【01】什么是概率图模型?
什么是概率图模型
文章目录
-
- 概率模型
- 概率模型的难点
- 用图描述概率
- 课程概览
-
- 表示
- 推理
- 学习
概率图模型是机器学习的一个分支,重点研究如何利用概率分布描述真实世界并对其做出有价值的预测。
学习概率模型有很多理由。其中之一就是它是一个迷人的科学领域,有着美丽的理论,以令人惊讶的方式连接了两个截然不同的数学分支:概率论和图论。概率模型也与哲学有着有趣的联系,特别是因果问题。
同时,概率模型也被广泛用于机器学习和真实问题中。这些技术可用于解决医学、语言处理、视觉等领域的问题。
优雅的理论加上强大的应用,使图模型成为现代人工智能和计算机科学中最炙手可热的课题1。
概率模型
那么到底什么是概率模型?当试图用数学解决现实世界的问题时,用方程的形式来定义现实世界的数学模型是非常常见的。也许最简单的模型是以下形式的线性方程:
y = β T x y = \beta^T x y=βTx
其中 y y y 是我们想预测的输出变量,而 x x x 是影响输出的给定变量。例如, y y y 可能表示房价, x x x 是一系列影响房价的因子,如地段、卧室数量、房龄等。我们假设 y y y 是输入的线性方程(线性参数为 β \beta β)。
我们要建模的现实世界往往非常复杂;尤其是,它通常涉及大量的不确定性(例如:如果房子周围新建了一个地铁站,房价有可能上涨)。因此,通过概率分布2的形式对世界进行建模来处理这种不确定性是非常自然的。
p ( x , y ) p(x, y) p(x,y)
对于这个模型,我们可能会问“未来五年房价上涨的可能性有多大?”,或者“假定房子价值10万美元,它有三间卧室的可能性有多大?”
模型中的概率成分非常重要,因为:
- 通常,我们无法完全预测未来。我们对这个世界往往没有足够的了解,而且这个世界本身也是随机的。
- 我们需要评估我们预测的可信度;通常,预测一个单一的值是不够的,我们需要系统输出它对世界上正在发生的事情的信念。
在本课程中,我们将研究关于不确定性的推理法则,并使用概率和图论的思想为这项任务推导有效的机器学习算法。我们将找到许多有趣问题的答案,例如:
- 计算复杂度和概率模型丰富度之间如何权衡取舍?
- 在给定固定数据集和计算预算的情况下,推断未来事实的最佳模型是什么?
- 用何种法则将先验知识与观测证据结合起来进行预测?
- 我们如何严格分析A是B的原因,还是B是A的原因?
此外,我们还将看到许多如何将概率技术应用于各种问题的示例,例如:疾病预测、图像理解、语言分析等等。
概率模型的难点
为了让大家快速了解我们面临的挑战,考虑一个简单的概率模型应用:垃圾邮件分类。
假设我们有一个垃圾邮件和非垃圾邮件中单词出现的模型 p θ ( y , x 1 , … , x n ) p_\theta(y, x_1, \dotsc, x_n) pθ(y,x1,…,xn)。每个二进制变量 x i x_i xi 对电子邮件中是否存在第 i i i 个英语单词进行编码;二进制变量 y y y 指示电子邮件是否为垃圾邮件。为了对新电子邮件进行分类,我们可以考虑概率
P ( y = 1 ∣ x 1 , … , x n ) P(y=1 \mid x_1, \dotsc, x_n) P(y=1∣x1,…,xn)
我们刚刚定义的函数 p θ p_\theta pθ 的“大小”是多少呢?我们的模型对每一个输入组合 y , x 1 , … , x n y, x_1, \dotsc, x_n y,x1,…,xn 给出 [ 0 , 1 ] [0, 1] [0,1] 之间的概率。给出所有这些概率需要我们写下惊人的 2 n + 1 2^{n+1} 2n+1 个不同的值,对每一个赋予 n + 1 n+1 n+1 个二进制变量。因为 n n n 是英语词汇的大小,无论从计算角度来看(我们如何存储这个大列表?)还是从统计角度来看(我们如何有效地从有限的数据中估计参数?),都显然不切实际。更一般而言,我们的示例说明了本课程将要处理的主要挑战之一:概率是固有的指数大小的对象;我们操纵它们的唯一方法是对它们的结构进行简化假设。
本课程中做出的主要简化假设是变量之间的条件独立性。例如,假设英语单词都跟给定的 Y Y Y 条件独立,换句话说,看到两个词的概率与消息是垃圾邮件是独立的。显而易见,“药丸”和“购买”这两个词的概率明显相关。然而对大多数词来说(例如“企鹅”和“松饼”)概率肯定是独立的,我们的这个假设不会显著降低模型的准确性。
我们将这种特定的独立性选择称为 朴素贝叶斯 假设。给定这个假设,我们可以将模型概率写成因子的乘积
P ( y , x 1 , … , x n ) = p ( y ) ∏ i = 1 n p ( x i ∣ y ) P(y, x_1, \dotsc, x_n) = p(y) \prod_{i=1}^n p(x_i \mid y) P(y,x1,…,xn)=p(y)i=1∏np(xi∣y)
每个因子 p ( x i ∣ y ) p(x_i \mid y) p(xi∣y) 完全可以由少量参数描述(准确的说,4个参数具有2个自由度)。整个分布由参数进行参数化,我们可以根据数据进行简单估计并进行预测。
用图描述概率
我们的独立性假设可以方便地用图的形式表示。这种表示法的直接优点是易于理解。它可以解释为向我们讲了一个故事:一封电子邮件先是通过随机选择是否是垃圾邮件(由
y y y 表示)而生成的,然后一次抽样一个词。相反,如果我们有一个关于数据集如何生成的故事,我们自然可以将其表示为具有相关概率分布的图。
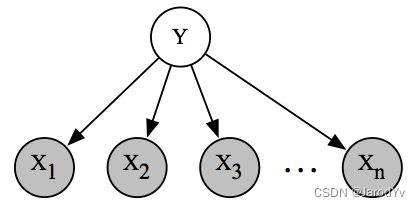
更重要的是,我们希望向模型提交各种查询(例如,如果我看到“药丸”一词,垃圾邮件的概率是多少?);回答这类问题需要使用图论中的专门算法。我们还将使用图论分析学习算法的速度,并量化不同学习任务的计算复杂性(例如,NP难度)。
课程概览
我们对图模型的讨论将分为三个主要部分:表示(如何描述模型)、推理(如何向模型提问)和 学习(如何用现实数据训练模型)。这三个主题相辅相成:为了推导出有效的推理和学习算法,模型需要得到充分的表示;此外,学习模型将需要推理作为子程序。因此,最好始终牢记这三项任务,而不是孤立地关注它们。
表示
我们要如何表达模拟真实世界现象的概率分布呢?这不是一个简单的问题:我们已经见到过用 n n n 个可能的词对垃圾邮件进行分类的简单模型,这么简单的模型通常都需要我们指定 O ( 2 n ) O(2^n) O(2n) 个参数。我们将通过构建可处理模型的一般技术来解决这一难题。这部分将大量使用图论;概率将由图来描述,图的属性(如连通性、树宽度)将揭示模型的概率和算法特征(如独立性、学习复杂性)。
推理
给定一个概率模型,我们如何获得关于真实世界的相关问题的答案呢?这些问题通常归结为对某些感兴趣事件的边缘概率或条件概率的查询。
更具体地说,我们通常会向系统提出两类问题:
- 边缘推理:当我们将模型中所有其他变量求和后,给定变量的概率是多少?比如确定随机房屋有三间以上卧室的概率。
p ( x 1 ) = ∑ x 2 ∑ x 3 ⋯ ∑ x n p ( x 1 , x 2 , … , x n ) p(x_1) = \sum_{x_2} \sum_{x_3} \cdots \sum_{x_n} p(x_1, x_2, \dotsc, x_n) p(x1)=x2∑x3∑⋯xn∑p(x1,x2,…,xn)
- 最大后验(MAP)推理:获取最可能的变量赋值。例如,我们可以尝试找出最可能是垃圾邮件的信息,解决这类问题
argmax x 1 , … , x n p ( x 1 , … , x n , y = 1 ) \underset{x_1, \dots, x_n}{\operatorname{argmax}}p(x_1,\dotsc,x_n, y=1) x1,…,xnargmaxp(x1,…,xn,y=1)
通常会涉及证据(如上面MAP的例子),在这种情况下,我们会更新变量子集的赋值。
事实证明,推理是一项非常具有挑战性的任务。对于许多我们感兴趣的概率,回答这些问题都是NP困难的。
至关重要的是,推理是否可处理取决于描述概率的图的结构!如果问题难以解决,我们仍然能够通过近似推理方法获得有价值的答案。
有趣的是,本课程这部分描述的算法将大量基于20世纪中期统计物理界所做的工作。
学习
我们最后一个关键任务是将模型拟合到数据集,例如,数据集可以是大量标记的垃圾邮件样本。
通过查看数据,我们可以推理出有用的模式(例如,哪些词在垃圾邮件中更常见),然后我们可以使用这些模式预测未来。
然而,我们会发现学习和推理之间也存在着一种更微妙的内在联系,我们可以证明推理是一个关键的子程序,在学习算法中反复调用。
此外,学习这一话题将与计算学习理论领域(该领域解决有限数据的泛化和过拟合等问题)和贝叶斯统计(该领域告诉我们结合先验知识和观测证据的法则)有着重要联系。
2011年图灵奖(被认为是“计算机科学诺贝尔奖”)授予了 朱迪亚·珀尔,奖励他创立了概率图模型这一新领域。 ↩︎
关于为什么应该使用概率论而不是其他学科的更多哲学讨论,请参阅 Dutch book argument for probabilism。 ↩︎