PyTorch 学习笔记 5 —— 实现手写数字识别 LeNet-5
1. MNIST
MNIST 数据集是一个包含了 50000 个训练数据,10000个测试数据的手写数字数据集,每张手写数字图像大小为为 28 × 28 28 \times 28 28×28,包含 10 个类别。
2. LeNet5
LeNet5 由 LeCun 等人在论文 Gradient-based learning applied to document recognition 中提出,其模型架构图如下:
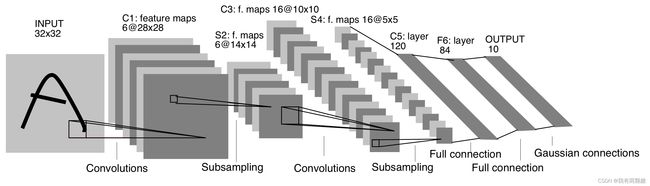
关于模型的解读可以参考论文原文或者博客 LeNet5 深入分析,但从现在的角度回顾这篇文章,会发现作者在设计模型时有点过于复杂了,现在常用的 LeNet5 是简化且效果更好的模型,但作者在设计模型时的一些设计理念将一直影响着深度学习的发展
改进的 LeNet5 模型如下:

特点:先用卷积层来学习图片的空间信息,再用全连接层来转换到类别空间
3. LeNet5 的 PyTorch 实现
3.1 Model
首先构建模型框架(可以将模型放到 model.py 文件中):
import torch
from torch import nn
class Reshape(nn.Module):
def forward(self, x):
return x.view(-1, 1, 28, 28)
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
self.net = nn.Sequential(
Reshape(),
# CONV1, ReLU1, POOL1
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2),
# nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
# CONV2, ReLU2, POOL2
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Flatten(),
# FC1
nn.Linear(in_features=16 * 5 * 5, out_features=120),
nn.ReLU(),
# FC2
nn.Linear(in_features=120, out_features=84),
nn.ReLU(),
# FC3
nn.Linear(in_features=84, out_features=10)
)
def forward(self, x):
logits = self.net(x)
return logits
为了使用 Sequential,代码中自定义了一个 Reshape 模块,将图片 resize 一下
3.2 检查模型
LetNet5 模型比较简单,接着检查一下模型(在 model.py 中加入下面代码)
随机创建一个 batch 大小为 5,channel = 1,image size 为 32 × 32 32 \times 32 32×32 的 batch 作为模型的输入:
if __name__ == '__main__':
model = LeNet5()
X = torch.rand(size=(256, 1, 28, 28), dtype=torch.float32)
for layer in model.net:
X = layer(X)
print(layer.__class__.__name__, '\toutput shape: \t', X.shape)
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
print(model(X))
输出结果如下:
Reshape output shape: torch.Size([256, 1, 32, 32])
Conv2d output shape: torch.Size([256, 6, 28, 28])
ReLU output shape: torch.Size([256, 6, 28, 28])
MaxPool2d output shape: torch.Size([256, 6, 14, 14])
Conv2d output shape: torch.Size([256, 16, 10, 10])
ReLU output shape: torch.Size([256, 16, 10, 10])
MaxPool2d output shape: torch.Size([256, 16, 5, 5])
Flatten output shape: torch.Size([256, 400])
Linear output shape: torch.Size([256, 120])
ReLU output shape: torch.Size([256, 120])
Linear output shape: torch.Size([256, 84])
ReLU output shape: torch.Size([256, 84])
Linear output shape: torch.Size([256, 10])
每一层的输出的 shape 与预期输出的 shape 一致,从输入到输出,层大小逐渐变小,通道逐渐变多,能够提取更多的模式。
4. 读取数据
下面的读取数据、训练模型的代码写如到新的文件 train.py
首先导入需要的模块:
import torch
from torch import nn
from torchvision import datasets
from torchvision.transforms import ToTensor
from torch.utils.data import DataLoader
from model import LeNet5
使用 datasets.MNIST() 下载数据到本地,并使用 DataLoader 加载数据:
# DATASET
train_data = datasets.MNIST(
root='./data',
train=False,
download=True,
transform=ToTensor()
)
test_data = datasets.MNIST(
root='./data',
train=False,
download=True,
transform=ToTensor()
)
# PREPROCESS
batch_size = 256
train_dataloader = DataLoader(dataset=train_data, batch_size=batch_size)
test_dataloader = DataLoader(dataset=test_data, batch_size=batch_size)
for X, y in train_dataloader:
print(X.shape) # torch.Size([256, 1, 28, 28])
print(y.shape) # torch.Size([256])
break
可以得到每个 batch 大小为 256,batch 中图像为单通道图像,大小为 28 × 28 28 \times 28 28×28, 但论文里面输入数据是 32 × 32 32 \times 32 32×32, 这也是我们在第一个 CONV 中设置 padding=2 的原因
5. 训练模型
为了使用 GPU,首先设置模型和数据的 device:
# MODEL
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = LeNet5().to(device)
接着常规操作,先定义损失函数,优化方法选择 Adam,设置train mode,再将数据放到 device,预测模型输出,计算损失,误差反向传播,参数更新 … \dots …
最后打印一下当前的 epoch 和 loss 值:
# TRAIN MODEL
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(params=model.parameters())
def train(dataloader, model, loss_func, optimizer, epoch):
model.train()
data_size = len(dataloader.dataset)
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device)
y_hat = model(X)
loss = loss_func(y_hat, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss, current = loss.item(), batch * len(X)
print(f'EPOCH{epoch+1}\tloss: {loss:>7f}', end='\t')
为了打印模型每次扫描完所有训练数据后模型在测试集上的准确率,增加测试的函数:
# Test model
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f'Test Error: Accuracy: {(100 * correct):>0.1f}%, Average loss: {test_loss:>8f}\n')
训练模型,实时打印训练效果,最后将模型保存为 model.pth 文件:
if __name__ == '__main__':
epoches = 20
for epoch in range(epoches):
train(train_dataloader, model, loss_func, optimizer, epoch)
test(test_dataloader, model, loss_func)
# Save models
torch.save(model.state_dict(), 'model.pth')
print('Saved PyTorch LeNet5 State to model.pth')
可以得到下面的输出:
EPOCH1 loss: 0.736027 Test Error: Accuracy: 68.5%, Average loss: 0.942332
EPOCH2 loss: 0.298749 Test Error: Accuracy: 83.3%, Average loss: 0.532160
EPOCH3 loss: 0.162936 Test Error: Accuracy: 89.4%, Average loss: 0.349719
EPOCH4 loss: 0.082190 Test Error: Accuracy: 90.9%, Average loss: 0.287907
EPOCH5 loss: 0.046385 Test Error: Accuracy: 92.2%, Average loss: 0.242192
...
EPOCH30 loss: 0.000041 Test Error: Accuracy: 98.8%, Average loss: 0.032203
模型训练成功,在测试集上的准确率为98.8%,最后训练得到的模型被保存在当前工作目录下
6. 使用训练好的模型
首先创建测试数据,在平板上写2个数字 2 和 8,截图后保存到 ./images 中:
接着创建程序 test.py,首先导入模块:
import torch
import cv2 as cv
from model import LeNet5
from matplotlib import pyplot as plt
接着加载模型,读取图片,转换为灰度图,改变大小,设置背景黑色,最后送到模型训练(注意 torch.no_grad()):
if __name__ == '__main__':
# Loading models
model = LeNet5()
model.load_state_dict(torch.load('./model.pth'))
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model.to(device)
# READ IMAGE
img = cv.imread('./images/2.jpg')
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
gray = 255 - cv.resize(gray, (28, 28), interpolation=cv.INTER_LINEAR)
X = torch.Tensor(gray.reshape(1, 28, 28).tolist())
X = X.to(device)
with torch.no_grad():
pred = model(X)
print(pred[0].argmax(0))
print(pred)
结果为 2:
tensor(2, device='cuda:0')
tensor([[ -386.6740, 2782.1257, 6817.6094, -896.5799, -6282.5933, -4064.7393,
-3018.1729, 665.6072, 1284.2777, -4511.3682]], device='cuda:0')
如果预测含有数字 8 的图输出也是 8,数字为输出的一组向量中数值最大的那一项对应的下标!
为了得到概率,可以这样修改 model
# 添加softmax层
self.softmax = nn.Softmax()
def forward(self, x):
logits = self.net(x)
# 将logits转为概率
prob = self.softmax(logits)
return prob
重新训练,测试可以得到概率:
tensor([[0., 0., 1., 0., 0., 0., 0., 0., 0., 0.]], device='cuda:0')
REFERENCE: 李沐深度学习 —— LeNet