 'mazda rx2 coupe', 'mazda 626', 'mazda glc custom', 'mitsubishi mirage', 'mitsubishi lancer', 'mitsubishi outlander', 'mitsubishi g4', 'mitsubishi mirage g4', 'nissan juke', 'nissan clipper', 'plymouth fury iii', 'plymouth cricket', 'renault 5 gtl', 'saab 99e', 'saab 99le', 'saab 99gle', 'subaru', 'subaru dl', 'toyota corona mark ii', 'toyota corona', 'vw dasher', 'vw rabbit']
调取4簇的情况
#调取4簇的情况
label_4_shape = data_label.loc[data_label['label'].isin([4])]
label_4_shape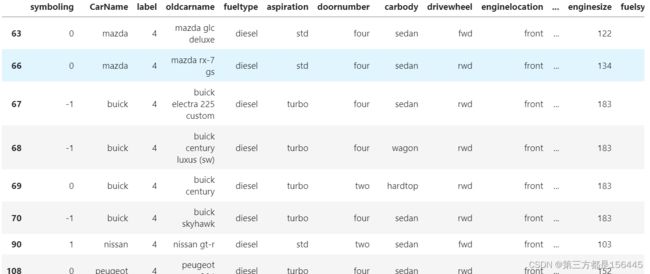
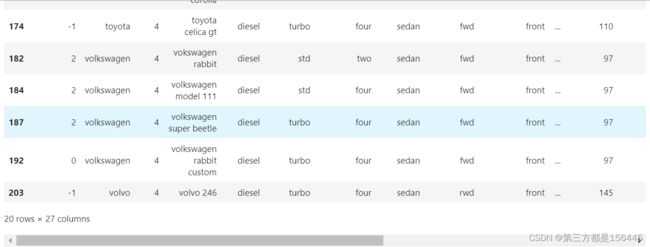
对4类的品牌名称去重,查看详细情况
label_4_name = data_label.loc[data_label['label'].isin([4])]['CarName'].unique().tolist()
label_4_name.remove('volkswagen')
print('去重的总品牌情况\n',label_4_name)
print('\n一共有',len(label_4_name),'种\n')
print('原名称情况\n',data_label.loc[data_label['label'].isin([4])]['oldcarname'].unique().tolist())去重的总品牌情况 ['mazda', 'buick', 'nissan', 'peugeot', 'toyota', 'volvo'] 一共有 6 种 原名称情况 ['mazda glc deluxe', 'mazda rx-7 gs', 'buick electra 225 custom', 'buick century luxus (sw)', 'buick century', 'buick skyhawk', 'nissan gt-r', 'peugeot 304', 'peugeot 504', 'peugeot 604sl', 'peugeot 505s turbo diesel', 'toyota corona', 'toyota corolla', 'toyota celica gt', 'vokswagen rabbit', 'volkswagen model 111', 'volkswagen super beetle', 'volkswagen rabbit custom', 'volvo 246']
调取6簇的情况
label_6_shape = data_label.loc[data_label['label'].isin([6])]
label_6_shape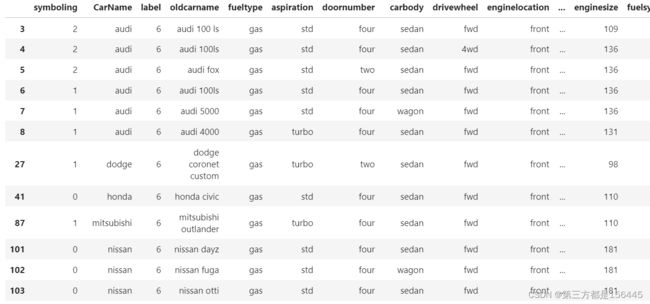
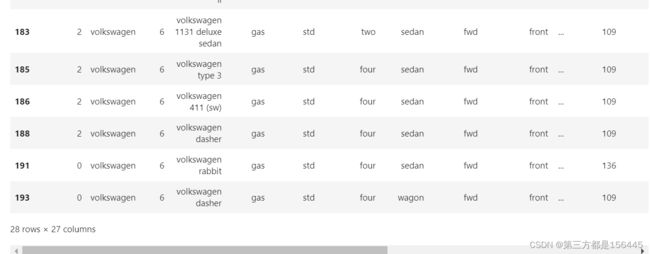
对6类的品牌名称去重,查看详细情况
label_6_name = data_label.loc[data_label['label'].isin([6])]['CarName'].unique().tolist()
label_6_name.remove('volkswagen')
print('去重的总品牌情况\n',label_6_name)
print('\n一共有',len(label_6_name),'种\n')
print('原名称情况\n',data_label.loc[data_label['label'].isin([6])]['oldcarname'].unique().tolist())去重的总品牌情况 ['audi', 'dodge', 'honda', 'mitsubishi', 'nissan', 'renault', 'saab', 'subaru', 'toyota'] 一共有 9 种 原名称情况 ['audi 100 ls', 'audi 100ls', 'audi fox', 'audi 5000', 'audi 4000', 'dodge coronet custom', 'honda civic', 'mitsubishi outlander', 'nissan dayz', 'nissan fuga', 'nissan otti', 'renault 12tl', 'saab 99le', 'saab 99gle', 'saab 99e', 'subaru baja', 'subaru tribeca', 'toyota corolla', 'toyota corona', 'toyota mark ii', 'volkswagen 1131 deluxe sedan', 'volkswagen type 3', 'volkswagen 411 (sw)', 'volkswagen dasher', 'volkswagen rabbit']
[ ]: