字节跳动面试经验 php,记一道字节跳动的算法面试题
点击蓝色“五分钟学算法”关注我哟
cache了,就是读到了旧数据;CPU写数据到内存时,如果只是先写到了cache,则内存里的数据就是旧数据了。这两种情况(两个方向)都存在cache一致性问题。例如,网卡发包的时候,CPU将数据写到c
加个“星标”,天天中午 12:15,一起学算法
size_tcount,loff_t*f_pos){unsignedlongtime_left;//structdma_data*dma=filp->private_data;DBG(

作者 | 帅地
答这道题的难点在于,是从链表的尾部开始组起的,而不是从链表的头部,如果是头部的话,那我们还是比较容易做的,因为你可以遍历链表,每遍历k个就拆分为一组来逆序。但是从尾部的话就不一样了,因为是单链表,不能
来源公众号 | 苦逼的码农
映射和流式映射”。我觉得说的不太对,对于缓存区保留时间到长短来分区两种映射有失偏见,这只能算是他们表现出来到现象。当然,我也从网上找到了一些比较靠谱到说法:CPU写内存的时候有两种方式:writeth
前几天有个朋友去面试字节跳动,面试官问了他一道链表相关的算法题,不过他一时之间没做出来,就来问了我一下,感觉这道题还不错,拿来讲一讲。
的码农前几天有个朋友去面试字节跳动,面试官问了他一道链表相关的算法题,不过他一时之间没做出来,就来问了我一下,感觉这道题还不错,拿来讲一讲。题目这其实是一道变形的链表反转题,大致描述如下给定一个单链表
题目
这其实是一道变形的链表反转题,大致描述如下
;linux/dma/sunxi-dma.h>#include#include#include
给定一个单链表的头节点 head,实现一个调整单链表的函数,使得每K个节点之间为一组进行逆序,并且从链表的尾部开始组起,头部剩余节点数量不够一组的不需要逆序。(不能使用队列或者栈作为辅助)
ngle(rx_chan,dma_dest,BUF_SIZE,DMA_DEV_TO_MEM,DMA_PREP_INTERRUPT|DMA_CTRL_ACK);if(!dma_desc_r
例如:链表:1->2->3->4->5->6->7->8->null, K = 3。那么 6->7->8,3->4->5,1->2各位一组。调整后:1->2->5->4->3->8->7->6->null。其中 1,2不调整,因为不够一组。
irection=DMA_DEV_TO_MEM;ret=dmaengine_slave_config(dma->rx_chan,&dma_rx_sconfig);if(ret<
解答
这道题的难点在于,是从链表的尾部开始组起的,而不是从链表的头部,如果是头部的话,那我们还是比较容易做的,因为你可以遍历链表,每遍历 k 个就拆分为一组来逆序。但是从尾部的话就不一样了,因为是单链表,不能往后遍历组起。
engine.h>#include#include#include
不过这道题肯定是用递归比较好做,对递归不大懂的建议看我之前写的一篇文章为什么你学不会递归?告别递归,谈谈我的一些经验,这篇文章写了关于递归的一些套路。
先做一道类似的反转题
在做这道题之前,我们不仿先来看看如果从头部开始组起的话,应该怎么做呢?例如:链表:1->2->3->4->5->6->7->8->null, K = 3。调整后:3->2->1->6->5->4->7->8->null。其中 7,8不调整,因为不够一组。
e solve(ListNode head, int k) { // 调用逆序函数 head = reverse(head); // 调用每 k 个为一组的逆序函数(从头部开始组起)
对于这道题,如果你不知道怎么逆序一个单链表,那么可以看一下我之前写的如何优雅着反转单链表
这道题我们可以用递归来实现,假设方法reverseKNode()的功能是将单链表的每K个节点之间逆序(从头部开始组起的哦);reverse()方法的功能是将一个单链表逆序。
uf,0,BUF_SIZE);memset(dma->tx_buf,6,BUF_SIZE);//Setup2dma_tx_sconfig.dst_addr=virt_to_phys(vir
那么对于下面的这个单链表,其中 K = 3。
ma_len()这两个宏来得到mapping后的dma地址和长度DMA流式映射需要定义方向:DMA_TO_DEVICE数据从内存传输到设备。DMA_FROM_DEVICE数据从设备传输到内存。DMA_
我们把前K个节点与后面的节点分割出来:
难点在于,是从链表的尾部开始组起的,而不是从链表的头部,如果是头部的话,那我们还是比较容易做的,因为你可以遍历链表,每遍历k个就拆分为一组来逆序。但是从尾部的话就不一样了,因为是单链表,不能往后遍历组
;u8*virt_tmp_buf;ret=misc_register(&misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_d
;}return0;}staticssize_trecv_dma(structfile*filp,char__user*buf,size_tcount,loff_t*f_pos){unsigne
分优化硬件的性能。DMA一致性映射使用cpu_addr=dma_alloc_coherent(dev,size,&dma_handle,gfp)请一块缓冲区…DMA流式映射有两种map/umm
}//Setup1dma_cap_zero(mask_tx);dma_cap_set(DMA_SLAVE,mask_tx);dma->tx_chan=dma_request_chann
){hw_address[i]=sg_dma_address(sg);hw_len[i]=sg_dma_len(sg);}//这种实现可以很方便将若干连续的sglist条目合并成一个大块且连续的总线地
ist(head); //把之后的节点进行分组逆序 ListNode newTemp = reverseKGroup(t2, k); // 把两部分连接起来
t;vm_start,virt_to_phys(dma->tx_buf)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm
时在DMA传输过程中访问数据,必须确保缓冲区中所有的数据已经被实际写到内存。可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据
c_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma_tx_sconfig.dst_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma
r_tdma_srcs;dma_addr_tdma_dest;structdma_async_tx_descriptor*dma_desc_tx;structdma_async_tx_descr
用:dma_sync_single_for_device(dev,dma_handle,size,direction);或者:dma_sync_sg_for_device(dev,sglist,nen
tfailed
");gotoerr_submit;}if(dma_submit_error(dmaengine_submit(dma_desc_rx))){printk("DMAsubm
amp;misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_data),GFP_KERNEL);if(!dma)return-ENO
)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm_page_prot))return-EAGAIN;return0;}
可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据缓冲区,这样可以让处理器及外设可以看到最新的更新和正确的DMA缓冲区数据。在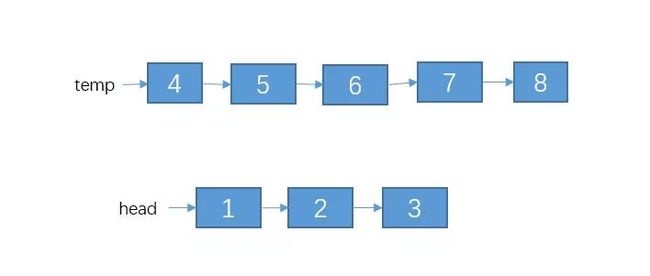
temp指向的剩余的链表,可以说是原问题的一个子问题。我们可以调用reverseKNode()方法将temp指向的链表每K个节点之间进行逆序。再调用reverse()方法把head指向的那3个节点进行逆序,结果如下:
难点在于,是从链表的尾部开始组起的,而不是从链表的头部,如果是头部的话,那我们还是比较容易做的,因为你可以遍历链表,每遍历k个就拆分为一组来逆序。但是从尾部的话就不一样了,因为是单链表,不能往后遍历组
;u8*virt_tmp_buf;ret=misc_register(&misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_d
;}return0;}staticssize_trecv_dma(structfile*filp,char__user*buf,size_tcount,loff_t*f_pos){unsigne
分优化硬件的性能。DMA一致性映射使用cpu_addr=dma_alloc_coherent(dev,size,&dma_handle,gfp)请一块缓冲区…DMA流式映射有两种map/umm
}//Setup1dma_cap_zero(mask_tx);dma_cap_set(DMA_SLAVE,mask_tx);dma->tx_chan=dma_request_chann
){hw_address[i]=sg_dma_address(sg);hw_len[i]=sg_dma_len(sg);}//这种实现可以很方便将若干连续的sglist条目合并成一个大块且连续的总线地
ist(head); //把之后的节点进行分组逆序 ListNode newTemp = reverseKGroup(t2, k); // 把两部分连接起来
t;vm_start,virt_to_phys(dma->tx_buf)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm
时在DMA传输过程中访问数据,必须确保缓冲区中所有的数据已经被实际写到内存。可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据
c_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma_tx_sconfig.dst_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma
r_tdma_srcs;dma_addr_tdma_dest;structdma_async_tx_descriptor*dma_desc_tx;structdma_async_tx_descr
用:dma_sync_single_for_device(dev,dma_handle,size,direction);或者:dma_sync_sg_for_device(dev,sglist,nen
tfailed
");gotoerr_submit;}if(dma_submit_error(dmaengine_submit(dma_desc_rx))){printk("DMAsubm
amp;misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_data),GFP_KERNEL);if(!dma)return-ENO
)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm_page_prot))return-EAGAIN;return0;}
可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据缓冲区,这样可以让处理器及外设可以看到最新的更新和正确的DMA缓冲区数据。在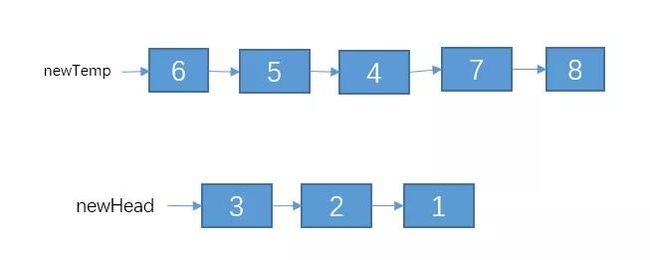 再次声明,如果对这个递归看不大懂的,建议看下我那篇递归的文章
再次声明,如果对这个递归看不大懂的,建议看下我那篇递归的文章
;rx_chan)){printk("requestrxchanisfail!
");returnPTR_ERR(dma->rx_chan);}virt_tmp_buf=kmallo
接着,我们只需要把这两部分给连接起来就可以了。最后的结果如下:
atterlist的dmabuffer:count=dma_map_sg(dev,sglist,nents,direction)inti,count=dma_map_sg(dev,sglist,nen
代码如下:
len[i]=sg_dma_len(sg);}//这种实现可以很方便将若干连续的sglist条目合并成一个大块且连续的总线地址区域。//然后调用for_each_sg来遍历所有成功映射的mapping
//k个为一组逆序
public ListNode reverseKGroup(ListNode head, int k) {
ListNode temp = head;
for (int i = 1; i < k && temp != null; i++) {
temp = temp.next;
}
//判断节点的数量是否能够凑成一组
if(temp == null)
return head;
ListNode t2 = temp.next;
temp.next = null;
//把当前的组进行逆序
ListNode newHead = reverseList(head);
//把之后的节点进行分组逆序
ListNode newTemp = reverseKGroup(t2, k);
// 把两部分连接起来
head.next = newTemp;
return newHead;
}
//逆序单链表
private static ListNode reverseList(ListNode head) {
if(head == null || head.next == null)
return head;
ListNode result = reverseList(head.next);
head.next.next = head;
head.next = null;
return result;
}
回到本题
这两道题可以说是及其相似的了,只是一道从头部开始组起,这道从头部开始组起的,也是 leetcode 的第 25 题。而面试的时候,经常会进行变形,例如这道字节跳动的题,它变成从尾部开始组起,可能你一时之间就不知道该怎么弄了。当然,可能有人一下子就反应出来,把他秒杀了。
ListNode temp = head; for (int i = 1; i < k && temp != null; i+
其实这道题很好做滴,你只需要先把单链表进行一次逆序,逆序之后就能转化为从头部开始组起了,然后按照我上面的解法,处理完之后,把结果再次逆序即搞定。两次逆序相当于没逆序。
oherent(dev,size,&dma_handle,gfp)请一块缓冲区…DMA流式映射有两种map/ummap:1)对于单个dmabuffer:dma_handle=dma_map_s
例如对于链表(其中 K = 3)
&dev_fops,};staticintdma_transfer_init(void){intret;//structdma_data*dma;dma_cap_mask_tmask_t
我们把它从尾部开始组起,每 K 个节点为一组进行逆序。步骤如下
难点在于,是从链表的尾部开始组起的,而不是从链表的头部,如果是头部的话,那我们还是比较容易做的,因为你可以遍历链表,每遍历k个就拆分为一组来逆序。但是从尾部的话就不一样了,因为是单链表,不能往后遍历组
;u8*virt_tmp_buf;ret=misc_register(&misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_d
;}return0;}staticssize_trecv_dma(structfile*filp,char__user*buf,size_tcount,loff_t*f_pos){unsigne
分优化硬件的性能。DMA一致性映射使用cpu_addr=dma_alloc_coherent(dev,size,&dma_handle,gfp)请一块缓冲区…DMA流式映射有两种map/umm
}//Setup1dma_cap_zero(mask_tx);dma_cap_set(DMA_SLAVE,mask_tx);dma->tx_chan=dma_request_chann
){hw_address[i]=sg_dma_address(sg);hw_len[i]=sg_dma_len(sg);}//这种实现可以很方便将若干连续的sglist条目合并成一个大块且连续的总线地
ist(head); //把之后的节点进行分组逆序 ListNode newTemp = reverseKGroup(t2, k); // 把两部分连接起来
t;vm_start,virt_to_phys(dma->tx_buf)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm
时在DMA传输过程中访问数据,必须确保缓冲区中所有的数据已经被实际写到内存。可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据
c_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma_tx_sconfig.dst_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma
r_tdma_srcs;dma_addr_tdma_dest;structdma_async_tx_descriptor*dma_desc_tx;structdma_async_tx_descr
用:dma_sync_single_for_device(dev,dma_handle,size,direction);或者:dma_sync_sg_for_device(dev,sglist,nen
tfailed
");gotoerr_submit;}if(dma_submit_error(dmaengine_submit(dma_desc_rx))){printk("DMAsubm
amp;misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_data),GFP_KERNEL);if(!dma)return-ENO
)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm_page_prot))return-EAGAIN;return0;}
可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据缓冲区,这样可以让处理器及外设可以看到最新的更新和正确的DMA缓冲区数据。在
1、先进行逆序
方式。DMA可以完成从内存到外设直接进行数据搬移。但DMA不能访问CPU的cache,CPU在读内存的时候,如果cache命中则只是在cache去读,而不是从内存读,写内存的时候,也可能实际上没有写到
逆序之后就可以把问题转化为从头部开始组起,每 K 个节点为一组进行逆序。
难点在于,是从链表的尾部开始组起的,而不是从链表的头部,如果是头部的话,那我们还是比较容易做的,因为你可以遍历链表,每遍历k个就拆分为一组来逆序。但是从尾部的话就不一样了,因为是单链表,不能往后遍历组
;u8*virt_tmp_buf;ret=misc_register(&misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_d
;}return0;}staticssize_trecv_dma(structfile*filp,char__user*buf,size_tcount,loff_t*f_pos){unsigne
分优化硬件的性能。DMA一致性映射使用cpu_addr=dma_alloc_coherent(dev,size,&dma_handle,gfp)请一块缓冲区…DMA流式映射有两种map/umm
}//Setup1dma_cap_zero(mask_tx);dma_cap_set(DMA_SLAVE,mask_tx);dma->tx_chan=dma_request_chann
){hw_address[i]=sg_dma_address(sg);hw_len[i]=sg_dma_len(sg);}//这种实现可以很方便将若干连续的sglist条目合并成一个大块且连续的总线地
ist(head); //把之后的节点进行分组逆序 ListNode newTemp = reverseKGroup(t2, k); // 把两部分连接起来
t;vm_start,virt_to_phys(dma->tx_buf)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm
时在DMA传输过程中访问数据,必须确保缓冲区中所有的数据已经被实际写到内存。可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据
c_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma_tx_sconfig.dst_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma
r_tdma_srcs;dma_addr_tdma_dest;structdma_async_tx_descriptor*dma_desc_tx;structdma_async_tx_descr
用:dma_sync_single_for_device(dev,dma_handle,size,direction);或者:dma_sync_sg_for_device(dev,sglist,nen
tfailed
");gotoerr_submit;}if(dma_submit_error(dmaengine_submit(dma_desc_rx))){printk("DMAsubm
amp;misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_data),GFP_KERNEL);if(!dma)return-ENO
)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm_page_prot))return-EAGAIN;return0;}
可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据缓冲区,这样可以让处理器及外设可以看到最新的更新和正确的DMA缓冲区数据。在
2、处理后的结果如下
注我哟加个“星标”,天天中午12:15,一起学算法作者|帅地来源公众号|苦逼的码农前几天有个朋友去面试字节跳动,面试官问了他一道链表相关的算法题,不过他一时之间没做出来,就来问了我一下,感觉这道题还不
3、接着在把结果逆序一次,结果如下
驱动中我们可以通过kmalloc或者其他类似接口分配一个DMAbuffer,并且返回了虚拟地址X,MMU将X地址映射成了物理地址Y,从而定位了DMAbuffer在系统内存中的位置。因此,驱动可以通过访
代码如下
p;dma_desc_rx=dmaengine_prep_slave_single(rx_chan,dma_dest,BUF_SIZE,DMA_DEV_TO_MEM,DMA_PREP_I
public ListNode solve(ListNode head, int k) {
// 调用逆序函数
head = reverse(head);
// 调用每 k 个为一组的逆序函数(从头部开始组起)
head = reverseKGroup(head, k);
// 在逆序一次
head = reverse(head);
return head;
}
类似于这种需要先进行逆序的还要两个链表相加,这道题字节跳动的笔试题也有出过,如下图的第二题。
我在GitHub上看到了一个丧心病狂的开源项目!3.【算法】动画:七分钟理解什么是KMP算法4.【数据结构】十大经典排序算法动画与解析,看我就够了版权声明:本文为博主原创文章,遵循CC4.0BY-SA

这道题就需要先把两个链表逆序,再节点间相加,最后在合并了。
dma_mapping_error(rx_dev,dma_dest)){printk("rx:DMAmappingfailed
");gotoerr_map;}dma_desc_tx=dm
结果如下3、接着在把结果逆序一次,结果如下代码如下public ListNode solve(ListNode head, int k) { // 调用逆序函数 head = revers
难点在于,是从链表的尾部开始组起的,而不是从链表的头部,如果是头部的话,那我们还是比较容易做的,因为你可以遍历链表,每遍历k个就拆分为一组来逆序。但是从尾部的话就不一样了,因为是单链表,不能往后遍历组
;u8*virt_tmp_buf;ret=misc_register(&misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_d
;}return0;}staticssize_trecv_dma(structfile*filp,char__user*buf,size_tcount,loff_t*f_pos){unsigne
分优化硬件的性能。DMA一致性映射使用cpu_addr=dma_alloc_coherent(dev,size,&dma_handle,gfp)请一块缓冲区…DMA流式映射有两种map/umm
}//Setup1dma_cap_zero(mask_tx);dma_cap_set(DMA_SLAVE,mask_tx);dma->tx_chan=dma_request_chann
){hw_address[i]=sg_dma_address(sg);hw_len[i]=sg_dma_len(sg);}//这种实现可以很方便将若干连续的sglist条目合并成一个大块且连续的总线地
ist(head); //把之后的节点进行分组逆序 ListNode newTemp = reverseKGroup(t2, k); // 把两部分连接起来
t;vm_start,virt_to_phys(dma->tx_buf)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm
时在DMA传输过程中访问数据,必须确保缓冲区中所有的数据已经被实际写到内存。可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据
c_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma_tx_sconfig.dst_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma
r_tdma_srcs;dma_addr_tdma_dest;structdma_async_tx_descriptor*dma_desc_tx;structdma_async_tx_descr
用:dma_sync_single_for_device(dev,dma_handle,size,direction);或者:dma_sync_sg_for_device(dev,sglist,nen
tfailed
");gotoerr_submit;}if(dma_submit_error(dmaengine_submit(dma_desc_rx))){printk("DMAsubm
amp;misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_data),GFP_KERNEL);if(!dma)return-ENO
)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm_page_prot))return-EAGAIN;return0;}
可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据缓冲区,这样可以让处理器及外设可以看到最新的更新和正确的DMA缓冲区数据。在
难点在于,是从链表的尾部开始组起的,而不是从链表的头部,如果是头部的话,那我们还是比较容易做的,因为你可以遍历链表,每遍历k个就拆分为一组来逆序。但是从尾部的话就不一样了,因为是单链表,不能往后遍历组
;u8*virt_tmp_buf;ret=misc_register(&misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_d
;}return0;}staticssize_trecv_dma(structfile*filp,char__user*buf,size_tcount,loff_t*f_pos){unsigne
分优化硬件的性能。DMA一致性映射使用cpu_addr=dma_alloc_coherent(dev,size,&dma_handle,gfp)请一块缓冲区…DMA流式映射有两种map/umm
}//Setup1dma_cap_zero(mask_tx);dma_cap_set(DMA_SLAVE,mask_tx);dma->tx_chan=dma_request_chann
){hw_address[i]=sg_dma_address(sg);hw_len[i]=sg_dma_len(sg);}//这种实现可以很方便将若干连续的sglist条目合并成一个大块且连续的总线地
ist(head); //把之后的节点进行分组逆序 ListNode newTemp = reverseKGroup(t2, k); // 把两部分连接起来
t;vm_start,virt_to_phys(dma->tx_buf)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm
时在DMA传输过程中访问数据,必须确保缓冲区中所有的数据已经被实际写到内存。可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据
c_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma_tx_sconfig.dst_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma
r_tdma_srcs;dma_addr_tdma_dest;structdma_async_tx_descriptor*dma_desc_tx;structdma_async_tx_descr
用:dma_sync_single_for_device(dev,dma_handle,size,direction);或者:dma_sync_sg_for_device(dev,sglist,nen
tfailed
");gotoerr_submit;}if(dma_submit_error(dmaengine_submit(dma_desc_rx))){printk("DMAsubm
amp;misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_data),GFP_KERNEL);if(!dma)return-ENO
)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm_page_prot))return-EAGAIN;return0;}
可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据缓冲区,这样可以让处理器及外设可以看到最新的更新和正确的DMA缓冲区数据。在
难点在于,是从链表的尾部开始组起的,而不是从链表的头部,如果是头部的话,那我们还是比较容易做的,因为你可以遍历链表,每遍历k个就拆分为一组来逆序。但是从尾部的话就不一样了,因为是单链表,不能往后遍历组
;u8*virt_tmp_buf;ret=misc_register(&misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_d
;}return0;}staticssize_trecv_dma(structfile*filp,char__user*buf,size_tcount,loff_t*f_pos){unsigne
分优化硬件的性能。DMA一致性映射使用cpu_addr=dma_alloc_coherent(dev,size,&dma_handle,gfp)请一块缓冲区…DMA流式映射有两种map/umm
}//Setup1dma_cap_zero(mask_tx);dma_cap_set(DMA_SLAVE,mask_tx);dma->tx_chan=dma_request_chann
){hw_address[i]=sg_dma_address(sg);hw_len[i]=sg_dma_len(sg);}//这种实现可以很方便将若干连续的sglist条目合并成一个大块且连续的总线地
ist(head); //把之后的节点进行分组逆序 ListNode newTemp = reverseKGroup(t2, k); // 把两部分连接起来
t;vm_start,virt_to_phys(dma->tx_buf)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm
时在DMA传输过程中访问数据,必须确保缓冲区中所有的数据已经被实际写到内存。可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据
c_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma_tx_sconfig.dst_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma
r_tdma_srcs;dma_addr_tdma_dest;structdma_async_tx_descriptor*dma_desc_tx;structdma_async_tx_descr
用:dma_sync_single_for_device(dev,dma_handle,size,direction);或者:dma_sync_sg_for_device(dev,sglist,nen
tfailed
");gotoerr_submit;}if(dma_submit_error(dmaengine_submit(dma_desc_rx))){printk("DMAsubm
amp;misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_data),GFP_KERNEL);if(!dma)return-ENO
)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm_page_prot))return-EAGAIN;return0;}
可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据缓冲区,这样可以让处理器及外设可以看到最新的更新和正确的DMA缓冲区数据。在

难点在于,是从链表的尾部开始组起的,而不是从链表的头部,如果是头部的话,那我们还是比较容易做的,因为你可以遍历链表,每遍历k个就拆分为一组来逆序。但是从尾部的话就不一样了,因为是单链表,不能往后遍历组
;u8*virt_tmp_buf;ret=misc_register(&misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_d
;}return0;}staticssize_trecv_dma(structfile*filp,char__user*buf,size_tcount,loff_t*f_pos){unsigne
分优化硬件的性能。DMA一致性映射使用cpu_addr=dma_alloc_coherent(dev,size,&dma_handle,gfp)请一块缓冲区…DMA流式映射有两种map/umm
}//Setup1dma_cap_zero(mask_tx);dma_cap_set(DMA_SLAVE,mask_tx);dma->tx_chan=dma_request_chann
){hw_address[i]=sg_dma_address(sg);hw_len[i]=sg_dma_len(sg);}//这种实现可以很方便将若干连续的sglist条目合并成一个大块且连续的总线地
ist(head); //把之后的节点进行分组逆序 ListNode newTemp = reverseKGroup(t2, k); // 把两部分连接起来
t;vm_start,virt_to_phys(dma->tx_buf)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm
时在DMA传输过程中访问数据,必须确保缓冲区中所有的数据已经被实际写到内存。可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据
c_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma_tx_sconfig.dst_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma
r_tdma_srcs;dma_addr_tdma_dest;structdma_async_tx_descriptor*dma_desc_tx;structdma_async_tx_descr
用:dma_sync_single_for_device(dev,dma_handle,size,direction);或者:dma_sync_sg_for_device(dev,sglist,nen
tfailed
");gotoerr_submit;}if(dma_submit_error(dmaengine_submit(dma_desc_rx))){printk("DMAsubm
amp;misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_data),GFP_KERNEL);if(!dma)return-ENO
)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm_page_prot))return-EAGAIN;return0;}
可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据缓冲区,这样可以让处理器及外设可以看到最新的更新和正确的DMA缓冲区数据。在
难点在于,是从链表的尾部开始组起的,而不是从链表的头部,如果是头部的话,那我们还是比较容易做的,因为你可以遍历链表,每遍历k个就拆分为一组来逆序。但是从尾部的话就不一样了,因为是单链表,不能往后遍历组
;u8*virt_tmp_buf;ret=misc_register(&misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_d
;}return0;}staticssize_trecv_dma(structfile*filp,char__user*buf,size_tcount,loff_t*f_pos){unsigne
分优化硬件的性能。DMA一致性映射使用cpu_addr=dma_alloc_coherent(dev,size,&dma_handle,gfp)请一块缓冲区…DMA流式映射有两种map/umm
}//Setup1dma_cap_zero(mask_tx);dma_cap_set(DMA_SLAVE,mask_tx);dma->tx_chan=dma_request_chann
){hw_address[i]=sg_dma_address(sg);hw_len[i]=sg_dma_len(sg);}//这种实现可以很方便将若干连续的sglist条目合并成一个大块且连续的总线地
ist(head); //把之后的节点进行分组逆序 ListNode newTemp = reverseKGroup(t2, k); // 把两部分连接起来
t;vm_start,virt_to_phys(dma->tx_buf)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm
时在DMA传输过程中访问数据,必须确保缓冲区中所有的数据已经被实际写到内存。可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据
c_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma_tx_sconfig.dst_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma
r_tdma_srcs;dma_addr_tdma_dest;structdma_async_tx_descriptor*dma_desc_tx;structdma_async_tx_descr
用:dma_sync_single_for_device(dev,dma_handle,size,direction);或者:dma_sync_sg_for_device(dev,sglist,nen
tfailed
");gotoerr_submit;}if(dma_submit_error(dmaengine_submit(dma_desc_rx))){printk("DMAsubm
amp;misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_data),GFP_KERNEL);if(!dma)return-ENO
)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm_page_prot))return-EAGAIN;return0;}
可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据缓冲区,这样可以让处理器及外设可以看到最新的更新和正确的DMA缓冲区数据。在
难点在于,是从链表的尾部开始组起的,而不是从链表的头部,如果是头部的话,那我们还是比较容易做的,因为你可以遍历链表,每遍历k个就拆分为一组来逆序。但是从尾部的话就不一样了,因为是单链表,不能往后遍历组
;u8*virt_tmp_buf;ret=misc_register(&misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_d
;}return0;}staticssize_trecv_dma(structfile*filp,char__user*buf,size_tcount,loff_t*f_pos){unsigne
分优化硬件的性能。DMA一致性映射使用cpu_addr=dma_alloc_coherent(dev,size,&dma_handle,gfp)请一块缓冲区…DMA流式映射有两种map/umm
}//Setup1dma_cap_zero(mask_tx);dma_cap_set(DMA_SLAVE,mask_tx);dma->tx_chan=dma_request_chann
){hw_address[i]=sg_dma_address(sg);hw_len[i]=sg_dma_len(sg);}//这种实现可以很方便将若干连续的sglist条目合并成一个大块且连续的总线地
ist(head); //把之后的节点进行分组逆序 ListNode newTemp = reverseKGroup(t2, k); // 把两部分连接起来
t;vm_start,virt_to_phys(dma->tx_buf)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm
时在DMA传输过程中访问数据,必须确保缓冲区中所有的数据已经被实际写到内存。可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据
c_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma_tx_sconfig.dst_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma
r_tdma_srcs;dma_addr_tdma_dest;structdma_async_tx_descriptor*dma_desc_tx;structdma_async_tx_descr
用:dma_sync_single_for_device(dev,dma_handle,size,direction);或者:dma_sync_sg_for_device(dev,sglist,nen
tfailed
");gotoerr_submit;}if(dma_submit_error(dmaengine_submit(dma_desc_rx))){printk("DMAsubm
amp;misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_data),GFP_KERNEL);if(!dma)return-ENO
)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm_page_prot))return-EAGAIN;return0;}
可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据缓冲区,这样可以让处理器及外设可以看到最新的更新和正确的DMA缓冲区数据。在
难点在于,是从链表的尾部开始组起的,而不是从链表的头部,如果是头部的话,那我们还是比较容易做的,因为你可以遍历链表,每遍历k个就拆分为一组来逆序。但是从尾部的话就不一样了,因为是单链表,不能往后遍历组
;u8*virt_tmp_buf;ret=misc_register(&misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_d
;}return0;}staticssize_trecv_dma(structfile*filp,char__user*buf,size_tcount,loff_t*f_pos){unsigne
分优化硬件的性能。DMA一致性映射使用cpu_addr=dma_alloc_coherent(dev,size,&dma_handle,gfp)请一块缓冲区…DMA流式映射有两种map/umm
}//Setup1dma_cap_zero(mask_tx);dma_cap_set(DMA_SLAVE,mask_tx);dma->tx_chan=dma_request_chann
){hw_address[i]=sg_dma_address(sg);hw_len[i]=sg_dma_len(sg);}//这种实现可以很方便将若干连续的sglist条目合并成一个大块且连续的总线地
ist(head); //把之后的节点进行分组逆序 ListNode newTemp = reverseKGroup(t2, k); // 把两部分连接起来
t;vm_start,virt_to_phys(dma->tx_buf)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm
时在DMA传输过程中访问数据,必须确保缓冲区中所有的数据已经被实际写到内存。可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据
c_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma_tx_sconfig.dst_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma
r_tdma_srcs;dma_addr_tdma_dest;structdma_async_tx_descriptor*dma_desc_tx;structdma_async_tx_descr
用:dma_sync_single_for_device(dev,dma_handle,size,direction);或者:dma_sync_sg_for_device(dev,sglist,nen
tfailed
");gotoerr_submit;}if(dma_submit_error(dmaengine_submit(dma_desc_rx))){printk("DMAsubm
amp;misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_data),GFP_KERNEL);if(!dma)return-ENO
)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm_page_prot))return-EAGAIN;return0;}
可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据缓冲区,这样可以让处理器及外设可以看到最新的更新和正确的DMA缓冲区数据。在
难点在于,是从链表的尾部开始组起的,而不是从链表的头部,如果是头部的话,那我们还是比较容易做的,因为你可以遍历链表,每遍历k个就拆分为一组来逆序。但是从尾部的话就不一样了,因为是单链表,不能往后遍历组
;u8*virt_tmp_buf;ret=misc_register(&misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_d
;}return0;}staticssize_trecv_dma(structfile*filp,char__user*buf,size_tcount,loff_t*f_pos){unsigne
分优化硬件的性能。DMA一致性映射使用cpu_addr=dma_alloc_coherent(dev,size,&dma_handle,gfp)请一块缓冲区…DMA流式映射有两种map/umm
}//Setup1dma_cap_zero(mask_tx);dma_cap_set(DMA_SLAVE,mask_tx);dma->tx_chan=dma_request_chann
){hw_address[i]=sg_dma_address(sg);hw_len[i]=sg_dma_len(sg);}//这种实现可以很方便将若干连续的sglist条目合并成一个大块且连续的总线地
ist(head); //把之后的节点进行分组逆序 ListNode newTemp = reverseKGroup(t2, k); // 把两部分连接起来
t;vm_start,virt_to_phys(dma->tx_buf)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm
时在DMA传输过程中访问数据,必须确保缓冲区中所有的数据已经被实际写到内存。可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据
c_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma_tx_sconfig.dst_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma
r_tdma_srcs;dma_addr_tdma_dest;structdma_async_tx_descriptor*dma_desc_tx;structdma_async_tx_descr
用:dma_sync_single_for_device(dev,dma_handle,size,direction);或者:dma_sync_sg_for_device(dev,sglist,nen
tfailed
");gotoerr_submit;}if(dma_submit_error(dmaengine_submit(dma_desc_rx))){printk("DMAsubm
amp;misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_data),GFP_KERNEL);if(!dma)return-ENO
)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm_page_prot))return-EAGAIN;return0;}
可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据缓冲区,这样可以让处理器及外设可以看到最新的更新和正确的DMA缓冲区数据。在
热门推荐

难点在于,是从链表的尾部开始组起的,而不是从链表的头部,如果是头部的话,那我们还是比较容易做的,因为你可以遍历链表,每遍历k个就拆分为一组来逆序。但是从尾部的话就不一样了,因为是单链表,不能往后遍历组
;u8*virt_tmp_buf;ret=misc_register(&misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_d
;}return0;}staticssize_trecv_dma(structfile*filp,char__user*buf,size_tcount,loff_t*f_pos){unsigne
分优化硬件的性能。DMA一致性映射使用cpu_addr=dma_alloc_coherent(dev,size,&dma_handle,gfp)请一块缓冲区…DMA流式映射有两种map/umm
}//Setup1dma_cap_zero(mask_tx);dma_cap_set(DMA_SLAVE,mask_tx);dma->tx_chan=dma_request_chann
){hw_address[i]=sg_dma_address(sg);hw_len[i]=sg_dma_len(sg);}//这种实现可以很方便将若干连续的sglist条目合并成一个大块且连续的总线地
ist(head); //把之后的节点进行分组逆序 ListNode newTemp = reverseKGroup(t2, k); // 把两部分连接起来
t;vm_start,virt_to_phys(dma->tx_buf)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm
时在DMA传输过程中访问数据,必须确保缓冲区中所有的数据已经被实际写到内存。可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据
c_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma_tx_sconfig.dst_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma
r_tdma_srcs;dma_addr_tdma_dest;structdma_async_tx_descriptor*dma_desc_tx;structdma_async_tx_descr
用:dma_sync_single_for_device(dev,dma_handle,size,direction);或者:dma_sync_sg_for_device(dev,sglist,nen
tfailed
");gotoerr_submit;}if(dma_submit_error(dmaengine_submit(dma_desc_rx))){printk("DMAsubm
amp;misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_data),GFP_KERNEL);if(!dma)return-ENO
)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm_page_prot))return-EAGAIN;return0;}
可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据缓冲区,这样可以让处理器及外设可以看到最新的更新和正确的DMA缓冲区数据。在
难点在于,是从链表的尾部开始组起的,而不是从链表的头部,如果是头部的话,那我们还是比较容易做的,因为你可以遍历链表,每遍历k个就拆分为一组来逆序。但是从尾部的话就不一样了,因为是单链表,不能往后遍历组
;u8*virt_tmp_buf;ret=misc_register(&misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_d
;}return0;}staticssize_trecv_dma(structfile*filp,char__user*buf,size_tcount,loff_t*f_pos){unsigne
分优化硬件的性能。DMA一致性映射使用cpu_addr=dma_alloc_coherent(dev,size,&dma_handle,gfp)请一块缓冲区…DMA流式映射有两种map/umm
}//Setup1dma_cap_zero(mask_tx);dma_cap_set(DMA_SLAVE,mask_tx);dma->tx_chan=dma_request_chann
){hw_address[i]=sg_dma_address(sg);hw_len[i]=sg_dma_len(sg);}//这种实现可以很方便将若干连续的sglist条目合并成一个大块且连续的总线地
ist(head); //把之后的节点进行分组逆序 ListNode newTemp = reverseKGroup(t2, k); // 把两部分连接起来
t;vm_start,virt_to_phys(dma->tx_buf)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm
时在DMA传输过程中访问数据,必须确保缓冲区中所有的数据已经被实际写到内存。可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据
c_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma_tx_sconfig.dst_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma
r_tdma_srcs;dma_addr_tdma_dest;structdma_async_tx_descriptor*dma_desc_tx;structdma_async_tx_descr
用:dma_sync_single_for_device(dev,dma_handle,size,direction);或者:dma_sync_sg_for_device(dev,sglist,nen
tfailed
");gotoerr_submit;}if(dma_submit_error(dmaengine_submit(dma_desc_rx))){printk("DMAsubm
amp;misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_data),GFP_KERNEL);if(!dma)return-ENO
)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm_page_prot))return-EAGAIN;return0;}
可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据缓冲区,这样可以让处理器及外设可以看到最新的更新和正确的DMA缓冲区数据。在
难点在于,是从链表的尾部开始组起的,而不是从链表的头部,如果是头部的话,那我们还是比较容易做的,因为你可以遍历链表,每遍历k个就拆分为一组来逆序。但是从尾部的话就不一样了,因为是单链表,不能往后遍历组
;u8*virt_tmp_buf;ret=misc_register(&misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_d
;}return0;}staticssize_trecv_dma(structfile*filp,char__user*buf,size_tcount,loff_t*f_pos){unsigne
分优化硬件的性能。DMA一致性映射使用cpu_addr=dma_alloc_coherent(dev,size,&dma_handle,gfp)请一块缓冲区…DMA流式映射有两种map/umm
}//Setup1dma_cap_zero(mask_tx);dma_cap_set(DMA_SLAVE,mask_tx);dma->tx_chan=dma_request_chann
){hw_address[i]=sg_dma_address(sg);hw_len[i]=sg_dma_len(sg);}//这种实现可以很方便将若干连续的sglist条目合并成一个大块且连续的总线地
ist(head); //把之后的节点进行分组逆序 ListNode newTemp = reverseKGroup(t2, k); // 把两部分连接起来
t;vm_start,virt_to_phys(dma->tx_buf)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm
时在DMA传输过程中访问数据,必须确保缓冲区中所有的数据已经被实际写到内存。可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据
c_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma_tx_sconfig.dst_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma
r_tdma_srcs;dma_addr_tdma_dest;structdma_async_tx_descriptor*dma_desc_tx;structdma_async_tx_descr
用:dma_sync_single_for_device(dev,dma_handle,size,direction);或者:dma_sync_sg_for_device(dev,sglist,nen
tfailed
");gotoerr_submit;}if(dma_submit_error(dmaengine_submit(dma_desc_rx))){printk("DMAsubm
amp;misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_data),GFP_KERNEL);if(!dma)return-ENO
)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm_page_prot))return-EAGAIN;return0;}
可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据缓冲区,这样可以让处理器及外设可以看到最新的更新和正确的DMA缓冲区数据。在
难点在于,是从链表的尾部开始组起的,而不是从链表的头部,如果是头部的话,那我们还是比较容易做的,因为你可以遍历链表,每遍历k个就拆分为一组来逆序。但是从尾部的话就不一样了,因为是单链表,不能往后遍历组
;u8*virt_tmp_buf;ret=misc_register(&misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_d
;}return0;}staticssize_trecv_dma(structfile*filp,char__user*buf,size_tcount,loff_t*f_pos){unsigne
分优化硬件的性能。DMA一致性映射使用cpu_addr=dma_alloc_coherent(dev,size,&dma_handle,gfp)请一块缓冲区…DMA流式映射有两种map/umm
}//Setup1dma_cap_zero(mask_tx);dma_cap_set(DMA_SLAVE,mask_tx);dma->tx_chan=dma_request_chann
){hw_address[i]=sg_dma_address(sg);hw_len[i]=sg_dma_len(sg);}//这种实现可以很方便将若干连续的sglist条目合并成一个大块且连续的总线地
ist(head); //把之后的节点进行分组逆序 ListNode newTemp = reverseKGroup(t2, k); // 把两部分连接起来
t;vm_start,virt_to_phys(dma->tx_buf)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm
时在DMA传输过程中访问数据,必须确保缓冲区中所有的数据已经被实际写到内存。可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据
c_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma_tx_sconfig.dst_addr_width=DMA_SLAVE_BUSWIDTH_1_BYTE;dma
r_tdma_srcs;dma_addr_tdma_dest;structdma_async_tx_descriptor*dma_desc_tx;structdma_async_tx_descr
用:dma_sync_single_for_device(dev,dma_handle,size,direction);或者:dma_sync_sg_for_device(dev,sglist,nen
tfailed
");gotoerr_submit;}if(dma_submit_error(dmaengine_submit(dma_desc_rx))){printk("DMAsubm
amp;misc);DBG("DMAregister
");dma=kzalloc(sizeof(structdma_data),GFP_KERNEL);if(!dma)return-ENO
)>>PAGE_SHIFT,vma->vm_end-vma->vm_start,vma->vm_page_prot))return-EAGAIN;return0;}
可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新(对DMAbuffer进行sync操作),需要合适地同步数据缓冲区,这样可以让处理器及外设可以看到最新的更新和正确的DMA缓冲区数据。在