实时分析之客户画像项目实践
客户画像的背景描述
原来的互联网,以解决用户需求为目的,衍生出众多的网联网产品,以及产生呈数量级递增的海量数据。当用户需求基本得到满足的时候,需要分析这些海量的数据,得以达到最高效的需求实现,最智能的功能服务,以及最精准的产品推荐,最后提升产品的竞争力。简言之,产品由原来的需求驱动转换成数据驱动。
客户画像就是数据驱动的代表作之一。具体点讲,客户画像就是用户的标签(使用该产品的群体),程序能自动调整、组合、生成这些标签,最后再通过这些标签,达到精准营销的目的。
当前流行的实时分析框架
首先一提到大数据,大家脑海中浮现的肯定是Hadoop,但是需要实时分析出结果的话,那Hadoop就力不从心了(先不讲数据多少,单单启动一个M/R就要几分钟的时间),如果没有实时性需求的产品分析则另当别论。
当下最流行的三大实时分析框架分别是Apache Spark,Apache Samza,Apache Storm。下面是网上找到的三大框架的说明和对比:
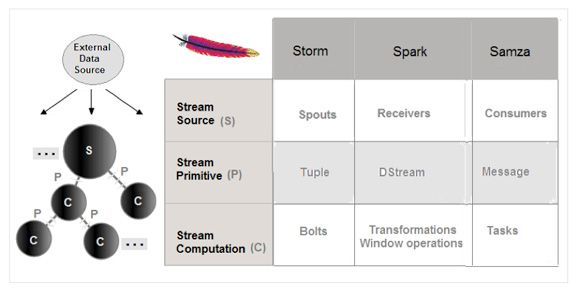
三者的整体框架相似,只是各个节点的名字和术语不一样罢了
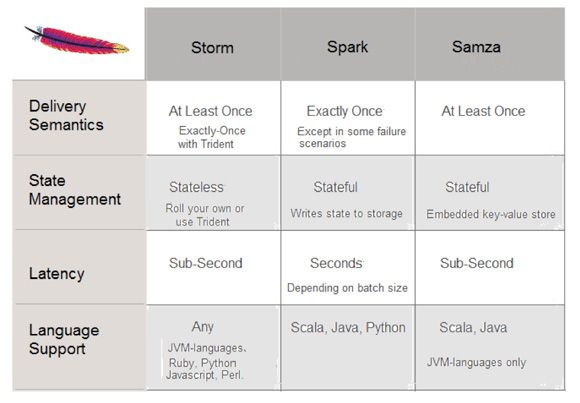
Storm和Samza在消息发送处理的机制上是至少一次,而Spark是有且仅此一次,换句话讲,Storm和Samza可能存在重复发送数据的情况;在消息处理上,Spark是秒级的,而Storm和Samza是压秒级的(性能都不错,压秒级的也还是可以接受^_^);在语言支持上,这个Storm貌似多点。另外,Storm开源的也比较早,社区比较活跃,版本迭代的比较快,文档相对来说也比较多,Storm相对Spark也比较轻量级,上手简单,这就是作者选择Storm的原因,不过个人还是推荐Spark的。
环境准备、搭建和运行
下面是作者使用的软件版本
1. kafka2.11
2. zookeeper3.5.1
3. storm0.9.5JDK的环境,这个都不明白的人也不用继续看下去了。
作者在测试环境准备了4台虚拟机,修改每台虚拟机的/etc/hosts
172.16.2.235 master
172.16.2.231 slave1
172.16.2.236 slave2
172.16.2.241 slave3235是主节点,其余三个是子节点,在主节点做好子节点免登录权限设置
主机运行
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
mv id_dsa.pub authorized_keys
chmod 600 authorized_keys
scp ~/.ssh/authorized_keys root@slave1:/root/.ssh/
scp ~/.ssh/authorized_keys root@slave2:/root/.ssh/
scp ~/.ssh/authorized_keys root@slave3:/root/.ssh/(拷贝到各个从机上去)
每个从机都ssh进入一次 记录从机信息
- zookeeper
zookeeper是大数据必备的框架之一,它是一个分布式的,开放源码的分布式应用程序协调服务,你可以理解成每个子节点的任务控制中心
解压
tar -zxvf zookeeper-3.5.1-alpha.tar.gz配置
conf/zoo.cfg
initLimit=10
syncLimit=5
clientPort=2181
tickTime=2000
autopurge.purgeInterval=12
autopurge.snapRetainCount=3
dataDir=/home/zookeeper-3.5.1-alpha/data
server.0=master:2888:3888
server.1=slave1:2888:3888
server.2=slave2:2888:3888
server.3=slave3:2888:3888注意:需要在/home/zookeeper-3.5.1-alpha/data目录下创建一个myid文件,写入该机的序列号,虚拟机就1,2累加下去
echo 0 >> /home/zookeeper-3.5.1-alpha/data/myid启动
/home/zookeeper-3.5.1-alpha/bin/zkServer.sh start &jps一下,列表中出现QuorumPeerMain进程则代表启动OK(各个子节点也启动起来,下面的服务都依赖zookeeper)。
- kafka
kafka,中文名叫卡夫卡,是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。简言之,就是数据采集、发送器。
解压
tar -zxvf kafka_2.11-0.8.2.0.tgz配置,修改
config/server.properties
broker.id=0
port=9092
num.network.threads=3
num.io.threads=8
host.name=master
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/home/kafka_2.11-0.8.2.0/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
log.cleaner.enable=false
zookeeper.connect=master:2181,slave1:2181,slave2:2181,slave3:2181
zookeeper.connection.timeout.ms=6000
#真正删除topic
delete.topic.enable=true注意:这里的broker.id在各个子节点也不能重复
启动
/home/kafka_2.11-0.8.2.0/bin/kafka-server-start.sh /home/kafka_2.11-0.8.2.0/config/server.properties &jps一下,列表中出现Kafka进程则代表启动OK。
验证kafka集群运行是否正常:
订阅日志
在log服务器上安装kafka,只解压就好了,不需要配置,然后订阅log
tail -0f /home/bigdata/logs/analytics.log | /home/kafka_2.11-0.8.2.0/bin/kafka-console-producer.sh --broker-list master:9092,slave1:9092,slave2:9092,slave3:9092 --topic bigdata_app_logs &将最新一行的日志文件传输到kafka集群,消息队列叫做bigdata_app_logs(这个ID在kafka集群中唯一)
再查询队列列表
./kafka-topics.sh --list --zookeeper master:2181,slave1:2181,slave2:2181,slave3:2181将会出现刚刚订阅的topic:bigdata_app_logs
再
./kafka-console-consumer.sh --zookeeper master:2181,slave1:2181,slave2:2181,slave3:2181 --topic topic:bigdata_app_logs --from-beginning将会实时同步log服务器上面的日志。这样,kafka集群环境就搭建OK了
下面是作者自己整理的kafka流程图:
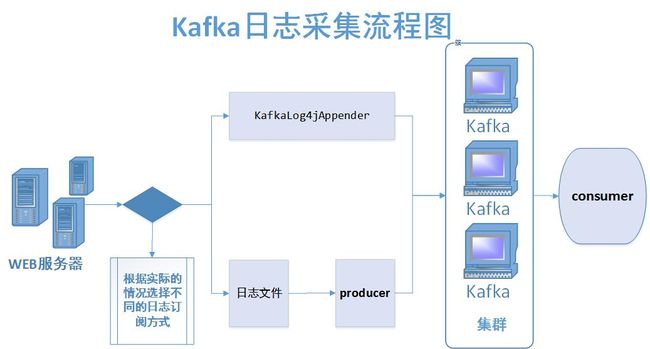
这里日志采集有两种方式,一种是网站程序通过log4j记录的log文件,然后再客户端运行,也就是上面介绍的那种。
另一种就是通过KafkaLog4jAppender之间讲日志传输到kafka集群,需要引入一个jar包
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka_2.11artifactId>
<version>0.8.2.0version>
dependency>在log4j的两种配置配置
log4j.logger.com.jjshome.bigdata.controller.CommonController=INFO,KAFKA_HIVE_AUDIT
log4j.appender.KAFKA_HIVE_AUDIT=kafka.producer.KafkaLog4jAppender
log4j.appender.KAFKA_HIVE_AUDIT.BrokerList=master:9092,slave1:9092,slave2:9092,slave3:9092
log4j.appender.KAFKA_HIVE_AUDIT.Topic=bigdata_app_logs
log4j.appender.KAFKA_HIVE_AUDIT.layout=org.apache.log4j.PatternLayout
log4j.appender.KAFKA_HIVE_AUDIT.layout.ConversionPattern=%m%n
log4j.appender.KAFKA_HIVE_AUDIT.ProducerType=async
<appender name="KAFKA_HIVE_AUDIT" class="kafka.producer.KafkaLog4jAppender">
<param name="DatePattern" value="'.'yyyy-MM-dd"/>
<param name="BrokerList" value="master:9092,slave1:9092,slave2:9092,slave3:9092"/>
<param name="Topic" value="jjs-fang-web-bigDatas"/>
<param name="ProducerType" value="async"/>
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %x - %m%n"/>
layout>
appender>个人建议使用第二种,但是要做好服务器之间的容错机制,作者前期就吃过亏,在采集日志的时候,直接影响了业务流程。
- storm
这里就不介绍了
解压
tar -zxvf apache-storm-0.9.5.tar.gz配置
conf/storm.yaml
storm.zookeeper.servers:
- "master"
- "slave1"
- "slave2"
- "slave3"
storm.local.dir: "/home/storm/data"
nimbus.host: "master"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
ui.port: 80子节点配置都一样,直接丢过去就好了
启动
作者是在主节点启动nimbus和ui、supervisor,其他的三个节点启动supervisor
主节点
storm nimbus &
storm ui &
storm supervisor &jps后出现nimbus和core、supervisor的进程,或者直接访问http://master即可(端口配置的是80)
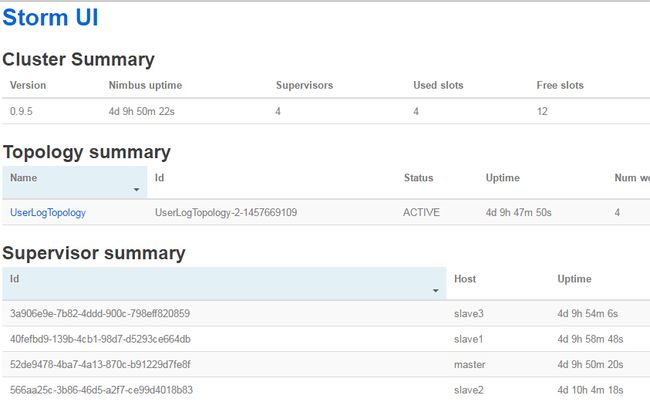
注:这里作者配置了环境变量,所以可以直接storm
子节点分别都运行
storm supervisor &下面是作者画的storm结构图
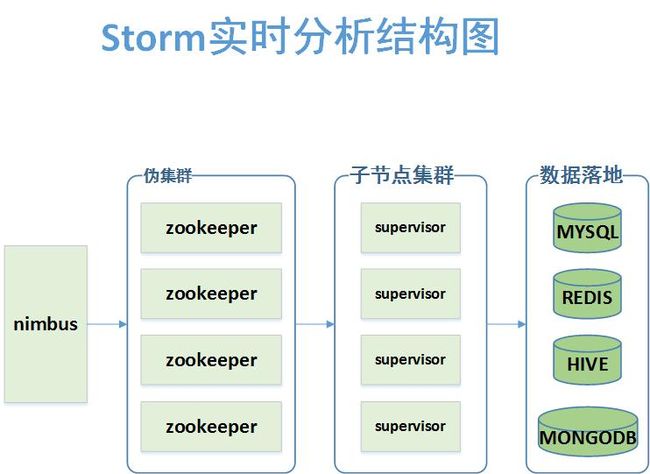
后面的数据落地,是结合业务,将数据存储起来
好了,到此环境以及准备完毕。
若是要关闭各种进程,直接jps后直接kill掉。
Topology开发
topology是storm中job的别名,它的工作流程大概如图:
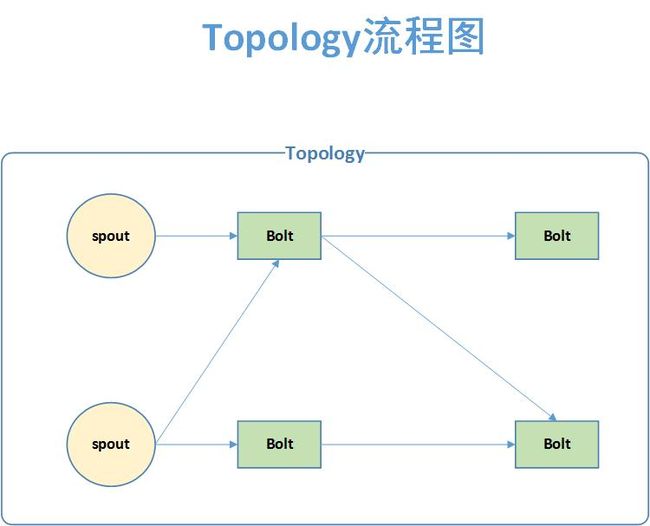
这里spout消息发送源,bolt是数据处理节点,计算出来的记过可以多次使用
项目准备:
storm-lib.zip
[big-data-client]
[big-data-storm]
第一个作者开发的Topology需要的lib包,将该lib替换到所有storm集群的storm/lib下
第二个作者开发环境需要的中间件,第三个storm项目。
项目中有两个案例,一个TopN案例,一个客户画像案例(针对自自有业务的客户画像)

bolt是工作节点,remote是外部调用的数据接口,spout是消息源,topology是job主目录。
下面是客户画像的
Topology
package com.jjshome.storm.topology;
import java.util.List;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import storm.kafka.BrokerHosts;
import storm.kafka.KafkaSpout;
import storm.kafka.SpoutConfig;
import storm.kafka.StringScheme;
import storm.kafka.ZkHosts;
import backtype.storm.Config;
import backtype.storm.spout.SchemeAsMultiScheme;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
import com.google.common.collect.ImmutableList;
import com.jjshome.storm.bolt.house.BoltFCWSplit;
import com.jjshome.storm.bolt.house.BoltLogFormat;
import com.jjshome.storm.bolt.house.BoltLogFormat4App;
import com.jjshome.storm.bolt.house.BoltSave;
import com.jjshome.storm.bolt.house.BoltThreshold;
import com.jjshome.storm.utils.CommonConstant;
import com.jjshome.storm.utils.StormRunner;
/**
* @功能描述: 用户行为分析的Topology
* @项目版本: 1.0.0
* @项目名称: 大数据
* @相对路径: com.jjshome.storm.topology.UserLogTopology.java
* @创建作者: 欧阳文斌
* @问题反馈: [email protected]
* @创建日期: 2015年12月7日 上午10:20:27
*/
public class UserLogTopology {
private static Logger logger = LoggerFactory.getLogger(UserLogTopology.class);
/** 本地调试运行时间单位(秒) */
private static final int DEFAULT_RUNTIME_IN_SECONDS = 60*30;
/** kafka集群 */
private static final String kafka_zookeeper_local = "master:2181,slave1:2181,slave2:2181,slave3:2181";
private static final String kafka_zookeeper_online = "bigdata-99-51-master.jjshome.com:2181,bigdata-99-52-slave.jjshome.com:2181,bigdata-99-53-slave.jjshome.com:2181,bigdata-99-54-slave.jjshome.com:2181";
/** Storm集群列表 */
private static final List zk_servers_local = ImmutableList.of("master","slave1", "slave2", "slave3");
private static final List zk_servers_online = ImmutableList.of("bigdata-99-51-master.jjshome.com","bigdata-99-52-slave.jjshome.com", "bigdata-99-53-slave.jjshome.com", "bigdata-99-54-slave.jjshome.com");
private static Config createTopologyConfiguration() {
Config conf = new Config();
//是否是本地模式
conf.setDebug(CommonConstant.IS_LOCAL?true:false);
//设置工作机数量
conf.setNumWorkers(CommonConstant.IS_LOCAL?4:16);
return conf;
}
/**
* @功能描述: 获取KafkaConfig
* @创建作者: 欧阳文斌
* @创建日期: 2015年12月11日 下午2:08:36
* @return
*/
private static KafkaSpout getKafkaSpout(){
// 房产网 bigdata日志的消息
String kafkaZookeeper = CommonConstant.IS_LOCAL?kafka_zookeeper_local:kafka_zookeeper_online;
BrokerHosts brokerHosts = new ZkHosts(kafkaZookeeper);
SpoutConfig kafka_config_fang = new SpoutConfig(brokerHosts,
"jjs-fang-web-bigDatas", "/jjs-fang-web-bigDatas", "jjs-fang-web-bigDatas");
kafka_config_fang.scheme = new SchemeAsMultiScheme(new StringScheme());
kafka_config_fang.zkServers = CommonConstant.IS_LOCAL?zk_servers_local:zk_servers_online;
kafka_config_fang.zkPort = 2181;
return new KafkaSpout(kafka_config_fang);
}
/**
* @功能描述: 获取KafkaConfig
* @创建作者: 欧阳文斌
* @创建日期: 2015年12月11日 下午2:08:36
* @return
*/
private static KafkaSpout getKafkaSpout_App(){
// 房产网 bigdata日志的消息
String kafkaZookeeper = CommonConstant.IS_LOCAL?kafka_zookeeper_local:kafka_zookeeper_online;
BrokerHosts brokerHosts = new ZkHosts(kafkaZookeeper);
SpoutConfig kafka_config_fang = new SpoutConfig(brokerHosts,
"bigdata_app_logs", "/bigdata_app_logs", "bigdata_app_logs");
kafka_config_fang.scheme = new SchemeAsMultiScheme(new StringScheme());
kafka_config_fang.zkServers = CommonConstant.IS_LOCAL?zk_servers_local:zk_servers_online;
kafka_config_fang.zkPort = 2181;
return new KafkaSpout(kafka_config_fang);
}
public static void main(String[] args) {
//Topology构造器
TopologyBuilder builder = new TopologyBuilder();
String topologyName = "UserLogTopology";
//配置器
Config topologyConfig = createTopologyConfiguration();
int runtimeInSeconds = DEFAULT_RUNTIME_IN_SECONDS;
final String app_index = "s_app";
final String pc_index = "s_pc";
final String fcwsplit_index = "b_fcwsplit";
final String logformat_index = "b_logformat";
final String logformatapp_index = "b_logformatapp";
//final String mongodb_index = "b_mongodb";
final String threshold_index = "b_threshold";
final String save_index = "b_save";
//设置 手机app log日志源
builder.setSpout(app_index, getKafkaSpout_App(), 4).setNumTasks(4);
//设置 房产网日志源
builder.setSpout(pc_index, getKafkaSpout(), 8).setNumTasks(8);
//房产网日志切割和过滤
builder.setBolt(fcwsplit_index, new BoltFCWSplit(), 8).setNumTasks(8).shuffleGrouping(pc_index);
//日志格式化
builder.setBolt(logformat_index, new BoltLogFormat(), 4).setNumTasks(4).shuffleGrouping(fcwsplit_index);
//手机日志格式化
builder.setBolt(logformatapp_index, new BoltLogFormat4App(), 4).setNumTasks(4).shuffleGrouping(app_index);
//存储 _USER_INTENTION 到mongoDB
/*builder.setBolt(mongodb_index, new BoltMongo(), 2)
.shuffleGrouping(logformat_index)
.shuffleGrouping(logformatapp_index);*/
//数据 阀 控制
builder.setBolt(threshold_index, new BoltThreshold(2,60), 6).setNumTasks(6)
.fieldsGrouping(logformat_index, new Fields("ip"))
.fieldsGrouping(logformatapp_index, new Fields("ip"));
//数据落地
builder.setBolt(save_index, new BoltSave(), 4).setNumTasks(4).fieldsGrouping(threshold_index, new Fields("ip"));
try {
StormRunner.runTopologyLocally(builder.createTopology(), topologyName,
topologyConfig, runtimeInSeconds);
} catch (Exception e) {
logger.error("UserLogTopology@main", e);
}
}
}
builder的整个构建过程,实际上也就是数据流的加工过程。kafka的spout是引用第三方的jar,pom中有配置。
bolt
package com.jjshome.storm.bolt.house;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.apache.commons.lang.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
import com.jjshome.bigdata.entity.log._JJS_Log;
import com.jjshome.bigdata.util.SystemConstant;
/**
* @功能描述: 房产网日志解析
* @项目版本: 1.0.0
* @项目名称: 大数据
* @相对路径: com.jjshome.storm.bolt.BoltFCWSplit.java
* @创建作者: 欧阳文斌
* @问题反馈: [email protected]
* @创建日期: 2015年12月11日 下午2:20:07
*/
public class BoltFCWSplit implements IRichBolt {
private static final long serialVersionUID = 1L;
private Logger logger = LoggerFactory.getLogger(BoltFCWSplit.class);
private OutputCollector collector;
/** 用户行为分析的LOG正则 */
private static Pattern s = Pattern.compile(""
//时间
+ "(.*?),.*"
//类别
+ "(YslHouseController|EsfHouseController|ZfHouseController|AgentInfoController|YywtController).*"
//ip
+ "ip=(.*?),.*"
//cityCode
+ "cityCode=(.*?),.*"
//userId
+ "userId=(.*?),.*"
//phone
+ "phone=(.*?),.*"
//refererAddress
+ "refererAddress=(.*?),.*"
//accessAddress
+ "accessAddress=(.*?),.*"
//tags
+ "tags=(.*?),.*"
//keyWord
+ "keyWord=(.*?),.*"
//cookiesId
+ "cookiesId=(.*?),.*");
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("object"));
}
@SuppressWarnings("rawtypes")
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String msg = "NOTHING";
try {
//获取消息流
msg = input.getString(0);
//异常日志判断
if(msg!=null&&msg.length()<1000){
//正则匹配
Matcher sm = s.matcher(msg);
if(sm.find()){
//LOG日志格式转换这对象
_JJS_Log jjsLog = new _JJS_Log();
log2entity(sm, jjsLog);
if (jjsLog.getUrl_type() == 5) {
if (jjsLog.getNew_url() != null
&& jjsLog.getNew_url().indexOf("saveReserveOrderInfo") > -1
&& !"".equals(jjsLog.getUserId())
&& null != jjsLog.getUserId()) {
//发送消息到下一个bolt
collector.emit(new Values(jjsLog));
}
} else {
//发送消息到下一个bolt
collector.emit(new Values(jjsLog));
}
}
}
} catch (Exception e) {
//错误记录做记录 不需要重复发送
logger.error("BoltFCWSplit@execute "+msg, e);
} finally {
//消息处理成功
collector.ack(input);
}
}
@Override
public void cleanup() {
// TODO Auto-generated method stub
}
@Override
public Map getComponentConfiguration() {
// TODO Auto-generated method stub
return null;
}
/**
* @功能描述: log日志转化
* @创建作者: 欧阳文斌
* @创建日期: 2015年12月15日 上午11:34:45
* @param sm
* @param jjsLog
*/
private void log2entity(Matcher sm, _JJS_Log jjsLog){
if(sm!=null&&jjsLog!=null){
int i=0;
jjsLog.setS_date(sm.group(++i));
jjsLog.setType(SystemConstant.FCW_INDEX);
String type = sm.group(++i);
if(StringUtils.isNotEmpty(type)){
if(type.equals("YslHouseController")){
jjsLog.setUrl_type(1);
}else if(type.equals("EsfHouseController")){
jjsLog.setUrl_type(2);
}else if(type.equals("ZfHouseController")){
jjsLog.setUrl_type(3);
}else if(type.equals("AgentInfoController")){
jjsLog.setUrl_type(4);
} else if(type.equals("YywtController")){
jjsLog.setUrl_type(5);
}
}
jjsLog.setIp(sm.group(++i));
jjsLog.setCityCode(sm.group(++i));
jjsLog.setUserId(sm.group(++i));
jjsLog.setTel_num(sm.group(++i));
jjsLog.setOld_url(sm.group(++i));
jjsLog.setNew_url(sm.group(++i));
jjsLog.setTags(sm.group(++i));
jjsLog.setKeyWord(sm.group(++i));
jjsLog.setCookies(sm.group(++i));
}
}
}
bolt中就是数据的逻辑处理,关键的方法是input.getString(0);获取数据,collector.emit(new Values(jjsLog));发送数据,collector.ack(input);告诉前一个发送者,信息处理成功。
在topology的grouping策略就是在Spout与Bolt、Bolt与Bolt之间传递Tuple的方式。总共有七种方式:
1)shuffleGrouping(随机分组)
2)fieldsGrouping(按照字段分组,在这里即是同一个单词只能发送给一个Bolt)
3)allGrouping(广播发送,即每一个Tuple,每一个Bolt都会收到)
4)globalGrouping(全局分组,将Tuple分配到task id值最低的task里面)
5)noneGrouping(随机分派)
6)directGrouping(直接分组,指定Tuple与Bolt的对应发送关系)
7)Local or shuffle Grouping
8)customGrouping (自定义的Grouping)
常用的也就是随机分组、按字段分组以及全局分组。
在自己Topology开发完成后,可以讲运行模型修改成本地,然后运行Topology,方便进行调试。若是要发布到进群环境中,则将Storm项目打包,maven install(作者是maven项目),将打好的jar上传到nimbus服务器。
storm jar storm-kafka-topology.jar com.jjshome.storm.topology.UserLogTopology在jar的根目录上传jar到storm集群中,后面的类名是一个带main的topology,也就是上面的客户画像的topology。
发布成功后,可以在UI界面看到topology的运行情况,各个节点的日志处理数量,延迟时间

topology运行起来后,可以在各个数据存储的节点中,获取storm实时分析的结果。通过分析的结构,得到各个用户实时的各种标签,最后通过这些标签,在产品库中筛选最匹配的产品。
下面是作者的客户画像架构图
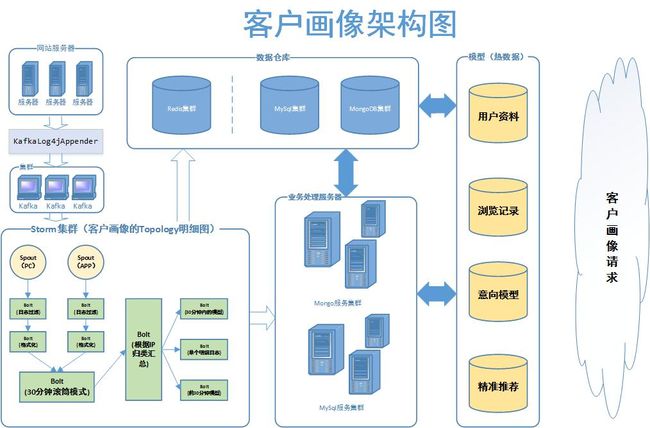
数据流程
1.用户操作产生日志
2.kafka收集日志
3.Storm分析处理日志
1)日志详情存储到mongoDB
2)半小时外意向模型存储到mongoDB
3)半小时内意向模型存储到redis
4)如果用户登录后的操作,则唤醒mongodb中所有的半小时意向模型,重新组装模型更新到mysql热表中
5)监控日志,如果发生预警事件操作,则触发意向模型以及精准推荐的生成
模型构建
在生成各种标签集合时,要加入权重因子(可变),针对不同产品,构建不同标签,再对各种操作以及权重因子,来生产用户标签。深度分析可以考虑加入机器学习在里面。
开发问题和运维问题的分析和解决
Q:在搭建集群的时候,通过UI看到各个节点的主机名一样,都是localhost,导致topology完全不工作。
A:检测各个虚拟机的hostname,保持和hosts中配置的一致,再重启zookeeper和storm集群
Q:在发布topology到集群上后,在UI界面中看到各种class找不到的错误
A:将storm项目中的lib打包统一都放到storm中lib,这里要注意jar包冲突和版本问题
Q:在日志累加的时候,fail的日志越来越多,导致延迟越来越大
A:这个问题跟业务处理有关系,检查出现问题的bolt,通过删剪法,反复提交测试,找出有问题的代码
Q:发现设置的works节点不生效,实际的比设置的少很多
A:检查topology的配置器,是不是本地模式。
Q:数据实时处理,怎么才能高效的让数据落地
A:作者这里用了滚筒模式,累积半小时的数据,再统一存储,半小时以内的,直接存放在redis集群中
Q:在使用kafka的producer命令监控日志的时候,老是出现日志终端的现象
A:看看log4j是否配置了日志时间戳,因为开启了时间戳,日志将会定时或不定时的将文件重命名,然后新开硬盘地址做存储,这样kafka是没有办法获取新的log硬盘地址。解决办法:换用KafkaLog4jAppender方式,或者让log文件不替换,每天定时清理一次就好了
Q:kafka集群服务器硬盘空间满了
A:在没有什么设定的操作下,kafka收到的日志会存储在硬盘中,终究有一天,硬盘会满掉。解决办法:在各个节点添加crontab计划
0 6 * * * /home/zookeeper/bin/zkCleanup.sh -n 3