大数据技术基础实验九:Hive实验——部署Hive
大数据技术基础实验九:Hive实验——部署Hive
文章目录
- 大数据技术基础实验九:Hive实验——部署Hive
-
- 一、前言
- 二、实验目的
- 三、实验要求
- 四、实验原理
- 五、实验步骤
-
- 1、安装部署
- 2、配置HDFS
- 3、启动Hive
- 4、Hive基本命令
- 六、最后我想说
一、前言
本周我们学习了有关Hive的相关基础知识,紧接着我们就将开始有关Hive的实验,周四开始做实验,我提前开始写,后面我就来试试Hive的创建表操作。
二、实验目的
- 理解Hive存在的原因
- 理解Hive的工作原理
- .理解Hive的体系架构
- 并学会如何进行内嵌模式部署
- 启动Hive,然后将元数据存储在HDFS上
三、实验要求
- 完成Hive的内嵌模式部署
- 能够将Hive数据存储在HDFS上
- 待Hive环境搭建好后,能够启动并执行一般命令
四、实验原理
Hive是Hadoop 大数据生态圈中的数据仓库,其提供以表格的方式来组织与管理HDFS上的数据、以类SQL的方式来操作表格里的数据,Hive的设计目的是能够以类SQL的方式查询存放在HDFS上的大规模数据集,不必开发专门的MapReduce应用。
Hive本质上相当于一个MapReduce和HDFS的翻译终端,用户提交Hive脚本后,Hive运行时环境会将这些脚本翻译成MapReduce和HDFS操作并向集群提交这些操作。
当用户向Hive提交其编写的HiveQL后,首先,Hive运行时环境会将这些脚本翻译成MapReduce和HDFS操作,紧接着,Hive运行时环境使用Hadoop命令行接口向Hadoop集群提交这些MapReduce和HDFS操作,最后,Hadoop集群逐步执行这些MapReduce和HDFS操作,整个过程可概括如下:
(1)用户编写HiveQL并向Hive运行时环境提交该HiveQL。
(2)Hive运行时环境将该HiveQL翻译成MapReduce和HDFS操作。
(3)Hive运行时环境调用Hadoop命令行接口或程序接口,向Hadoop集群提交翻译后的HiveQL。
(4)Hadoop集群执行HiveQL翻译后的MapReduce-APP或HDFS-APP。
由上述执行过程可知,Hive的核心是其运行时环境,该环境能够将类SQL语句编译成MapReduce。
Hive构建在基于静态批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive 并不能够在大规模数据集上实现低延迟快速的查询,例如,Hive 在几百MB 的数据集上执行查询一般有分钟级的时间延迟。
因此,Hive 并不适合那些需要低延迟的应用,例如,联机事务处理(OLTP)。Hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,Hive 将用户的HiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
Hive架构与基本组成如下图所示:

五、实验步骤
相对于其他组件,Hive部署要复杂得多,按metastore存储位置的不同,其部署模式分为内嵌模式、本地模式和完全远程模式三种。当使用完全模式时,可以提供很多用户同时访问并操作Hive,并且此模式还提供各类接口(BeeLine,CLI,甚至是Pig),这里我们以内嵌模式为例。
由于使用内嵌模式时,其Hive会使用内置的Derby数据库来存储数据库,此时无须考虑数据库部署连接问题,整个部署过程可概括如下。
1、安装部署
我们首先在master机上确定存在Hive:
ls /usr/cstor/hive/
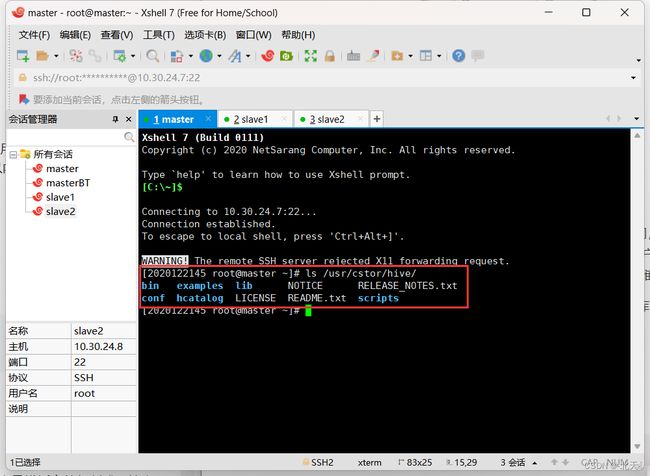
可以看到能显示hive文件夹内的文件,证明存在hive。
2、配置HDFS
先为Hive配置Hadoop安装路径。
待解压完成后,进入Hive的配置文件夹conf目录下,接着将Hive的环境变量模板文件复制成环境变量文件。
cd /usr/cstor/hive/conf
cp hive-env.sh.template hive-env.sh
vim hive-env.sh

这里使用cp命令而不是mv命令,是因为我们可以备份一份之前的文件,我们只是复制一份修改,而不是替换。
然后我们再配置文件中加入如下语句:
HADOOP_HOME=/usr/cstor/hadoop

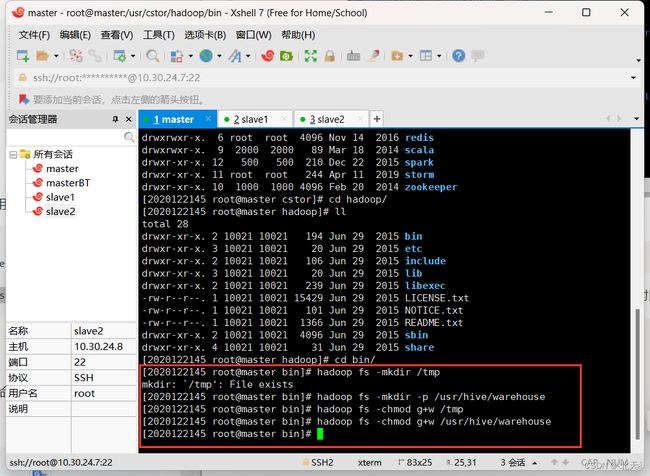
然后我们在HDFS里新建Hive的存储目录,进入hadoop的bin目录内:
cd /usr/cstor/hadoop/bin
然后在HDFS中新建/tmp 和 /usr/hive/warehouse 两个文件目录,并对同组用户增加写权限。
hadoop fs -mkdir /tmp
hadoop fs -mkdir -p /usr/hive/warehouse
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /usr/hive/warehouse
3、启动Hive
在内嵌模式下,启动Hive指的是启动Hive运行时环境,用户可使用下述命令进入Hive运行时环境。
首先我们进入hive内的bin目录中:
cd /usr/cstor/hive/bin/
然后直接执行hive命令:
hive
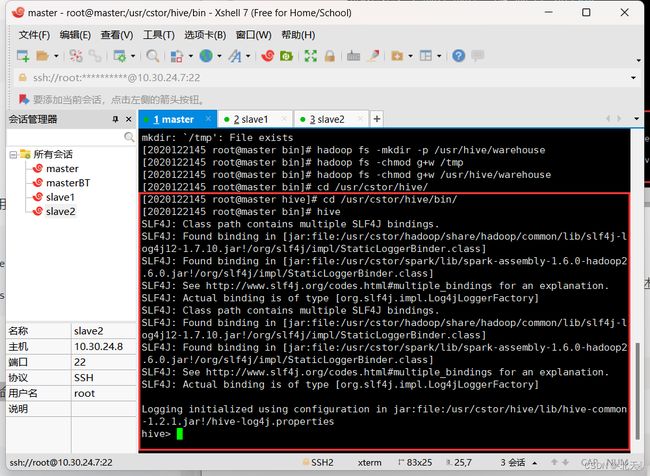
可以看到我们启动Hive成功了。
4、Hive基本命令
我们在Hive中写几个基本命令看看。
显示表:
show tables;

因为目前我们没有创建表所以返回了一个OK。
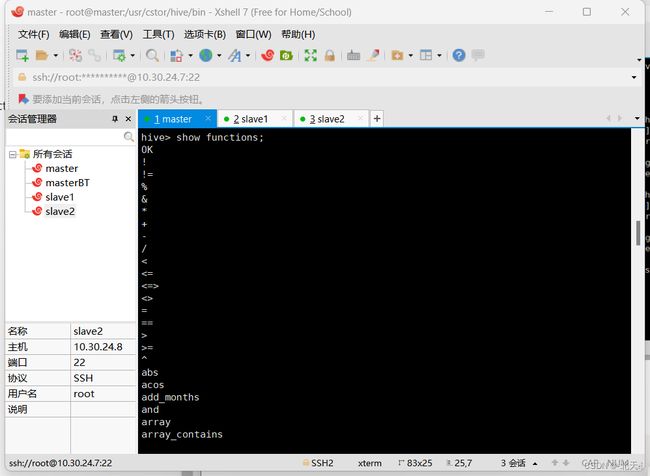
显示Hive内置函数:
show functions;
六、最后我想说
本次实验内容非常的简单,部署Hive和启动Hive很快就能成功,重要的是后面的Hive语句学习,后面我会更新有关这方面的博客的。
谢谢大家!