计算机是如何工作的
1. 计算机发展史
在人类历史中有很多发明是用于"军事",比如火药,枪,计算机…计算机诞生于"普林斯顿大学",而最初计算机的诞生的目的是用来计算"弹道导弹"的轨迹,其发展大体经历了从一般计算工具到机械计算机到目前的电子计算机的发展历程 :

2. 冯诺依曼体系
现代的计算机,大多数都遵守 冯诺依曼体系 (Von Neumann Architecture)
脱离了冯·诺依曼结构原有模式的计算机,例如光子计算机(光处理器利用光的高速和无干扰性,使用光学元件构成处理器,尚在研发中),并行计算机、数据流计算机以及量子计算机等

- CPU 中央处理器: 进行算术运算和逻辑判断.
- 存储器: 分为外存和内存, 用于存储数据(使用二进制方式存储)
- 输入设备: 用户给计算机发号施令的设备.
- 输出设备: 计算机个用户汇报结果的设备.
对于存储空间: 硬盘 > 内存 > > CPU
对于访问速度: CPU > > 内存 > 硬盘
CPU的主频代表CUP的运算速度,比如3.2GHz(1G = 10亿, Hz代表1s运算1次)代表CPU1秒可以计算32亿次
- 显卡和CPU的区别:
- 二者本质没有什么区别,具体区别在与一个是全能王另一个是人柱力:
- CPU叫做通用处理器,应对各种计算场景.
- 显卡叫做专用处理器,特别擅长计算大规模浮点数,尤其是矩阵运算,所以在玩3A大作时,需要依赖大量计算,这时候就需要强大的显卡.
认识计算机的祖师爷 – 冯诺依曼
冯·诺依曼(John von Neumann,1903年12月28日-1957年2月8日), 美籍匈牙利数学家、计算机科学家、物理学家,是20世纪最重要的数学家之一。冯·诺依曼是布达佩斯大学数学博士,在现代计算机、博弈论、核武器和生化武器等领域内的科学全才之一,被后人称为**“现代计算机之父”、“博弈论之父” .**

3. CPU基本工作流程
下面将计算CPU从无到有的过程中,是如何一步一步搭建出来的.
3.1 逻辑门
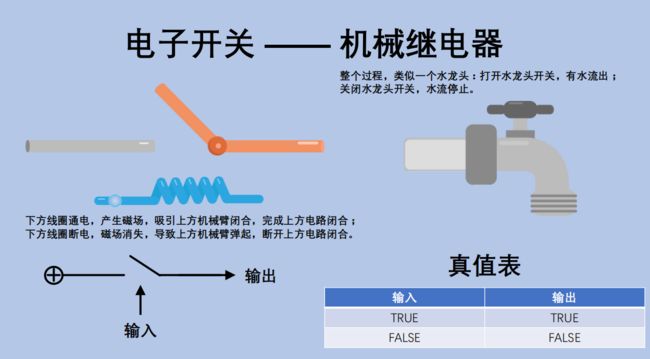
3.1.1 电子开关 —— 机械继电器(Mechanical Relay)
通过电子开关,实现1位(bit)的逻辑运算.
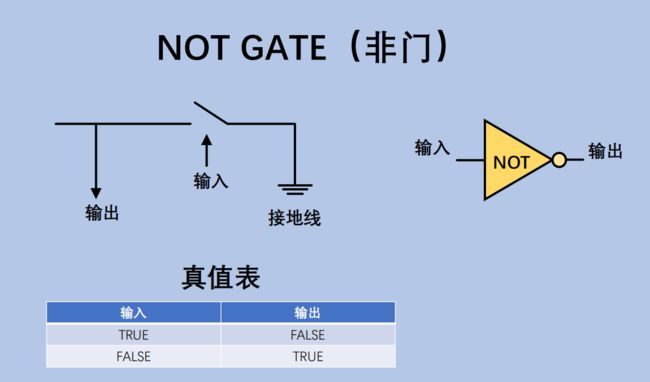
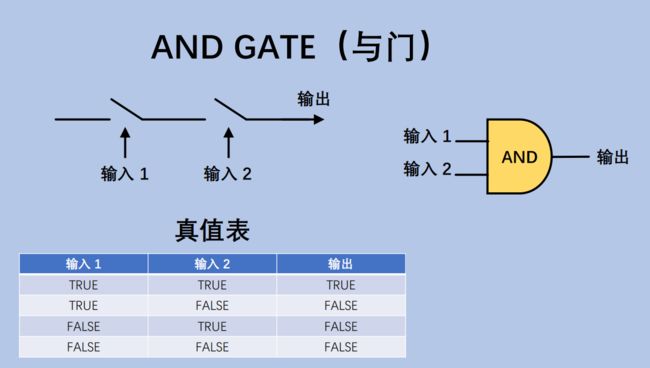
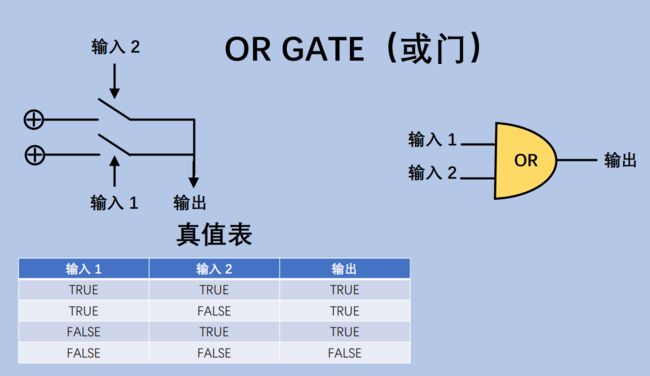
3.1.2 门电路(Gate Circuit)
通过电子开关实现1位(bit)的"门电路" – 非门,或门,与门,异或门,
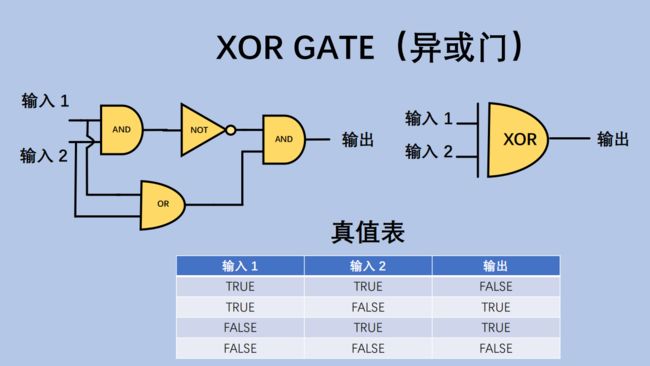
3.2 算术逻辑单元 ALU(Arithmetic & Logic Unit)
ALU 是计算机中进行算数、逻辑运算的核心部件,是计算机的数学大脑 ,ALU用以计算机指令集中的执行算术与逻辑操作;ALU分为两部分,逻辑单元(LU)在上面已经谈到,下面的是算术单元 (AU),在介绍它之前,我们要知道数字在计算机中是以二级制来存储的.
3.2.1 进制的理解

注:二进制都以补码的形式来存储
3.2.2 算术单元(Arithmetic Unit)
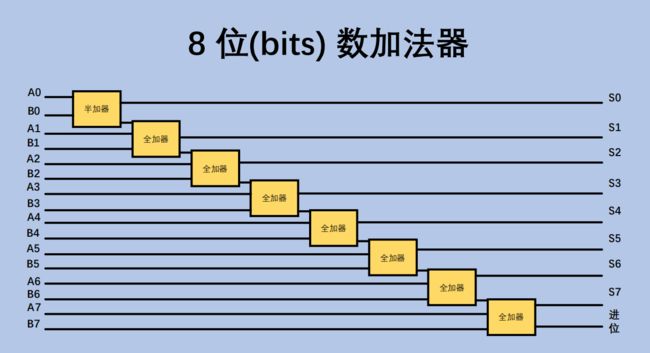
算数单元负责计算简单的四则运算,下面我们简单了解一个8位的加法器(adder)
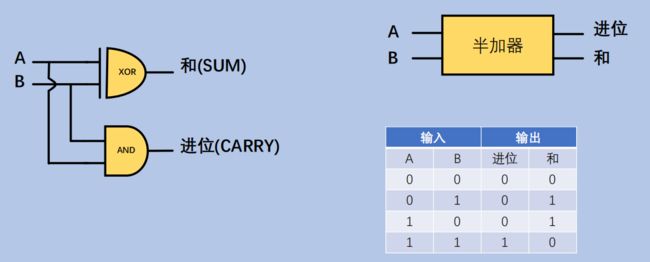
- 半加器 - 实现两个1位的相加
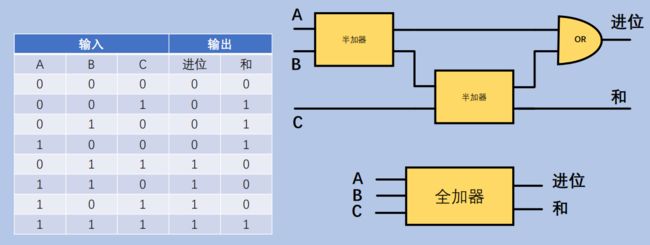
- 全加器 - 实现三个1位的相加
- 加法器 - 8位相加版
3.2.3 逻辑单元(Logic Unit)
逻辑单元主要用来进行逻辑操作,最基本的操作就是 与、或、非操作,但不只是一位(bit)数的比较 .
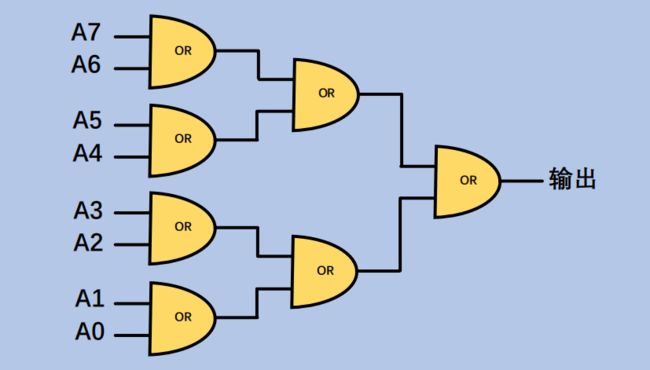
3.3 寄存器(Register) 和内存(RAM)
ALU已经为我们提供逻辑运算和算数运算,接下来将计算存储的部件,当然这些部件都是在通电情况下,不同于与外存(存储是数据是不易失),这些存储都是易失的(volatile).并且其存储空间更小(一般就是几百个字节),访问速度更快(比内存快3~4个数量级)
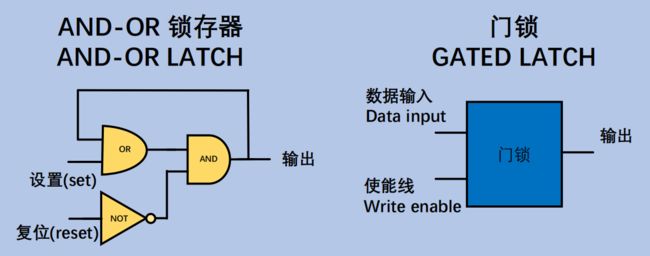
- 1位(bit))寄存器:
中间我们隐藏了一些实现细节,最后的效果就是:使能线置位时,输入为 1,保存 1;输入为 0,保存0。使能线不置位时,则写入无效
- 8位(bits))寄存器:
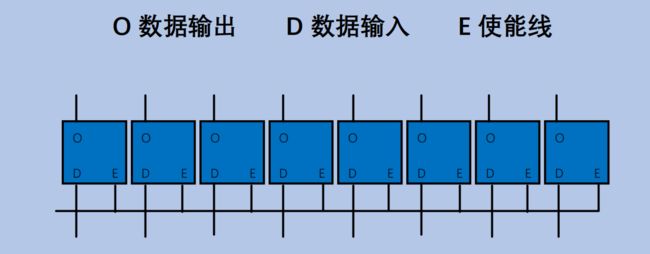
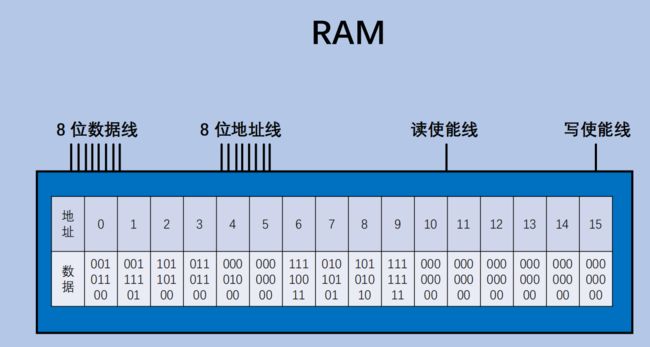
内存的构建要比这个复杂一点,但基本原理一致。如此构建的内存被称为 RAM(Random AccessMemory),可以支持 O(1) 时间复杂度访问任意位置的数据,这也就是我们数组下标访问操作是 O(1)的硬件支持 .
3.4 控制单元 CU(Control Unit)
现在有 ALU、存储了,但这还是不足以让我们的计算机工作起来,我们需要有一个部件来指挥 ALU进行何种的运算,而这个部件就是控制单元(CU)
现在CU就可以驱动 ALU 进行具体的计算工作
3.5 指令(Instruction)
所谓指令,即指导 CPU 进行工作的命令,主要有操作码 + 被操作数组成
- 操作码用来表示要做什么动作
- 被操作数是本条指令要操作的数据,可能是内存地址,也可能是寄存器编号等
指令本身也是一个数字,用二进制形式保存在内存的某个区域中.

3.6 CPU的基本工作流程
接下来将演示指令运行的一个周期 .
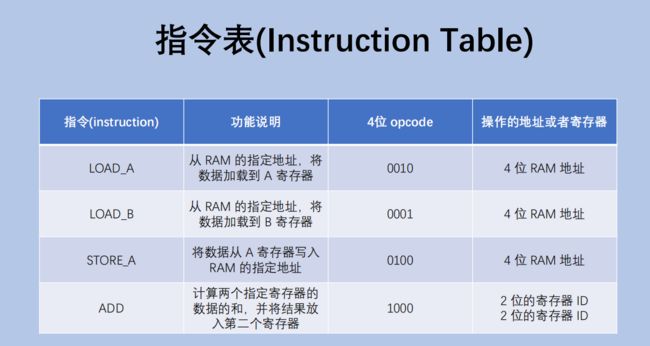
下面这个表表示内存中的一个片段,每个内存地址中存的都是一个指令,每个指令都是按照指令表来解析的.

- CPU先从内存中读取指令
Q1: 从那个地址开始读?
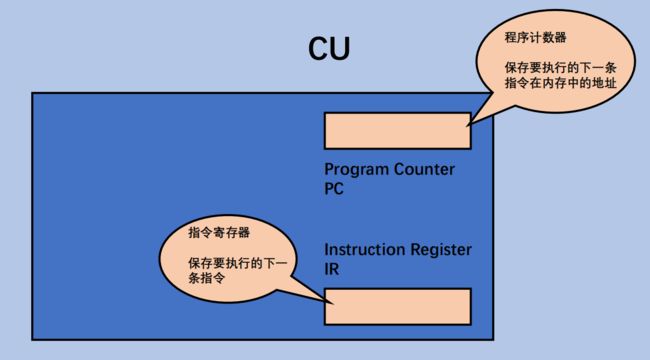
在CPU里有一个特殊的寄存器,叫做"程序计数器”,也称为PC指针,实际上在x86_32 CPU叫做EIP寄存器(还有EBP - 栈底指针, ESP:栈顶指针),程序计数器中就包含了一个"地址",表示接下来要读哪个内存里的指令.
读取的指令为 00101110
- 解析指令
指令0010为LOAD_A 要读取的内存地址为1110 - 整个指令的含义,就是从1110这个地址里读一个字节进到A寄存器中.
- 执行指令
找到1110地址处的字段(十进制为14) - > 00000011 也就是十进制的3 -> 寄存器A中存放3 -> 程序计数器累计
- 读取指令
读取指令为 00011111
- 解析指令
指令 0001为LOAD_B 要读取的内存地址为1111 - 整个指令的含义,就是从1110这个地址里读一个字节进到B寄存器中.
- 执行指令
找到1110地址处的字段(十进制为15) - > 00001110 也就是十进制的3 -> 寄存器B中存放14-> 程序计数器累计
- 读取指令
读取指令为 10000100
- 解析指令
指令1000为ADD 要读取的内存地址为0100 - 这里的01是B寄存器,00是A寄存器 - 也就是说把AB寄存器中的值相加后的结果放入A
- 执行指令
执行加法A寄存器中值为17 - 程序计数器累计
- 读取指令
读取指令为 01001101
- 解析指令
指令0100为STORE_A 要读取的内存地址为1101
- 执行指令
把A寄存器中的17写入到内存地址为1101(十进制为13) - pc自增
看起来好像是, CPU读一个指令,再解析指令,再执行指令然后再读下一条…但实际上不是,实际上CPU是类似于"流水线"的方式来执行的.

我们来总结下执行周期经过哪些阶段
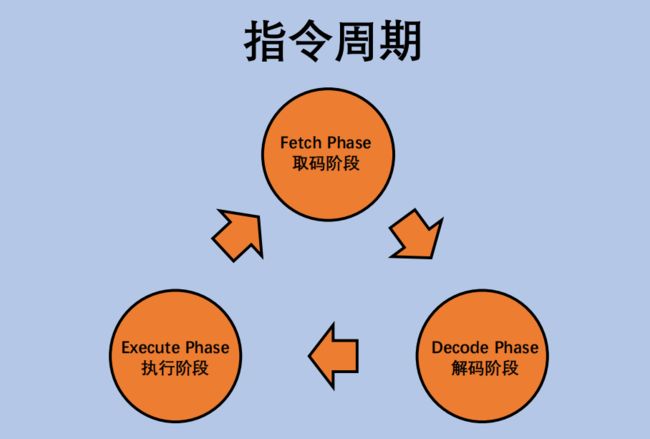
当然,电子计算机中的 CPU 可不像我们刚才那样,靠自己来驱动这个周期的运转,而是靠背后一个时钟来进行周期驱动的.
最后,ALU + CU + 寄存器 + 时钟就组成了我们平时经常看到的一个词汇:中央处理器(Center Process Unit)简称 CPU。
总结:
- CPU内部本质上是由一大堆的门电路构成
- CPU内部的集成程度越高,就认为计算能力越强
- CPU上面还包含了寄存器,可以存储一些运算的中间结果.
- CPU执行程序的过程,大概是取指令,解析指令,执行指令
4. 编程语言(Program Language)
上面我们知道了CPU和内存内部的简单构造与原理,这些操作计算机的指令都是机器指令,如何和我们现在学习的高级语言C/C++,Java…联系起来的呢???
4.1 程序(Program)
程序,就是一组指令以及这组指令要处理的数据。平时咱们所说的程序大多指的是一个“可执行文件”.exe是在硬盘上的,是一个文件.
当双击exe运行的时候,操作系统就会读取这个文件,把里面的关键信息加载到内存中.
Java代码也是同理.写了一个.java 编译生成.class文件, .class就会被JVM进行加载 .class里面保存的就是一些二进制指令(和CPU无关)也就会先放到内存中了
程序 = 指令 + 指令要处理的数据
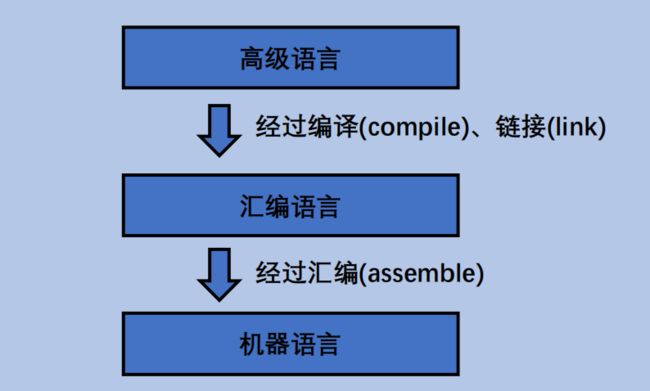
4.2 编程语言发展史
编程语言的类型
第一代机器语言
机器语言是由二进制 0、1 代码指令构成,不同的 CPU 具有不同的指令系统。机器语言程序难编写、难修改、难维护,需要用户直接对存储空间进行分配,编程效率极低。这种语言已经被渐渐淘汰了。
第二代汇编语言
汇编语言指令是机器指令的符号化,与机器指令存在着直接的对应关系,所以汇编语言同样存在着难学难用、容易出错、维护困难等缺点。但是汇编语言也有自己的优点:可直接访问系统接口,汇编程序翻译成的机器语言程序的效率高。 从软件工程角度来看,只有在高级语言不能满足设计要求,或不具备支持某种特定功能的技术性能(如特殊的输入输出)时,汇编语言才被使用。
第三代高级语言
高级语言是面向用户的、基本上独立于计算机种类和结构的语言。其最大的优点是:形式上接近于算术语言和自然语言,概念上接近于人们通常使用的概念。高级语言的一个命令可以代替几条、几十条甚至几百条汇编语言的指令。因此,高级语言易学易用,通用性强,应用广泛。高级语言种类繁多,可以从应用特点和对客观系统的描述两个方面对其进一步分类。
5. 操作系统(Operating System)
CPU,存储器,输入设备,输出设备,都是"硬件"设备,普通用户,和硬件打交道,并不是一件方便的事情,聪明的程序猿发明了一个软件,就是操作系统.
5.1 操作系统的功能
操作系统的核心功能:
- 对下,要管理各种硬件设备
- 对上,要给各种软件提供稳定的运行环境
目前常见的操作系统有:Windows系列、Unix系列、Linux系列、Android系列、iOS系列等.

- 系统调用: **由操作系统实现提供的所有系统调用所构成的集合即程序接口或应用编程接口(Application Programming Interface,API)。是应用程序同系统之间的接口。**就比如你想往控制台打印一个"hello"这个过程你需要调用printf .(库函数)
内部就要调用操作系统提供的系统调用write .调用write就会进入到内核来执行.内核的话就要进一步的控制硬件,完成输出过程- 操作系统内核: 内核,是一个操作系统的核心。提供操作系统的最基本的功能,是操作系统工作的基础,它负责管理系统的进程、内存、设备驱动程序、文件和网系统,决定着系统的性能和稳定性.当我们使用系统调用进入操作系统内核的时候就会涉及到用户态到内核态之间的切换.由于内核只有一个,应用程序有很多,这些程序都需要靠我们的这个操作系统内核来提供工作支持.就很可能要排队等待.
- 驱动程序: 可以使计算机和设备进行相互通信的特殊程序。相当于硬件的接口,操作系统只有通过这个接口,才能控制硬件设备的工作,假如某设备的驱动程序未能正确安装,便不能正常工作。因此,驱动程序被比作“ 硬件的灵魂”、“硬件的主宰”、“硬件和系统之间的桥梁”等。
- 硬件: 硬件的功能是输入并存储程序和数据,以及执行程序把数据加工成可以利用的形式。
总而言之,操作系统就是一个搞管理的软件,比如内存管理,文件管理,设备管理,进程管理…
5.2 进程/任务(Process/Task)
进程/任务是同一事物不同说法,指的是操作系统对一个正在运行的程序的一种抽象.换句话说,就是一个程序运行起来,完成一系列任务的表现.
进程与程序(可执行文件)的区别:
打开任务管理器可以查看当前电脑上运行的进程:
下面是一个可执行文件:
一个可执行文件,没有对它进行操作时,是"静态"的,即在硬盘上,当我们双击运行的时候,操作系统就会把这个可执行文件的关键信息加载到内存中,并且开始运行里面的代码,这样就由"静态"转变为"动态"了.

在操作系统内部,进程又是操作系统进行资源分配的基本单位.那么在同一时间,操作系统上运行着很多进程,这时候就需要进程管理
5.3 进程控制块抽象(PCB Process Control Block)
对于许多的进程操作系统是如何管理的呢?
- 先描述: 使用一个类/结构体(操作系统就是C语言实现的,而结构体就是低配的类),把进程的特征给描述出来.
- 再组织: 使用一个数据结构把多个对象/结构体 组织起来.
再Java中,用PCB(进程控制块) 来描述这一特性,里面就包含进程的核心信息,在操作系统内核提供双向链表,搜索树等一系列数据结构来管理.
PCB的简单信息:
- 进程的身份标识 - pid
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-C3twZ5zg-1658471166923)(C:\Users\a\AppData\Roaming\Typora\typora-user-images\image-20220721170750806.png)]
内存指针
描述该进程的内存中哪些部分是指令,那些部分是数据,操作系统要把一些必要的数据(运行的指令-代码, 运行所依赖的数据 - 全局变量)加载到内存中就形成内存指针.
文件描述符表
表示当前进程都打开了那些文件,当我们打开文件时,就会在文件描述符表里给这个文件分配一个表项, 而文件描述符表可以理解为一个顺序表,每个元素就代表一个打开的文件,对应的顺序表下标就是"文件描述符".
而内存指针和文件描述符表就描述了进程持有哪些系统的资源
5.4 CPU 分配 —— 进程调度(Process Scheduling)
如今的计算机的CPU核心数是有限的,而进程的数量是很多的,成百上千,比如本机的CPU内核为8,在此时进程数为224.现在最多核心的CPU有AMD的线程撕裂者和霄龙,都有64核;英特尔的至强铂金 9282 处理器,56核.

那么这样就造成的狼多肉少(CPU核心数少,进程多)的现象,所以操作系统要做到尽可能的公平,让每个"狼"都有吃"肉"的机会,这时候就需要"轮流吃",这里的轮转速度是非常快的,比如CPU的主频是3.2GHz,那么1s就有32亿个时钟周期.
由于轮转速度十分快,因此人根本感受不到这种轮转,在宏观角度下:好像这些进程都是同时执行,但是在微观的角度下,并不是同时进行的,而是"轮流"的方式占用CPU执行 - 并发式的执行
由于CPU上有多个核心.每个核心上都可以跑一个进程.某一时刻两个进程就是在两个CPU核心上同时执行的 - 并行式的执行
在实际开发中,并不会对这两概念做明确的区分,往往使用"并发"概括表示"并发”“和"并行”,称为"并发编程"
辅助进程调度的设计理念:
- 进程的优先级
- 进程的状态
- 进程的记账记录
- 进程的上下文
举个栗子:
假设本人是一个女神级别的妹子,有很多追求者,现在在我的鱼塘里,有三个男朋友,当然不会让三人有交集.
A:有钱,给我买很多漂亮的衣服,包包…;B帅,平时就发我和她的照片到朋友圈;C会舔,能把我舔的很舒服;
于是我化身为"时间管理大师",要规划出一个时间表,规划在什么时间段和谁交往,并且不能让他们知道.
比如: 周一:和A取逛街,买衣服; 周二:和B去野餐;周三:和C去上课…
在这里,就可以把我当成一个CPU,ABC是三个进程,在我时间表的安排下,就好像三个进程在CPU上并发执行
- 进程的优先级
对应到我在安排时间表时的优先级问题,比如优先给A安排时间把我这一周最整块的时间都安排给A,其次给B安排时间
至于C,就看剩下的时间了(舔到最后一无所有)
-
进程的状态
比如A说这周要出差两个礼拜,于是接下来的时间就只给B和C安排就行了,安排时间表的时候要考虑到每个人的当前的特定情况
对于进程来说,有很多的状态,其中最典型的:就绪状态:进程是准备就绪的,随时可以上CPU执行.阻塞状态:进程在等待某个任务完成(读写磁盘),完成之后才能上CPU,完成之前,就没法继续执行,正常情况下,ABC都是就绪状态(我随便排时间,他们都是随叫随到)如果A出差了,(相当于进入阻塞状态),此时我就无法给A安排时间
-
进程的进账记录
在安排时间表的时候,我就需要考虑到一些历史记录(以往的安排),比如连续好几个礼拜,都给C安排的时间太少了,我一看统计数据,C的时 间太少,我可能就要失去这个小可爱了,下一周排时间的时候就给C稍微多排一些.对应到操作系统在安排进程的时候,也会记录每个进 程以往在CPU上执行的时间/执行的指令数…如果发现某个进程被安排的太少,就会适当的调整策略.
- 进程的上下文
某一次,某一次,我和A在一起的时候,和A说好了,放暑假时,他带我去夏威夷旅游;有一次,我和B在一起的时候,B和我说好了,下次见面的时候他会给我带个小礼物,当我下次遇到A的时候,就可以问他说:夏威夷那边准备的咋样了?当我遇到B的时候,就可以问他说:你的礼物呢?为了避免出现穿帮的情况我就需要记录好,每次约会后的一些关键信息,尤其是这次约会还没处理完的一些事情,要下次在处理,就需要明确的记录好当前处理的进度/中间结果,这样下次约会的时候就可以从上次的结果中继续往下进行了.对于进程来说,上下文,具体指的就是CPU里的一堆寄存器里面的值.上下文就会在进程被切出CPU的时候把寄存器的状态保存到PCB里(内存)下次进程回到CPU上就把PCB里的上下文读取出来,恢复到CPU寄存器中
5.5 内存分配 —— 内存管理(Memory Manage)
操作系统对进程分配的资源有很多,其中一个很关键的就是内存资源,每个进程对应着自己的PCB,其中的内存指针,就会指向电脑中的内存,从而达到对内存资源的使用,但是有可能内存指针中的存放的地址是其他进制的地址呢?很有可能,在这种操作下,可能会把其他进程给整崩溃了,使操作系统不稳定,而操作系统要给应用程序提供稳定的运行环境,所以为了让各个进程之间互不影响,操作系统就引入了"虚拟地址空间"这样的概念,每个进程都只能访问到自己的地址空间,相互之间不会有影响了,哪怕你指针指错,操作系统也能及时发现,不会影响到其他的进程,就算出问题,问题也被限制到进程的内部了.

所以对于进程1和进程二,即使他们的虚拟地址是相同的,但是由于通过MMU这种映射关系得到的真实地址是不同的,所以就有效的避免进程之间的相互影响,如果访问到一个错误的地址,MMU就会向操作系统发送错误信息:有进程访问内存错了;随即操作系统就会反馈到进制中,告诉进程你内存访问出错了,这个反馈的表现为- 让进程终止运行(程序崩溃).
5.6 进程间通信(Inter Process Communication)
从上面所述中我们可以知道进程是操作系统进行资源分配的最小单位 ,这意味着各个进程互相之间是无法感受到对方存在的,这就是操作系统抽象出进程这一概念的初衷,这样便带来了进程之间互相具备”隔离性(Isolation)“。
对于每一个进程来说,它们都有它自己的"虚拟地址空间",那么对于操作系统来说,如果内存中的进程很多,这些"虚拟地址空间"会不会比物理内存大呢?
虽然系统里的进程这么多,但是实际上,
同一时刻执行的进程没几个
即使同一时刻,有好几个进程再跑,这些进程也不是同时把所有的虚拟地址空间的内存都使用上了->虽然每个进程的虚拟空间很大,但是实际使用的内存只有一小部分.物理内存只需要把真实使用的这部分内存数据给表示出来即可
极端情况下,确实同时跑的这几个进程同时吃了很多的真实内存,确实会导致物理内存不够~~(出现这种情况。算bug,因此程序猿就需要想办法优化一下内存占用,或者扩容换一个内存更大的机器)比如服务器开发就很吃内存.
进程引入了隔离性,确实让系统更稳定了,但是也有别的问题,多个进程之间要想配合工作,就麻烦了,操作系统又引入了"进程间通信",在隔离性的前提下,开了个口子,让多个进程之间能相互通信.
操作系统提供的进程间通信方式有很多种,但是本质上都是一样的,搞一个多个进程之间都能访问到的公共资源,借助公共资源来进行通信
目前,主流操作系统提供的进程通信机制有如下 :
- 管道.
- 共享内存
- 文件
- 网络
- 信号量
- 信号
其中,网络是一种相对特殊的 IPC 机制,也是现在最主要使用的方式,它除了支持同主机两个进程间通信,还支持同一网络内部非同一主机上的进程间进行通信。
据给表示出来即可
- 极端情况下,确实同时跑的这几个进程同时吃了很多的真实内存,确实会导致物理内存不够~~(出现这种情况。算bug,因此程序猿就需要想办法优化一下内存占用,或者扩容换一个内存更大的机器)比如服务器开发就很吃内存.
进程引入了隔离性,确实让系统更稳定了,但是也有别的问题,多个进程之间要想配合工作,就麻烦了,操作系统又引入了"进程间通信",在隔离性的前提下,开了个口子,让多个进程之间能相互通信.
操作系统提供的进程间通信方式有很多种,但是本质上都是一样的,搞一个多个进程之间都能访问到的公共资源,借助公共资源来进行通信
目前,主流操作系统提供的进程通信机制有如下 :
- 管道.
- 共享内存
- 文件
- 网络
- 信号量
- 信号
其中,网络是一种相对特殊的 IPC 机制,也是现在最主要使用的方式,它除了支持同主机两个进程间通信,还支持同一网络内部非同一主机上的进程间进行通信。