机器学习中过拟合和欠拟合的案例代码分析
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(666)
x = np.random.uniform(-3,3,size = 100) #均匀随机分布
# 线性回归模型需要二维数组
X = x.reshape(-1,1)
y = 0.5* x**2 + x+2 +np.random.normal(0,1,size = 100)#+np...均值为0方差为1正态分布的噪声
from sklearn.linear_model import LinearRegression
estimator = LinearRegression()
estimator.fit(X,y)
y_predict = estimator.predict(X)
#绘制图像
plt.scatter(x,y)
plt.plot(x,y_predict,color = 'r')
plt.show()
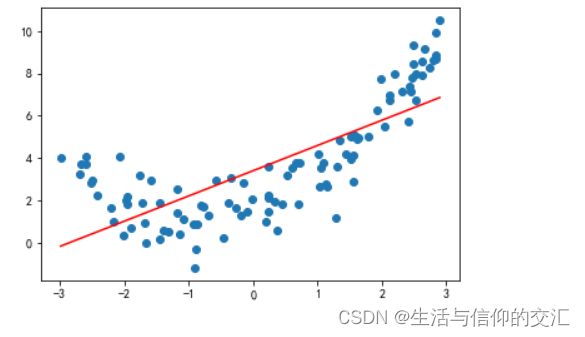
#计算均方误差
from sklearn.metrics import mean_squared_error
mean_squared_error(y,y_predict)
#3.0750025765636577
- 添加二次项,绘制图像
X2 = np.hstack([X,X**2])
estimator2 = LinearRegression()
estimator2.fit(X2,y)
y_predict2 = estimator2.predict(X2)
plt.scatter(x,y)
plt.plot(np.sort(x),y_predict2[np.argsort(x)],color = 'r')
plt.show()
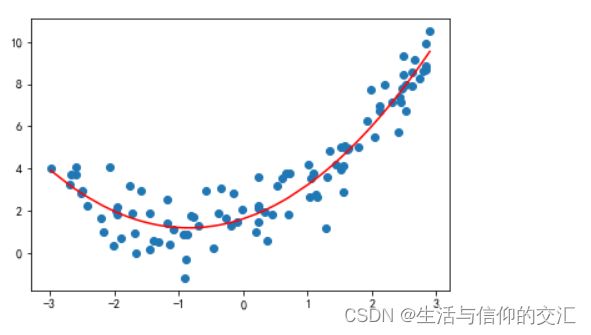
#计算均方误差和准确率
from sklearn.metrics import mean_squared_error
mean_squared_error(y,y_predict2)
#1.0987392142417858
- 可以看到二次拟合更精准
- 再次加入高次项,绘制图像,观察均方误差结果
X5 = np.hstack([X2,X**3,X**4,X**5,X**6,X**7,X**8,X**9,X**10])
estimator3 = LinearRegression()
estimator3.fit(X5,y)
y_predict5 = estimator3.predict(X5)
plt.scatter(x,y)
plt.plot(np.sort(x),y_predict5[np.argsort(x)],color = 'r')#np.sort排序x从小到大排序
plt.show()
error = mean_squared_error(y, y_predict5)
error
#1.0508466763764157
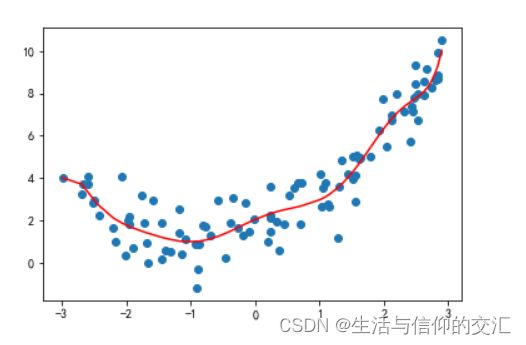
-
随着加入的高次项越来越多,拟合程度越来越高,均方误差也随着加入越来越小。
- X的测试集均方误差
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state = 5)
estimator = LinearRegression()
estimator.fit(X_train,y_train)
y_predict = estimator.predict(X_test)
mean_squared_error(y_test,y_predict)
#3.153139806483088
- X2的测试集均方误差
X_train,X_test,y_train,y_test = train_test_split(X2,y,random_state = 5)
estimator = LinearRegression()
estimator.fit(X_train,y_train)
y_predict = estimator.predict(X_test)
mean_squared_error(y_test,y_predict)
#1.111873885731967
- X5的测试集的均方误差
X_train,X_test,y_train,y_test = train_test_split(X5,y,random_state = 5)
estimator = LinearRegression()
estimator.fit(X_train,y_train)
y_predict = estimator.predict(X_test)
mean_squared_error(y_test,y_predict)
#1.4145580542309835
欠拟合产生原因: 学习到数据的特征过少
解决办法:
1)添加其他特征项,有时出现欠拟合是因为特征项不够导致的,可以添加其他特征项来解决
2)添加多项式特征,模型过于简单时的常用套路,例如将线性模型通过添加二次项或三次项使模型泛化能力更强
过拟合产生原因: 原始特征过多,存在一些嘈杂特征, 模型过于复杂是因为模型尝试去兼顾所有测试样本
解决办法:
1)重新清洗数据,导致过拟合的一个原因有可能是数据不纯,如果出现了过拟合就需要重新清洗数据。
2)增大数据的训练量,还有一个原因就是我们用于训练的数据量太小导致的,训练数据占总数据的比例过小。
3)正则化
4)减少特征维度