DETR 论文精读,并解析模型结构
上一篇文章介绍了ViT,即Version Transformer,用于图像分类,今天这篇名为DETR的模型结构诞生于2020年,一经发布便有很多的追随者对其进行改进,使得目标检测前景更加广阔。
目录
一、摘要
二、结论
三、DETR模型结构
(1)简略的DETR模型
(2)精简的DETR模型
四、极其简易的DETR架构
(1)Backbone
(2)Transformer encoder
(3)Transformer decoder
(4)Prediction feed-forward networks (FFNs)
(5)Auxiliary (辅助) decoding losses
(5)预测损失(匈牙利算法)
五、实验细节和训练技巧(干货满满)
六、注意力权重可视化
附录:(Pytorch框架中的超简单的DETR网络架构代码)
一、摘要
我们提出了一种新的方法,将目标检测视为一个直接的集合预测问题。我们的方法精简了检测管道,有效地消除了许多手工设计的组件,如非极大值抑制过程或锚生成,这些组件显式地编码了我们关于任务的先验知识。新框架的主要组成部分,称为 DEtect TRansforme r或 DETR,是一个基于集合的全局损耗,通过二分匹配和一个转换器编码器-解码器架构强制进行唯一的预测。给定一个固定的小规模学习对象查询集,DETR根据对象和全局图像上下文的关系,并行地直接输出最终的预测集。新模型在概念上很简单,不需要专门的库,不像其他许多现代探测器。DETR在具有挑战性的COCO目标检测数据集上展示了与公认的、高度优化的Faster R-CNN基线相当的准确性和运行时性能。此外,DETR可以很容易地推广到以统一的方式产生全景分割。我们表明它明显优于竞争性基线。
训练代码和预训练模型:https://github.com/facebookresearch/detr.
二、结论
我们提出了DETR,一种新的基于 Transformer 和二分匹配损失的直接集预测目标检测系统设计。该方法在具有挑战性的COCO数据集上取得了与优化的Faster R-CNN基线相当的结果。DETR易于实现,并且具有灵活的体系结构,易于扩展到全景分割,具有竞争性的结果。此外,它在大型对象上的性能显著优于Faster R-CNN,这可能归功于自注意力对全局信息的处理。
局限性:这种新的探测器设计也带来了新的挑战,特别是在小物体上的训练、优化和性能。目前的检测器需要几年的改进才能应对类似的问题,我们期待未来的工作能够成功地解决这些问题。
三、DETR模型结构
(1)简略的DETR模型

图1 DETR通过将普通 CNN 与 Transformer 架构相结合,直接(并行)预测最终的检测集。
如简略的DERT框架图1 所示,在训练过程中:
- 二分匹配唯一地将预测分配给 ground truth boxes 。
- 没有匹配的预测应该产生一个"no object" (
 )类预测。
)类预测。
我们将目标检测看作直接的集合预测问题,从而精简训练管道。我们采用了基于转换器的编码器-解码器架构《Attention is all you need》,这是一种流行的序列预测架构,即大名鼎鼎的 Transformer。Transformer的自注意力机制显式地建模了序列中元素之间的所有成对交互,使得这些架构特别适用于集合预测的特定约束,如去除重复预测。
我们的 DEtect TRansformer ( DETR, 见图1)能够自动预测所有对象,并使用集合损失函数进行端到端训练,该损失函数在预测对象和真实对象之间执行二分匹配。DETR通过删除多个手工设计的编码先验知识的组件来简化检测管道,如空间锚框或非最大抑制。与大多数现有的检测方法不同,DETR不需要任何自定义层,因此可以在包含标准 CNN 和 Transformer 类的任何框架中轻松复制。
缺点之一:DETR的训练设置在多个方面与标准对象检测器不同。新模型需要超长的训练时间表,并受益于变压器中的辅助解码损耗。我们深入探索了哪些成分对所展示的性能至关重要。
DETR的设计理念很容易扩展到更复杂的任务。在我们的实验中,我们展示了在预训练的DETR上训练的一个简单的分割头在全景分割上的竞争性基线,这是一个具有挑战性的像素级识别任务,最近得到了普及。
(2)精简的DETR模型
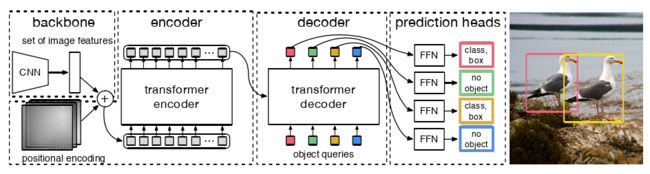
图2 DETR使用传统的CNN主干来学习输入图像的2D表示。该模型将其扁平化,并在将其传入Transformer 编码器之前用位置编码进行补充。然后,Transformer 解码器将少量固定数量的学习位置嵌入作为输入,我们称之为对象查询(object queries),并附加到编码器输出。我们将解码器的每个输出嵌入传递给一个共享前馈网络( FFN ),该网络预测一个检测( 类和 bround box )或一个 "无对象" 类。
End-to-End Object Detection with Transformers 一次前向传播的过程:
- 输入图像,经过标准 CNN 后,得到图像的特征矩阵。
- 把图像特征拉直,并进行位置编码补充。
- 在 Transformer Encoder 中学习图像的全局信息。
- 位置嵌入和 Encoder 的输出作为 Decoder 的输入,经过解码后传递给 FFN。
- 判断 FFN 预测图像中是否包含目标对象。
- 如果有,则输出预测框和类别;否则输出一个 “no object” 类。
四、极其简易的DETR架构
DETR的整体架构令人惊讶地简单,如图2所示。它包含三个主要组成部分,我们将在下面描述:一个CNN主干来提取紧凑的特征表示,一个编码器-解码器转换器,以及一个简单的前馈网络( feed forward network,FFN )来进行最终的检测预测。
与许多现代检测器不同,DETR可以在任何深度学习框架中实现,该框架提供了一个通用的CNN骨干和一个变压器架构实现,只有几百行代码。在PyTorch《Pytorch: An imperative style, high-performance deep learning library.》中,DETR 的推理代码可以在少于 50 行中实现。我们希望我们的方法的简洁性将吸引新的研究人员加入检测界。
(1)Backbone
从初始图像 ![]() (with 3 color channels) 开始,传统的 CNN 主干生成一个低分辨率的激活图
(with 3 color channels) 开始,传统的 CNN 主干生成一个低分辨率的激活图 ![]() 。我们使用的典型值为
。我们使用的典型值为 ![]() 和
和 ![]() 。
。
(2)Transformer encoder
首先,一个1x1卷积将高层激活图  的通道维度从 C 降低到更小的维度 d,从而创建新的特征映射
的通道维度从 C 降低到更小的维度 d,从而创建新的特征映射 ![]() 。编码器期望一个序列作为输入,因此将
。编码器期望一个序列作为输入,因此将 ![]() 的空间维度压缩为一维,得到
的空间维度压缩为一维,得到 ![]() 特征图。
特征图。
每个编码器层都有一个标准的体系结构,由一个多头自注意力模块和一个前馈网络( FFN )组成。由于 Transformer 结构是置换不变的,我们用固定位置的编码来补充它,这些编码被添加到每个注意力层的输入中。
在补充材料中,我们引用了体系结构的详细定义,该定义遵循《Attention is all you need》中描述的定义。
(3)Transformer decoder
解码器遵循转换器的标准架构,使用多头自注意力机制和编码器-解码器注意力机制转换 N 个大小为 d 的嵌入。与原始转换器不同的是,我们的模型在每个解码器层并行解码N个对象,而 Transformer 使用一个自回归模型,一次预测输出序列一个元素。由于解码器也是置换不变的,所以 N 个输入嵌入必须不同才能产生不同的结果。这些输入嵌入是我们称为对象查询的学习位置编码,类似于编码器,我们将它们添加到每个注意力层的输入中。N个对象查询被解码器转换为一个输出嵌入。然后通过前馈网络(在下一小节中描述)将它们独立解码为框坐标和类标签,从而得到N个最终预测。利用对这些嵌入的自注意力和编码器-解码器注意力,模型利用它们之间的成对关系对所有对象进行全局推理,同时能够使用整个图像作为上下文。
(4)Prediction feed-forward networks (FFNs)
最终的预测由一个具有 ReLU 激活函数和隐藏维数 d 的 3 层感知器和一个线性投影层计算。FFN 预测输入图像的归一化中心坐标、BOX高度和宽度,线性层使用 softmax 函数预测类标签。由于我们预测了一个固定大小的 N 个边界框集合,其中 N 通常比图像中感兴趣的对象的实际数目大得多,因此使用了一个额外的特殊类标签( Special class label )来表示在槽中没有检测到对象。这个类在标准物体检测方法中扮演与 "背景" 类相似的角色。
(5)Auxiliary (辅助) decoding losses
我们发现在训练过程中使用辅助损失[1]有助于解码器,特别是帮助模型输出正确的每类对象个数。我们在每个解码器层之后添加预测 FFN 和匈牙利损失(Hungarian loss)。所有预测 FFN 共享其参数。我们使用一个额外的共享层规范来规范化来自不同解码器层的预测 FFN 的输入。
补充:匈牙利算法(Hungarian Algorithm)是一种组合优化算法,用于求解指派问题(assignment problem),算法时间复杂度为O( )。Harold Kuhn发表于1955年,由于该算法基于两位匈牙利数学家的早期研究成果,所以被称作“匈牙利算法”。
)。Harold Kuhn发表于1955年,由于该算法基于两位匈牙利数学家的早期研究成果,所以被称作“匈牙利算法”。
[1]. Al-Rfou, R., Choe, D., Constant, N., Guo, M., Jones, L.: Character-level languagemodeling with deeper self-attention. In: AAAI Conference on Artificial Intelligence(2019)
(5)预测损失(匈牙利算法)
损失函数的具体分析和实现,见另一篇文章: 通过公式和源码解析 DETR 中的损失函数 & 匈牙利算法(二分图匹配)_Flying Bulldog的博客-CSDN博客 https://blog.csdn.net/qq_54185421/article/details/125992305?spm=1001.2014.3001.5501
https://blog.csdn.net/qq_54185421/article/details/125992305?spm=1001.2014.3001.5501
DETR在单次通过解码器时推断一个固定大小的N个预测集合,其中N被设置为显著大于图像中典型的物体数量。训练的主要困难之一是在 ground truth 方面得分预测对象( 类别、位置、大小 )。我们的损失在预测对象和真实对象之间产生一个最佳的二分匹配,然后优化特定于对象( 边界框 )的损失。
DERT根据先前的工作《End-to-end people detection in crowdedscenes》,利用改进的匈牙利算法计算二分匹配损失和BOX的损失。
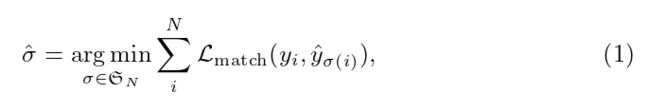
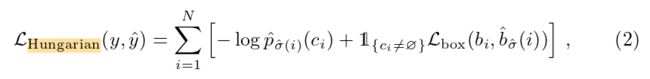
(6)DETR Transformer 结构图
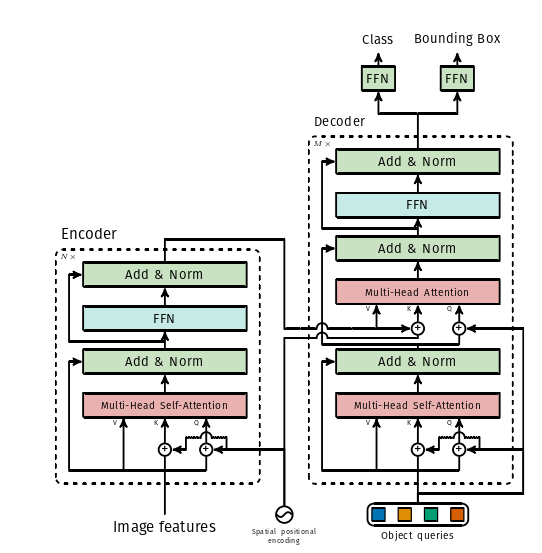
DETR中使用的变压器的详细描述,以及在每个注意层传递的位置编码,如上图所示。来自CNN主干的图像特征通过Transformer编码器传递,以及在每个多头自注意力层添加到查询和键的空间位置编码。然后,解码器接收查询(初始设置为零),输出位置编码(对象查询)和编码器内存,并通过多个多头自注意力和解码器-编码器注意力产生最终的预测类标签和边界框集合。可以跳过第一个解码器层中的第一个自注意力层。
五、实验细节和训练技巧(干货满满)
我们使用AdamW [ 26 ] 训练DETR,将初始Transformer的学习率设置为 ,主干的学习率设置为
,主干的学习率设置为 ,权重衰减设置为。所有的Transformer权重都是用Xavier init [ 11 ]初始化的,而主干网是用ImageNet预训练的ResNet模型[ 15 ],它来自于具有冻结BN层的 torchvision 库。
,权重衰减设置为。所有的Transformer权重都是用Xavier init [ 11 ]初始化的,而主干网是用ImageNet预训练的ResNet模型[ 15 ],它来自于具有冻结BN层的 torchvision 库。
- 我们用两个不同的主干报告结果:一个ResNet-50和一个ResNet-101。相应的模型分别称为DETR和DETR-R101。
- 在[ 21 ]之后,我们还通过向主干的最后一个阶段添加一个展开,并从这个阶段的第一个卷积中移除一个跨步来提高特征分辨率。相应的模型分别称为 DETR-DC5 和 DETR-DC5-R101 (扩张的C5级)。
优缺点:这种修改将分辨率提高了两倍,从而提高了对小目标的性能,代价是编码器的自注意力增加了16倍,导致整体计算成本增加了 2 倍。表1 给出了这些模型与Faster R-CNN的FLOPs的全面比较。
表1 在COCO验证集上与以ResNet-50和ResNet-101为骨架的Faster R-CNN进行对比。
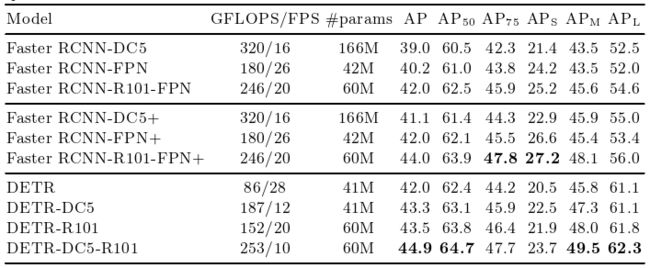
我们使用缩放,调整输入图像的大小,使得最短的一面是至少480和最多800像素,最长的一面是最多1333像素[ 50 ]。为了通过编码器的自注意力来帮助学习全局关系,我们还在训练过程中应用了随机的crop增强,提高了大约1 AP的性能。具体来说,将一列火车图像以0.5的概率裁剪为一个随机的矩形块,然后重新调整大小为800 ~ 1333。
Transformer以默认dropout为0.1进行训练。在推理时,一些槽预测空类。为了优化AP,我们使用相应的置信度,将这些槽的预测与第二高得分类覆盖。这比过滤掉空槽提高了2个点的AP。对于我们的消融实验,我们使用300个epochs的训练计划,在200个epochs之后,学习率下降了10倍,其中一个epoch是所有训练图像的一次。在16个 V100 GPUs 上训练300个epochs的基线模型(baseline model)需要3天时间,每个GPU( 因此总的批量大小为64 )有4幅图像。对于用于与Faster R-CNN进行比较的更长的计划,我们在400个epochs后训练500个epochs,学习率下降。与较短的计划相比,这个计划增加了1.5个AP。
- [26]. Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: ICLR (2017)
- [11]. Glorot, X., Bengio, Y.: Understanding the difficulty of training deep feedforwardneural networks. In: AISTATS (2010)
- [15]. He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR (2016)
- [21]. Li, Y., Qi, H., Dai, J., Ji, X., Wei, Y.: Fully convolutional instance-aware semantic segmentation. In: CVPR (2017)
- [50]. Wu, Y., Kirillov, A., Massa, F., Lo, W.Y., Girshick, R.:Detectron2. https://github.com/facebookresearch/detectron2 (2019)
六、注意力权重可视化

图3 针对一组参考点的编码器自注意力
如上图所示,编码器能够分离出单独的实例。在验证集图像上使用基线DETR模型进行预测。
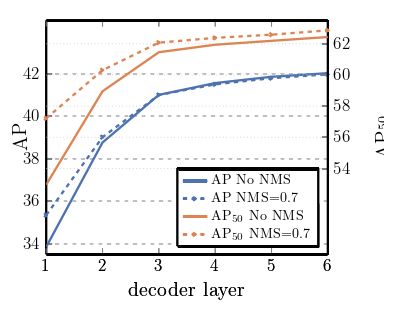
图4 每个解码器层后的AP和AP50性能
对单个长调度基线模型进行评估。通过设计,DETR不需要NMS,该图验证了这一点。NMS在最终层中降低了AP,消除了TP预测,但在第一个解码器层中提高了AP,消除了双重预测,因为在第一层中没有通信,略微改进了AP50。
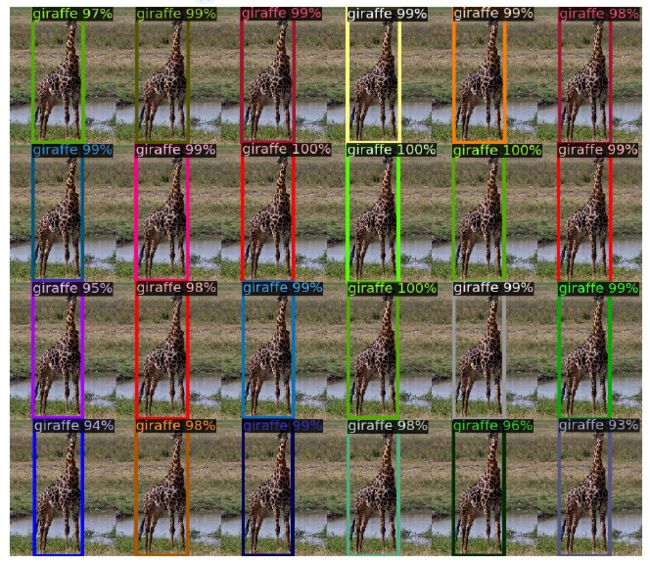
图5 稀有类的非分布泛化
尽管在训练集中没有图像有超过13个长颈鹿,但是DETR很容易的推广到同一类的24个及更多实例。

图6 可视化每个预测对象(图像来自COCOval集)的解码器注意力
采用DETR - DC5模型进行预测。对于不同的对象,采用不同的颜色对注意力分数进行编码。解码器通常关注对象的四肢,如腿部和头部。通过颜色可以观察到,不同物体之间的边缘划分的很是明显,虽然大象的四肢和皮肤很相似,但是也难逃DETR的法眼,还有斑马的条纹很复杂,但是也没有对DETR造成困难。
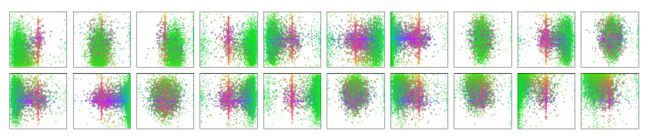
图7 DETR解码器中N = 100个预测槽中的20个图像上的所有框预测的可视化。
每个盒子预测被表示为一个点,其中心的坐标在每个图像大小归一化的1-by-1平方中。这些点是彩色编码的,所以绿色对应于small boxes,红色对应于large horizontal boxes,蓝色对应于large vertical boxes。我们观察到,每个槽都通过几种操作模式学习专注于某些区域和boxes大小。我们注意到,几乎所有的槽都有一种模式来预测COCO数据集中常见的 large image-wide boxes。
附录:(Pytorch框架中的超简单的DETR网络架构代码)
import torch2
from torch import nn3
from torchvision.models import resnet5045
class DETR(nn.Module):
def __init__(self, num_classes, hidden_dim, nheads,
num_encoder_layers, num_decoder_layers):
super().__init__()
# We take only convolutional layers from ResNet-50 model
self.backbone = nn.Sequential(*list(resnet50(pretrained=True).children())[:-2])
self.conv = nn.Conv2d(2048, hidden_dim, 1)
self.transformer = nn.Transformer(hidden_dim, nheads,
num_encoder_layers, num_decoder_layers)
self.linear_class = nn.Linear(hidden_dim, num_classes + 1)
self.linear_bbox = nn.Linear(hidden_dim, 4)
self.query_pos = nn.Parameter(torch.rand(100, hidden_dim))
self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
def forward(self, inputs):
x = self.backbone(inputs)
h = self.conv(x)
H, W = h.shape[-2:]
pos = torch.cat([
self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),
self.row_embed[:H].unsqueeze(1).repeat(1, W, 1),
], dim=-1).flatten(0, 1).unsqueeze(1)
h = self.transformer(pos + h.flatten(2).permute(2, 0, 1),
self.query_pos.unsqueeze(1))
return self.linear_class(h), self.linear_bbox(h).sigmoid()
detr = DETR(num_classes=91, hidden_dim=256, nheads=8, num_encoder_layers=6, num_decoder_layers=6)
detr.eval()
inputs = torch.randn(1, 3, 800, 1200)
logits, bboxes = detr(inputs)>>> 如有疑问,欢迎评论区一起探讨。
>>> 关于更多Transformer的文章,可以访问本文的专栏:
变形金刚 Transformer_Flying Bulldog的博客-CSDN博客https://blog.csdn.net/qq_54185421/category_11847619.html?spm=1001.2014.3001.5482