MySQL知识点梳理 万字超详解
文章目录
- MySQL
-
- 数据库分类
- SQL分类
- 数据库的基础操作
- 常用数据类型
- 表的操作
- MySQL表的增删查改(基础)
-
- 增加操作
- 查询(Retrieve)
- order by 排序
- 别名
- 去重 distinct
- 条件查询 where
- 分页查询
- 修改update
- 删除 delete
- MySQL增删查改(进阶)
- null约束
- unique唯一约束
- DEFAULT:默认值约束
- PRIMARY KEY:主键约束
- FOREIGN KEY: 外键约束
- CHECK约束(了解)
- 数据库表的设计
-
- 一对一
- 一对多
- 多对多
- 新增
- 聚合查询
-
- 聚合函数
- GROUP BY子句
- HAVING
- 联合查询
-
- 多表查询
- 外连接
- 内连接
- 自连接
- 子连接
- 合并查询
- MySql索引
-
- 概念
- 作用
- 使用场景
- 使用
- MySQL事务
-
- 事务的概念
- 使用
- JDBC编程(重要)
-
- 数据库编程的必备条件
- Java的数据库编程:JDBC
- JDBC工作原理
- **JDBC的使用**
- insert
- update
- delete
- select 有点不一样
MySQL
数据库分类
数据库大体可以分为 关系型数据库 和 非关系型数据库
关系型数据库(RDBMS):
是指采用了关系模型来组织数据的数据库。 简单来说,关系模型指的就是二维表格模型,而一个
关系型数据库就是由二维表及其之间的联系所组成的一个数据组织。
基于标准的SQL,只是内部一些实现有区别。常用的关系型数据库如:
-
Oracle:甲骨文产品,适合大型项目,适用于做复杂的业务逻辑,如ERP、OA等企业信息系
统。收费。 -
MySQL:属于甲骨文,不适合做复杂的业务。开源免费。
-
SQL Server:微软的产品,安装部署在windows server上,适用于中大型项目。收费。
非关系型数据库:
(了解)不规定基于SQL实现。现在更多是指NoSQL数据库,如:- 基于键值对(Key-Value):如 memcached、redis
- 基于文档型:如 mongodb
- 基于列族:如 hbase
- 基于图型:如 neo4j
关系型数据库与非关系型数据库的 区别 :
关系型数据库 非关系型数据库 使用SQL 是 不强制要求,一般不基于SQL实现 事务支持 支持 不支持 复杂操作 支持 不支持 海量读写操作 效率低 效率高 基本结构 基于表和列,结构固定 灵活性比较强 使用场景 业务方面的OLTP系统 用于数据的缓存,或基于统计分析的OLAP系统
SQL分类
-
DDL数据定义语言,用来维护数据的结构
代表指令: create drop,alter
-
DML数据操纵语言,对数据进行操作
代表指令:insert,delete,update;
DML表指令: insert,delete,update
DML中又单独分了一个DQL,数据查询语言,代表指令: select -
DCL数据控制语言,主要负责权限管理和事务
代表指令: grant,revoke,commit
数据库的基础操作
- 数据库的操作:创建数据库、删除数据库
- 常用数据类型
- 表的操作:创建表、删除表
显示当前数据库
show databases;创建数据库
create database test; -- 数据库名字不能跟关键字重复,除非用``来包含起来 `create`这种 -- 如果系统没有 db_test2 的数据库,则创建一个名叫 db_test2 的数据库,如果有则不创建使用数据库
use 数据库名;删除数据库
drop database 数据库名; -- 删除数据库是很谨慎的事,删除之后里面的数据大概率是恢复不过来 -- 数据库删除以后,内部看不到对应的数据库,里边的表和数据全部被删除常用数据类型
整型和浮点型:
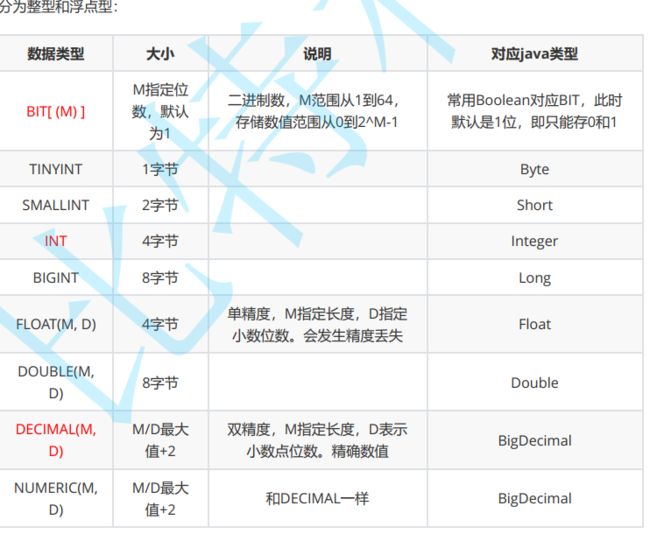
字符串类型:

日期类型:

表的操作
需要操作数据库中的表时,需要先使用该数据库
use 数据库名;
查看表结构
desc 表名;
创建表
-- 首先跟Java不同的是 变量名和类型换了位置 类似于Python和Go
-- 其次注意有些字段的要求:比如double需要在后面声明你的保留几位小数和精度,还有varchar字符型的字符大小设置,一个字符可能是多个字节
create table stu_test (
id int,
name varchar(20) comment '姓名',
password varchar(50) comment '密码',
age int,
sex varchar(1),
birthday timestamp,
amout decimal(13,2),
resume text
);
删除表
drop table 表名;
- 常用数据类型:
INT:整型
DECIMAL(M, D):浮点数类型
VARCHAR(SIZE):字符串类型
TIMESTAMP:日期类型 – 时间戳
插入表
insert into(可加可不加) 表名 values (字段1 ,字段2,字段3) ;
-- 如果想要直插入期中一个或者某一个列的字段 其他值采用默认值
insert into 表名(字段4,字段5) values (字段1 ,字段2,字段3) ;


MySQL表的增删查改(基础)
CRUD :CRUD 即增加(Create)、查询(Retrieve)、更新(Update)、删除(Delete)四个单词的首字母缩写
增加操作
先use database – 使用数据库
然后再去创建表结构
-- 这里跟插入有区别的是: create的时候需要拿括号把所有字段括起来,但是插入是values后面没括号,每插入一列都要扩一次
mysql> CREATE TABLE student (
-> id INT ,
-> sn INT,
-> name VARCHAR(20),
-> qq_mail VARCHAR(20)
-> );
2.1 单行数据 + 全列插入
INSERT INTO student (id, sn, name) VALUES
(102, 20001, '曹孟德'),
(103, 20002, '孙仲谋');
-- 如果想要全列插入 中间括号就不要 ,中间括号就是声明你要插入的列
INSERT INTO student VALUES
查询(Retrieve)
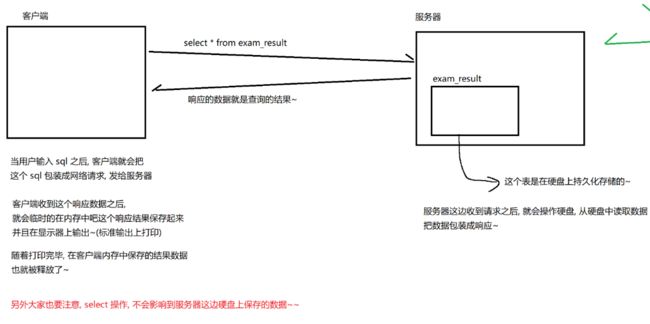
select * from 表名 -- 全列查询
select 字段1 字段2 from 表名 -- 表名查询的显示结果只有这两个字段
查询方式可以配合多个操作进行使用 比如后面的排序等等 但是不能结合去重操作(意思就是 你可以)[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EAfFQOEv-1647608853537)(E:/MarkDown/note.1/image/image-20220307163817602.png)]

而且面对数据量大的服务器,不要使用全列查询,否则会导致服务器瘫痪(数据量过大,传输出了问题)
上图可以,在查询这一系类操作中,我们的数据都是作为临时表来进行显示的,到了后面的update操作,才会修改硬盘上的数据

order by 排序
--排序可以用别名来使用
SELECT name, chinese + english + math as total FROM exam_result order by total
-- ASC 为升序(从小到大)
-- DESC 为降序(从大到小)
-- 默认为 ASC
1. 没有 ORDER BY 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序
2. NULL 数据排序,视为比任何值都小,升序出现在最上面,降序出现在最下面
-- 查询同学姓名和 qq_mail,按 qq_mail 排序显示
SELECT name, qq_mail FROM student ORDER BY qq_mail;
SELECT name, qq_mail FROM student ORDER BY qq_mail DESC;
-- 查询同学及总分,由高到低
SELECT name, chinese + english + math FROM exam_result
ORDER BY chinese + english + math DESC;
SELECT name, chinese + english + math total FROM exam_result
ORDER BY total DESC;
-- 多重排序的意思是,假如第一层排序有相同的数据大小,就按第二层来进行排序
-- 查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示
SELECT name, math, english, chinese FROM exam_result ORDER BY math DESC, english, chinese;
别名
select chinese chinese+math+english as total from 表名 -- as也可以省略
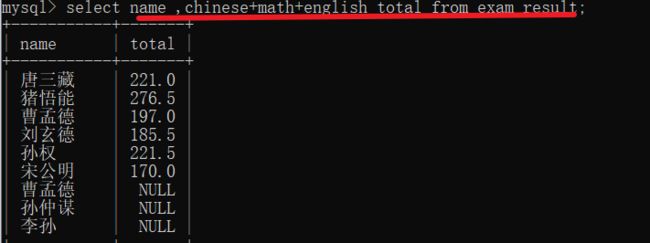
别名也可以结合查询来使用 但是不能用作where条件中
![]()
去重 distinct
select dintinct math from exam_result;
查询方式可以配合多个操作进行使用 比如后面的排序等等 但是不能结合去重操作(意思就是 你可以)[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kpO7jJBw-1647608853539)(E:/MarkDown/note.1/image/image-20220307163817602.png)]
条件查询 where
比较运算符

逻辑运算符
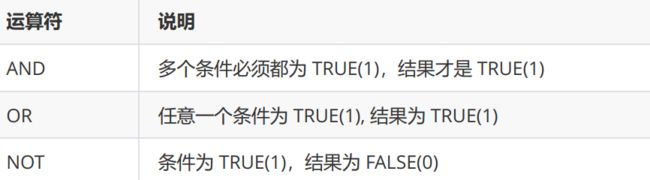
注: 1. WHERE条件可以使用表达式,但不能使用别名。
2. AND的优先级高于OR,在同时使用时,需要使用小括号()包裹优先执行的部分
注1:where 条件在进行查询的时候 回去硬盘里寻找满足条件的数据,那么如果你用了别名,你的别名只是在临时表中进行修改 你硬盘里并没有 ,包括你在使用模糊查询的时候也是不行的

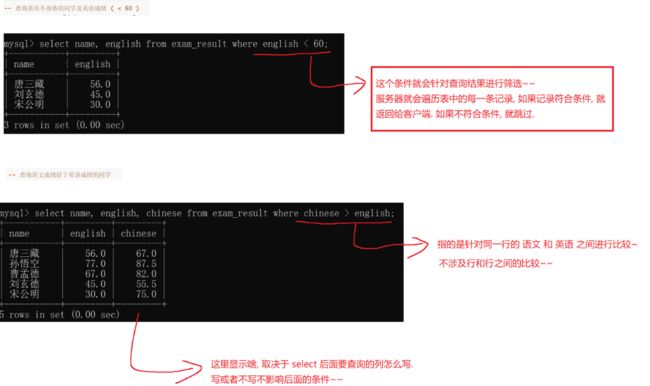
-- 基本查询
-- 查询英语不及格的同学及英语成绩 ( < 60 )
SELECT name, english FROM exam_result WHERE english < 60;
-- 查询语文成绩好于英语成绩的同学
SELECT name, chinese, english FROM exam_result WHERE chinese > english;
-- 查询总分在 200 分以下的同学
SELECT name, chinese + math + english 总分 FROM exam_result
WHERE chinese + math + english < 200;
and 和 or
-- 查询语文成绩大于80分,且英语成绩大于80分的同学
SELECT * FROM exam_result WHERE chinese > 80 and english > 80;
-- 查询语文成绩大于80分,或英语成绩大于80分的同学
SELECT * FROM exam_result WHERE chinese > 80 or english > 80;
-- 观察AND 和 OR 的优先级:
SELECT * FROM exam_result WHERE chinese > 80 or math>70 and english > 70;
SELECT * FROM exam_result WHERE (chinese > 80 or math>70) and english > 70;
-- 范围查询 between and
--编程领域很多时候都是前必又开 但MYSQL这里是都闭的
SELECT name, chinese FROM exam_result WHERE chinese BETWEEN 80 AND 90;
-- 使用 AND 也可以实现
SELECT name, chinese FROM exam_result WHERE chinese >= 80 AND chinese
<= 90;
-- in
-- 查询数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩
SELECT name, math FROM exam_result WHERE math IN (58, 59, 98, 99);
-- 使用 OR 也可以实现
SELECT name, math FROM exam_result WHERE math = 58 OR math = 59 OR math
= 98 OR math = 99;
-- 模糊查询
-- % 匹配任意多个(包括 0 个)字符
SELECT name FROM exam_result WHERE name LIKE '孙%';-- 匹配到孙悟空、孙权
-- _ 匹配严格的一个任意字符
SELECT name FROM exam_result WHERE name LIKE '孙_';-- 匹配到孙权
null 查询
select name from where chinese = null 这种实际上查不出来 因为 = 对于判断null是不安全的,数据库理解的是
null = null 结果还是null 所以被视为false 然后显示Empty set
-- 查询 qq_mail 已知的同学姓名
SELECT name, qq_mail FROM student WHERE qq_mail IS NOT NULL;
-- 查询 qq_mail 未知的同学姓名
SELECT name, qq_mail FROM student WHERE qq_mail IS NULL;
上面的模糊查询 重点说下:


分页查询
-- 根据id来排序 然后offset是从起始位置开始 limit是每一页的数量
--分页查询可以避免了你select * from 表名的这种返回全部数据的危险操作,你可以通过多次分页查询来减少数据量
--limit仍可以搭配order by 等操作来进行搭配
SELECT id, name, math, english, chinese FROM exam_result ORDER BY id LIMIT 3
OFFSET 0;
-- 第 2 页
SELECT id, name, math, english, chinese FROM exam_result ORDER BY id LIMIT 3
OFFSET 3;
-- 第 3 页,如果结果不足 3 个,不会有影响
SELECT id, name, math, english, chinese FROM exam_result ORDER BY id LIMIT 3
OFFSET 6;

修改update
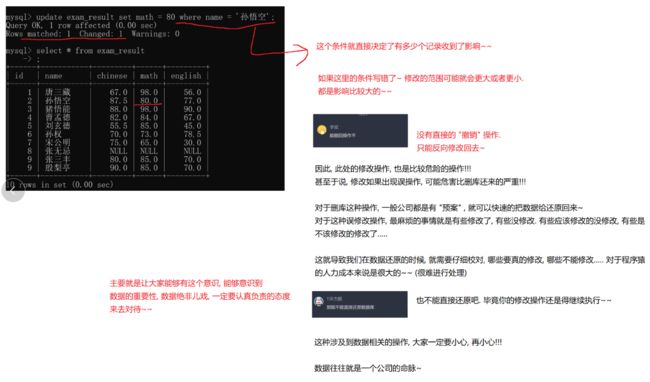
-- 将孙悟空同学的数学成绩变更为 80 分
UPDATE exam_result SET math = 80 WHERE name = '孙悟空';
-- 将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
UPDATE exam_result SET math = 60, chinese = 70 WHERE name = '曹孟德';
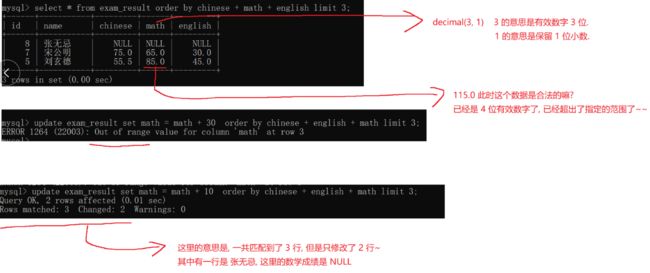
-- 将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
UPDATE exam_result SET math = math + 30 ORDER BY chinese + math + english LIMIT
3;
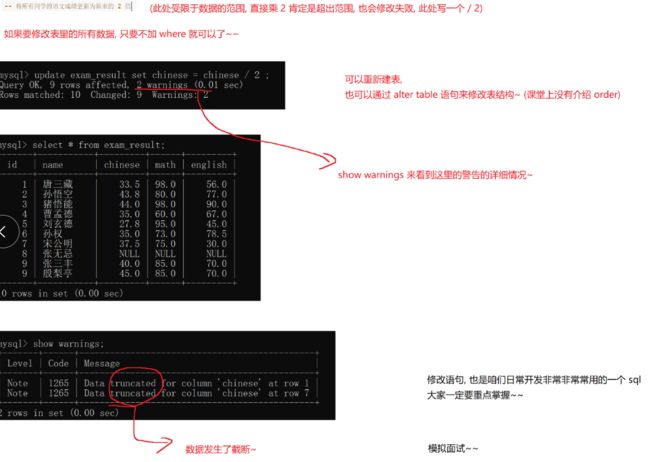
-- 将所有同学的语文成绩更新为原来的 2 倍
UPDATE exam_result SET chinese = chinese * 2;
update操作针对的是数据库硬盘里的数据 并不像上面的select显示的临时表
-- update操作针对的数据修改 如果想要修改字段的名称之类的该如何修改
alter table white_user change column name nick_name varchar(50) null
-- 如果想要修改字段的数据类型 ,也是使用alter table
alter table 表名 modify 字段名 新数据类型 ;

下图有两个注意的点:你update更新数据的时候,浮点数当时对数据进行了限制,此时你超过了限制就报错
还有一个就是null值得是无法与数据类型进行计算 你可以直接修改null
删除 delete
DELETE操作是针对表的数据 ,所以也是针对硬盘的数据来进行的 而不是临时表的删除
-- 删除孙悟空同学的考试成绩
DELETE FROM exam_result WHERE name = '孙悟空';
-- 删除整张表数据
-- 准备测试表
DROP TABLE IF EXISTS for_delete;
CREATE TABLE for_delete (
id INT,
name VARCHAR(20)
);
-- 插入测试数据
INSERT INTO for_delete (name) VALUES ('A'), ('B'), ('C');
-- 删除整表数据
DELETE FROM for_delete;

MySQL增删查改(进阶)
数据库的约束
- NOT NULL - 指示某列不能存储 NULL 值
- UNIQUE - 保证某列的每行必须有唯一的值
- DEFAULT - 规定没有给列赋值时的默认值
- PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标
识,有助于更容易更快速地找到表中的一个特定的记录 - FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性
- CHECK - 保证列中的值符合指定的条件。对于MySQL数据库,对CHECK子句进行分析,但是忽略
CHECK子句
null约束
-- 创建表时制定某列不为空
CREATE TABLE student (
id INT not null,
sn INT,
name VARCHAR(20),
qq_mail VARCHAR(20)
);
unique唯一约束
指定sn为唯一的 ,不重复的
-- 保证某列的每行都必须是惟一的值,否则报错
CREATE TABLE student (
id INT not null,
sn INT,
name VARCHAR(20),
qq_mail VARCHAR(20)
);
DEFAULT:默认值约束
指定插入数据时,name列为空,默认值unkown:
-- 重新设置学生表结构
-- 如果你不设置名字,就会默认是unkown
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT NOT NULL,
sn INT UNIQUE,
name VARCHAR(20) DEFAULT 'unkown',
qq_mail VARCHAR(20)
);
PRIMARY KEY:主键约束
指定id列为主键 – 既不能为空也得唯一
-- 重新设置学生表结构
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT NOT NULL PRIMARY KEY,
sn INT UNIQUE,
name VARCHAR(20) DEFAULT 'unkown',
qq_mail VARCHAR(20)
);
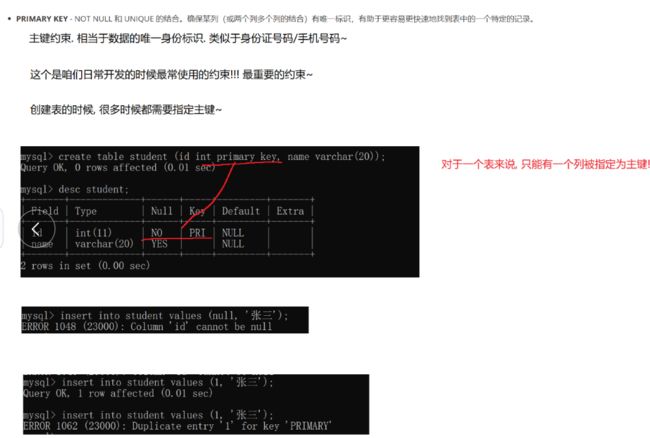

类似于c原因的枚举 :如果你跳跃了100,此时下一个id就是101

FOREIGN KEY: 外键约束
外键用于关联其他表的主键或唯一键,语法
foreign key (字段名) references 主表(列)
案例
- 创建班级表classes,id为主键
-- 创建班级表,有使用MySQL关键字作为字段时,需要使用``来标识
DROP TABLE IF EXISTS classes;
CREATE TABLE classes (
id INT PRIMARY KEY auto_increment,
name VARCHAR(20),
`desc` VARCHAR(100)
)
- 创建学生表student,一个学生对应一个班级,一个班级对应多个学生。使用id为主键,
classes_id为外键,关联班级表id
-- 重新设置学生表结构
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT PRIMARY KEY auto_increment,
sn INT UNIQUE,
name VARCHAR(20) DEFAULT 'unkown',
qq_mail VARCHAR(20),
classes_id int,
--
FOREIGN KEY (classes_id) REFERENCES classes(id)
);

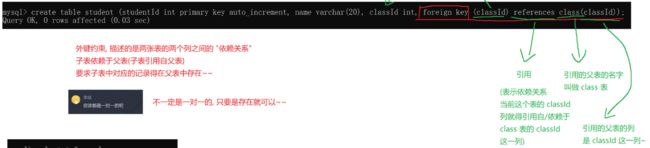
由下图可以看出:当约束形成后,你在学生表中去插入的时候,满足的classid 肯定要在class 表中classid中出现过,否则你的约束没有起作用.
所谓的外键约束:很多人觉得是表和表之间的关系 实际上是两个表中的某条列形成约束关系 导致两张表起了关联

不仅仅是新增数据的时候起了约束作用,你在修改的时候也要保证约束条件 否则也是无法成功的

所以外键约束也对父表进行着约束 ,当你删除父表中的classid 5 但是此时你的子表中存在5班级的学生,那么你父表也不能随意删除.


关于商品表和订单表之间的一个问题

CHECK约束(了解)
drop table if exists test_user;
create table test_user (
id int,
name varchar(20),
sex varchar(1),
check (sex ='男' or sex='女')//类似于枚举
);
数据库表的设计
一般分为三大块
一对一
一对多
多对多


新增
insert into B select * from A;
-- 将从表A中查询到的数据插入到表B中


聚合查询
聚合函数
| 函数 | 说明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
-
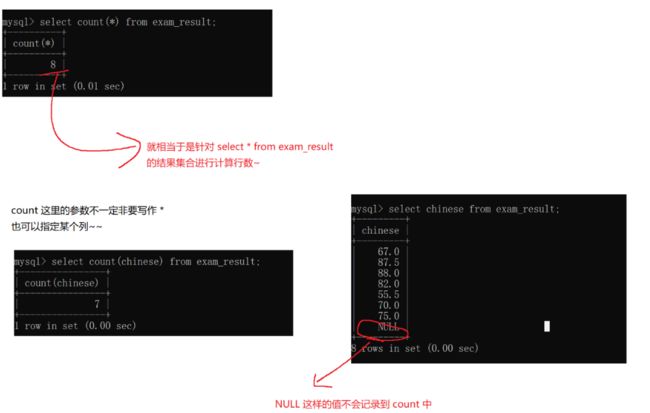
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wsYC2ifc-1647608853542)(E:/MarkDown/note.1/image/image-20220312165141831.png)]
sum里面也可以是表达式:sum(math+chinese+english) – 这加起来是相当于是所有学生的三门科目的总分
-
AVG
-- 统计平均总分 SELECT AVG(chinese + math + english) 平均总分 FROM exam_result; -
MAX
-- 返回英语最高分 SELECT MAX(english) FROM exam_result; -
MIN
-- 返回 > 70 分以上的数学最低分 SELECT MIN(math) FROM exam_result WHERE math > 70;GROUP BY子句
分组操作:根据行的值,对数据进行分组,把值相同的归为一组
演示:
根据角色分组来进行查询
查询每个角色的最高工资、最低工资和平均工资
select role,max(salary),min(salary),avg(salary) from emp group by role;
-- 实际上这条语句是先去执行group by进行分组,分完组之后进行select显示我们的聚合函数

分成每个组之后,就可以根据分组来执行每个组的聚合函数.
HAVING
针对分组之后得到的结果可以通过having来指定条件
GROUP BY 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 WHERE 语句,而需要用
HAVING
group by 是可以使用where的,只不过是where是在分组之前执行,如果要对分组之后的结果进行条件筛选,就需要使用having
-
显示平均工资低于1500的角色和它的平均工资

联合查询
实际开发中往往数据来自不同的表,所以需要多表联合查询。多表查询是对多张表的数据取笛卡尔积

如何在SQL中进行笛卡尔积?
最简单的做法就是直接select from 后面跟多个表名,表名之间用逗号隔开

这个是笛卡尔积的主要操作:因为笛卡尔积大部分的数据是无效的,你需要去筛选出来:很明显可以看出:在学生表里的classId列和班级表中的classId列是相同条件的,通过这个连接关系可以去找到有效数据
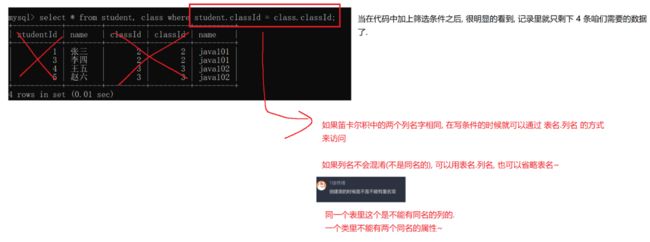
多表查询

接下来进行一些多表查询的操作
-
查询“许仙”同学的 成绩
一般来说:我们事先去思考一下需要的数据在哪?
查询许仙的成绩:肯定是对学生表和成绩表进行笛卡尔积
第一步:select * from student ,score ;
第二步: select score.score from student ,score where student.id = score.student.id – 对笛卡尔积的表进行筛选,得出所有有效的数据
第三步:在去进行一步条件筛选:select score.score from student ,score student.id = score.student.id and student.name = ‘许仙’
select sco.score from student stu, score sco where stu.id=sco.student_id and stu.name='许仙'; -- 或者 select sco.score from student stu join score sco on stu.id=sco.student_id and stu.name='许仙'; 其实第二种也是一种语法,select 列 from 表1, join 表2 on 条件 (这种就是取代了where操作的) -
查询所有同学的总成绩,及同学的个人信息
这个操作是多表查询再加上一个聚合查询
老样子,我们先去对需要的表进行笛卡尔积,然后筛选
select * from student ,score where student.id = score.student_id

然后进行分组(因为你需要的每个同学的总成绩,那么你上面的每一行针对的是一个学生的多门成绩,此时学生id相同,你通过名字进行分组,得到的就是一个人的成绩)
select * from student ,score where student.id = score.student_id group by student.id
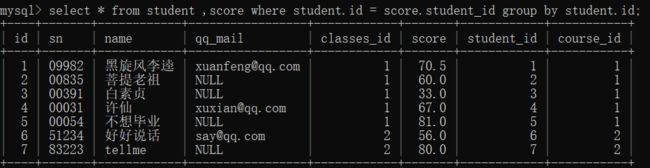
此时显示的只有一列成绩(这一列实际上是course_id为1的课程分数),此时你去通过聚合查询来操作就可以得到每个学生的总成绩了
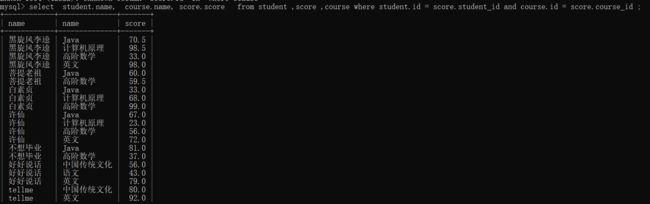
查询所有同学的成绩,及同学的个人信息
这个操作实际上要对三张表进行笛卡尔积(学生的各科成绩,分数,姓名)
select * from student ,score ,course where student.id = score.id and course.id = score.course_id ;
之后呢 对查询的数据进行必要的返回即可
select student.name, coure.name, score.score from student ,score ,course where student.id = score.id and course.id = score.course_id ;
外连接
外连接又分为左外连接和右外连接
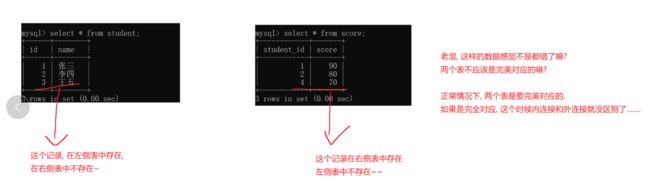
假如你左边是一个学生表,右边是个分数表,你可以发现左边的学生id只有1、2、3而右边的分数表中学生id只有1、2、4
如果是完全对应,也就是左边出现的右边也出现了,右边出现的左边也出现了就是内连接,如果不满足类似于上述
你去操作一下发现:
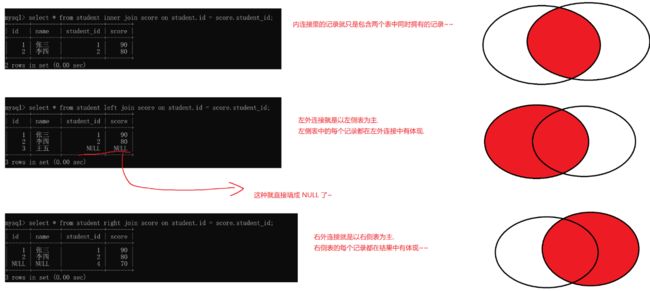
内连接
内连接在上面也描述了,实际上join on 在上面的操作中可以取代where,在这里也是可以去取决于你用哪个连接
select * from 表1 left/right join 表2 on 条件 (左外右外连接区别在于除了公共部分显示外,究竟还要显示左边部分还是右边部分的数据)

自连接
自连接实际上是同一张表连接自身进行查询
案例:此时让你去查询 "计算机原理"成绩比Java成绩高的成绩信息
-
首先你先去查询课程表(知道这两门科目的课程id)
-
然后你去分数表中查询
-
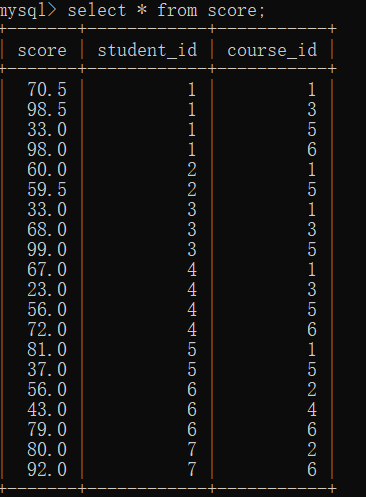
-
很明显的就是:此时你需要比较两门课程的分数,但是这两们课程是行,你无法通过行去比较,所以你需要将它转换成列,那么你想到了笛卡尔积,通过自连接,再去筛选.
-
首先你先去通过student_id去筛选
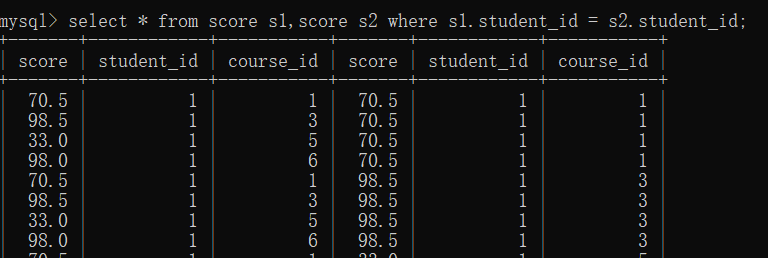
-
其次,你再去规定分数表1只显示课程1 ,分数表2只显示课程3

-
你再去规定 课程3的分数大于课程1的分数

这样一来你就将行的比较转换成列的比较,进而筛选出来了.自连接就是将行的比较转换成列的比较
还有一点记住:自连接由于是同一个表,所以出现相同的表名,你需要改成别名,这样才分辨的清楚.
子连接
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询
select * from student where classes_id=(select classes_id from student where
name='不想毕业');
这种就类似于套娃,在上一个查询的结果中进行查询,比较恶心,不建议使用,最好还是一步一步地来,这种不容易记住
上面的子查询是只有一条查询记录可以用=,但是出现多条查询记录时需要用in

在from子句中使用子查询:子查询语句出现在from子句中。这里要用到数据查询的技巧,把一个
子查询当做一个临时表使用。
查询所有比“中文系2019级3班”平均分高的成绩信息
-- 获取“中文系2019级3班”的平均分,将其看作临时表
SELECT
avg( sco.score ) score
FROM
score sco
JOIN student stu ON sco.student_id = stu.id
JOIN classes cls ON stu.classes_id = cls.id
WHERE
cls.NAME = '中文系2019级3班';
查询成绩表中,比以上临时表平均分高的成绩
SELECT
*
FROM
score sco,
(
SELECT
avg( sco.score ) score
FROM
score sco
JOIN student stu ON sco.student_id = stu.id
JOIN classes cls ON stu.classes_id = cls.id
WHERE
cls.name = "中文系2019级3班"
)
where
sco.score > tmp.score;
合并查询
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all。使用UNION
和UNION ALL时,前后查询的结果集中,字段需要一致
这里的字段一致,其实就是保证你的查询列是对应的,不能前面的select查询2列 后面的select查询三列这样子
-
union
该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行。
案例:查询id小于3,或者名字为“英文”的课程select * from course where id<3 union select * from course where name='英文'; -- 或者使用or来实现 select * from course where id<3 or name='英文'; -
union all
该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。
案例:查询id小于3,或者名字为“Java”的课程-- 可以看到结果集中出现重复数据Java select * from course where id<3 union all select * from course where name='英文';MySql索引
首先明确的是:关于索引和事务在开发工作中用的比较少,但是面试比较爱考.
概念
索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或多列创建索引,
并指定索引的类型,各类索引有各自的数据结构实现
作用
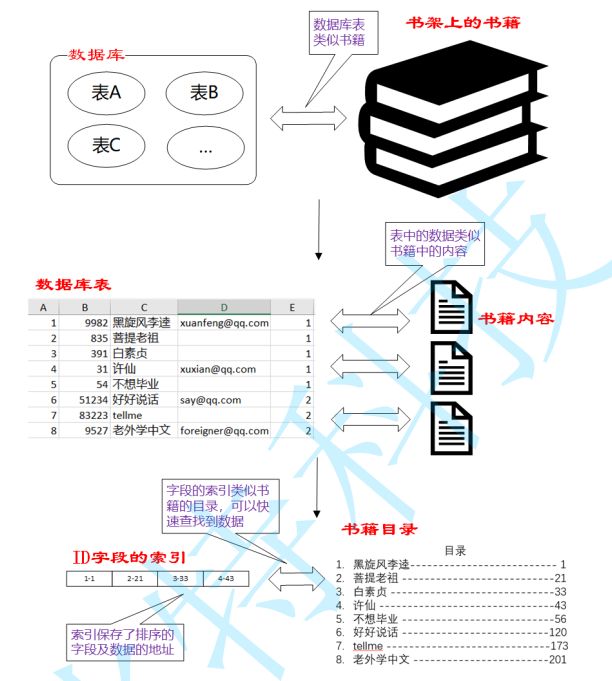
- 数据库中的表、数据、索引之间的关系,类似于书架上的图书、书籍内容和书籍目录的关系。
- 索引所起的作用类似书籍目录,可用于快速定位、检索数据
- 索引对于提高数据库的性能有很大的帮助
使用场景
要考虑对数据库表的某列或某几列创建索引,需要考虑以下几点:
- 数据量较大,且经常对这些列进行条件查询。
- 该数据库表的插入操作,及对这些列的修改操作频率较低。
- 索引会占用额外的磁盘空间
满足以上条件时,考虑对表中的这些字段创建索引,以提高查询效率。
反之,如果非条件查询列,或经常做插入、修改操作,或磁盘空间不足时,不考虑创建索引。
使用
创建主键约束(PRIMARY KEY)、唯一约束(UNIQUE)、外键约束(FOREIGN KEY)时,会自动创建
对应列的索引。

- 查看索引
show index from 表名;
show index from student;
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UApRQ8kD-1647608853545)(E:/MarkDown/note.1/image/image-20220314215930385.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UqA0jhAI-1647608853545)(E:/MarkDown/note.1/image/image-20220314220056062.png)]
上面的介绍说的很明白:
- 创建主键约束、唯一约束、外键约束三种约束会自动创建索引,其余的列你可以自己去手动创建索引
- 其次索引的优缺点,因为索引是针对查询操作来说提高了效率,在处理数据库的时候大部分是进行查询操作,其次当你进行增删改的操作是,索引拖慢了效率,就比如你在书中进行修改内容的时候,你是不是也要对索引进行重新规划呢?
- 所以你在创建索引和删除索引的效率也是极低的,那么你在创建数据库的时候,首先要规划好是否创建索引,不要等到内容都差不多,你再去创建索引,此时就是比较麻烦,包括删除操作也是.
- 创建索引
create index 索引名 on 表名(字段名);
create index idx_classes_name on classes(name);
- 删除索引
drop index 索引名 on 表名;
drop index idx_classes_name on classes;
而在面试中主要考察索引背后的数据结构,对于合适的数据结构可以加快查找的速度.
我们学习的数据结构关于查找:脑海中回想起来的是顺序表、链表、二叉树(二叉搜索树、AL树、红黑树)、堆、hashMap等
- 查找实际上是按照" 查找值"来来进行查找的,不是根据下标进行的 ,顺序表pass
为啥顺序表按照下标的访问的速度就快呢? => 顺序表是在连续的内存空间上 => 内存支持随机访问 (访问任意地址上的数据,速度都是极快的)
- 二叉搜索树 查找的时间复杂度是 ? 不是O(logN) ,O(logN)是正常情况下,但是当你的树是一颗单分支的数,时间复杂度达到O(N),那么我们一般谈论时间复杂度是最差的情况,此时时间复杂度比较大,不太适合作为mysql的索引底层.

实际上我们还是要二叉搜索树,只不过就是让这个二叉搜索树不要变成单分支即可.
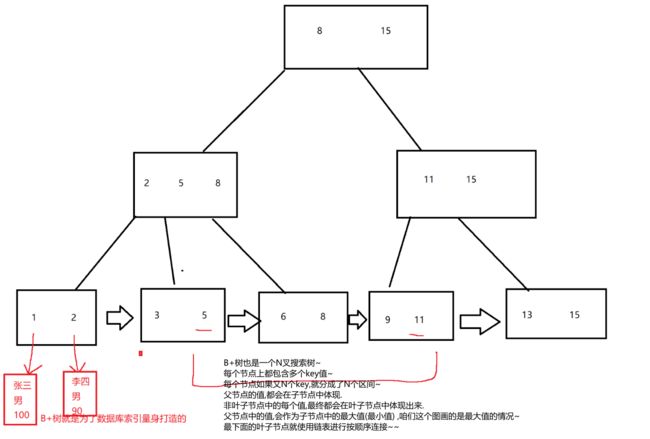
.最适合做索引的,还是树形结构 只不过就不再是二叉树 ,在此处我们使用多叉搜索树 高度就下来了
在数据库中使用这个多叉搜索树,叫做B+ 树,(这个是数据库索引中最常见的数据结构)
数据库有很多种,每个数据库底层又支持多种存储引擎(实现了数据具体按照啥结构来存储的程序)
每个存储引擎存储数据的结构可能都不一样,背后的索引数据结构可能也不同~~
理解B+ 树 先去理解它的前身 B- 树
 \
\
B+ 树:
MySQL事务
为什么要使用事务???

准备测试表
drop table if exists accout;
create table accout(
id int primary key auto_increment,
name varchar(20) comment '账户名称',
money decimal(11,2) comment '金额'
);
insert into accout(name, money) values
('阿里巴巴', 5000),
('四十大盗', 1000);
比如说,四十大盗把从阿里巴巴的账户上偷盗了2000元
-- 阿里巴巴账户少2000
update accout set money=money-2000 where name = '阿里巴巴';
-- 四十大盗账户增加2000
update accout set money=money+2000 where name = '四十大盗';
假如在执行以上第一句SQL时,出现网络错误,或是数据库挂掉了,阿里巴巴的账户会减少2000,但是
四十大盗的账户上就没有了增加的金额。
解决方案:使用事务来控制,保证以上两句SQL要么全部执行成功,要么全部执行失败
事务的概念
事务指逻辑上的一组操作,组成这组操作的各个单元,要么全部成功,要么全部失败。
在不同的环境中,都可以有事务。对应在数据库中,就是数据库事务
使用
1)开启事务:start transaction;
2)执行多条SQL语句;
(3)回滚或提交:rollback/commit;
说明:rollback即是全部失败,commit即是全部成功。
start transaction;
-- 阿里巴巴账户减少2000
update accout set money=money-2000 where name = '阿里巴巴';
-- 四十大盗账户增加2000
update accout set money=money+2000 where name = '四十大盗';
commit;


事务相关的面试题
谈谈事务的四个基本特性:
- 原子性~
- 一致性 ~ 在事务执行之前和执行之后 数据库中的数据都是合理合法的~ ,例如你转账完了不能出现账户为负数这种情况
- 持久性 ~ 事务一旦提交之后,数据就能持久化保存起来了 ~~ 数据就写入到硬盘中
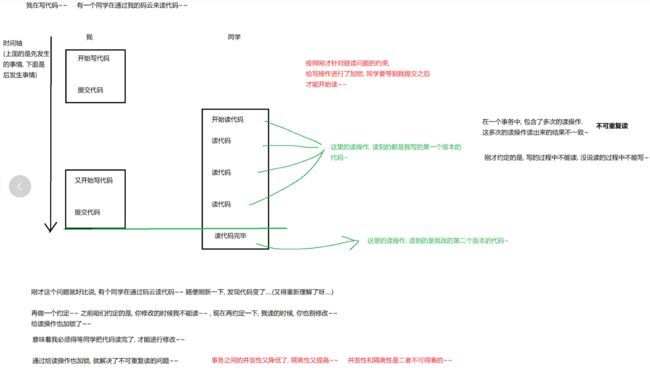
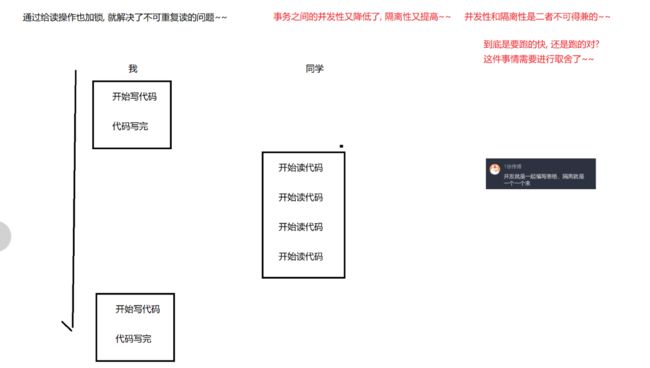
- 隔离性 ~ (不好弄) 跟并发是互相矛盾的 描述的是事务并发执行的时候产生的情况
当并发执行多个事务,尤其是这多个事务在尝试修改/读取同一份数据,这个时候就容易出现一些问题 ,而事物的隔离性就在解决上述问题~~~
隔离性和并发性的介绍

- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jq6eMgL7-1647608853548)(E:/MarkDown/note.1/image/image-20220314234905075.png)]
总结:



JDBC编程(重要)
数据库编程的必备条件
- 编程语言,如Java,C、C++、Python等
- 数据库,如Oracle,MySQL,SQL Server等
- 数据库驱动包:不同的数据库,对应不同的编程语言提供了不同的数据库驱动包,如:MySQL提
供了Java的驱动包mysql-connector-java,需要基于Java操作MySQL即需要该驱动包。同样的,
要基于Java操作Oracle数据库则需要Oracle的数据库驱动包ojdbc
Java的数据库编程:JDBC
JDBC,即Java Database Connectivity,java数据库连接。是一种用于执行SQL语句的Java API,它是
Java中的数据库连接规范。这个API由 java.sql.,javax.sql. 包中的一些类和接口组成,它为Java
开发人员操作数据库提供了一个标准的API,可以为多种关系数据库提供统一访问
JAVA中的JDBC对接各种数据库的sql语句,因为每个版本的数据库都有自己的一套api(mysqo,sql sever oracle等等),
关于api的统一接口没有明确规定.但是在Java中,规定了JDBC为统一api去对接各个版本的数据库api,便于实现数据库编程.
JDBC编程需要用到mysql的驱动包,(驱动包就是将mysql自身的api’转换成java风格的) 驱动包也是mysql官方提供的
所以在实现数据库编程的前提是:你需要在项目中导入对应的jar包 便于我们去操作.
JDBC工作原理
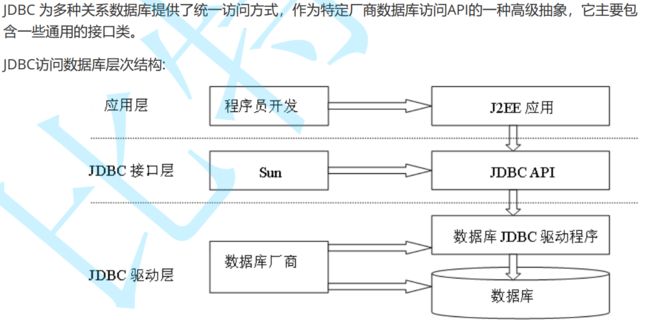
JDBC优势 :
- Java语言访问数据库操作完全面向抽象接口编程
- 开发数据库应用不用限定在特定数据库厂商的API
- 程序的可移植性大大增强
JDBC的使用
准备数据库驱动包,并添加到项目的依赖中:
在项目中创建文件夹lib,并将依赖包mysql-connector-java-5.1.47.jar复制到lib中。右键lib目录,点击add aslibrary这个选项(手动导入)
点击这个选项,才能把这个jar包引入到项目中,此时项目才会从jar包中读取内部的class 等 ,否则代码就找不到jar中一些类了
接下来就用代码截图来说明JDBC的使用,主要就是增删改查四个操作
insert
public static void main(String[] args) throws SQLException {
Scanner scanner = new Scanner(System.in);
//创建好数据源
DataSource dataSource = new MysqlDataSource();//向上转型
//设置数据库所在的地址
//下面这其实是向下转型
((MysqlDataSource) dataSource ).setURL("jdbc:mysql://127.0.0.1:3306/emp?characterEncoding=utf8&useSSL=false");
//设置数据库的用户名
((MysqlDataSource) dataSource ).setUser("root");
//设置数据库的密码
((MysqlDataSource) dataSource ).setPassword("123456");
Connection connection = dataSource.getConnection();
//2.5让用户通过控制台来输入一下带插入的数据
System.out.println("请输入学号");
int id = scanner.nextInt();
System.out.println("请输入姓名");
String name = scanner.next();
//我们先写一个字符串类型的SQL语句,完了之后需要把这个字符串类型SQL语句转换成一个语句对象
//将SQL语句包装成一个语句对象,返回值是一个对象,你使用这个对象的方法去进行执行
String sql = "insert into student values(?,?)";
PreparedStatement statement = connection.prepareStatement(sql);
//进行替换操作
statement.setInt(1,id);
statement.setString(2,name);
System.out.println("statement "+ statement);
//上面说了,语句对象返回的对象用PrepareStatement类型对象接收,然后这个类里面的execuUpdate方法会执行转化的SQL语句
//执行完之后返回值是一个整数,表示返回影响了几行
int ret = statement.executeUpdate();
System.out.println(ret);
//在关闭资源上千万不要忘记,而且注意关闭的顺序,正所谓先开的大门后关上,资源的先后打开也是如此
statement.close();
connection.close();
在代码中有一串代码很重要
System.out.println("statement "+ statement);
他会帮助我们打印一串信息
![]()
这串信息,就是你在执行这条语句之前,你可以去检查你输入的数据是否对得上号 也可以作为一个分辨报错方向的标志,如果没有打印出来说明你在前面的代码中就出了问题.
update
public static void main(String[] args) throws SQLException {
Scanner scanner = new Scanner(System.in);
DataSource dataSource = new MysqlDataSource();
//设置数据库地址
((MysqlDataSource) dataSource).setURL("jdbc:mysql://127.0.0.1:3306/emp?characterEncoding=utf8&useSSL=false");
//设置数据库的用户名
((MysqlDataSource) dataSource).setUser("root");
//设置数据库的密码
((MysqlDataSource) dataSource).setPassword("123456");
//让代码和数据库服务器建立连接,相当于到达了菜鸟驿站
Connection connection = dataSource.getConnection();
System.out.println("请输入要更新的学号");
int id = scanner.nextInt();
System.out.println("请输入要更新的名字");
String name = scanner.next();
//此时也只开始写sql语句,然后㢥Preparedstatement 将字符串转换成一个语句对象,
String sql = "update student set name = ? where id = ? ";
PreparedStatement statement = connection.prepareStatement(sql);
statement.setString(1,name);
statement.setInt(2,id);
System.out.println("statement " + statement);
//执行executeUpdate
int ret = statement.executeUpdate();
System.out.println(ret);
//释放资源
connection.close();
statement.close();
}
delete
public static void main(String[] args) throws SQLException {
//建立数据源
DataSource dataSource = new MysqlDataSource();
//设置数据库地址\用户名\密码
((MysqlDataSource) dataSource ).setURL("jdbc:mysql://127.0.0.1:3306/emp?characterEncoding=utf8&useSSL=false");
((MysqlDataSource) dataSource ).setUser("root");
((MysqlDataSource) dataSource ).setPassword("123456");
Scanner scanner = new Scanner(System.in);
//开始让代码与数据库服务器进行连接
//dataSource的getConnection方法,就是获取连接,
Connection connection = dataSource.getConnection();
System.out.println("请输入要删除的id :");
int id = scanner.nextInt();
//转换完语句对象
String sql = "delete from student where id = ? ";
PreparedStatement statement = connection.prepareStatement(sql);
statement.setInt(1,id);
System.out.println("statement "+ statement);
//执行SQL语句
int ret = statement.executeUpdate();
System.out.println(ret);
statement.close();
connection.close();
}
select 有点不一样
public static void main(String[] args) throws SQLException {
DataSource dataSource = new MysqlDataSource();//向上转型
//设置数据库所在的地址
((MysqlDataSource) dataSource ).setURL("jdbc:mysql://127.0.0.1:3306/emp?characterEncoding=utf8&useSSL=false");
//设置数据库的用户名
((MysqlDataSource) dataSource ).setUser("root");
//设置数据库的密码
((MysqlDataSource) dataSource ).setPassword("123456");
Connection connection = dataSource.getConnection();
//3.拼装sql
String sql = "select * from student";
PreparedStatement statement = connection.prepareStatement(sql);
//4.执行sql,对于查询操作,就需要使用executeQuery了
//查询操作返回的是不是一个int了,而是一个临时表
//使用ResultSet表示这个表
ResultSet resultSet = statement.executeQuery();
//5.遍历结果集合(返回的临时表) 先获取一行,在获取这一行中的若干列
//next 方法表示获取到一行记录,同时把光标往后移动一行
//如果遍历到表的结束为止,此处的next 就直接返回false;
while(resultSet.next()){
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
System.out.println("id :"+ id + " ," + "name :"+ name);
}
resultSet.close();
connection.close();
statement.close();
}
类似于这种报错就是数据库连接失败,那么出了问题也就是在
Connection connection = dataSource.getConnection(); 这一串或者上面出了问题

获取连接失败了~~
1.数据库的地址不对
2.端口号不对
3.数据库名不对
4.用户名不对5.密码不对
6.其他的情况~
关于MySQL数据库的内容重点就是这些, 核心知识还是在于前期学习的SQL语句,而在语句中,查询语句又是最复杂的.
当然在面试过程中,面试官问的比较多的还是索引和事务两个方面.那么在编程方面,JDBC编程用的比较多,因为在做一些项目的过程中,肯定也是需要一些表的.
ows SQLException {
DataSource dataSource = new MysqlDataSource();//向上转型
//设置数据库所在的地址
((MysqlDataSource) dataSource ).setURL(“jdbc:mysql://127.0.0.1:3306/emp?characterEncoding=utf8&useSSL=false”);
//设置数据库的用户名
((MysqlDataSource) dataSource ).setUser(“root”);
//设置数据库的密码
((MysqlDataSource) dataSource ).setPassword(“123456”);
Connection connection = dataSource.getConnection();
//3.拼装sql
String sql = "select * from student";
PreparedStatement statement = connection.prepareStatement(sql);
//4.执行sql,对于查询操作,就需要使用executeQuery了
//查询操作返回的是不是一个int了,而是一个临时表
//使用ResultSet表示这个表
ResultSet resultSet = statement.executeQuery();
//5.遍历结果集合(返回的临时表) 先获取一行,在获取这一行中的若干列
//next 方法表示获取到一行记录,同时把光标往后移动一行
//如果遍历到表的结束为止,此处的next 就直接返回false;
while(resultSet.next()){
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
System.out.println("id :"+ id + " ," + "name :"+ name);
}
resultSet.close();
connection.close();
statement.close();
}
类似于这种报错就是数据库连接失败,那么出了问题也就是在
Connection connection = dataSource.getConnection(); 这一串或者上面出了问题
[外链图片转存中...(img-UbHTbhSC-1647608853550)]
获取连接失败了~~
1.数据库的地址不对
2.端口号不对
3.数据库名不对
4.用户名不对5.密码不对
6.其他的情况~
**关于MySQL数据库的内容重点就是这些, 核心知识还是在于前期学习的SQL语句,而在语句中,查询语句又是最复杂的.**
**当然在面试过程中,面试官问的比较多的还是索引和事务两个方面.那么在编程方面,JDBC编程用的比较多,因为在做一些项目的过程中,肯定也是需要一些表的.**