【机器学习】决策树实验报告
三、实验目的
利用决策树算法对数据进行训练建模,并实现输入一组数据就能预测出结果。
四、实验内容
1、实验背景与问题提出
决策树是一种非参数化监督学习方法,用于分类和回归。目标是创建一个模型,通过学习从数据功能推断出的简单决策规则来预测目标变量的值。决策树的一些优点是:简单易懂和解释,可以可视化。适用于小数据集。能够同时处理数字和分类数据,能够处理多输出问题。可解释性强,可以使用统计测试验证模型。缺点:决策树会出现过拟合,为了避免此问题,需要剪枝或者在叶节点设置所需的最小样本数量或设置树的最大深度等机制。决策树学习算法基于启发式算法,如贪婪算法,在每个节点做出本地最佳决策。此类算法无法保证返回全局最佳决策树。这可以通过在交叉验证中训练多棵树来缓解,其中样本被随机采样并更换。
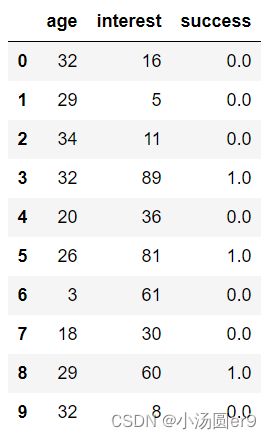
本次实验数据来源于Kaggle官网中的一个Beginner's Classification Dataset小数据集,数据集描述的是一组被测试者的年龄和该运动感兴趣程度对该测试者学好该项运动的影响。数据集中有297个样本,3个属性:age、interest、success,其中age、intrest为连续型数据,success为只取0或1的标签,表示该项运动是否学习成功。本次实验旨在用决策树算法实现分类、可视化,并实现输入一个年龄和兴趣值既可以预测是否学习成功的功能。
2、解决思路
首先读取数据,查看数据的基本信息,发现没有空缺值。箱线图(别名:盒子图),利用数据中的五个统计量:最小值、第一四分位数、中位数、第三四分位数与最大值来描述数据的一种方法。它可以直观明了地识别数据批中的异常值,利用箱线图判断数据批的偏态和尾重,也可以粗略地看出数据是否具有有对称性,分布的分散程度等信息。因此选择绘制箱线图来观察属性age、interest是否有异常值,以及属性值的分布情况:

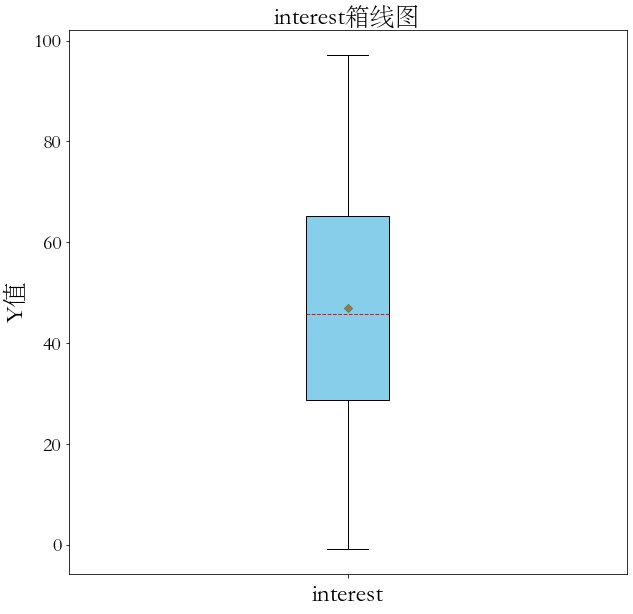
图1 数据箱线图
从箱线图中可以看出两个属性下均没有异常值,并且age取值范围大概为3-47,interest的取值范围大致为0-100。下图给出部分实验数据:


图2 部分数据取值
接着选取80%的数据作为训练集训练决策树模型,并将训练好的决策树模型可视化后得到如图3的决策树:树的高度为9,此时分类准确率为96.67%。为了观察建立的决策树模型随测试集大小变化其分类准确率的变化情况,先初始选取了0.001大小的测试集,以0.05的步长依次增大测试集的大小,每次循环训练一个决策树模型;并记录该决策树模型在测试集上的表现情况。由于测试集越大,训练集就越小,训练出的决策树模型可能分类效果就越不好。最后得到了图5随着测试集大小分类准确率变化情况的折线图,通过图三选取最后参与预测的模型。
为了实现输入一个年龄和对运动的兴趣值就预测出该学者是否能学好这项运动的功能,结合图5,选取测试集为0.2的决策树作为模型来进行后续预测。利用随机生成age和interest数据作为测试数据,观察10组测试数据的预测结果是否合理。

图3 决策树可视化
3、算法步骤
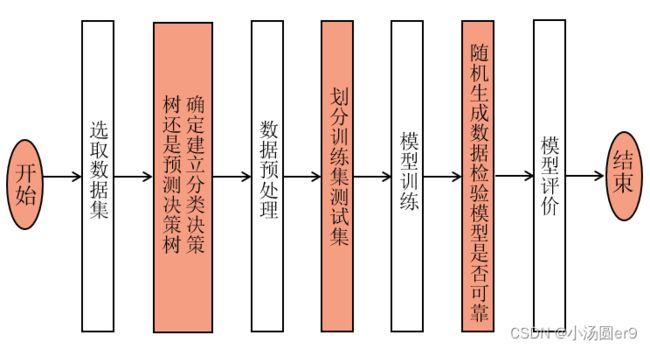
图4 算法步骤
4、结果分析
利用逐步改变测试集的大小,得到的结果图如图5:初始值测试集占比为0.001,此时分类准确率最高,但是很可能出现过拟合的情况。为了使预测的结果更加可靠,实验选取了0.2的验证集,0.8的训练集训练出的模型作为预测模型。
 标题
标题
图5 分类准确率随测试机大小变化折线图
前面我们已经知道了年龄和兴趣指数的取值范围,这里我们通过随机生成age和interest的方法进行了三组实验,每组实验测试10个数据,得到了如图6的结果。从第(1)组的6、8可以发现在具有相近兴趣值的情况下,年龄越小越不容易学好一项运动;观察(2)组的7号和(3)组的9号可以发现相近的兴趣值,年龄太大也不容易学好一项运动;最后从整体来看,相近的年龄,兴趣越高越容易学好一项运动。


- (2) (3)
图6 三组随机生成数据预测结果
import math
import warnings
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib as mpl
from sklearn import tree
from pylab import rcParams
from matplotlib import font_manager
from matplotlib import pyplot as plt
from sklearn.metrics import r2_score
from sklearn.model_selection import train_test_split
warnings.filterwarnings('ignore')
#参数设置
myfont = mpl.font_manager.FontProperties(fname="C:\Windows\Fonts\STSONG.TTF",size=25)
legend_font = mpl.font_manager.FontProperties(fname="C:\Windows\Fonts\STSONG.TTF",size=25)
plt.rcParams['font.sans-serif'] = ['STSONG']
plt.rcParams['axes.unicode_minus'] = False
#1. 加载数据
df = pd.read_csv(r"classification.csv",engine='python')
print("数据集形状和基本信息为:",len(df),len(df.iloc[0]))
df1=df.iloc[:,0:2]
#2. 数据预处理,删除空值
#查看数据分布情况,是否存在异常值
def view(X,Title):
plt.figure(figsize=(6,6))
plt.boxplot(x = np.array(X)[:,0].T, # 指定绘图数据
patch_artist=True, # 要求用自定义颜色填充盒形图,默认白色填充
showmeans=True, # 以点的形式显示均值
boxprops = {'color':'black','facecolor':'#9999ff'}, # 设置箱体属性,填充色和边框色
flierprops = {'marker':'o','markerfacecolor':'red','color':'black'}, # 设置异常值属性,点的形状、填充色和边框色
meanprops = {'marker':'D','markerfacecolor':'indianred'}, # 设置均值点的属性,点的形状、填充色
medianprops = {'linestyle':'--','color':'orange'}) # 设置中位数线的属性,线的类型和颜色
plt.tick_params(labelsize=20)
plt.xlabel(Title,fontproperties=myfont)
plt.ylabel("Y值",fontproperties=myfont)
The_title=Title+"箱线图"
plt.title(The_title,fontproperties=myfont)
plt.show()
view(df[["age"]],"age")
view(df[["interest"]],"interest")
#3. 划分训练、测试数据集
X=df1
y=df[["success"]]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
plt.figure(dpi=500)
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X_train, y_train)
tree.plot_tree(clf,filled=True)
plt.show()
score=clf.score(X_test,y_test)
print("预测得分为:",score)
Score=[]
testsaiz=[]
saiz=0.001
for i in range(17):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=saiz, random_state=42)
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X_train, y_train)
Score.append(round(clf.score(X_test,y_test),4))
testsaiz.append(saiz)
saiz=saiz+0.05
#print("testsaiz",saiz)
plt.figure(figsize=(12,8))
plt.plot(testsaiz,Score,c='lime',marker="p")
plt.grid(linestyle=":", color="deepskyblue")
plt.tick_params(labelsize=20)
plt.xlabel(r'测试集大小',fontproperties=myfont)
plt.ylabel('分类准确率%',fontproperties=myfont)
plt.legend(fontsize=20)
plt.show()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
plt.figure(dpi=500)
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X_train, y_train)
#随机生成10组测试数据
import random
suijiage=[]
suijiinterest=[]
for i in range(10):
suijiage.append(random.randint(3,47))
suijiinterest.append(random.randint(0,100))
suijiTEST=pd.DataFrame(columns=["age","interest"])
suijiTEST[["age"]]=pd.DataFrame(suijiage)
suijiTEST[["interest"]]=pd.DataFrame(suijiinterest)
result=clf.predict(suijiTEST)
suijiTEST[["success"]]=pd.DataFrame(result)
suijiTEST五、实验总结
- 决策树防止过拟合可以通过剪枝或者控制树的高度来实现。剪枝分为预剪枝和后剪枝;预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点。后剪枝是先生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。
- 对于异常值有一定的容错能力。
- 决策树和其他模型相比有以下优点:生成的规则可理解;效率高,决策树只需要一次构建,反复使用,每一次预测的最大计算次数不超过决策树的深度;决策树算法的时间复杂度较小,为用于训练决策树的数据点的对数。
- 决策树的目标函数是最小化损失函数,损失函数是正则化最大似然函数。
- 分类树采用叶子节点里概率最大的类别作为当前节点的预测类别。回归树输出采用的是用最终叶子的均值或者中位数来预测输出结果。
- 决策树会因为样本发生一点点的改动,就会导致树结构的剧烈改变。这个可以通过集成学习之类的方法解决。