使用MobileNetv2实现图像分类
简介
目前的神经网络模型层出不穷,其中在图像识别的领域不仅非常高效快速,而且准确率也非常高。但我们在提高准确率的道路上是永不止步的,比较矛盾的是在提高精确率的同时也会带来消耗,需要更高的计算资源,这对模型的应用是很大的门槛。本次分享小Mi给大家介绍一个神经网络模型Mobilenet_V2。该模型骨骼精奇,独特的网络结构设计可以减少训练过程中的计算次数和对内存的占用,下面我们一起探讨学习下。
MindSpore深度学习框架中的MobileNet_V2可以结合硬件感知神经网络架构搜索(NAS)和NetAdapt算法,移植到手机CPU上运行,不过本次仅从基础使用介绍,没有涉及手机上运行,感兴趣的同学可以自己Moilenet_V2教程参考尝试下哦。
Mobilenet_V2介绍
在减少计算量和堆内存的占用方面,Mobilenet_V2的结构设计主要有以下几点改进。
深度可分离卷积(Depthwise Separable Convolutions):深度可分离卷积块对提高网络结构的高效性是非常有效的,论文作者在MobileNet_V2模型中也使用了这种结构。简单的解释为:把原始的一层正常卷积分解成两层的卷积。分解后的两层第一层叫做depthwise卷积,它的filter的参数很少,是对输入的每一个channel进行单独的卷积运算。第二层是一个1x1的卷积,叫做pointwise卷积,可以改变channel的个数,直观的结构设计如下图。
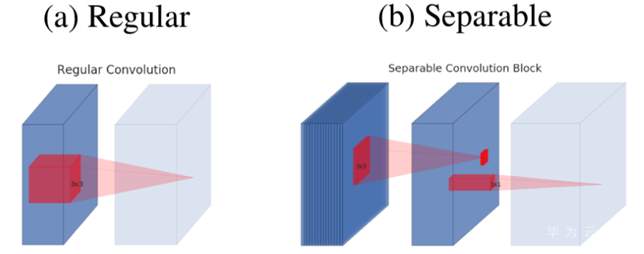
我们再从从计算量上分析。在常规的卷积计算中,如果我们输入是
![]()
,卷积的kernel是,输出设定为,这样卷积过程中的计算量就是。如果我们使用可分离卷积的方法,需要的计算量就会是。假设我们的卷积的k=3,可分离卷积的计算量要比普通卷积的计算量减少80%多,但是也会有些精度损失。
线性瓶颈(Linear Bottlenecks):这也是模型原作者提到的一点,可以理解为当channel的个数比较少的时候,所有的信息就会集中在比较窄的channel中,如果这个时候进行非线性激活就会造成很多信息的丢失。而在MobileNet V1中引入的一个超参数width multiplier会缩减channel,这样看起来就像一个瓶子的颈部一样。下图是作者一个直观的展示。

可以很明显的发现如果channel越小,输出与输入的差距越大,表示丢失的信息越多,随着channel的逐渐增大,丢失的信息会越来越少。理解起来就是,假设当channel为2时,信息都会集中在这两个channel中,如果有部分数值小于0就会被RELU激活丢失掉。而如果channel为30,其实信息就相对分散一些,所以就算通过非线性函数Relu激活后归于0的值可能并不会影响太多信息的存储。
所以作者建议是对于channel数很少的那些网络层做线性激活。bottlenect就表示缩减的层,linear bottleneck表示对channel缩减的网络层做线性函数激活。如果要用Relu激活需要先增加channel数再做Relu激活。而且原文中非线性激活函数使用Relu6,Relu6=min(max(features, 0), 6),这个函数应该更适用于这个模型。
倒置残差(Inverted residuals):可以非常有效的解决线性瓶颈的问题。因为考虑到如果channel比较少的时候,tensor的信息会特别集中,在使用非线性激活会造成信息的损失,应对的策略可以是对channel比较少的tensor进行channel的扩张。而残差block是先进行channel缩减,然后扩张,这样可能会丢失信息。作者就设计了一种倒置的残差block,先进行channel扩张,然后进行channel缩减。如下图显示对比,虚线的tensor后进行线性激活,这种倒置残差block是作者对残差block提出的一个改进。详细结构如下图所示
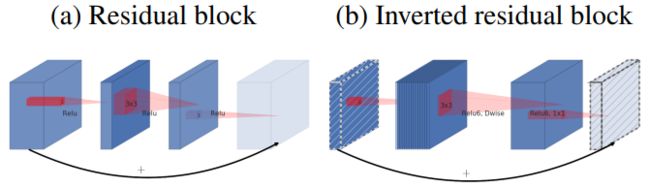
然后再结合我们上面说到的深度可分离卷积,深度可分离卷积+倒置残差的结构如下图所示
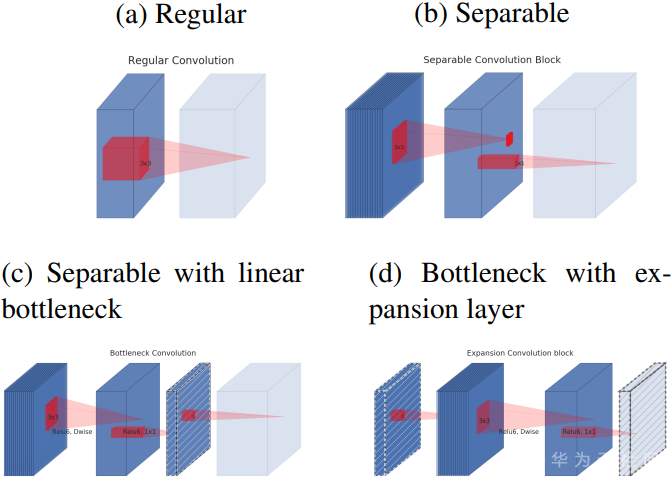
上图就是论文中展示的各种结构的对比,a是普通卷积结构,b是深度分离卷积结构,c是有bottlenect的分离卷积,d是对bottlenect进行扩张后的分离卷积。图中所有虚线的tensor后面都是线性激活。d的结构和导致残差结构就是有无shorcut连接的差别,详细的计算如下图。

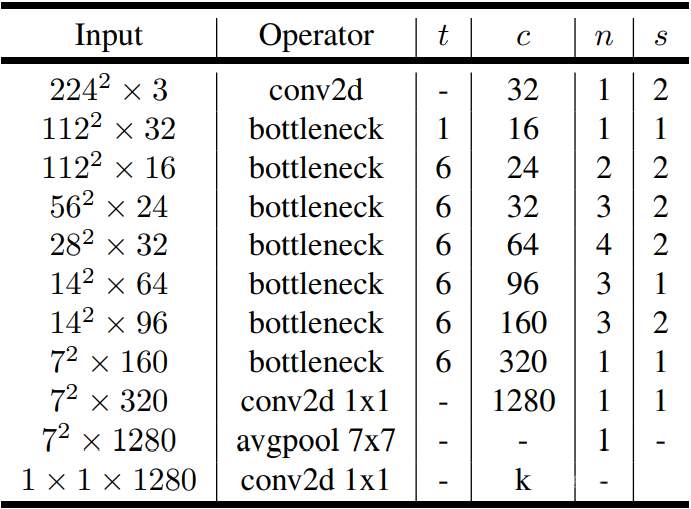
以上几点就是MobileNet_V2模型的关键创新,同时附上完整的计算图给大家参考
原文请见:https://arxiv.org/pdf/1801.04381.pdf
ImageNet数据集介绍
ImageNet数据是CV领域非常出名的数据集,ImageNet图像数据集始于2009年,CVPR2009上发表了一篇名为《ImageNet: A Large-Scale Hierarchical Image Database》的论文,之后就是基于ImageNet数据集的7届ImageNet挑战赛(2010年开始),2017年后,ImageNet由Kaggle继续维护。
ImageNet是一项持续的研究工作,目前ImageNet中总共有14197122幅图像,总共分为21841个类别(synsets),也是目前世界上图像识别最大的数据库。ImageNet拥有用于分类、定位和检测任务评估的数据,与分类数据类似,定位任务有1000个类别。所有图像中至少有一个边框。对200个目标的检测问题有470000个图像,平均每个图像有1.1个目标。
该数据集是公开的,所以我们想要下载使用也比较方便。下载页面如下图所示,可以通过此链接下载:http://www.image-net.org/download-imageurls
数据集大小:125G,共1000个类、1.2万张彩**像
训练集:120G,共1.2万张图像
测试集:5G,共5万张图像
数据格式:RGB
MindSpore中的MobileNet_V2
MindSpore的仓库中有完整的模型教程和脚本,详细的链接可见:models: Models of MindSpore - Gitee.com
有完整的目录指导我们进行配置训练,这里可以更细致的了解MindSpore框架对MobileNet_V2模型的实现,也可以学习到使用MindSpore训练的步骤方法方法和特性。
模型训练
以上内容我们介绍了Moilenet_V2网络模型、ImageNet数据集和MindSpore中的说明使用。现在我们按照教程中的步骤尝试下,这里使用的环境是Windows系统+1.5.0版本的MindSpore,因为是使用CPU硬件,所以也需要设置下参数,保证能够识别出硬件环境。
if config.platform == "CPU":
context.set_context(mode=context.GRAPH_MODE, device_target=config.platform, \
save_graphs=False)
MindSpore提供了完整的训练脚本,所以我们可以我们所直接在Gitee中克隆MindSpore开源项目仓库,详细的位置链接:models: Models of MindSpore - Gitee.com
本次使用的python文件,在运行train.py的时候也需要设置 config_path、dataset_path、platform、pretrain_ckpt与freeze_layer五个参数。验证时,运行eval.py并且传入config_path、dataset_path、platform、pretrain_ckpt四个参数。命令如下
Windows train with Python file
python train.py --config_path [CONFIG_PATH] --platform [PLATFORM] --dataset_path
Windows eval with Python file
python eval.py --config_path [CONFIG_PATH] --platform [PLATFORM] --dataset_path
以上便是训练该模型的基本的步骤。当然不同的环境会有不同的配置和运行方法,支持Windows和Linux系统,支持CPU、GPU和Ascend硬件平台上使用,详细的参数设置和使用请大家参考官网中教程:使用MobileNetV2网络实现微调(Fine Tune) — MindSpore master documentation
总结
本次小Mi分享的第一部分主要给大家介绍了Moilenet_V2网络模型的深度可分离卷积结构,模型中所遇到的线性瓶颈问题,以及应对线性瓶颈问题所提出的倒置残差解决方法。第二部分介绍了ImageNet数据集的基本参数信息,也提供了数据集下载的地址。第三部分是介绍了MindSpore的框架中的Moilenet_V2模型的脚本和信息,以及官网教程中的运行指导,欢迎大家尝试,如果有使用问题欢迎留言交流哦!