Flink1.16 发布新特性
文章目录
- 引用
- 前线速看
- 更快更稳更易用:Flink自适应批处理能力演进
-
- 01 Adaptive Batch Scheduler自动设置作业并行度
- 02 Speculative Execution 发现和缓解热点机器对作业的影响
- 03 Hybrid Shuffle 提供资源利用率和数据传输率
- 04 Dynamic Partition Pruning 过滤无用数据,提高处理效率
- Flink 1.16 Preview: Hive SQL如何平迁到Flink SQL
-
- 01 迁移的动机
- 02 迁移的挑战
- 03 如何迁移
- 04 demo
- 基于log的通用增量 Checkpoint
-
- 01 checkpoint 性能优化之路
- 02 解析changelog
- 03 一览State/Checkpoint优化
- 04 总结
- Flink CDC + Kafka加速业务实时化
-
- 01 Flink CDC技术
- 02 Flink+Kafka实时数据集成方案
- 03 Demo:Flink+Kafka实现CDC数据的实时集成和实时分析
- Flink Table Store典型应用场景
-
- 01 介绍Flink Table Store
- 02 应用场景
- 03 Demo
- 04 后续挑战
- 结语
引用
虽然flink1.16已经发布,但是小编在文章发布日查看了下官网,目前最新稳定版依然是flink1.15.2,生产要用最新版flink1.16的小伙伴,请慎重使用。
flink下载页
flink主页
Flink学习网
下面内容来源于Apache Flink Meetup 北京站,小编只是加以整理。
前线速看
- 统一API: 对比spark程序开发,flink一套应用开发即可重用在流批环境
- 统一计算:适配多种数据源,可以在streaming warehouse整体概念下计算,一套计算引擎解决多种场景计算
- 统一存储:table store不仅对flink提供存储能力,对spark外部计算引擎同样可以;同时flink也适配了各式的存储中间件
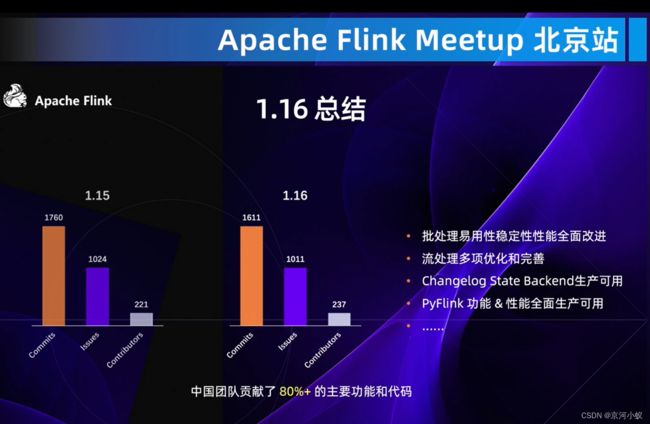
上图着重强调了中国团队对flink1.16的贡献。
sql gateway这个功能超级强大,支持多租户,协议插件化,兼容hive生态,以后flink流批作业都可以通过sql gateway提交到集群了。
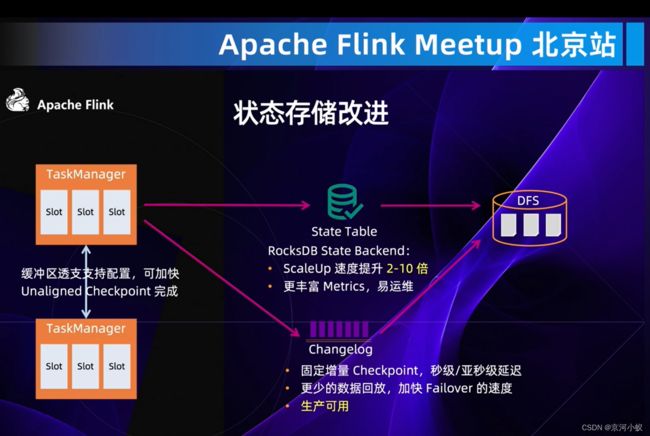
上图是状态存储改进。
更快更稳更易用:Flink自适应批处理能力演进

那么具体有哪些优化呢?
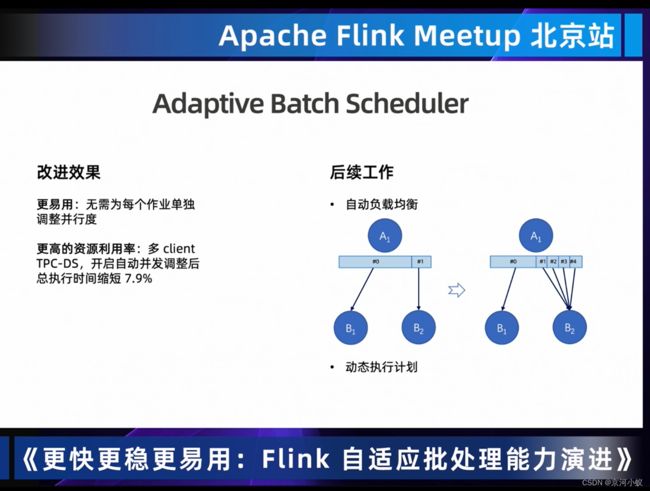
01 Adaptive Batch Scheduler自动设置作业并行度

综上,上面的问题,我们都思考下,怎么解决?
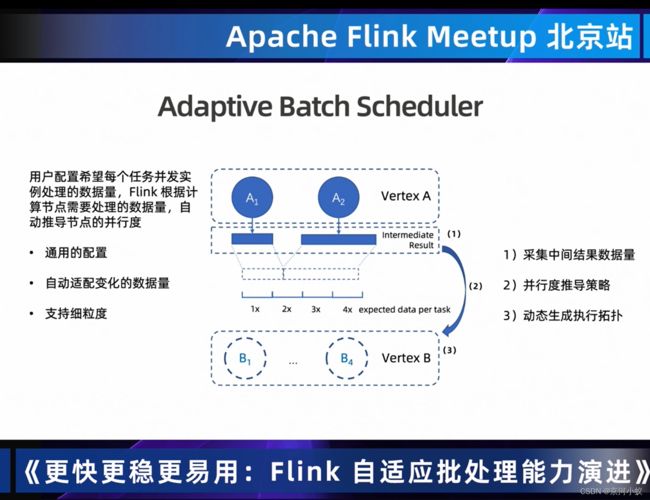
那么自适应批量调度
02 Speculative Execution 发现和缓解热点机器对作业的影响

从上面 现状和问题,可以看到下面的图片flink批处理推出了推测执行,这也是flink1.16新推出的机制。
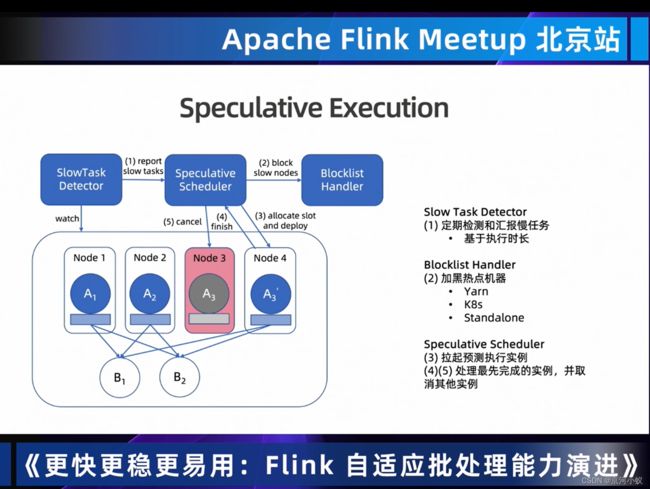
下面的推测执行在flink框架层面的执行范围,目前知道的是sink层面是不支持推测机制;如果自定义source事件,SplitEnumerator需要实现SupportsHandleExecutionAttemptSourceEvent接口
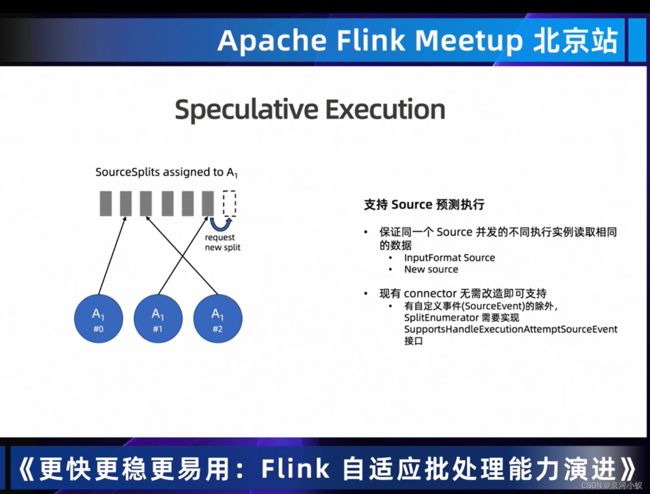
下图中是推测执行的web ui,后续会支持sink推测执行。

03 Hybrid Shuffle 提供资源利用率和数据传输率

那么怎么集合流和批两种的优势呢,其实就是怎样结合流的快和批的稳定,Hybrid Shufle应运而生
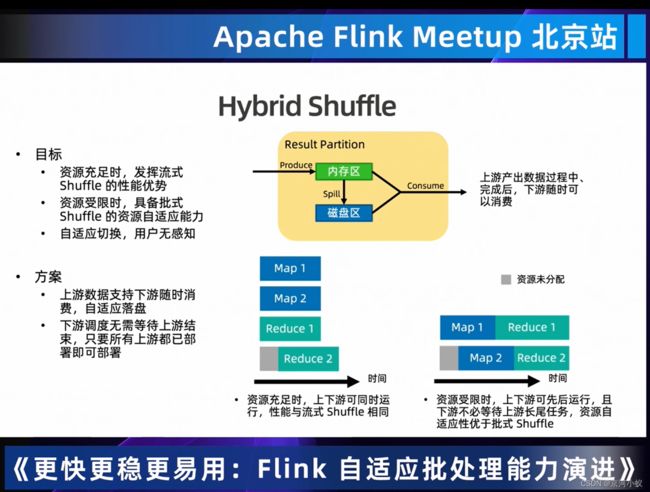
Hybrid Shuffle的目标时 具备资源自适应的能力,资源充足时,直接流式shuffle,资源不足时,又具备批量shuffle的稳定性,用户完全无感(我这里抱由怀疑态度)。
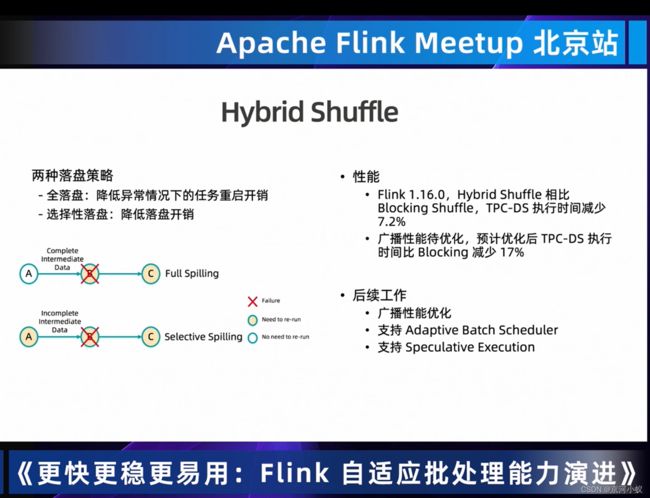
Hybrid Shuffle提供了两种落盘策略,从上图中可以看出,性能是有提升,但是提升有限,期待后面有质的飞跃。
04 Dynamic Partition Pruning 过滤无用数据,提高处理效率
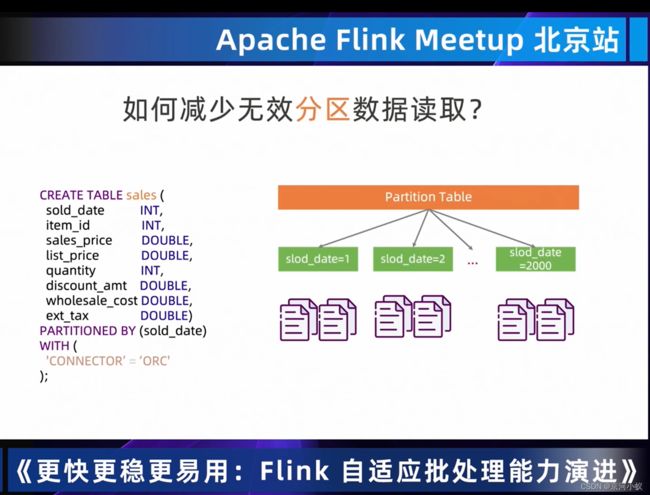
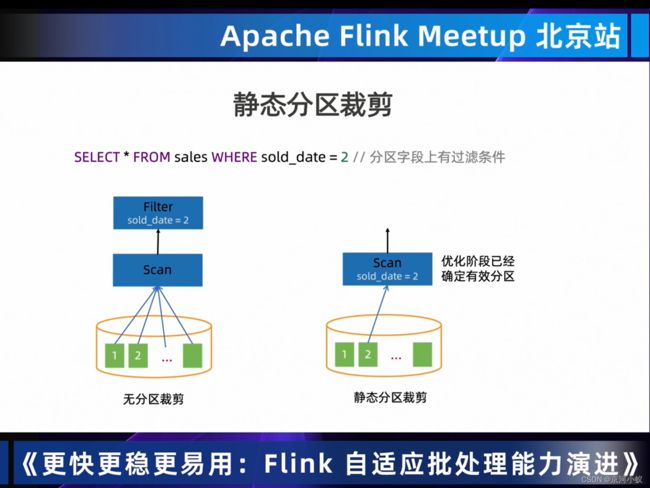
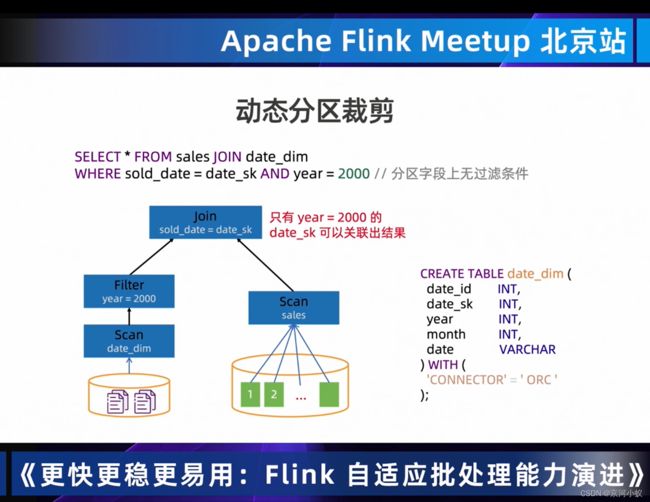
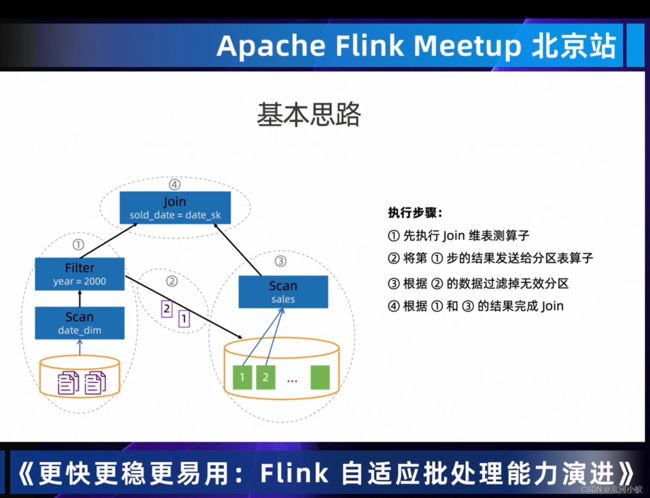
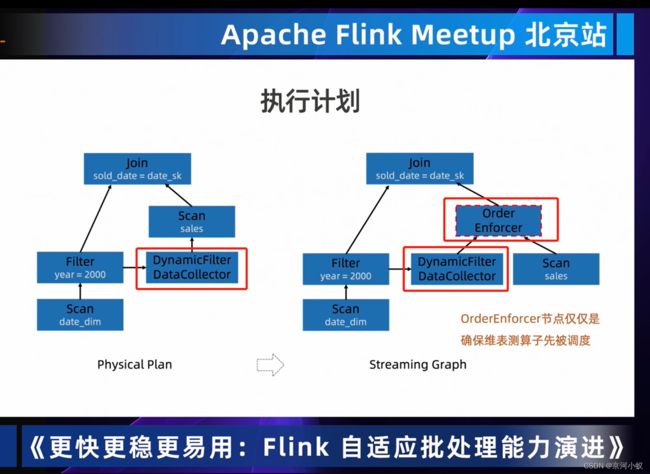
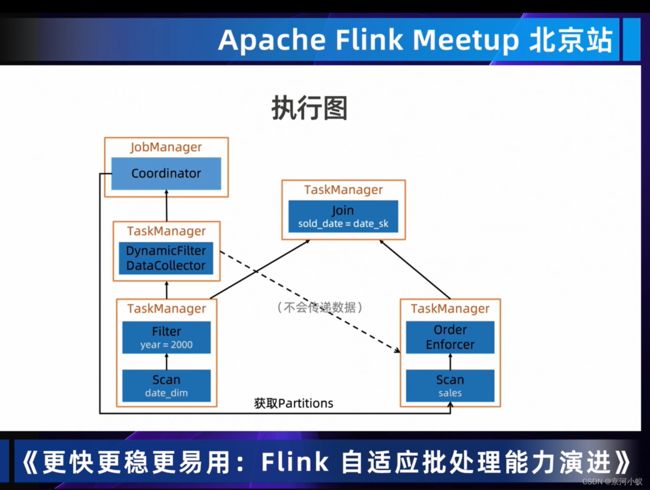
从上图中可以看出DynmaicFilter DataCollector左边和右边的scan是没有依赖关系的,OrderEnforcer就是建立两者之间的依赖关系,仅是为了runtime调度器他们之前是有数据依赖的,从而确保调度先后顺序是没毛病的。


Flink 1.16 Preview: Hive SQL如何平迁到Flink SQL
01 迁移的动机
为什么Flink要做hive sql迁移?
离线用户吸引离线数仓用户,打磨批引擎,螺旋迭代;离线业务开发门槛降低用户flink开发离线业务的门槛;hive生态工具生态是最高的壁垒,融入离线生态;流批一体 推动业界,先统一殷勤,后统一API。

02 迁移的挑战

03 如何迁移
复用hive语法
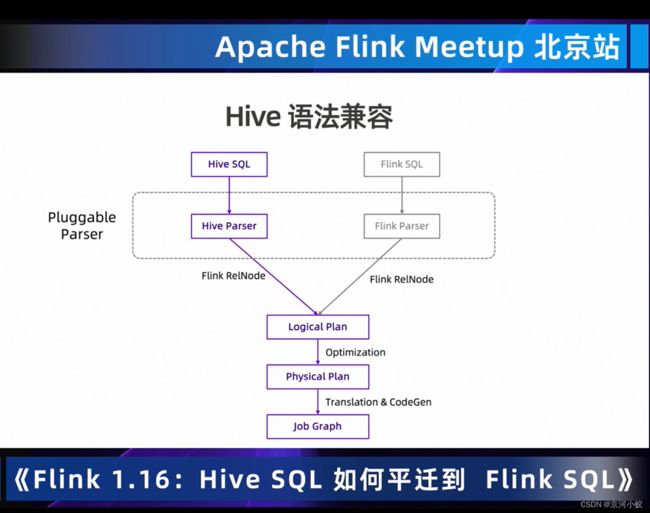
hivesql到hive parser 再到flink relnode做了大量的工作,目的为了更好的与flinksql引擎的兼容。
hive语法兼容:Flink1.16 hive语法兼容度从85%提升至94.1%(Hive qtest 12k测试集)。
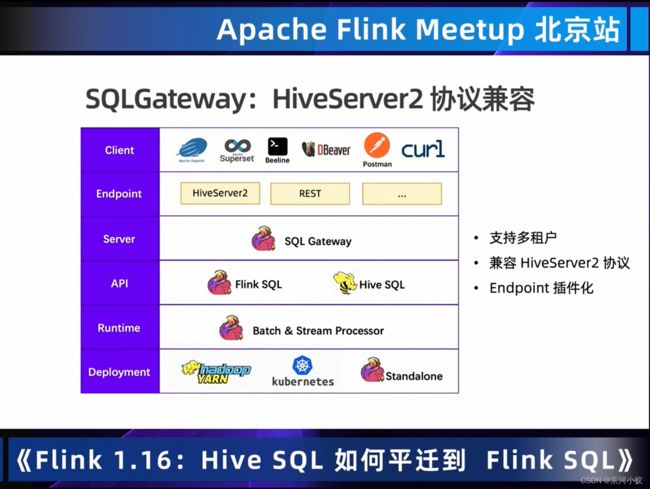
hivesql 迁移在快手的实践

04 demo
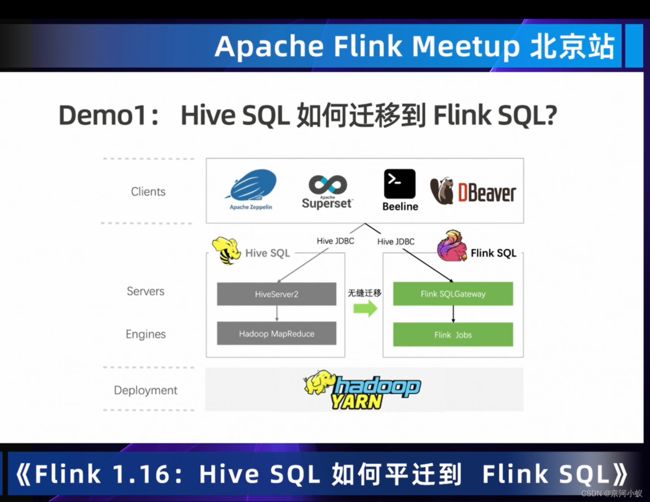
看了大佬讲了这个功能,感觉简单的端到端的流批操作都很简单,但是大数据量下会不会出现什么问题,有待本人验证。
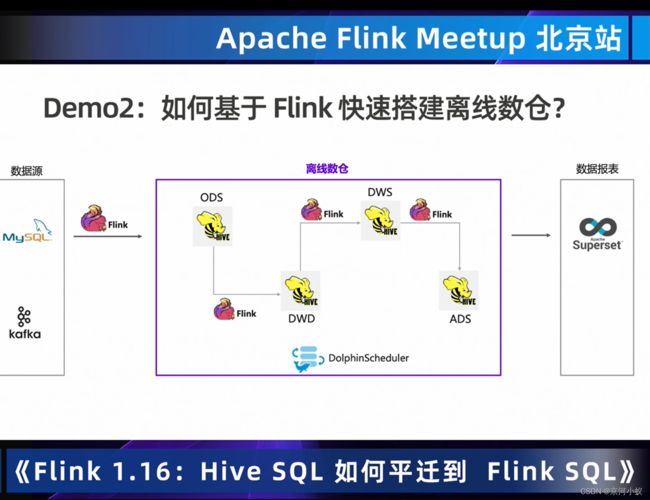

基于log的通用增量 Checkpoint
什么是checkpoint ,通常会想到状态持久化,flink独有的特性,轻量且快,容错,本地格式化,快速恢复。
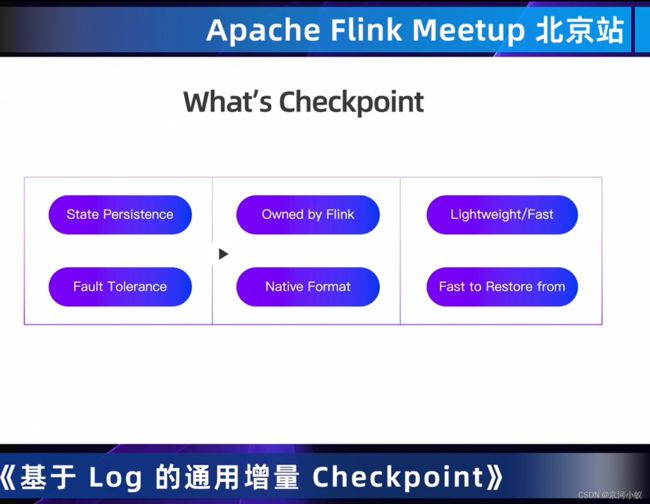
01 checkpoint 性能优化之路

checkpoint不同版本之间的优化
- 0.9 轻量级异步的snapshot算法,把barrier作为一个特殊的record在graph中流动,同时将耗时较大的文件上传等工作放到异步的过程当中进行,这样的话对主流程的影响是变的非常小的。
- 1.0 当中支持了RocksDB StateBackend,对于大状态下的存储提供了很好的支持。
- 1.3 当中实现了基于RocksDB incremental checkpoint,这个机制是进一步提升了在异步阶段的checkpoint的性能。
- 1.11 当中引入了Unaligned Checkpoint
- 1.13 当中又引入了Unaligned Checkpoint (Production-ready),在一些场景下对于barrier对齐会有瓶颈的作业的话,基于Unaligned Checkpoint 以及 buffer debloating我们可以甚至让一些作业在反压比较严重的情况下依然可以做出Checkpoint
- 1.14 当中又加入了buffer debloating的概念,上面1.13中介绍的buffer debloating就是此概念,通过调整buffer debloating的大小来加速barrier的流动,进一步加速checkpoint的完成,而对 unaligned checkpoint去进一步减少 unaligned checkpoint过程中存储的数据量
- 1.15 1.16 当中引入了changelog backend,这个功能就是我们本次学习的重点,它的机制就是进一步的通过一个更通用的increment的checkpoint机制更进一步异步的减少开销,提升checkpoint的异步部分的性能
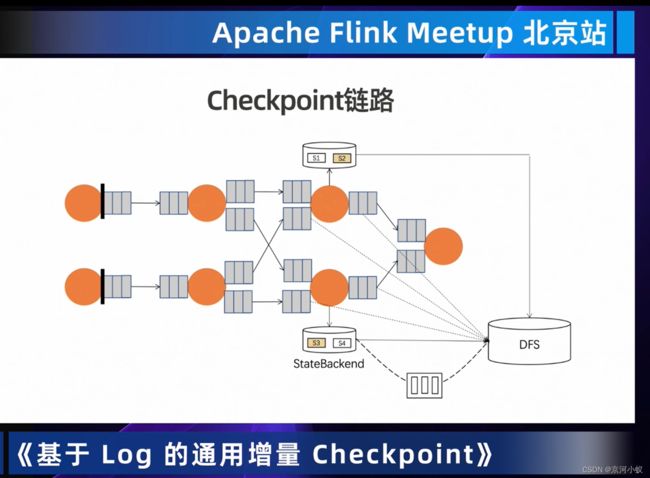
我们可以通过checkpoint链路上看这些优化技术在graph中的体现,在触发checkpoint的时候,我们知道source阶段barrier随着graph进行流动,然后在刚打开了buffer debloating的时候flink会通过计算数据吞吐等方式来动态调整network buffer的大小来加速barrier的传递,而当barrier到达state节点的时候,如果是aligned checkpoint那么就会等待barrier的对齐,如果是unaligned checkpoint的话会直接将buffer当中的内容存储到hdfs当中不会阻塞,然后同时触发statebackend上的checkpoint的过程 ,buffer的传输的话就像上图中虚线所示,然后在statebackend内部再触发checkpoint的时候基于异步的checkpoint算法,在异步部分会进行一个文件的上传,如上图实现所示,开启了rocksdb increment的时候,会做些增量文件的上传,在这次介绍changelog statebackend的部分的话,我们可以看到最下面的虚线 我们会把原来的statebackend的异步上传部分和changelog进行解耦,然后会有一个独立的上传hdfs的过程,这个过程会在后面进行详细介绍。
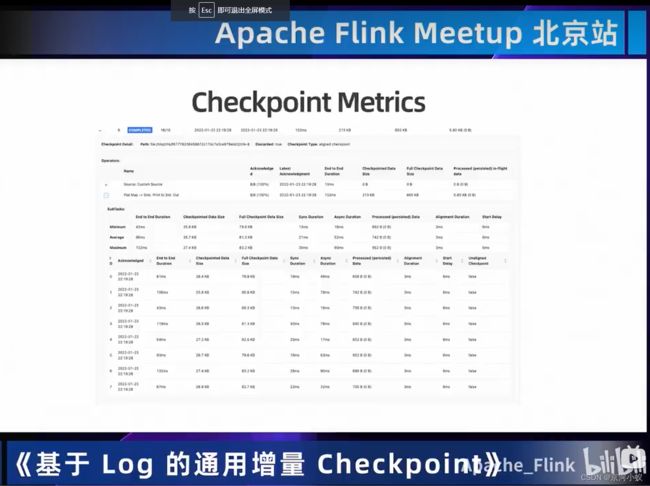
上图中的指标会让你对checkpoint有一些直观的感受,包括像端到端延迟,这个是对checkppoint最直观的性能的一个感受。
02 解析changelog




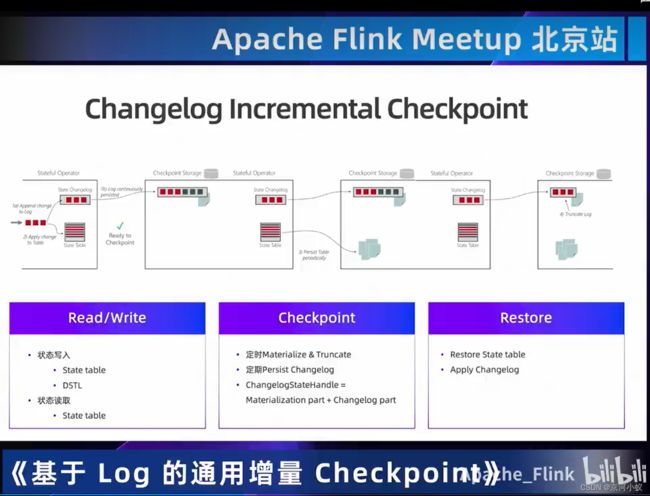


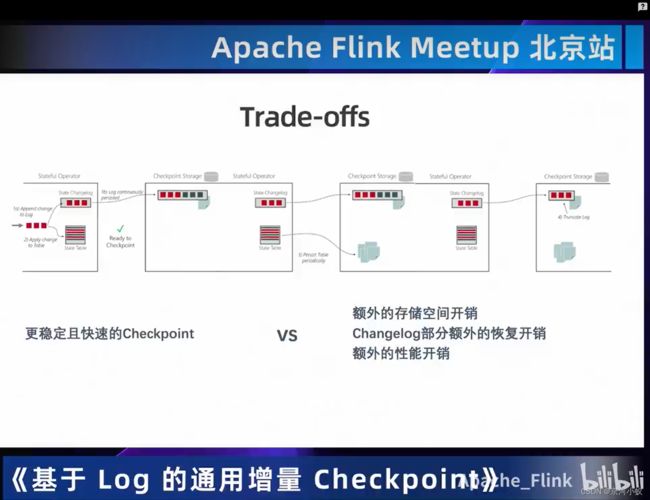
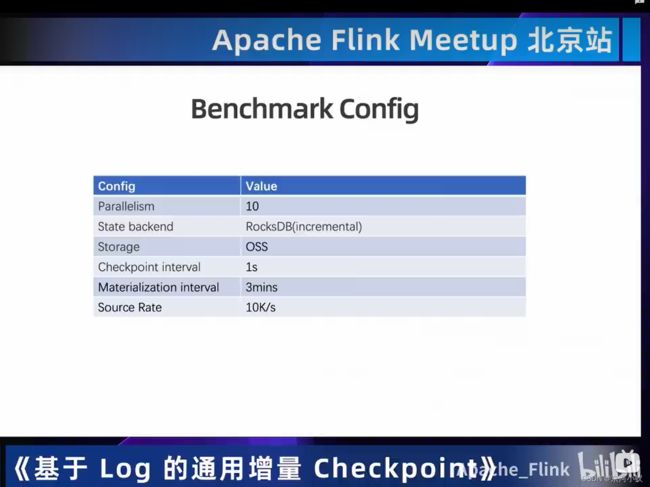
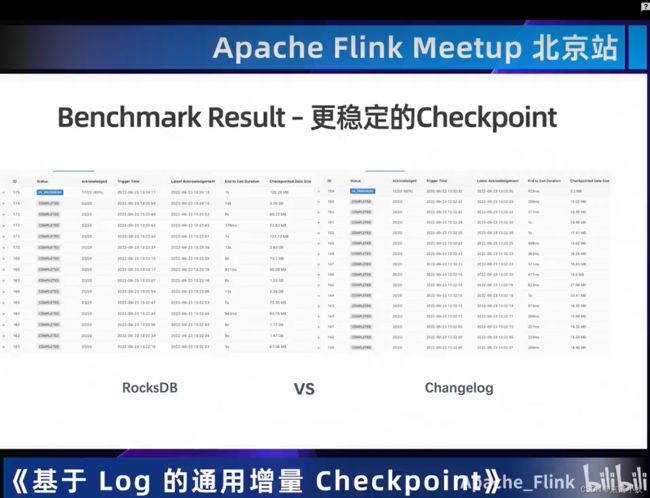
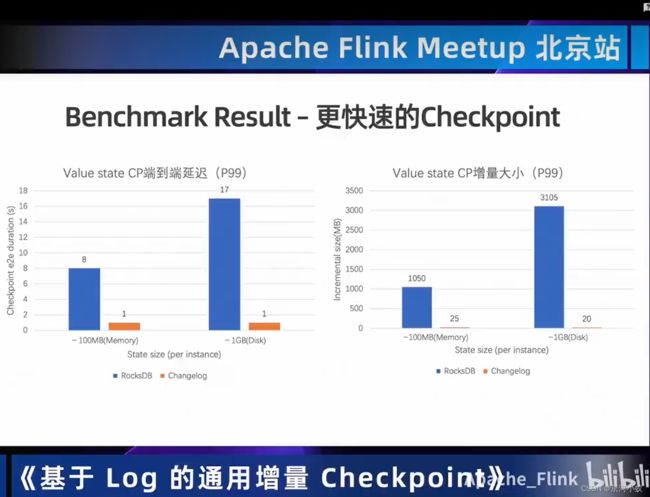
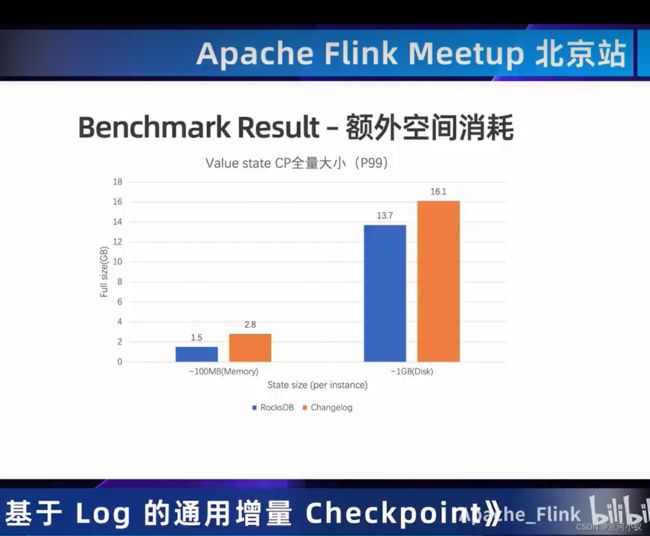
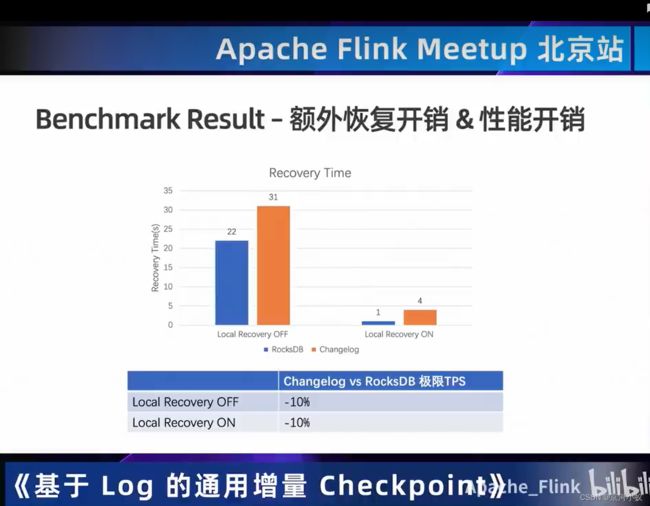
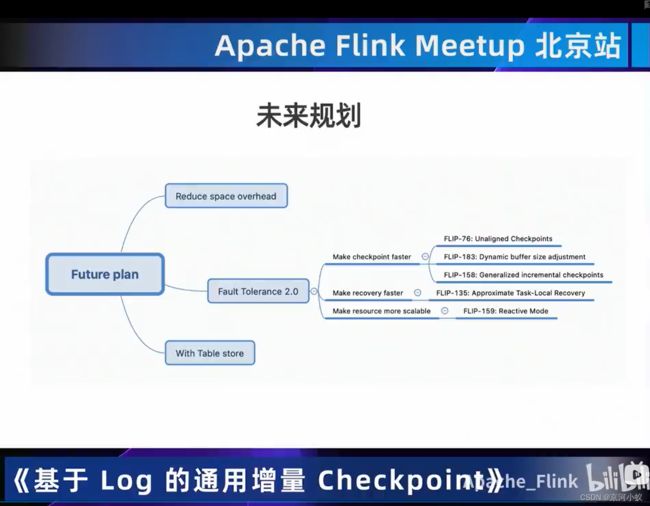
03 一览State/Checkpoint优化

04 总结

Flink CDC + Kafka加速业务实时化
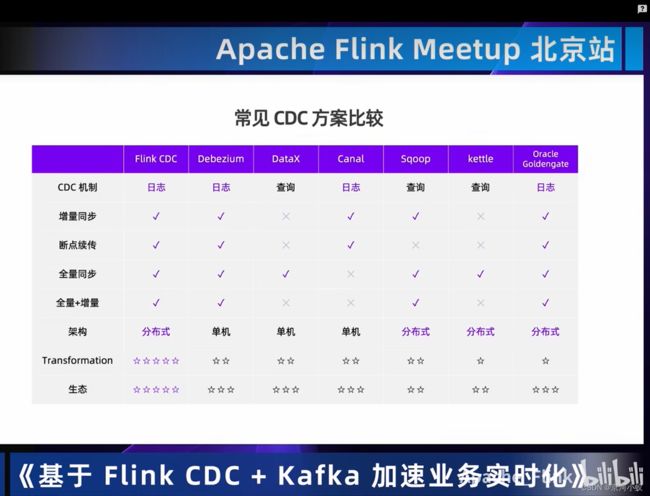
广义的概念上,能够捕获数据变更的技术,我们都可以称为CDC (Change Data Capture)。通常我们说的CDC技术主要面向数据库的变更,是一种用于捕获数据库中数据变更的技术。
01 Flink CDC技术
主要用到的场景有以下这些:


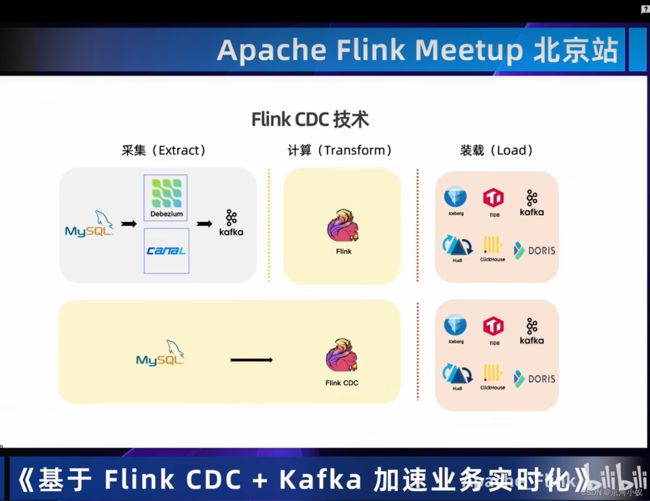
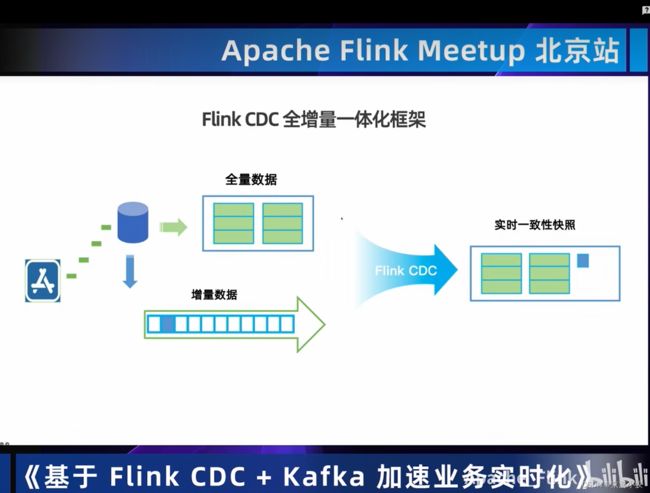
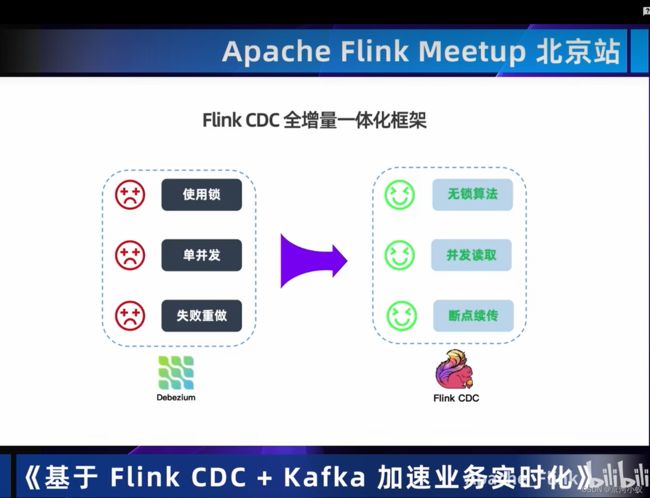

02 Flink+Kafka实时数据集成方案
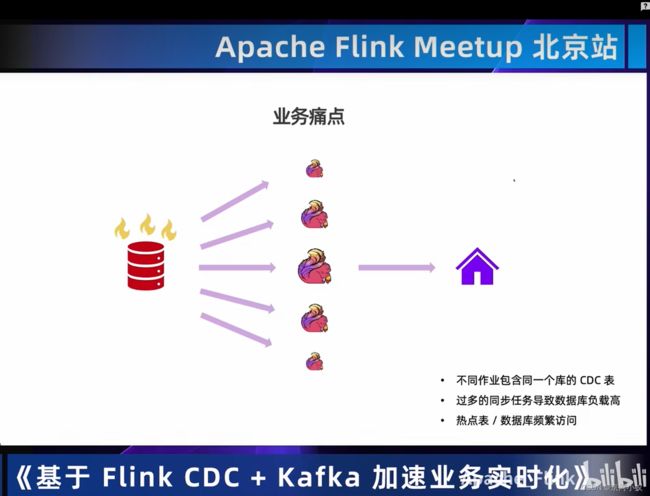
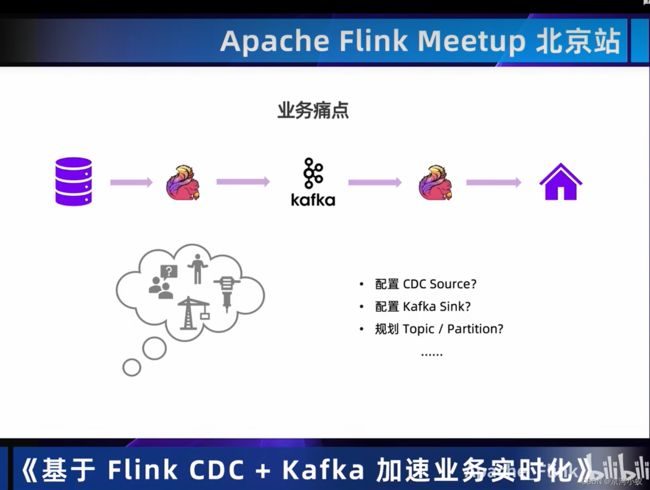
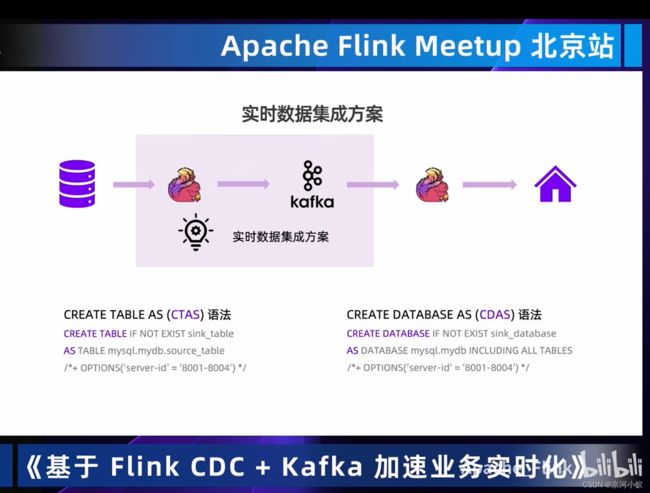
目前CDAS是阿里云商业化的功能,该部分代码在写这篇文章时暂时没有开源。
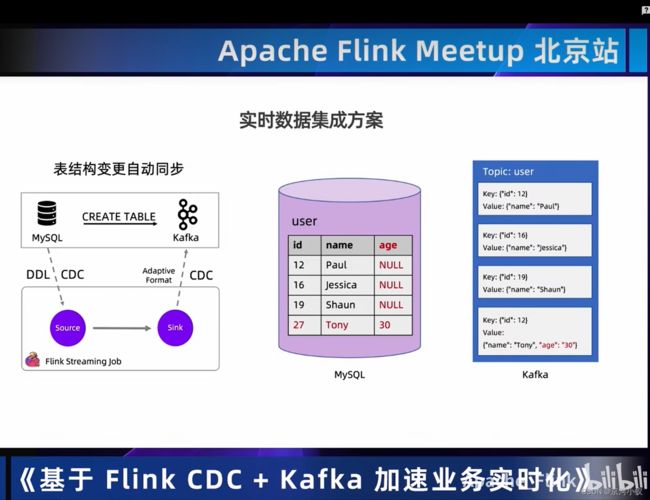
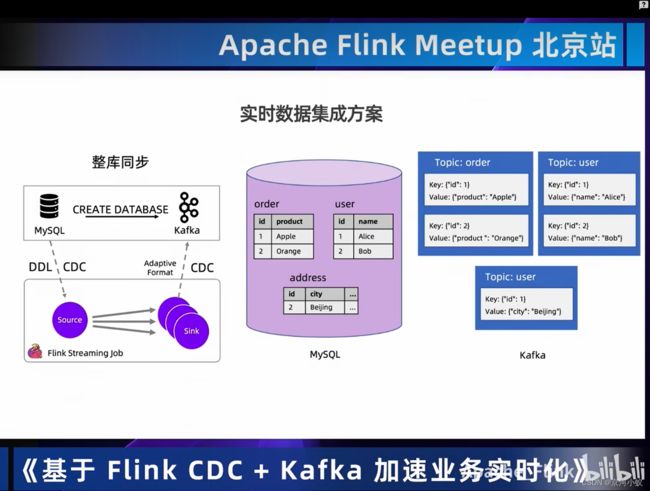

03 Demo:Flink+Kafka实现CDC数据的实时集成和实时分析
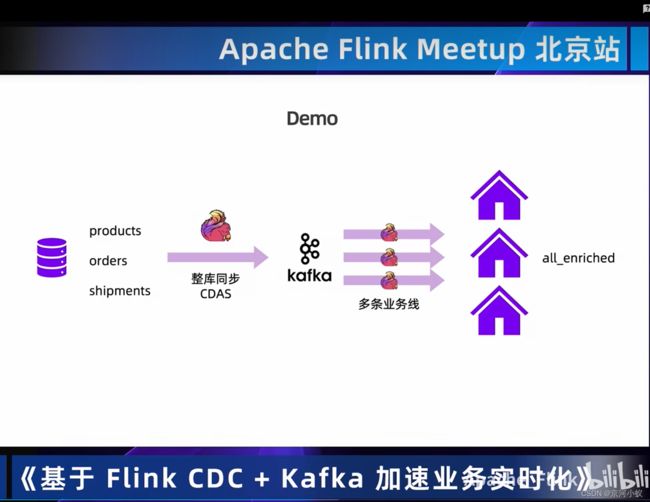
此处省略,有想看的请自行按照上面url查看。
Flink Table Store典型应用场景
01 介绍Flink Table Store
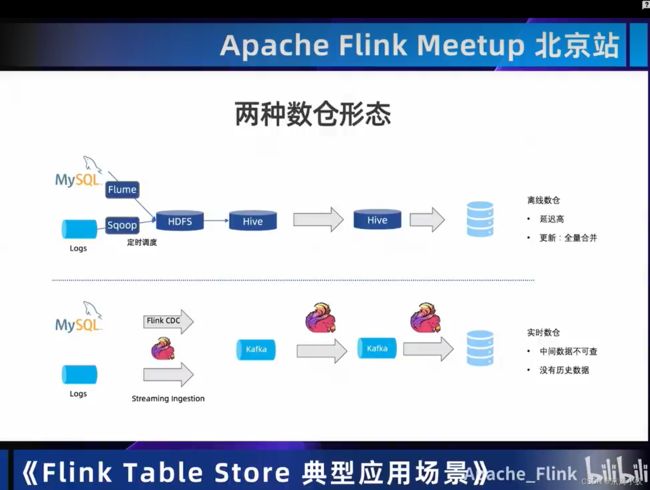
其实我觉得数仓分为实时和离线最好的状态(个人想法)。
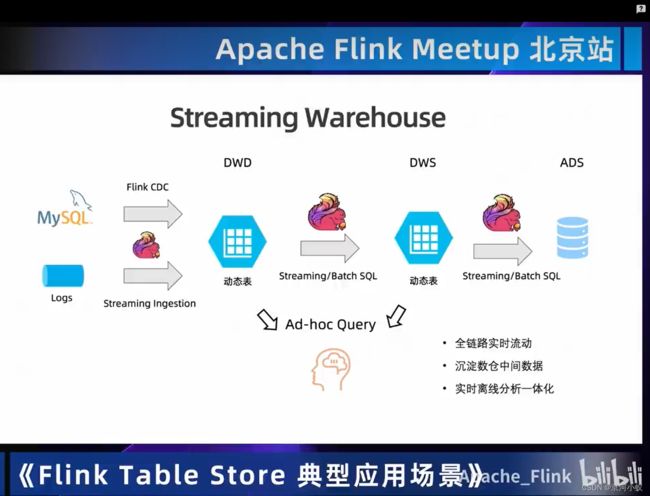

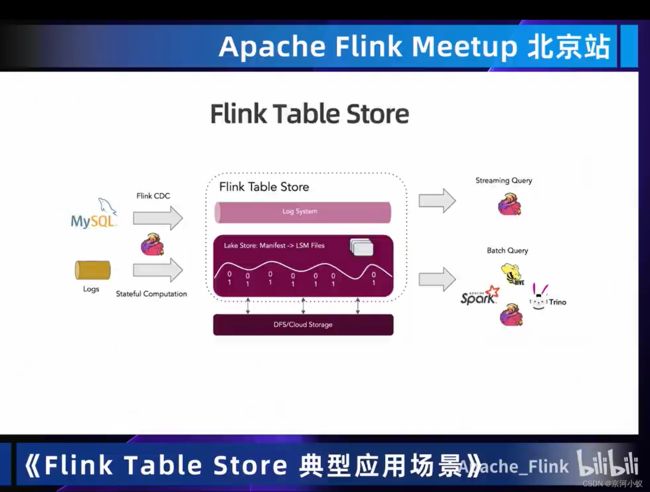
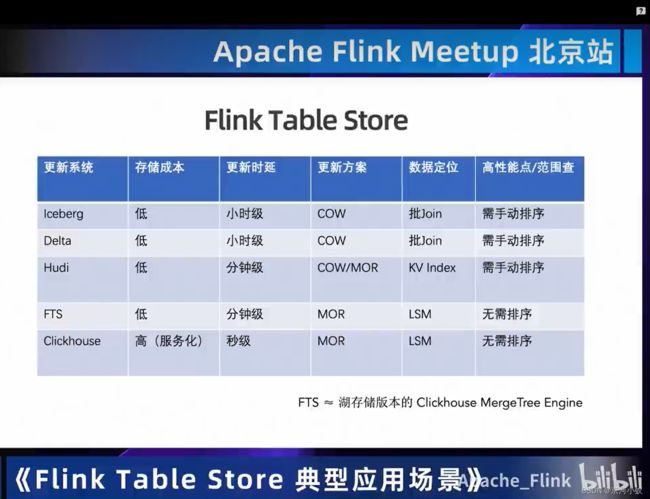
02 应用场景
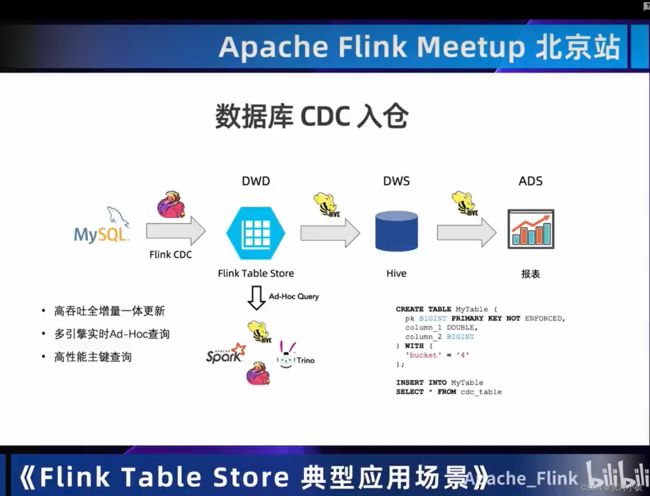
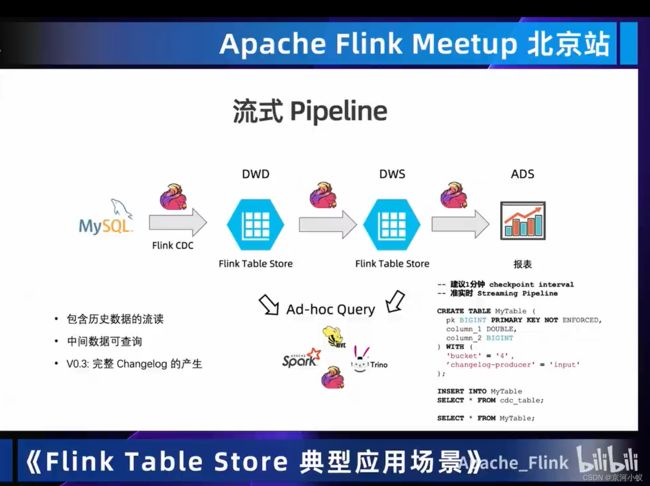

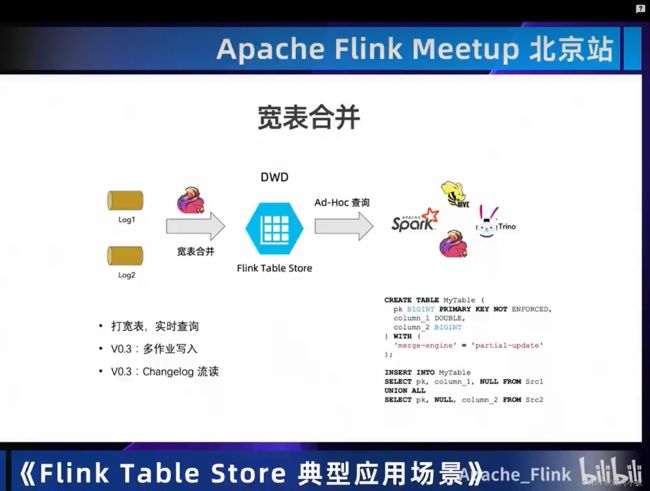
03 Demo
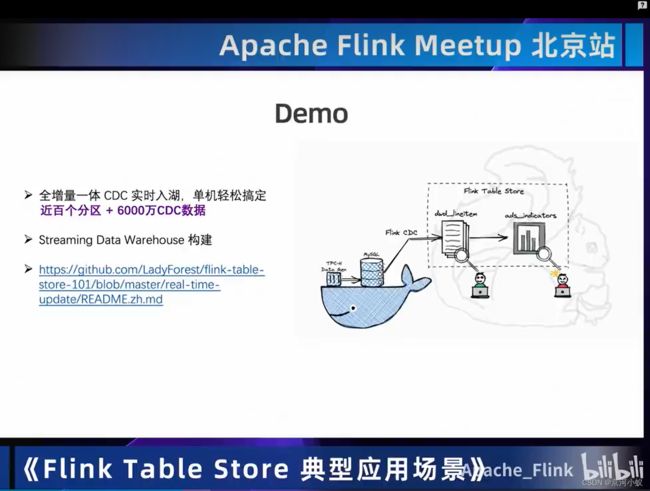
后面自己去看,去听吧,一个小姐姐讲的,声音很好听。。。
04 后续挑战

结语
meetup看了两遍,第一遍感觉听着讲change log那节,比较晦涩,今天又全部听了一遍,感觉对checkpoint的历史节点上优化又有了更深一步的理解。
还有一个感觉就是flink在实时方向已经一超多强了,社区现在除了致力于实时特性更加稳定,更强大,也在尝试着内卷flink。
我始终抱着敬畏的态度学习flink,每一个组件背后都是很多前辈,老师的辛勤的付出,向这些flink等开源人致敬。