相信最近看过我的文章的朋友对于Microsoft.Extensions.ObjectPool不陌生;复用、池化是在很多高性能场景的优化技巧,它能减少内存占用率、降低GC频率、提升系统TPS和降低请求时延。
那么池化和复用对象意味着同一时间会有多个线程访问池,去获取和归还对象,那么这肯定就有并发问题。那ObjectPool在涉及多线程访问资源应该怎么做到线程安全呢?
今天就带大家通过学习ObjectPool的源码聊一聊它是如何实现线程安全的。
源码解析
ObjectPool的关键就在于两个方法,一个是Get用于获取池中的对象,另外就是Return用于归还已经使用完的对象。我们先来简单的看看ObjectPool的默认实现DefaultObjectPool.cs类的内容。
私有字段
先从它的私有变量开始,下面代码中给出,并且注释了其作用:
// 用于存放池化对象的包装数组 长度为构造函数传入的max - 1 // 为什么 -1 是因为性能考虑把第一个元素放到 _firstItem中 private protected readonly ObjectWrapper[] _items; // 池化策略 创建对象 和 回收对象的防范 private protected readonly IPooledObjectPolicy_policy; // 是否默认的策略 是一个IL优化 使编译器生成call 而不是 callvirt private protected readonly bool _isDefaultPolicy; // 因为池化大多数场景只会获取一个对象 为了性能考虑 单独整一个对象不放在数组中 // 避免数组遍历 private protected T? _firstItem; // 这个类是在2.1中引入的,以尽可能地避免接口调用 也就是去虚拟化 callvirt private protected readonly PooledObjectPolicy ? _fastPolicy;
构造方法
另外就是它的构造方法,默认实现DefaultObjectPool有两个构造函数,代码如下所示:
////// Creates an instance of /// The pooling policy to use. public DefaultObjectPool(IPooledObjectPolicy. /// policy) : this(policy, Environment.ProcessorCount * 2) { // 从这个构造方法可以看出,如果我们不指定ObjectPool的池大小 // 那么池大小会是当前可用的CPU核心数*2 } /// /// Creates an instance of /// The pooling policy to use. /// The maximum number of objects to retain in the pool. public DefaultObjectPool(IPooledObjectPolicy. /// policy, int maximumRetained) { _policy = policy ?? throw new ArgumentNullException(nameof(policy)); // 是否为可以消除callvirt的策略 _fastPolicy = policy as PooleObjectPolicy ; // 如上面备注所说 是否为默认策略 可以消除callvirt _isDefaultPolicy = IsDefaultPolicy(); // 初始化_items数组 容量还剩一个在 _firstItem中 _items = new ObjectWrapper[maximumRetained - 1]; bool IsDefaultPolicy() { var type = policy.GetType(); return type.IsGenericType && type.GetGenericTypeDefinition() == typeof(DefaultPooledObjectPolicy<>); } }
Get 方法
如上文所说,Get()方法是ObjectPool中最重要的两个方法之一,它的作用就是从池中获取一个对象,它使用了CAS近似无锁的指令来解决多线程资源争用的问题,代码如下所示:
public override T Get()
{
// 先看_firstItem是否有值
// 这里使用了 Interlocked.CompareExchange这个方法
// 原子性的判断 _firstItem是否等于item
// 如果等于那把null赋值给_firstItem
// 然后返回_firstItem对象原始的值 反之就是什么也不做
var item = _firstItem;
if (item == null || Interlocked.CompareExchange(ref _firstItem, null, item) != item)
{
var items = _items;
// 遍历整个数组
for (var i = 0; i < items.Length; i++)
{
item = items[i].Element;
// 通过原子性的Interlocked.CompareExchange尝试读取一个元素
// 读取成功则返回
if (item != null && Interlocked.CompareExchange(ref items[i].Element, null, item) == item)
{
return item;
}
}
// 如果遍历整个没有获取到元素
// 那么走创建方法,创建一个
item = Create();
}
return item;
}
上面代码中,有一个点解释一下Interlocked.CompareExchange(ref _firstItem, null, item) != item,其中!=item,如果其等于item就说明交换成功了,当前线程获取到_firstItem元素的期间没有其它线程修改_firstItem的值。
Return 方法
Retrun(T obj)方法是ObjectPool另外一个重要的方法,它的作用就是当程序代码把从池中获取的对象使用完以后,将其归还到池中。同样,它也使用CAS指令来解决多线程资源争用的问题,代码如下所示:
public override void Return(T obj)
{
// 使用策略的Return方法对元素进行处理
// 比如 List 需要调用Claer方法清除集合内元素
// StringBuilder之类的也需要调用Claer方法清除缓存的字符
if (_isDefaultPolicy || (_fastPolicy?.Return(obj) ?? _policy.Return(obj)))
{
// 先尝试将归还的元素赋值到 _firstItem中
if (_firstItem != null || Interlocked.CompareExchange(ref _firstItem, obj, null) != null)
{
var items = _items;
// 如果 _firstItem已经存在元素
// 那么遍历整个数组空间 找一个存储为null的空位将对象存储起来
for (var i = 0; i < items.Length && Interlocked.CompareExchange(ref items[i].Element, obj, null) != null; ++i)
{
}
}
}
}
从核心的Get()和Set()方法来看,其实整个代码是比较简单的,除了有一个_firstItem有一个简单的优化,其余没有什么特别的复杂的逻辑。
主要的关键就在Interlocked.CompareExchange方法上,我们在下文来仔细研究一下这个方法。
关于 Interlocked.CompareExchange
Interlocked.CompareExchange它实际上是一个CAS的实现,也就是Compare And Swap,从名字就可以看出来,它就是比较然后交换的意思。
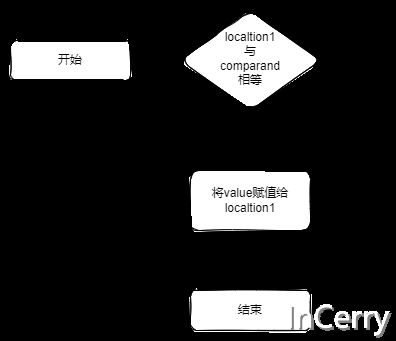
从下面的代码段我们也可以看出来,它总共需要三个参数。其特性就是只有当localtion1 == comparand的时候才会将value赋值给localtion1,另外吧localtion1的原始值返回出来,这些操作都是原子性的。
// localtion1 需要比较的引用A // value 计划给引用A 赋的值 // comparand 和引用A比较的引用 public static T CompareExchange(ref T location1, T value, T comparand) where T : class;
一个简单的流程如下所示:
简单的使用代码如下所示:
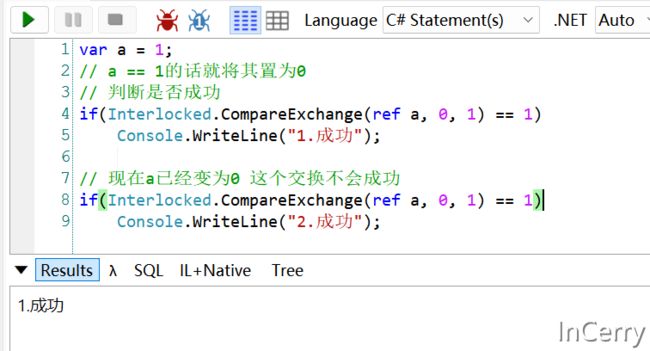
var a = 1;
// a == 1的话就将其置为0
// 判断是否成功就看返回的值是否为a的原始值
if(Interlocked.CompareExchange(ref a, 0, 1) == 1)
Console.WriteLine("1.成功");
// 现在a已经变为0 这个交换不会成功
if(Interlocked.CompareExchange(ref a, 0, 1) == 1)
Console.WriteLine("2.成功");
结果如下所示,只有当a的原始值为1的时候,才会交换成功:
那么Interlocked.CompareExchange是如何做到原子性的?在多核CPU中,数据可能在内存或者L1、L2、L3中(如下图所示),我们如何保证能原子性的对某个数据进行操作?

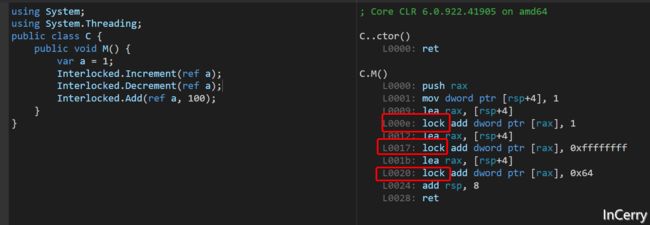
实际上这是CPU提供的功能,如果查看过JIT编译的结果,可以看到CompareExchange是由一条叫lock cmpxchgl的汇编指令支撑的。

其中lock是一个指令前缀,汇编指令被lock修饰后会成为"原子的",lock指令有两种实现方法:
- 早期 - Pentium时代(锁总线),在Pentium及之前的处理器中,带有
lock前缀的指令在执行期间会锁住总线,使得其它处理器暂时无法通过总线访问内存,很显然,这个开销很大。 - 现在 - P6以后时代(锁缓存),在新的处理器中,Intel使用缓存锁定来保证指令执行的原子性,缓存锁定将大大降低lock前缀指令的执行开销。
现在这里的锁缓存(Cache Locking)就是用了Ringbus + MESI协议。
MESI协议是 Cacheline 四种状态的首字母的缩写,分别是修改(Modified)态、独占(Exclusive)态、共享(Shared)态和失效(Invalid)态。 Cache 中缓存的每个 Cache Line 都必须是这四种状态中的一种。
修改态(Modified),如果该 Cache Line 在多个 Cache 中都有备份,那么只有一个备份能处于这种状态,并且“dirty”标志位被置上。拥有修改态 Cache Line 的 Cache 需要在某个合适的时候把该 Cache Line 写回到内存中。但是在写回之前,任何处理器对该 Cache Line在内存中相对应的内存块都不能进行读操作。 Cache Line 被写回到内存中之后,其状态就由修改态变为共享态。
独占态(Exclusive),和修改状态一样,如果该 Cache Line 在多个 Cache 中都有备份,那么只有一个备份能处于这种状态,但是“dirty”标志位没有置上,因为它是和主内存内容保持一致的一份拷贝。如果产生一个读请求,它就可以在任何时候变成共享态。相应地,如果产生了一个写请求,它就可以在任何时候变成修改态。
共享态(Shared),意味着该 Cache Line 可能在多个 Cache 中都有备份,并且是相同的状态,它是和内存内容保持一致的一份拷贝,而且可以在任何时候都变成其他三种状态。
失效态(Invalid),该 Cache Line 要么已经不在 Cache 中,要么它的内容已经过时。一旦某个Cache Line 被标记为失效,那它就被当作从来没被加载到 Cache 中。
总得来说,若干个CPU核心通过Ringbus连到一起。每个核心都维护自己的Cache的状态。如果对于同一份内存数据在多个核里都有Cache,则状态都为S(Shared)。
一旦有一核心改了这个数据(状态变成了M),其他核心就能瞬间通过Ringbus感知到这个修改,从而把自己的Cache状态变成I(Invalid),并且从标记为M的Cache中读过来。同时,这个数据会被原子的写回到主存。最终,Cache的状态又会变为S。
关于MESI协议更详细的信息就不在本文中介绍了,在计算机操作系统和体系结构相关书籍和资料中有更详细的介绍。
然后compxchg这个指令就很简单了,和我们之前提到的一样,比较两个地址中的值是否相等,如果相等的话那么就修改。
Interlocked类中的其它方法也是同样的原理,我们可以看看Add之类的方法,同样是在对应的操作指令前加了lock指令。
总结
本文主要是带大家看了下ObjectPool的源码,然后看了看ObjectPool能实现无锁线程安全的最大功臣Interlocked.CompareExchange方法;然后通过汇编代码了解了一下Interlocked类中的一些方法是如何做到原子性的。
到此这篇关于从ObjectPool到CAS指令的文章就介绍到这了,更多相关ObjectPool到CAS指令内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!