动态规划——编辑距离系列问题
动态规划——编辑距离系列问题
- 1 概述
- 2 实战
-
- 2.1 判断子序列
- 2.2 不同的子序列
- 2.3 小结
- 2.4 两个字符串的删除操作
- 2.5 编辑距离
- 参考
1 概述
编辑距离原题——72. 编辑距离,是LeetCode上的一道 hard 级别的题目,该题允许对两个字符串进行增删改(没有查)的操作,而一些类似的题目可能操作起来没有这道题这么复杂,但是也可利用同样的思路去做,因此我们把这些题型提取出来,当作一个知识点来做巩固。下面将按照由易到难的顺序来依次解决这些题目,当然有一些题目也可以用贪心等思想去做,但是由于本文着重讲解动态规划算法,所以涉及到其它的算法暂不作讨论。
2 实战
2.1 判断子序列
LeetCode链接:392. 判断子序列
给定字符串 s 和 t ,判断 s 是否为 t 的子序列。
字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,"ace"是"abcde"的一个子序列,而"aec"不是)。
示例 1:
输入:s = “abc”, t = “ahbgdc”
输出:true
示例 2:
输入:s = “axc”, t = “ahbgdc”
输出:false
提示:
0 <= s.length <= 100
0 <= t.length <= 10^4
两个字符串都只由小写字符组成。
- 思路:s 和 t 都从空串开始一点点扩,在这个过程中不断判断 s 的 子串是否为 t 子串的子序列,最终得到完整的 s 是否为完整的 t 的子序列。特别地,当 s 为 t 的子串的子序列时,s 一定也为 t 的子序列。
- dp 数组和下标的定义
- 本题涉及到两个字符串,所以我们下意识定义一个二维 dp 数组,一维代表 s 字符串,另一维代表 t 字符串。
dp[i][j]表示以第 i - 1 位结束的 s 串是否为以 j - 1 位结束的 t 串的子序列。至于为啥定义为 i - 1 和 j - 1,纯粹是为了编码(初始化)方便,如果不是很明白,可以自行定义为以第 i 位和第 j 位结尾。
// dp[i][j] 以i-1结尾的s是否是以j-1结尾的t的子序列
boolean[][] dp = new boolean[lens + 1][lent + 1];
- 递推公式
-
涉及到两个字符串(数组)的问题,大方向是分为两种情况来讨论 —— 当前位置的值相等、当前位置的值不相等:
-
if (s[i - 1] == t[j - 1]):

当前位置的值相等时,我们可以同时去掉两字符串中该相等字符,判断以第 i - 2 位结束的 s 串是否为以 j - 2 位结束的 t 串的子序列,即考虑
dp[i - 1][j -1]的值。如果以第 i - 2 位结束的 s 串是以 j - 2 位结束的 t 串的子序列,那么两个字符串都加上相等的这一位,就能确定以第 i - 1 位结束的 s 串是否为以 j - 1 位结束的 t 串的子序列;
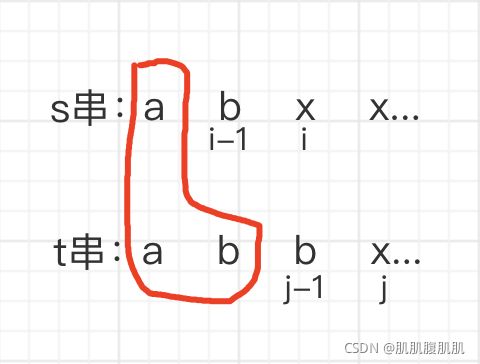
除此之外,我们也可以仅去掉 t 串中的相同位,判断以第 i - 1 位结束的 s 串是否为以 j - 2 位结束的 t 串的子序列,即考虑
dp[i][j - 1]。如果以第 i - 1 位结束的 s 串为以 j - 2 位结束的 t 串的子序列,那么当 t 串加上去掉的那一位,该结论依旧成立。
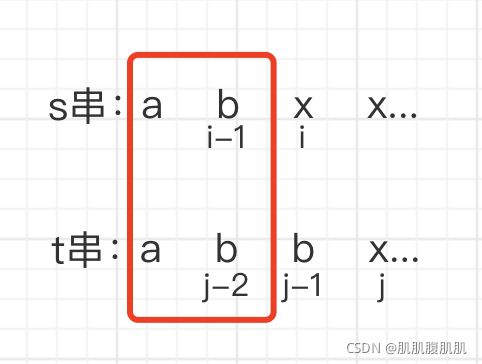
所以当
s[i - 1] == t[j - 1]时,dp[i][j] = dp[i - 1][j -1] || dp[i][j - 1]。
- if (s[i - 1] != t[j - 1]):
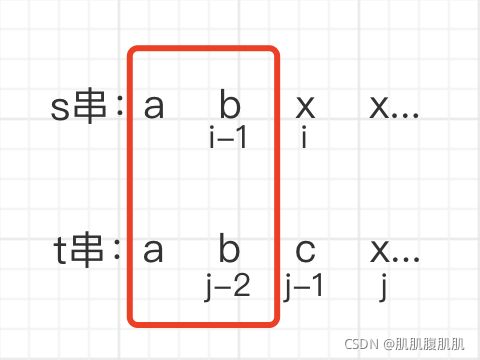
当 s 串的第 i-1 位不等于 t 串的第 j - 1 位时,我们将t 串的第 j - 1 位“删除”,判断以第 i - 1 位结束的 s 串是否为以 j - 2 位结束的 t 串的子序列,即
dp[i][j] = dp[i][j - 1]
- 综上所述:
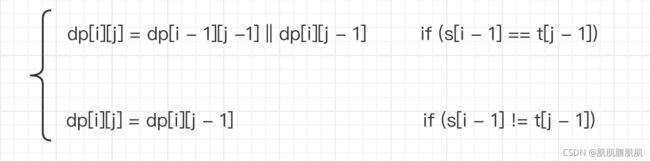
- 初始化
- 从递推公式可以看出
dp[i][j]都是依赖于dp[i - 1][j - 1]和dp[i][j - 1],所以需要对dp[0][0]、dp[i][0]和dp[0][j]是一定要初始化的。而且我们初始化一定要严格按照 dp 数组的定义来:dp[i][j]表示以第 i - 1 位结束的 s 串是否为以 j - 1 位结束的 t 串的子序列。 - 当 j 为 0 时,以 j - 1 位结束的 t 串为空串,而「任何以第 i - 1 位结束的非空 s 串」不可能是「以 j - 1 位结束的 t 串为空串」的子序列,即
dp[i][0] = false (i != 0),而dp[0][0] = true; - 当 i 为 0 时,以 i - 1 位结束的 s 串为空串,该空串是「任何以第 j - 1 位结尾的 t 串」的子序列,即 `dp[0][j] = true。
// 初始化 dp[0][j] = true, dp[i][0] = false
// 由于boolean数组默认就是false,所以d[i][0]不用单独初始化
for (int j = 0; j <= lent; j++) {
dp[0][j] = true;
}
- 确认遍历顺序
- 从递推公式可以看出
dp[i][j]都是依赖于dp[i - 1][j - 1]和dp[i][j - 1],那么遍历顺序也应该是从上到下,从左到右
- 举例推导 dp 数组

- 完整代码如下:
public boolean isSubsequence(String s, String t) {
// 特判
if (s == null || s.length() == 0) return true;
if (t == null || t.length() == 0) return false;
int lens = s.length();
int lent = t.length();
char[] chars = s.toCharArray();
char[] chart = t.toCharArray();
// dp[i][j] 以i-1结尾的s是否是以j-1结尾的t的子序列
boolean[][] dp = new boolean[lens + 1][lent + 1];
// 初始化 dp[0][j] = true, dp[i][0] = false
for (int j = 0; j <= lent; j++) {
dp[0][j] = true;
}
for (int i = 1; i <= lens; i++) {
for (int j = 1; j <= lent; j++) {
// 递推公式两种情况都有 dp[i][j] = dp[i][j - 1],将其提取出来
dp[i][j] = dp[i][j - 1];
if (chars[i - 1] == chart[j - 1]) {
dp[i][j] |= dp[i - 1][j - 1];
}
}
}
return dp[lens][lent];
}
- 其它做法:
- 双指针
- 求 s 和 t 的最长公共子序列,最后判断该最长公共子序列的长度是否与 s 相等
2.2 不同的子序列
LeetCode链接:115. 不同的子序列
给定一个字符串 s 和一个字符串 t ,计算在 s 的子序列中 t 出现的个数。
字符串的一个 子序列 是指,通过删除一些(也可以不删除)字符且不干扰剩余字符相对位置所组成的新字符串。(例如,“ACE” 是 “ABCDE” 的一个子序列,而 “AEC” 不是)
题目数据保证答案符合 32 位带符号整数范围。
示例 1:
输入:s = “rabbbit”, t = “rabbit”
输出:3
解释:
如下图所示, 有 3 种可以从 s 中得到 “rabbit” 的方案。
示例 2:
输入:s = “babgbag”, t = “bag”
输出:5
解释:
如下图所示, 有 5 种可以从 s 中得到 “bag” 的方案。
提示:
0 <= s.length, t.length <= 1000
s 和 t 由英文字母组成


- 思路:本题与392. 判断子序列 比较类似,只不过上一题求“是不是”,而本题求“有多少”。同样的思路,s 和 t 都从空开始,一点点扩展为完整的 s 和 t,在这个扩展的过程中,不断计算并记录“ s 的子序列中 t 出现的个数 ”,最终当 s 和 t 完整时的结果即为所求。按照动归五部曲如下:
- dp 数组和下标的定义
dp[i][j]表示以 i - 1 位结尾的 s 的子序列中出现以 j - 1 位结尾的 t 的子串的次数
// dp[i][j] 以i - 1结尾的s串的子序列中与以j - 1结尾t串相等的个数
int[][] dp = new int[lens + 1][lent + 1];
- 递推公式
- if (s[i - 1] == t[j - 1]):
- 考虑 s 的 i - 1 位:
dp[i][j] = dp[i - 1][j - 1] - 不考虑 s 的 i - 1 位:
dp[i][j] = dp[i - 1][j]
- 考虑 s 的 i - 1 位:
- if (s[i - 1] != t[j - 1]):
- 考虑 s 的 i - 1 位:
dp[i][j] = 0 - 不考虑 s 的 i - 1 位:
dp[i][j] = dp[i - 1][j]
- 考虑 s 的 i - 1 位:
- 综上:

- 初始化
- 从递推公式中可以看出需要初始化
dp[i][0]、dp[0][j]和dp[0][0],并且我们在初始化的时候,一定要“死扣” dp 数组的定义,根据定义来进行初始化!dp[i][j]表示 s[0: i -1] 的子序列中出现 t[0: j - 1] 的次数。 - 当 j 为0时,t[0: j - 1] 表示空,而 s 的任意子数组的子序列中必有一个空数组,所以
dp[i][0] = 1; - 同理当i 为0时,s[0: i -1] 为空,空数组的子序列也位空,不可能包含 t 的子数组,所以
dp[0][j] = 0; - 特殊地,
dp[0][0] = 1
// 初始化 dp[i][0] = 1; dp[0][j] = 0
for (int i = 0; i <= lens; i++) {
dp[i][0] = 1;
}
- 确认遍历顺序
- 从递推公式
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];和dp[i][j] = dp[i - 1][j];中可以看出dp[i][j]都是根据左上方和正上方推出来的。 - 所以遍历的时候一定是从上到下,从左到右,这样保证
dp[i][j]可以根据之前计算出来的数值进行计算。
- 举例推导 dp 数组
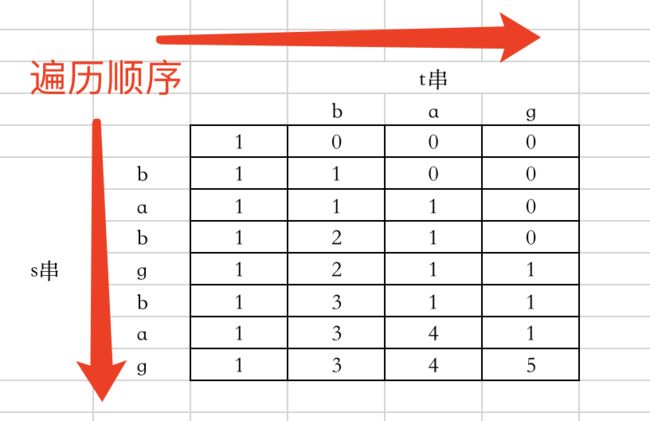
- 代码如下:
public int numDistinct(String s, String t) {
if (s == null || s.length() == 0) return 0;
if (t == null || t.length() == 0) return s.length();
char[] chars = s.toCharArray();
char[] chart = t.toCharArray();
int lens = chars.length;
int lent = chart.length;
// dp[i][j] 以i - 1结尾的s串的子序列中与以j - 1结尾t串相等的个数
// 递推公式:if (s[i - 1] == t[j - 1]) dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j]
// if (s[i - 1] != t[j - 1]) dp[i][j] = dp[i - 1][j]
int[][] dp = new int[lens + 1][lent + 1];
// 初始化 dp[i][0] = 1; dp[0][j] = 0
for (int i = 0; i <= lens; i++) {
dp[i][0] = 1;
}
for (int i = 1; i <= lens; i++) {
for (int j = 1; j <= lent; j++) {
if (chars[i - 1] == chart[j - 1]) {
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
} else {
dp[i][j] = dp[i - 1][j];
}
}
}
return dp[lens][lent];
}
2.3 小结

392. 判断子序列 和 115. 不同的子序列 我们都可以按照上图的思路去做:
- 首先判断两个串中当前位置的元素是否相等,如果相等,再在求子序列的字符串中分为两种情况:考虑该位置的元素、不考虑该位置的元素;
- 如果当前位置不相等,一般在求子序列的字符串中就不考虑该位置的元素,因为即使考虑了,对结果也没有贡献。
2.4 两个字符串的删除操作
LeetCode链接:583. 两个字符串的删除操作
给定两个单词 word1 和 word2,找到使得 word1 和 word2 相同所需的最小步数,每步可以删除任意一个字符串中的一个字符。
示例:
输入: “sea”, “eat”
输出: 2
解释: 第一步将"sea"变为"ea",第二步将"eat"变为"ea"
提示:
给定单词的长度不超过500。
给定单词中的字符只含有小写字母。
- 思路:
- dp 数组及下标定义
dp[i][j]表示以 i - 1 结尾的 word1 与以 j - 1 结尾的 word2 相等的最少删除次数
- 递推公式
- word1[i - 1] == word2[j - 1]:
dp[i][j] = dp[i - 1][j - 1] - word1[i - 1] != word2[j - 1]:
- 删 word1[i - 1],最少操作次数为
dp[i - 1][j] + 1 - 删 word2[j - 1],最少操作次数为
dp[i][j - 1] + 1 - 同时删 word1[i - 1] 和 word2[j - 1],操作的最少次数为
dp[i - 1][j - 1] + 2 - 取上述三种情况中的最小值,所以当 word1[i - 1] != word2[j - 1] 时,
dp[i][j] = min(dp[i - 1][j] + 1, dp[i][j - 1] + 1, dp[i - 1][j - 1] + 2)
- 删 word1[i - 1],最少操作次数为
- 初始化
- 根据递推公式可知需要初始化
dp[i][0]、dp[0][j]和dp[0][0],而且我们初始化的时候一定要遵循 dp 数组的定义来: - 当 i 为0时,word1[0 : i - 1] 表示空数组,如果想让 word2[0 : j - 1] 变成 word1[0 : i - 1] (空数组),则 word2[0 : j - 1] 应该删除 j 步,即
dp[0][j] = j; - 同理,当 j 为0时,word2[0 : j - 1] 表示空数组,如果想让 word1[0 : i - 1] 变成word2[0 : j - 1](空数组),则 word1[0 : i - 1] 应该删除 i 步,即
dp[i][0] = i; - 特殊地,
dp[0][0] = 0
- 确定遍历顺序
-
从递推公式
dp[i][j] = min(dp[i - 1][j] + 1, dp[i][j - 1] + 1, dp[i - 1][j - 1] + 2)和dp[i][j] = dp[i - 1][j - 1]可以看出dp[i][j]都是根据左上方、正上方、正左方推出来的。 -
所以遍历的时候一定是从上到下,从左到右,这样保证
dp[i][j]可以根据之前计算出来的数值进行计算。
- 举例推导 dp 数组
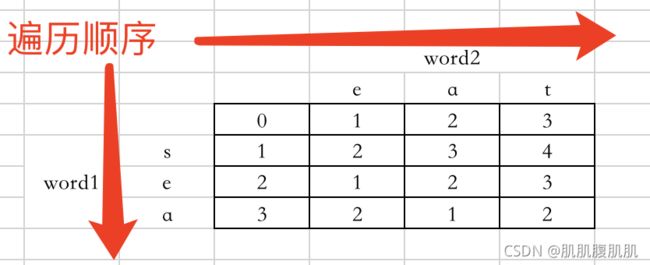
- 代码如下:
public int minDistance(String word1, String word2) {
// 特判
if (word1 == null || word1.length() == 0) return word2.length();
if (word2 == null || word2.length() == 0) return word1.length();
char[] char1 = word1.toCharArray();
char[] char2 = word2.toCharArray();
int len1 = char1.length;
int len2 = char2.length;
// dp[i][j] 使word1[0:i-1]与word2[0:j-1]相等的最少删除次数
int[][] dp = new int[len1 + 1][len2 + 1];
// 递推公式
// if word1[i - 1] == word2[j - 1]: dp[i][j] = dp[i - 1][j - 1]
// if word1[i - 1] != word2[j - 1]: dp[i][j] = min(dp[i - 1][j - 1] + 2, dp[i - 1][j] + 1, dp[i][j - 1] + 1)
// 初始化: dp[i][0] = i; dp[0][j] = j; dp[0][0] = 0
for (int i = 0; i <= len1; i++) dp[i][0] = i;
for (int j = 0; j <= len2; j++) dp[0][j] = j;
for (int i = 1; i <= len1; i++) {
for (int j = 1; j <= len2; j++) {
if (char1[i - 1] == char2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1];
} else {
dp[i][j] = Math.min(dp[i - 1][j - 1] + 2, Math.min(dp[i - 1][j], dp[i][j - 1]) + 1);
}
}
}
return dp[len1][len2];
}
2.5 编辑距离
LeetCode链接: 72. 编辑距离
给你两个单词 word1 和 word2,请你计算出将 word1 转换成 word2 所使用的最少操作数 。
你可以对一个单词进行如下三种操作:
插入一个字符
删除一个字符
替换一个字符
示例 1:
输入:word1 = “horse”, word2 = “ros”
输出:3
解释:
horse -> rorse (将 ‘h’ 替换为 ‘r’)
rorse -> rose (删除 ‘r’)
rose -> ros (删除 ‘e’)
示例 2:
输入:word1 = “intention”, word2 = “execution”
输出:5
解释:
intention -> inention (删除 ‘t’)
inention -> enention (将 ‘i’ 替换为 ‘e’)
enention -> exention (将 ‘n’ 替换为 ‘x’)
exention -> exection (将 ‘n’ 替换为 ‘c’)
exection -> execution (插入 ‘u’)
提示:
0 <= word1.length, word2.length <= 500
word1 和 word2 由小写英文字母组成
- 思路
- dp 数组及下标定义
dp[i][j]表示以 i - 1 位结尾的 word1 转换成以 j - 1 位结尾的 word2 所需要的最少操作步数
- 递推公式
- word1[i - 1] == word2[j - 1]:
dp[i][j] = dp[i - 1][j - 1] - word1[i - 1] != word2[j - 1]:
- 删除 word1 的第 i - 1 位:
dp[i][j] = dp[i - 1][j] + 1,删除 word1 的第 i - 1 位之后我们需要比较的是以 i - 2 位结尾的 word1 与j - 1 位结尾的 word2 相等时所需要的最少操作步数(即dp[i - 1][j]),最后再加上删除的一步的 1; - 替换 word1 的第 i - 1 位,
dp[i][j] = dp[i - 1][j - 1] + 1,替换word1 的第 i - 1 位之后,word1 的第 i - 1 位与 word2 的第 j- 1 位就相等了,此时我们需要比较的是以 i - 2 位结尾的 word1 与j - 2 位结尾的 word2 相等时所需要的最少操作步数(即dp[i - 1][j - 1]),最后再加上替换的这一步的 1; - word1 新增一位:
dp[i][j] = dp[i][j - 1] + 1,word1添加一个元素,相当于word2删除一个元素 - 删除 word2 的第 j - 1 位:
dp[i][j] = dp[i][j - 1] + 1,删除 word2 的第 j - 1 位之后我们需要比较的是以 j - 2 位结尾的 word2 与i - 1 位结尾的 word1 相等时所需要的最少操作步数(即dp[i][j - 1]),最后再加上删除的一步的 1; - 替换 word2 的第 j - 1 位,
dp[i][j] = dp[i - 1][j - 1] + 1,替换word2 的第 j - 1 位之后,word1 的第 i - 1 位与 word2 的第 j- 1 位就相等了,此时我们需要比较的是以 i - 2 位结尾的 word1 与j - 2 位结尾的 word2 相等时所需要的最少操作步数(即dp[i - 1][j - 1]),最后再加上替换的这一步的 1; - word2 新增一位:
dp[i][j] = dp[i - 1][j] + 1,word2添加一个元素,相当于word1删除一个元素
- 删除 word1 的第 i - 1 位:
- 初始化
- 确定遍历顺序
- 举例推导 dp 数组
- 代码如下:
参考
- 代码随想录