在安卓手机上运用AidLux实现人流检测数据统计
目录
第一章 关于AidLux介绍,安装和远程调试
第一节 AidLux介绍
第二节 手机版本AidLux软件安装
第三节 使用vscode进行PC端远程调试AidLux
第二章 ⼈体检测模型的训练和部署测试
第一节 数据集准备
第二节 上传云服务器训练人体检测模型
第三节 在AidLux上测试模型
第三章 实现人流检测数据统计
第一节 人流检测分析
第二节 实现人流数据统计
第一章 关于AidLux介绍,安装和远程调试
第一节 AidLux介绍
AIdlux主打的是基于ARM架构的跨生态(Android/鸿蒙+Linux)一站式AIOT应用开发平 台。可以在安卓手机上直接下载Aidlux使用。同时基于 ARM芯片,比如高通骁龙的855芯片和865芯片,也开发了AidBox边缘设备,提供7T OPS和 15TOPS算力,可以直接在设备上使用。
而实际应用到现场的时候,通常会以几种形态:GPU服务器、嵌入式设 备(比如Android手机、人脸识别闸机等)、边缘设备。GPU服务器我们好理解,而Android 嵌入式设备的底层芯片,通常是ARM架构。而Linux底层也是ARM架构,并且Android又是 基于Linux内核开发的操作系统,两者可以共享Linux内核。因此就产生了从底层开发一套应 用系统的方式,在此基础上同时带来原生Android和原生Linux使用体验。

而使用这些设备平台开发的时候,和在Linux 上开发都是通用的,即Linux上开发的Python代码,可以在安卓手机、边缘设备上转换后使用。

第二节 手机版本AidLux软件安装
目前使用Aidlux主要有两种方式:
(1)边缘设备的方式:阿加犀用高通芯片的S855,和S865制作了两款边缘设备,一款提供 7T算力,一款提供15T算力。
(2)手机设备的方式:没有边缘设备的情况下,也可以使用手机版本的Aidlux,尝试边缘设 备的所有功能。
在手机上下载AidLux软件:
(1)可以在各大应用商店直接搜索AidLux进行下载。

(2)打开手机版本的Aidlux软件APP,第一次进入的时候,APP自带的系统会进行初始化。

初始化好后,进入系统登录页面,这一步最好可以用手机注册一下,当然也可以直接点击“我 已阅读并同意”,然后点击跳过登录。
(3)进入主页面后,可以点击左上角的红色叉号,将说明页面关闭。

(4)可以通过点击AidLux中的cloud_ip显示网络IP地址,可以通过IP地址映射到电脑端,便于操作,需要注意的是手机和电脑必须在同一个局域网内,并且电脑端的登陆初始密码为aidlux。


第三节 使用vscode进行PC端远程调试AidLux
vscode安装可以参考:https://blog.csdn.net/weixin_43883917/article/details/113867914
(1)先将测试的demo文件上传到home文件夹中。
demo文件链接:https://pan.baidu.com/s/1AYauO4kCfLh9GuEHqufZqA?pwd=tdzr
提取码:tdzr

(2)在vscode中安装Remote SSH,点击Vscode左侧的“Extensions”,输入“Remote”,针对跳出的Remote SSH,点击安装。

(3)进行远程连接调试。
点击"Remote Explorer",进行远程连接的页面,点击左下角的“Open a Remote Window”,再选择“Open SSH Configuration file”。

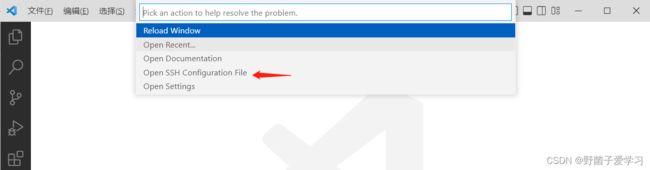
针对跳出的弹窗,再选择第一个config。

输入连接信息,需要注意的是,这里的Host Name填写你自己的Aidlux里面Cloud_ip的地址。

保存后,在左侧会生成一个SSH服务器,鼠标放上后,会跳出一个“Connect to Host in New Window”。
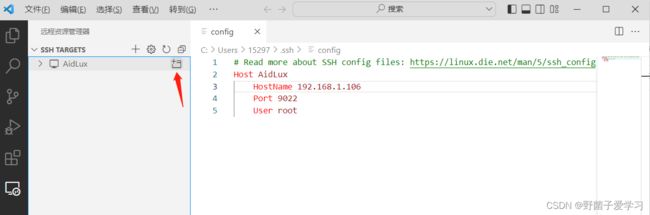
点击窗口,弹出界面选择"Linux",在选择continue,然后输入上面的初始密码。

左下角跳出SSH Aidlux时,表示已经连接成功。

点击打开文件夹,找到home问价夹目录下的demo文件。
开始测试demo,注意的是在Aidlux中读取图片,在显示图片的地方,不能采用cv2.imshow的方式,需要修改成cvs图 形控件模块。
读取图片测试:

读取视频测试:

第二章 ⼈体检测模型的训练和部署测试
第一节 数据集准备
因为需要⼈体检测的模型,在本次任务中主要采⽤旷视开源的Crowdhuman的数据集。
官⽹是:http://www.crowdhuman.org/
Crowdhuman数据集,总共包含三个⽅⾯:15000张的训练数据集,4370张的验证数据集,5000张的测 试数据集。其中训练集和验证集都是有标注信息的,测试集没有标注信息。

数据集下载链接:https://pan.baidu.com/s/1PkIQQnCYP0VLpuUTKmR1kw?pwd=ci6u
提取码:ci6u
本次主要采⽤了val数据集 4370张图⽚,需要下面这2个文件,都在上面的链接里面。

下载完数据集后,需要对人体检测数据集标注⽂件转换,首先自己新建⼀个文件夹CH_data,并将⽹盘下载的Crowdhuman_val.zip 和annotation_val.odgt,全都拷⻉到CH_data中。
将其中的CrowdHuman_val.zip解压缩,可以得到⼀个Images⽂件夹,将Images⽂件夹拷⻉到CH_data路径下,并修改成JPEGImages,此外新建⼀个 Annotations,⽽Annotations⽂件 夹是空的。
接下来需要用代码,将annotation_val.odgt中的标注信息提取出来,变成和4370张图⽚对应的XML格式。
from xml.dom import minidom
import cv2
import os
import json
from PIL import Image
roadlabels = "C:\\Users\\15297\\Desktop\\aidlux\\CH_data\\Annotations"
roadimages = "C:\\Users\\15297\\Desktop\\aidlux\\CH_data\\JPEGImages"
fpath = "C:\\Users\\15297\\Desktop\\aidlux\\CH_data\\annotation_val.odgt"
def load_func(fpath):
assert os.path.exists(fpath)
with open(fpath, 'r') as fid:
lines = fid.readlines()
records = [json.loads(line.strip('\n')) for line in lines]
return records
bbox = load_func(fpath)
if not os.path.exists(roadlabels):
os.makedirs(roadlabels)
for i0, item0 in enumerate(bbox):
print(i0)
# 建立i0的xml tree
ID = item0['ID'] # 得到当前图片的名字
imagename = roadimages + '/' + ID + '.jpg' # 当前图片的完整路径,双斜杠一定要加
savexml = roadlabels + '/' + ID + '.xml' # 生成的.xml注释的名字,双斜杠一定要加
gtboxes = item0['gtboxes']
img_name = ID
floder = 'CrowdHuman'
im = cv2.imread(imagename)
w = im.shape[1]
h = im.shape[0]
d = im.shape[2]
doc = minidom.Document() # 创建DOM树对象
annotation = doc.createElement('annotation') # 创建子节点
doc.appendChild(annotation) # annotation作为doc树的子节点
folder = doc.createElement('folder')
folder.appendChild(doc.createTextNode(floder)) # 文本节点作为floder的子节点
annotation.appendChild(folder) # folder作为annotation的子节点
filename = doc.createElement('filename')
filename.appendChild(doc.createTextNode(img_name + '.jpg'))
annotation.appendChild(filename)
source = doc.createElement('source')
database = doc.createElement('database')
database.appendChild(doc.createTextNode("Unknown"))
source.appendChild(database)
annotation.appendChild(source)
size = doc.createElement('size')
width = doc.createElement('width')
width.appendChild(doc.createTextNode("%d" % w))
size.appendChild(width)
height = doc.createElement('height')
height.appendChild(doc.createTextNode("%d" % h))
size.appendChild(height)
depth = doc.createElement('depth')
depth.appendChild(doc.createTextNode("%d" % d))
size.appendChild(depth)
annotation.appendChild(size)
segmented = doc.createElement('segmented')
segmented.appendChild(doc.createTextNode("0"))
annotation.appendChild(segmented)
# 下面是从odgt中提取三种类型的框并转为voc格式的xml的代码
for i1, item1 in enumerate(gtboxes):
# 提取全身框(full box)的标注
boxs = [int(a) for a in item1['fbox']]
# 左上点长宽->左上右下
minx = str(boxs[0])
miny = str(boxs[1])
maxx = str(boxs[2] + boxs[0])
maxy = str(boxs[3] + boxs[1])
# print(box)
object = doc.createElement('object')
nm = doc.createElement('name')
nm.appendChild(doc.createTextNode('person')) # 类名: fbox
object.appendChild(nm)
pose = doc.createElement('pose')
pose.appendChild(doc.createTextNode("Unspecified"))
object.appendChild(pose)
truncated = doc.createElement('truncated')
truncated.appendChild(doc.createTextNode("1"))
object.appendChild(truncated)
difficult = doc.createElement('difficult')
difficult.appendChild(doc.createTextNode("0"))
object.appendChild(difficult)
bndbox = doc.createElement('bndbox')
xmin = doc.createElement('xmin')
xmin.appendChild(doc.createTextNode(minx))
bndbox.appendChild(xmin)
ymin = doc.createElement('ymin')
ymin.appendChild(doc.createTextNode(miny))
bndbox.appendChild(ymin)
xmax = doc.createElement('xmax')
xmax.appendChild(doc.createTextNode(maxx))
bndbox.appendChild(xmax)
ymax = doc.createElement('ymax')
ymax.appendChild(doc.createTextNode(maxy))
bndbox.appendChild(ymax)
object.appendChild(bndbox)
annotation.appendChild(object)
savefile = open(savexml, 'w')
savefile.write(doc.toprettyxml())
savefile.close()使⽤VScode编程软件打开data_code.py的⽂件夹,⾸先修改其中的roadlabels、roadimages、fpath三 个路径,需要注意的是Crowdhuman中,有三种标注内容,vbox、fbox、hbox,分别对应:可看到的⼈体,完整 ⼈体,⼈脸。本次训练过程中主要使⽤完整⼈体进⾏训练,因此主要⽤到fbox的标签。所以再修改下⾯的两个地⽅,fbox即表示提取annotation_val.odgt中完整⼈体的检测框信息,⽽person表示转换成xml后⼈体的标签名称信息。
运行代码后可以在Annotations中得到4370张VOC格式的xml⽂件。
可以使用Labelimg来进行标注检验,Labelimg安装和教程可以参考:https://blog.csdn.net/knighthood2001。
将CH_data/JPEGImages⾥⾯的xml,复制最前⾯的10个左右xml,粘贴到⽂件夹 CH_data/Annotations⾥⾯。

再使⽤Labelimg⾥⾯的Open Dir打开Annotations⽂件夹,可以看到我们⽣成的标注信息,检查⼀下是否有标注错误的,如果都没有,那说明其他⽣成的也都是对 的。

因为本次主要采⽤Yolov5的算法,因此我们还要将上⾯VOC格式转换成Yolov5可以训练的格式。所以需要对数据进行清理和切分,自己新建一个train_data文件夹,根据下面train_data_split.py代码进行一步一步操作。
import argparse
import xml.etree.ElementTree as ET
from utilis import *
import argparse
label_list = ['person']
def get_image_txt(opt):
#阶段一:对于数据集进行清洗梳理
#第一步:根据images_label_split中的图像删除多余的xml
print("V1")
compare_image_label_remove_xml(opt.train_data)
# # 第二步:根据images_label_split中的图像删除多余的image
# print("V2")
# compare_image_label_remove_image(opt.train_data)
# 第三步:将各个文件夹中的xml不满足条件的文件删除
# print("V3")
# remove_not_satisfied_xml(opt.train_data)
# 第四步:查找xml是否为空,空的话删除xml,也删除对应的image
# print("V4")
# remove_image_null_xml(opt.train_data,label_list)
# 第五步:对照image和xml中数据,显示图片看画得框是否正确
# show_label(opt.train_data,label_list)
# 阶段二:将数据按照一定比例分成训练和验证集
# 将train和test随机分开,将image和xml分别保存到train和test所在的文件夹中
# 根据前面可以得到xml和image,每个场景下选择10%的数据,作为验证集, 生成train和test两个文件夹
#yolov3_get_train_test_file(opt.train_data,0.2)
# 阶段三:将train和test的xml,转换成txt
# 第一步:将train和test中的xml文件生成txt文件,都放到image_txt文件夹中
#yolov3_get_txt(opt.train_data,label_list)
# # 第二步:将所有的image文件一起移动到image_txt中
#yolov3_move_image(opt.train_data)
# # 第三步:将train/Annotations和test/Annotations的xml自动生成train.txt和test.txt文件,并保存到train_test_txt中
#yolov3_get_train_test_txt(opt.train_data)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--train_data', type=str, default='C:\\Users\\15297\\Desktop\\aidlux\\train_data', help='data dir')
opt = parser.parse_args()
get_image_txt(opt)第二节 上传云服务器训练人体检测模型
在这里笔者推荐AutoDLI算⼒云,官⽹链接是:https://www.autodl.com/。
第一步 先将训练和验证集图片上传,为了上传⽅便,将train_data⽂件夹,压缩成⼀个train_data.zip。
第二步 将训练代码Yolov5_code和,进⾏压缩;Yolov5代码,链接:https://pan.baidu.com/s/1WyMsiwKUgBpODxGAmH1oDA?pwd=n51f ,提取码:n51f
第三步 后台上传压缩包。

第四步 创建自己的实例,参考:可基大萌萌哒的马鹿的博客_CSDN博客-LeetCode刷题计划,js常见技巧领域博主
第五步 运行自己的实例后,可以打开jupyter notebook看到自己上传的压缩包。
第六步 在Linlux系统中操作训练和更改代码,使用unzip解压成功过后,需要对标注⽂件xml格式转换txt格式;先查看⼀下训练数据集train_data的路径,因为会涉及到转换后的txt路径,在云服务器上运⾏加训练。 先cd train_data⽂件夹,再输⼊pwd,可以看到这时的数据集路径是:/root/autodl-nas/train_data。

然后再去修改代码中的路径,在Yolov5_code中有一个data_prepare_code文件夹,进入这个文件夹,再vim train_data_split.py使用第三断代码,来实现格式转换。
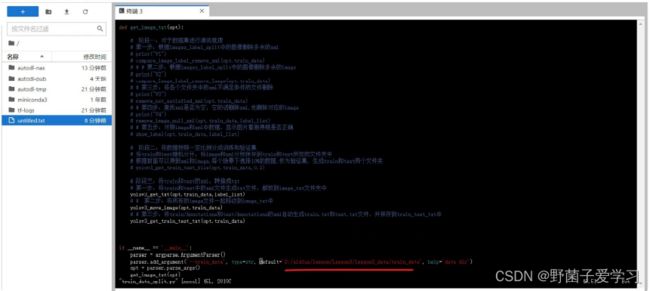
按键盘上的“i”,进⼊代码的编辑状态,移动到路径处,修改成云服务器上对应的路径。

修改完成后,按键盘上的Esc键,跳出编辑状态。 再输⼊“:”,会跳出输⼊框,再输⼊"wq!",表示对于该修改内容,保存编辑强制退出,回到原始⻚⾯。
因为云服务器我们刚刚新建实例的时候,没有安装任何安装包。所以先pip install opencv-python,安装 ⼀下,再进⼊train_data⽂件夹中,会发现多了两个⽂件夹image_txt,train_test_txt,即训练时可以使⽤。
在准备训练人体模型前,还需要更改一下在yolov5_code/data⽂件夹中的个person.yaml文件,训练集和验证集的路径都要修改⼀下,此外还有类别数,以及类别标签。

然后可以在yolov5_code/train.py⽂件中,按照自己的需求更改参数。

在训练的时候,需要⼀系列的库⽂件,所以回到yolov5_code的路径下,输⼊ pip install -r requirements,安装⼀系列的库⽂件 。
安装完成后,输⼊python train.py,就可以开始训练了。

训练过程中,⼀般会得到两个模型,⼀个best.pt,即epoch迭代的过程中,map精度对⽐⽐较好保存的 模型。⼀个是last.pt,即迭代过程中,最后⼀次epoch保存的模型。
在AutoDL的我的⽹盘,找到runs下⾯最新训练⼈体检测模型,路径可以参考:

将best.pt模型下载下来,修改成yolov5n_best.pt。并放到Yolov5_code代码⽂件夹中,至此,我们的人体模型已经训练好了,在后面部署到手机上时,要将pt模型移植到Aidlux上使⽤,还要进⾏转换成tflite模型,模型转换的⽂件是export.py⽂件。
第三节 在AidLux上测试模型
在Aidlux中进行视频推理的代码,放在Yolov5_code中的aidlux文件夹中,⼤家也可以将训 练好的tflite放到aidlux⽂件夹中,有关AidLux推理代码中API,⼤家可以在https://docs.aidlux.com/#/intro/ai/ai-aidlite,查 看下相关的函数说明。
*************和上面⼀样,我们将yolov5的代码,全部上传到Aidlux的home下⾯。
然后在vscode连接好远程调试,打开aidlux文件夹中的yolov5代码,更改好路径,进行视频推理。

执行过后可以看到手机上弹出推理过后的视频。
第三章 实现人流检测数据统计
第一节 人流检测分析
在第二章我们运用yolov5实现了训练了⼀个⼈体检测模型,而人流检测数据统计需要⼈体检测+⼈体追踪 ,因此,需要了解目标跟踪算法。
常⻅的⽬标追踪的算法::⼀种是多⽬标追踪,⼀种是单⽬标追踪;单⽬标追踪,则是在视频分析的过程中,选定某⼀个物体,针对他的整个运动轨迹进⾏分析,多⽬标追踪主要针对的是多个⽬标的运动轨迹,⽽单⽬标追踪主要 针对的某⼀个⽬标的运动轨迹,而在多⽬标跟踪算法中,应⽤的⽐较⼴的发展路径是:sort->deepsort->bytetrack。
有一些不错的文章可以看看:
(1)带你⼊⻔多⽬标跟踪(⼀)领域概述 8
https://zhuanlan.zhihu.com/p/62827974
(2)带你⼊⻔多⽬标跟踪(⼆)SORT&DeepSORT
https://zhuanlan.zhihu.com/p/62858357
(3)带你⼊⻔多⽬标跟踪(三)匈⽛利算法&KM算法
https://zhuanlan.zhihu.com/p/62981901
(4)带你⼊⻔多⽬标跟踪(四)外观模型 Appearance Model https://zhuanlan.zhihu.com/p/63189011
(5)ByteTrack: Multi-Object Tracking by Associating Every Detection Box阅读笔记 https://zhuanlan.zhihu.com/p/421264325
第二节 实现人流数据统计
检测人流数据,可以规划一个越界区域,分成-1和1,我们将⼈体在监测区域内设置为1,不在监测区域内设置为-1,来达到人流数据统计的目的。
越界区域代码
from cvs import *
import cv2
from utils import process_points
# # ### 保存图片 ###
# cap = cvs.VideoCapture("/home/lesson5_codes/aidlux/video.mp4")
# frame = cap.read()
# cv2.imwrite("image.jpg",frame)
# cap.release()
# cv2.destroyAllWindows()
### 显示监测区域 ###
cap = cvs.VideoCapture("/home/lesson5_codes/aidlux/video.mp4")
frame_id = 0
while True:
frame = cap.read()
if frame is None:
continue
# 绘制越界监测区域
color_light_green=(144, 238, 144) ##浅绿色
res_img=cv2.line(frame,[186,249],[1235,366],color_light_green,3)
cvs.imshow(res_img)
人流数据统计代码
链接:https://pan.baidu.com/s/1yc06nu7hzGHqeDmXTSc3BQ?pwd=aca8
提取码:aca8
打开aidlux文件夹中的yolov5_overstep.py运行,就可以完成人流的统计了。
