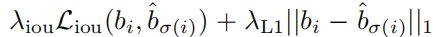detr目标检测算法源码详解
1.图像数据加上mask
对于每一批次的图像,首先找出每一批次图片的H,W的最大值Hmax,Wmax,然后将原始图像填充为3*Hmax*Wmax大小,并将图像部分置为False,填充部分置为True.最后将图像数据tensor和mask打包为nesttensor格式
(从nesttensor取出tensors和mask只需要调用方法tensor_list.tensors、tensor_list.mask即可)
代码如下:
def nested_tensor_from_tensor_list(tensor_list: List[Tensor]):
# TODO make this more general
"""
- samples.tensor: batched images, of shape [batch_size x 3 x H x W]
- samples.mask: a binary mask of shape [batch_size x H x W], containing 1 on padded pixels
"""
if tensor_list[0].ndim == 3:
if torchvision._is_tracing():
# nested_tensor_from_tensor_list() does not export well to ONNX
# call _onnx_nested_tensor_from_tensor_list() instead
return _onnx_nested_tensor_from_tensor_list(tensor_list)
# TODO make it support different-sized images
# bach_size中能够接受所有图片大小的图片size
# C*H*W
max_size = _max_by_axis([list(img.shape) for img in tensor_list])
# min_size = tuple(min(s) for s in zip(*[img.shape for img in tensor_list]))
# Batch_size * C *H*W
batch_shape = [len(tensor_list)] + max_size
b, c, h, w = batch_shape
dtype = tensor_list[0].dtype
device = tensor_list[0].device
# 生成mask,有图像部分全为False,填充部分全为true
tensor = torch.zeros(batch_shape, dtype=dtype, device=device)
mask = torch.ones((b, h, w), dtype=torch.bool, device=device)
for img, pad_img, m in zip(tensor_list, tensor, mask):
pad_img[: img.shape[0], : img.shape[1], : img.shape[2]].copy_(img)
m[: img.shape[1], :img.shape[2]] = False
else:
raise ValueError('not supported')
return NestedTensor(tensor, mask)2.backbone部分
(1)位置编码
位置编码提供了两种编码方式,一种是正弦编码,一种是可以学习的编码,默认为正弦编码。
正弦编码:
取出mask,对mask进行取反,因为编码方式为二维编码,我们对行、和列分别进行累加,作为每一个维度的编码,并进行归一化,转化为角度。同时我们假设编码的每一维度都由一个128维的向量组成。然后,我们按照如下正弦编码方式进行编码,对奇数求余弦,偶数求正弦。编码后,x_emding,y_emding的维度均为batch*h*w*128

代码如下:
class PositionEmbeddingSine(nn.Module):
"""
This is a more standard version of the position embedding, very similar to the one
used by the Attention is all you need paper, generalized to work on images.
"""
def __init__(self, num_pos_feats=64, temperature=10000, normalize=False, scale=None):
super().__init__()
self.num_pos_feats = num_pos_feats
self.temperature = temperature
self.normalize = normalize
if scale is not None and normalize is False:
raise ValueError("normalize should be True if scale is passed")
if scale is None:
scale = 2 * math.pi
self.scale = scale
def forward(self, tensor_list: NestedTensor):
# shape:2, 2048, 24, 29
x = tensor_list.tensors
# print(x.shape)
# shape:2, 24, 29
mask = tensor_list.mask
# print(mask.shape)
assert mask is not None
# 取反
not_mask = ~mask
# 行方向累加 2, 24, 29
y_embed = not_mask.cumsum(1, dtype=torch.float32)
# print(y_embed.shape)
# 列方向累加 2, 24, 29
x_embed = not_mask.cumsum(2, dtype=torch.float32)
# print(x_embed.shape)
# 归一化,并转化为角度
if self.normalize:
eps = 1e-6
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale
# 假设横纵坐标都有128个,套用正弦编码公式
dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
# print(dim_t.shape)
dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats)
# print(dim_t.shape)
# 2, 24, 29, 128
pos_x = x_embed[:, :, :, None] / dim_t
# print(pos_x.shape)
# 2, 24, 29, 128
pos_y = y_embed[:, :, :, None] / dim_t
# print(pos_y.shape)
pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3)
# print(pos_x.shape)
# 2, 24, 29, 128
pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)
# print(pos_y.shape)
# 2, 24, 29, 128
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
# print(pos.shape)
return posbackbone:直接使用pytorch的resnet迁移学习模型,对图像数据tensor进行卷积操作,对mask进行下采样操作
class BackboneBase(nn.Module):
def __init__(self, backbone: nn.Module, train_backbone: bool, num_channels: int, return_interm_layers: bool):
super().__init__()
for name, parameter in backbone.named_parameters():
if not train_backbone or 'layer2' not in name and 'layer3' not in name and 'layer4' not in name:
parameter.requires_grad_(False)
# 获取中间层结果
if return_interm_layers:
return_layers = {"layer1": "0", "layer2": "1", "layer3": "2", "layer4": "3"}
else:
return_layers = {'layer4': "0"}
# 获取模型中间层的输出
self.body = IntermediateLayerGetter(backbone, return_layers=return_layers)
self.num_channels = num_channels
def forward(self, tensor_list: NestedTensor):
# 对tensor进行卷积
xs = self.body(tensor_list.tensors)
out: Dict[str, NestedTensor] = {}
for name, x in xs.items():
m = tensor_list.mask
assert m is not None
# 对mask进行下采样
mask = F.interpolate(m[None].float(), size=x.shape[-2:]).to(torch.bool)[0]
# 结果转换为NestedTensor格式
out[name] = NestedTensor(x, mask)
return out
class Backbone(BackboneBase):
"""ResNet backbone with frozen BatchNorm."""
def __init__(self, name: str,
train_backbone: bool,
return_interm_layers: bool,
dilation: bool):
# 加载模型
backbone = getattr(torchvision.models, name)(
replace_stride_with_dilation=[False, False, dilation],
pretrained=is_main_process(), norm_layer=FrozenBatchNorm2d)
num_channels = 512 if name in ('resnet18', 'resnet34') else 2048
super().__init__(backbone, train_backbone, num_channels, return_interm_layers)resnet结构:
Backbone(
(body): IntermediateLayerGetter(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): FrozenBatchNorm2d()
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d()
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d()
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d()
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
)
)
)
)联合起来:首先将数据输入resnet,进行卷积同时对mask进行下采样,然后运行位置编码层,进行位置编码
class Joiner(nn.Sequential):
def __init__(self, backbone, position_embedding):
super().__init__(backbone, position_embedding)
def forward(self, tensor_list: NestedTensor):
# print(tensor_list.tensors.shape)
# 前项传播,将数据输入backbone,shape:2, 3, 765, 911
xs = self[0](tensor_list)
# 输出:2, 2048, 24, 29,只返回layer4的结果
# print(xs)
out: List[NestedTensor] = []
pos = []
for name, x in xs.items():
# print(name)
# print(x.tensors.shape)
out.append(x)
# position encoding
# 运行位置编码层
pos.append(self[1](x).to(x.tensors.dtype))
# print(pos.shape)
return out, pos2.transformer部分
我们在backbone部分得到了特征图和位置编码,其中特征图的维度batch_size*2048*H*W,mask维度batch_szie*H*W,我们首先将特征图 通过1*1的卷积降维至batch_size*256*H*W大小,通时构建维度为256*100的query向量,输入transformer网络中
encoder部分
我们将position_embeding,特征图维度,mask分别变为HW*batch_size*256,HWxNx256,batch_size*HW,输入encoder中,对queries,和key加上位置编码,然后经过多头注意力机制,结构如下:
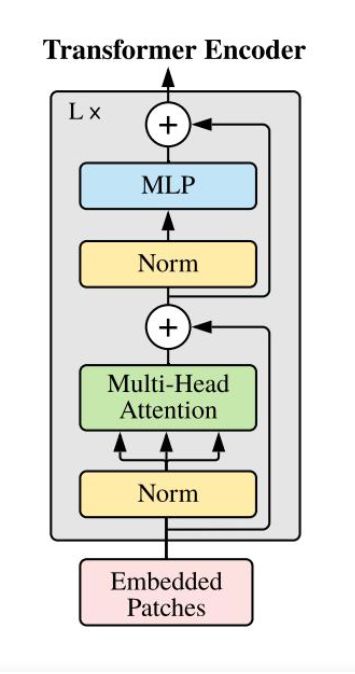
代码如下:
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False):
super().__init__()
# dmodel:256 nhead:8
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward_post(self,
src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
# shape:696, 2, 256
q = k = self.with_pos_embed(src, pos) #只有K和Q 加入了位置编码;并没有对V做
# print(q.shape)
# 两个返回值:自注意力层的输出,自注意力权重;只需要第一个
# shape:696, 2, 256
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
# print(src2.shape)
# 残差连接
src = src + self.dropout1(src2)
# 层归一化+全连接
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
# print(src2.shape)
# 残差连接
src = src + self.dropout2(src2)
# 层归一化
src = self.norm2(src)
# print(src.shape)
return src
def forward_pre(self, src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
src2 = self.norm1(src)
q = k = self.with_pos_embed(src2, pos)
src2 = self.self_attn(q, k, value=src2, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src2 = self.norm2(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src2))))
src = src + self.dropout2(src2)
return src
def forward(self, src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
if self.normalize_before:
return self.forward_pre(src, src_mask, src_key_padding_mask, pos)
return self.forward_post(src, src_mask, src_key_padding_mask, pos)decoder部分
解码器首先随机初始化object queries(0+位置编码),以自身为q,k,v,做自注意力机制运算,以计算结果作为下一次注意力机制的query(加上位置编码),同时,注意力机制以encoder的输出为keys和value,最终经过6次的decoder模块,将6次decoder的结果保存,shape改变为6*batch_size*100*256
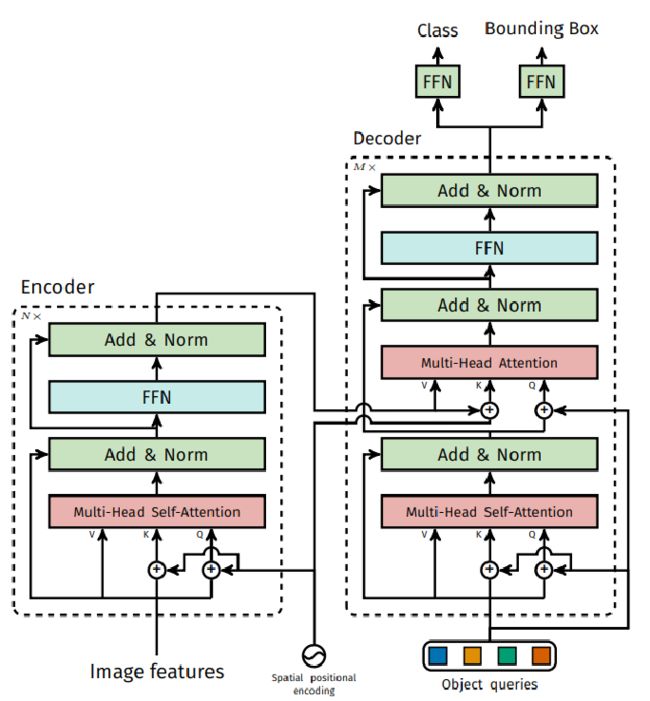
FFN层
对于分类,我们直接连接一层全连接进行预测,对于回归,我们使用3层全连接层,并在前两层使用relu激活函数,最后将结果使用sigmoid激活函数,保证值大于0,最后我们使用最后一层的结果作为输出。
ModuleList(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): Linear(in_features=256, out_features=256, bias=True)
(2): Linear(in_features=256, out_features=4, bias=True)
)整个detr部分代码:
class DETR(nn.Module):
""" This is the DETR module that performs object detection """
def __init__(self, backbone, transformer, num_classes, num_queries, aux_loss=False):
""" Initializes the model.
Parameters:
backbone: torch module of the backbone to be used. See backbone.py
transformer: torch module of the transformer architecture. See transformer.py
num_classes: number of object classes
num_queries: number of object queries, ie detection slot. This is the maximal number of objects
DETR can detect in a single image. For COCO, we recommend 100 queries.
aux_loss: True if auxiliary decoding losses (loss at each decoder layer) are to be used.
"""
super().__init__()
self.num_queries = num_queries
self.transformer = transformer
hidden_dim = transformer.d_model
self.class_embed = nn.Linear(hidden_dim, num_classes + 1)
self.bbox_embed = MLP(hidden_dim, hidden_dim, 4, 3)
self.query_embed = nn.Embedding(num_queries, hidden_dim)
self.input_proj = nn.Conv2d(backbone.num_channels, hidden_dim, kernel_size=1)
self.backbone = backbone
self.aux_loss = aux_loss
def forward(self, samples: NestedTensor):
""" The forward expects a NestedTensor, which consists of:
- samples.tensor: batched images, of shape [batch_size x 3 x H x W]
- samples.mask: a binary mask of shape [batch_size x H x W], containing 1 on padded pixels
It returns a dict with the following elements:
- "pred_logits": the classification logits (including no-object) for all queries.
Shape= [batch_size x num_queries x (num_classes + 1)]
- "pred_boxes": The normalized boxes coordinates for all queries, represented as
(center_x, center_y, height, width). These values are normalized in [0, 1],
relative to the size of each individual image (disregarding possible padding).
See PostProcess for information on how to retrieve the unnormalized bounding box.
- "aux_outputs": Optional, only returned when auxilary losses are activated. It is a list of
dictionnaries containing the two above keys for each decoder layer.
"""
if isinstance(samples, (list, torch.Tensor)):
samples = nested_tensor_from_tensor_list(samples)
features, pos = self.backbone(samples)
# print(pos[-1].shape)
# 可以设置返回resnet的多层结果,我们只取最后一层的结果,进行数据分解
# src:2, 2048, 24, 29
# mask:2, 24, 29
src, mask = features[-1].decompose()
# print(src.shape)
# print(mask.shape)
assert mask is not None
# self.input_proj(src):1*1卷积,特征图:2, 2048, 24, 29-->2, 256, 24, 29
# hs.shape:6, 2, 100, 256
hs = self.transformer(self.input_proj(src), mask, self.query_embed.weight, pos[-1])[0]
# print(hs.shape)
outputs_class = self.class_embed(hs)
outputs_coord = self.bbox_embed(hs).sigmoid()
out = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]}
if self.aux_loss:
out['aux_outputs'] = self._set_aux_loss(outputs_class, outputs_coord)
return out损失函数
损失函数包含两部分,分类损失和回归损失,分类损失使用交叉熵损失,回归损失包含两部分,边界框损失使用L1损失,再加上GIOU损失