【回归预测-BP预测】基于灰狼算法优化BP神经网络实现数据回归预测附matlab代码
1 内容介绍
Mirjalili 等在 2014 年 提 出 了 灰 狼 优 化 ( Grey Wolf Optimizer,GWO) 算法,是一种新型群智能优化算法,通过模拟自然界中灰狼寻找、包围和攻击猎物等狩猎机制的过程来完成最优化工作。该算法将狼群划分为 4 个等级,将狼按照适应度值最优排序,选择适应度值的前 3 个分别作为最优灰狼 α,次优灰狼 β 和第三优灰狼 δ,剩余灰狼作为 ω。在捕食过程中,由α、β、δ灰狼进行猎物的追捕,而剩余灰狼 ω追随前三者进行追踪和围捕,猎物的位置便是问题的解。研究证明GWO 算法在全局寻优方面明显优于粒子群优化 ( Particle Swarm Optimization,PSO) 算法、遗传算法( Genetic Algorithm, GA) 和 进 化 策 略( Evolutionary Strategy,ES) 等 智 能 优 化 算法。因此,本文利用 GWO 来优化 BP 神经网络的权重和阈值。下面给出灰狼算法的主要数学模型:

灰狼优化算法是一种能够寻找全局最优解的群智能算 法,具有加速模型收敛速度快和提升精度等特点,将 BP 神经 网络的权重和阈值作为灰狼的位置信息,根据灰狼对猎物的 位置判断,不断更新位置,就等同于在不断更新权重和阈值, 最终寻得全局最优。具体优化神经网络过程如下:
Step1 确定神经网络结构,主要是隐层节点的选取。
Step2 初始化参数。根据网络结构计算灰狼个体位置信 息的 维 度 ( dim) 、灰 狼 种 群 大 小 ( SN) 、最 大 迭 代 次 数 ( maxIter) 、灰狼维度的上界( ub) 和下界( lb) ,随机初始化灰 狼位置。
Step3 确定神经网络适应度函数及隐层节点、输出节点 的激励函数,其中适应度函数选用均方误差( Mean Squared Error,MSE) ,隐含层和输出层的激励函数均采用 Sigmoid 型函数。
Step4 计算适应度值,选取最优灰狼 α、次优灰狼 β 和第 三优灰狼 δ,根据式( 3) 更新剩余灰狼 ω 的位置信息,并更新 参数 A 和 C 及 a。
Step5 记录训练样本和检验样本的误差及所对应的最 优灰狼 α 的位置。
Step6 判断个体每一维度是否存在越界,将越界的值设 置为灰狼维度的上界 ( ub) 或下界( lb) 。
Step7 判断是否满足设定的误差或者达到最大迭代次 数; 否则重复 Step4 ~ Step7,直到满足条件。
Step8 最后返回结果为最优灰狼位置 α 及对应的最小 误差; 训练样本和检验样本的误差及训练过程每一次迭代最 优灰狼 α 的位置。
2 仿真代码
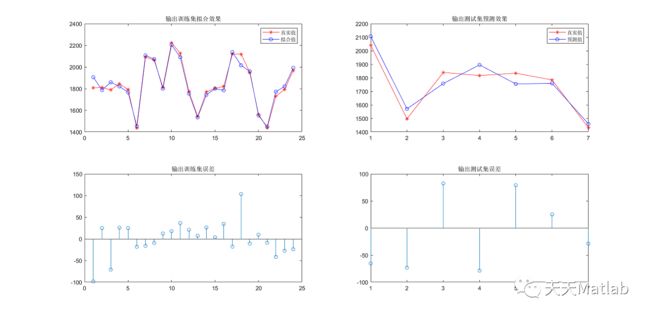
%灰狼优化多输入多输出BP神经网络代码clearclcticglobal SamIn SamOut HiddenUnitNum InDim OutDim TrainSamNum %% 导入训练数据data = xlsread('test_data1.xlsx');[data_m,data_n] = size(data);%获取数据维度P = 80; %百分之P的数据用于训练,其余测试Ind = floor(P * data_m / 100);train_data = data(1:Ind,1:end-1)'; train_result = data(1:Ind,end)';test_data = data(Ind+1:end,1:end-1)';% 利用训练好的网络进行预测test_result = data(Ind+1:end,end)';%% 初始化参数[InDim,TrainSamNum] = size(train_data);% 学习样本数量[OutDim,TrainSamNum] = size(train_result);HiddenUnitNum = 7; % 隐含层神经元个数[SamIn,PS_i] = mapminmax(train_data,0,1); % 原始样本对(输入和输出)初始化[SamOut,PS_o] = mapminmax(train_result,0,1);W1 = HiddenUnitNum*InDim; % 初始化输入层与隐含层之间的权值B1 = HiddenUnitNum; % 初始化输入层与隐含层之间的阈值W2 = OutDim*HiddenUnitNum; % 初始化输出层与隐含层之间的权值B2 = OutDim; % 初始化输出层与隐含层之间的阈值L = W1+B1+W2+B2; %粒子维度%%优化参数的设定dim=L; % 优化的参数 number of your variablesfor j=1:Llb(1,j)=-3.5; % 参数取值下界ub(1,j)=3.5;end% 参数取值上界test_error=test_result(1,:)-Forcast_data_test(1,:);mean_error=mean(abs(test_error)/test_result)% test_mse=mean(test_error.^2)test_mse=sqrt(mean(test_error.^2))%% 绘制结果figureplot(Convergence_curve,'r')xlabel('迭代次数')ylabel('适应度')title('收敛曲线')figuresubplot(2,2,1);plot(train_result(1,:), 'r-*')hold onplot(Forcast_data(1,:), 'b-o');legend('真实值','拟合值')title('输出训练集拟合效果')subplot(2,2,2);plot(test_result(1,:), 'r-*')hold onplot(Forcast_data_test(1,:), 'b-o');legend('真实值','预测值')title('输出测试集预测效果')subplot(2,2,3);stem(train_result(1,:) - Forcast_data(1,:))title('输出训练集误差')subplot(2,2,4);stem(test_result(1,:) - Forcast_data_test(1,:))title('输出测试集误差')toc%save('灰狼算法预测2-4')3 运行结果

4 参考文献
[1]石峰, 楼文高, 张博. 基于灰狼群智能最优化的神经网络PM2.5浓度预测[J]. 计算机应用, 2017, 037(010):2854-2860.
[2]张文胜, 郝孜奇, 朱冀军,等. 基于改进灰狼算法优化BP神经网络的短时交通流预测模型[J]. 交通运输系统工程与信息, 2020, 20(2):8.
博主简介:擅长智能优化算法、神经网络预测、信号处理、元胞自动机、图像处理、路径规划、无人机等多种领域的Matlab仿真,相关matlab代码问题可私信交流。
部分理论引用网络文献,若有侵权联系博主删除。