MySQL-InnoDB事务隔离级别和锁机制
一、基础知识
1.索引
1.1 聚集索引
- InnoDB中的表是索引组织表,即表中的数据按主键顺序存放。
- 聚集索引即按照每张表的主键构造一棵B+树,同时叶子节点中存放的即为整张表的行记录数据。也将聚集索引的叶子节点称为数据页,每个数据页都通过一个双向链表来进行链接。对于聚集索引来说,索引即数据,数据即索引。
- 因为一张表中只能有一个主键(但主键可由多列组成),因此每张表只能拥有一个聚集索引。
-
聚集索引B+树图示:

聚集索引B+树.png-58.1kB
1.2 辅助索引
- 辅助索引,也称非聚集索引,叶子节点中并不包括记录的全部数据,只包含一个指示与索引相对应的行数据位置的书签。因为InnoDB使用索引组织表,所以这个书签就是相应的行数据的聚集索引键。
扩展:在SQLServer数据库中,并不使用索引组织表,而是使用一种称为堆表的表类型。因此对于SQLServer来说,书签是一个行标识符,用类似 文件号:页号:槽号 的格式来定位行数据。
- 因为辅助索引中并不包括实际行记录,所以通过辅助索引查询时,除了在辅助索引本身查询之外,还有在聚集索引中进行一次查询,才能取得真正的行记录。这一步也被称为回表查询。
-
辅助索引与聚集索引关系图示:

辅助索引&聚集索引.png-87.8kB
2.锁机制
2.1 记录锁
- InnoDB实现了如下两种标准记录锁(行级锁):
- 共享锁(S Lock):允许事务读一行数据。
- 排它锁(X Lock):允许事务删除或更新一行数据。
- 行级锁的S锁和X锁的兼容性如下:(需要注意的是,这里的S锁和X锁都是行级锁,兼容性是指对同一记录锁的兼容情况)
| . | X | S |
|---|---|---|
| X | 不兼容 | 不兼容 |
| S | 不兼容 | 兼容 |
- S锁和X锁也可加到表上,详见第三小节“多粒度锁”。
2.2 范围锁
- InnoDB有如下两种范围锁算法:
- Gap Lock:间隙锁,锁定一个范围,但不包含记录本身。
- Next-Key Lock:Gap Lock + Record Lock,锁定一个范围,并且锁定记录本身。
-
范围锁也是行级锁的一种,不过锁定的是多行记录。
-
在 repeatable read 和 seraliable 隔离级别下,会使用Next-Key Lock来做范围锁定。从而避免幻读。
-
在Next-Key Lock算法下,假如一个索引有10,11,13和20这四个值,那么该索引可能被Next-Key Lock的区间为:
(-无穷大, 10]
(10, 11]
(11, 13]
(13, 20]
(20, +无穷大) -
在上述情况下,若事务T1已通过Next-Key Lock锁定了如下范围:
(10, 11],(11, 13]
当插入新的记录12时,则锁定的范围会变成:
(10, 11],(11, 12],(12, 13] -
需要注意的是,如果定值查询的索引是唯一索引,InnoDB会对Next-Key Lock进行优化,将其降级为Record Lock,即仅锁住索引本身,而不是范围:由range降级为point。但如果是范围查询且是一致性锁定查询,则即使是唯一索引,也会使用Next-Key Lock进行锁定。例如:
select * from t where id > 2 for update;。
2.3 多粒度锁
- InnoDB支持多粒度锁定,这种锁定允许事务在行级上的锁和更高级(表、段、区、页)上的锁同时存在。
- 为了支持在不同粒度上进行加锁,InnoDB支持一种额外的加锁方式,称之为意向锁。
- InnoDB支持两种意向锁:
- 意向共享锁(IS Lock):事务想要获得一张表中某几行的共享锁。
- 意向排它锁(IX Lock):事务想要获得一张表中某几行的排它锁。
-
若将上锁的对象看成一棵树,那么对最下层(最细粒度)的对象上锁,需要先对粗粒度的对象上锁。如下图所示,如果需要对页上的记录上X锁,那么分别需要对数据库A、表、页上意向锁IX,最后对记录上X锁,若其中任何一个部分导致等待,那么该操作需要等待粗粒度锁的完成:
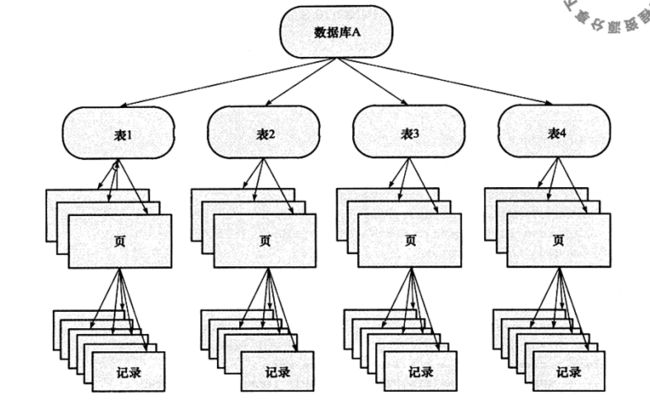
层级结构.png-178kB
-
粗粒度锁的兼容性如下:
| . | IS | IX | S | X |
|---|---|---|---|---|
| IS | 兼容 | 兼容 | 兼容 | 不兼容 |
| IX | 兼容 | 兼容 | 不兼容 | 不兼容 |
| S | 兼容 | 不兼容 | 兼容 | 不兼容 |
| X | 不兼容 | 不兼容 | 不兼容 | 不兼容 |
- 粗粒度锁也会有S锁和X锁的情况。举例来说,全表扫、alter表等。
- 意向锁存在的意义是:减少逐行检查锁标志的开销。
比如事务B要在一个表上加S锁,如果表中的一行已被事务A加了X锁,那么事务B锁的申请也应被阻塞。如果表中的数据很多,逐行检查锁标志的开销将很大,系统的性能将会受到影响。为了解决这个问题,可以在表级上引入新的锁类型来表示其所属行的加锁情况,这就引出了“意向锁”的概念。举个例子,如果表中有1亿条记录,事务A把其中有几条记录上了行锁了,这时事务B需要给这个表加表级锁,如果没有意向锁的话,那就要去表中查找这一亿条记录是否上锁了。如果存在意向锁,那么假如事务A在更新一条记录之前,先加意向锁,再加X锁,事务B先检查该表上是否存在意向锁,存在的意向锁是否与自己准备加的锁冲突,如果有冲突,则等待直到事务A释放,而无须逐条记录去检测。事务B更新表时,其实无须知道到底哪一行被锁了,它只要知道反正有一行被锁了就行了。
3.并发控制协议
3.1 MVCC
- MVCC全称Multi-Version Concurrent Control,即多版本并发控制,是一种乐观锁的实现。
- MVCC最大的特点是:读可不加锁,读写不冲突。并发性能很高。
- MVCC中默认的读是非锁定的一致性读,也称快照读。读取的是记录的可见版本,当读取的的记录正在被别的事务并发修改时,会读取记录的历史版本。读取过程中不对记录加锁。例如:
select * from table where ?;。
注意:不同事务隔离级别下,快照读对历史版本的读取方式并不相同:read committed级别下,对快照数据总是读取 最新一份的 快照数据;repeatable read级别下,总是读取当前 事务开始时的 快照数据。
- MVCC被用在 read committed 和 repeatable read 两种隔离级别中。
3.2 LBCC
- LBCC全称Lock-Based Concurrent Control,即基于锁的并发控制,是一种悲观锁的实现。
- LBCC中,对读会加S锁(共享锁),对写会加X锁(排它锁),即读读之间不阻塞,读写、写写之间会阻塞。
- LBCC中的读是一致性锁定读,也称当前读:读取的是记录的最新版本,并且会对记录加锁。例如:
// 读加S锁
select * from table where ? lock in share mode;
// 读加X锁
select * from table where ? for update;
// 写加X锁
所有的DML操作:insert, update, delete
-
当前读DML操作示意图:

DML当前读.jpg-13.3kB
-
LBCC被用在 seraliable 隔离级别中,seraliable级别会对每个
select语句后面自动加上lock in share mode。
4.并发问题
4.1 脏读
- 脏读:两个事务,一个事务读取到了另一个事务未提交的数据。
- 脏读在 read uncommitted 隔离级别下会发生。read committed 及更严格的级别下不会。
4.2 不可重复读
- 不可重复读:一个事务对同一行记录的两次读取结果不同。
- 不可重复读在 read committed 及更低隔离级别下会发生。repeatable read 及更严格的级别下不会。
4.3 幻读
- 幻读:一个事务对同一范围的两次查询结果不同。
- SQL标准规定,幻读在 repeatable read 及更低隔离级别下可发生。seraliable 级别不可。但需要注意的是:因为InnoDB在repeatable read隔离级别会使用Next-Key Lock,所以InnoDB的repeatable read级别也可避免幻读。
二、事务隔离级别
1.read uncommitted
- 总是读记录的最新版本数据,无论该版本是否已提交。
- 可能出现脏读、不可重复读、幻读。
- 无锁。
- 在业务中基本不会使用该级别。
2.read committed
- 事务中能看到其他事务已提交的修改。
- 可能出现不可重复读、幻读。
- 使用乐观锁(MVCC)。不使用范围锁。
- 是大多数数据库默认的隔离级别。
3.repeatable read
- 可对读取到的记录加锁 (记录锁),同时保证对读取的范围加锁(范围锁),保证新的满足查询条件的记录不会被插入。
- SQL规范下的repeatable read允许出现幻读,但InnoDB依靠范围锁,在repeatable read级别下也可避免幻读。
- 是InnoDB的默认隔离级别。
- 使用乐观锁(MVCC),使用范围锁。
4.seraliable
- 在操作的每一行数据上都加上锁,读取加S锁,DML加X锁。
- 使用悲观锁(LBCC)。
三、SQL加锁分析
- 下面以一个简单的delete操作SQL为例,来分析其加锁细节:
delete from t1 where id=10;
-
想要确定InnoDB的加锁情况,需要知道很多前提条件, 例如:
-
id列是不是主键?
-
事务的隔离级别是什么?
-
id非主键的话,其上有建立索引吗?
-
建立的索引是唯一索引吗?
-
该SQL的执行计划是什么?索引扫描?全表扫描?
-
下面对这些问题的各种答案进行组合,然后按照从易到难的顺序,逐个分析每种组合下,上面的SQL会加哪些锁。
1.id列是主键,RC隔离级别
- 当id是主键的时候,我们只需要在该id=10的记录上加上x锁即可。如下图:

组合1.jpg-58.5kB
2.id列是辅助唯一索引,RC隔离级别
- 当id列为辅助唯一索引时,辅助索引和聚集索引,都会加X锁。如下图:
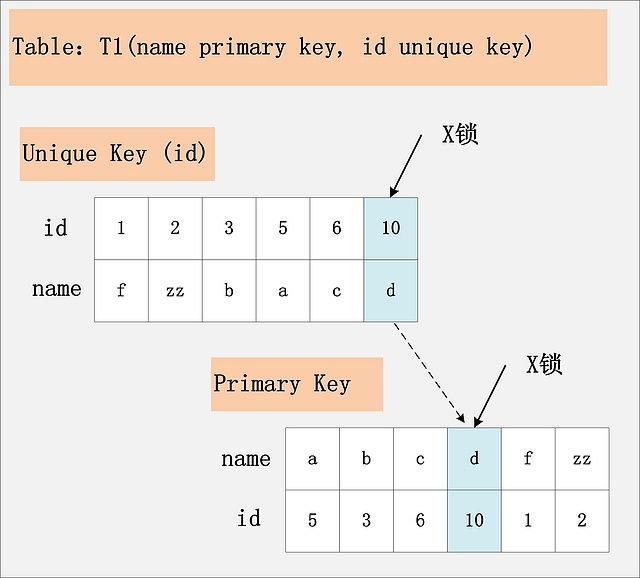
组合2.jpg-66.6kB
3.id列是辅助非唯一索引,RC隔离级别
- 如果id是非唯一索引,那么所对应的 所有的辅佐索引和聚集索引记录 上都会上x锁。如下图:

组合3.jpg-67.5kB
4.id列上没有索引,RC隔离级别
- 由于id列上没有索引,因此只能走聚簇索引,进行全表扫描。因此聚集索引上的每条记录,无论是否满足条件,都会被加上X锁。但是,为了效率考量,MySQL做了优化,对于不满足条件的记录,会在判断后放锁,最终持有的,是满足条件的记录上的锁,但是不满足条件的记录上的加锁/放锁动作不会省略。同时,优化也违背了2PL约束(同时加锁同时放锁)。如下图:

组合4.jpg-72.1kB
5.id列是主键,RR隔离级别
- 与id列是主键,RC隔离级别的情况,完全相同。因为只有一条结果记录,只能在上面加锁。如下图:
组合5.jpg-58.5kB
6.id列是辅助唯一索引,RR隔离级别
- 与id列是辅助唯一索引,RC隔离级别的情况,完全相同。因为只有一条结果记录,只能在上面加锁。如下图:
组合6.jpg-66.6kB
7.id列是辅助非唯一索引,RR隔离级别
- 在RR隔离级别下,为了防止幻读的发生,会使用范围锁(GAP锁)。这里,可以把范围锁理解为,不允许在数据记录前面插入数据。首先,通过辅助索引定位到第一条满足查询条件的记录,加记录上的X锁,加GAP上的GAP锁,然后加聚簇索引上的记录X锁,然后返回;然后读取下一条,重复进行。直至进行到第一条不满足条件的记录[11,f],此时,不需要加记录X锁,但是仍旧需要加GAP锁,最后返回结束。如下图:

组合7.jpg-65.4kB
8.id列上没有索引,RR隔离级别
- 在这种情况下,聚集索引上的所有记录,都被加上了X锁。其次,聚集索引每条记录间的间隙(GAP),也同时被加上了GAP锁。但是,InnoDB也做了相关的优化,就是所谓的semi-consistent read。semi-consistent read开启的情况下,对于不满足查询条件的记录,MySQL会提前放锁,同时也不会添加Gap锁。如下图:
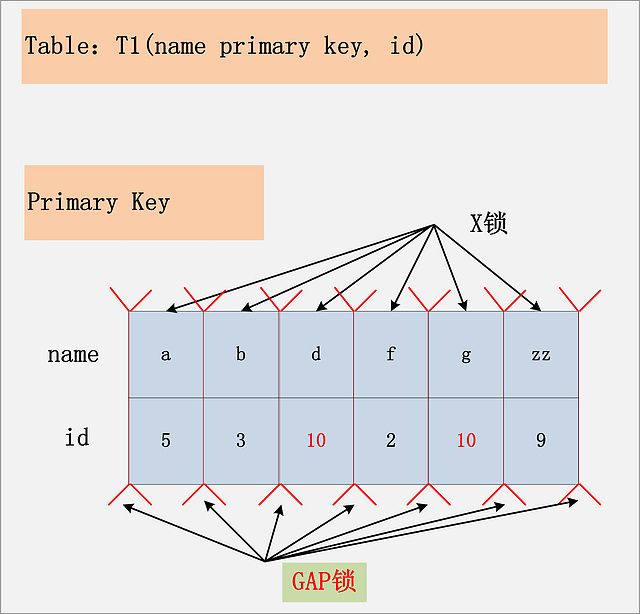
组合8.jpg-88.8kB
9.Serializable隔离级别
- 因为这是DML(delete)操作,所以与RR级别的各种情况下表现完全相同。但如果是select操作,会有所不同:RR级别默认是一致性非锁定读(快照读取),除非SQL中主动加锁进行一致性锁定读(lock in share mode 或 for update);而Serializable级别下,会对每条select语句,自动加上lock in share mode,进行一致性锁定读。
四、错误案例分析
1.先读后更新导致的线程安全问题
-
业务场景:根据template_id获取其对应的编号值。同一template_id每次请求得到的值要求唯一&递增。
-
问题表现:并发情况下,多次请求可得到相同的编号值。
-
表结构:

表结构.png-101.3kB
-
索引情况:

索引情况.png-160.7kB
-
问题代码(这里忽略对numInfo记录不存在情况的处理):
public Long getNum(Long templateId) throws Exception {
beginTransaction();
try {
ContractCodeState numInfo = stateDao.searchByTemplateId(templateId);
numInfo.setNum(numInfo.getNum + 1);
stateDao.update(numInfo);
commitTransaction();
return numInfo.getNum();
} catch (Exception e) {
rollbackTransaction();
throw e;
}
}
-
问题原因分析:对这个代码段来说,RC和RR隔离级别的表现是完全相同的。第4行代码通过一致性非锁定读进行查询,不会对改行记录加任何锁。这时如果有template_id参数相同的另一个并发请求,则会取到相同的numInfo,因此在第5行代码新生成的num会发生重复,导致取到相同的编号。
-
修复后代码:(这里忽略对numInfo记录不存在情况的处理)
public Long getNum(Long templateId) throws Exception {
beginTransaction();
try {
stateDao.incrementNum(templateId);
ContractCodeState numInfo = stateDao.searchByTemplateId(templateId);
commitTransaction();
return numInfo.getNum();
} catch (Exception e) {
rollbackTransaction();
throw e;
}
}
-
修复方案分析:修复后的代码,先对记录进行了update操作,加上X锁,这时对该条记录来说,操作已被串行化,其他事务对该记录的任何操作,包括查询,都将被阻塞,直到当前事务提交。因此可保证线程安全。
-
扩展:思考一下,假如问题代码的事务隔离级别是serializable,此时并发的向同一template_id发起请求,会发生什么情况?
下拉查看答案:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
会发生死锁。InnoDB检测到死锁后,会回滚其中一个事务,使另一个事务成功执行完毕。即并发请求时,只有一个请求可成功执行,而另一个事务将回滚,并返回异常。如下图:
1).事务1阻塞。

pic1.png-686.1kB
2).死锁。事务1执行成功,事务2自动回滚并返回异常。

pic2.png-770.1kB
- 总结:
- serializable隔离级别并不是完全串行化,而是读写串行化。
- 尽量避免先读后更情况的发生,转为先更后读。
- 如果一定要先读后更,那么可以使用加X锁的一致性锁定读(for update)。
五、其他要点
1.表很小,可能直接使用表锁而不是行锁
- 即便在条件中使用了索引字段,但是否使用索引来检索数据是由MySQL通过判断不同执行计划的代价来决定的,如果MySQL认为全表扫描效率更高,比如对一些很小的表,它就不会使用索引,这种情况下InnoDB将使用表锁,而不是行锁。因此,在分析锁冲突时,别忘了检查SQL的执行计划,以确认是否真正使用了索引。
2.查询时使用的数据类型与字段类型不同,不会使用索引
- 检索值的数据类型与索引字段不同,虽然MySQL能够进行数据类型转换,但却不会使用索引,从而导致InnoDB使用表锁。
例如name字段上有索引,且name字段是varchar类型的,如果where条件是name=1而不是name='1',则会对name进行类型转换,而执行的是全表扫描。 - 类似的,如果查询条件中对索引字段使用了函数(例如length),也不会使用索引。
3.几种避免死锁的常用方法
- 在应用中,如果不同的程序会并发存取多个表,应尽量约定以相同的顺序来访问表,这样可以大大降低产生死锁的机会。
- 在程序以批量方式处理数据的时候,如果事先对数据排序,保证每个线程按固定的顺序来处理记录,也可以大大降低出现死锁的可能。
- 在事务中,如果要更新记录,应该直接申请足够级别的锁,即排他锁,而不应先申请共享锁,更新时再申请排他锁,因为当用户申请排他锁时,其他事务可能又已经获得了相同记录的共享锁,从而造成锁冲突,甚至死锁。
end
作者:灵派coder
链接:https://www.jianshu.com/p/e83e88e2bcee
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。