干货!针对知识图谱学习的高效超参搜索算法
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

超参数调优对于知识图谱学习是一个重要问题,会严重影响模型性能,但由于模型训练时间长,现有的超参数搜索算法往往效率低下。
为解决这一问题,我们详细地分析了不同超参数的性质,及子图到全图的迁移能力。并根据实验效果提出了两阶段的调参算法KGTuner,我们在第一阶段利用子图高效地探索大量超参数,并将性能最好的几组超参数配置迁移到全图上,在第二阶段进行微调。
实验表明,两阶段搜索算法大大提升了超参数搜索效率,在不同的大规模知识图谱链接预测任务上,均获得了性能的提升。
本期AI TIME PhD直播间,我们邀请到香港科技大学计算机系博士——张永祺,为我们带来报告分享《针对知识图谱学习的高效超参搜索算法》。
张永祺:
第四范式算法科学家,从事机器学习算法研究工作,主要研究方向为自动化机器学习、知识图谱表示学习与图神经网络。其自研的自动化知识图谱表示学习技术,在知识图谱的多项重要任务上达到国际领先水平,并在人工智能领域顶级会议期刊NeurIPS、TPAMI、ACL、WWW、VLDB Journal、ICDE上发表多个相关工作。他于2020年博士毕业于香港科技大学,2015年本科毕业于上海交通大学。
1
Background
Background – Knowledge Graph (KG)
首先,对于知识图谱来说,有以下背景知识。

用关系来度量头实体和尾实体之间的关联。作为语义图谱的KG,既要建模语义信息,也要建模结构信息。
Representative applications代表应用
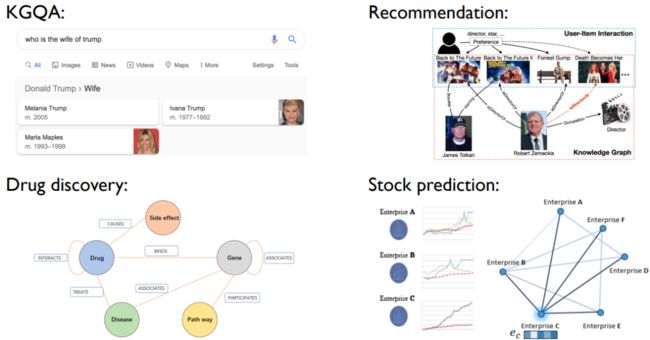
Background – Knowledge Graph Learning
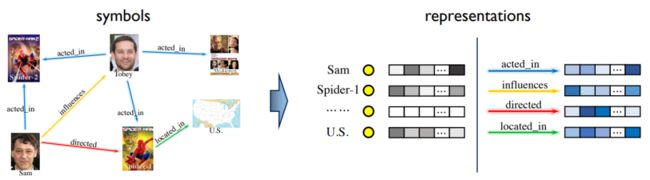
如上图所示,在给到一个知识图谱之后,我们希望把符号表达映射到向量表达,并学习实体之间关系的一个表示。
Advantages:
• Continuous, ease of use in ML pipeline.
• Discover latent properties.
• Efficient similarity search
Background – Machine learning on Knowledge Graph
• A scoring function F to measure the plausibility triplets
• A sampling scheme to generate negative samples S-!
• A loss function L and regularization r to define the learning problem • An optimization strategy for convergence procedure
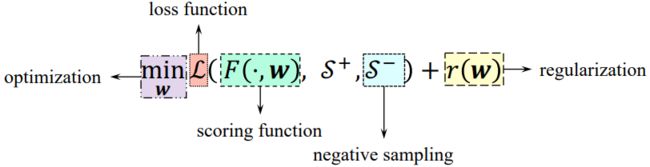
我们需要一些采样机制去采样一些负样本,有了正负样本之后我们需要定义损失函数并避免过拟合。最后,我们还需要有一个优化策略。
Key components and related hyper-parameters (HPs)
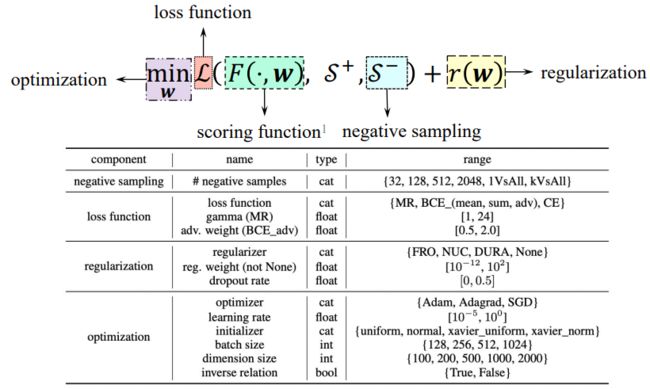
对于这些不同的结构,在对应的几个方面都有相应地超参数。
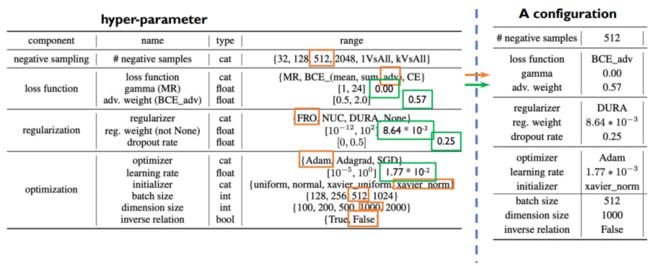
在给定这么大的范围之后,我们如上图所示在各项中都选择一个组成超参数的配置并拿给模型去训练,这样也就完成了一次超参数评估。
Background – review of KGE models
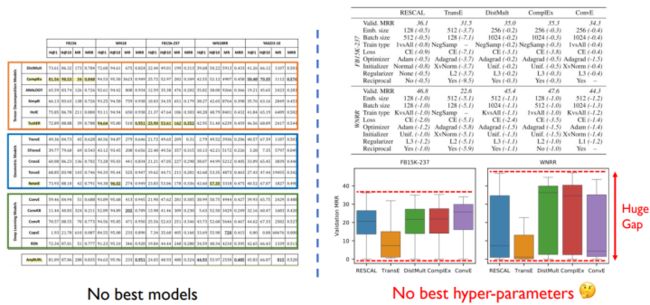
在现有的问题之中,首先对于不同的任务数据来说并不存在最好的模型,这点对于超参数来说是一样的。
我们也发现,选择不同的超参数所带来的影响也是非常大的。所以选择超参数对我们来说是一个非常重要的问题。
Background – from the AutoML scope
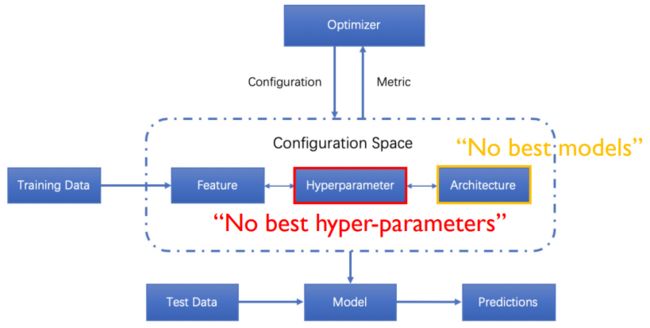
对于超参数的评估,首先存在上图这样的一个框架。在给定训练集之后,我们利用训练集设计一个优化器来优化模型和超参数。
优化完之后,我们再把最好的超参传递给预测集去预测。我们关心的主要就是这样一个超参数的搜索过程。
Background – review of HPO methods
下面我们来看一些传统的超参搜索算法。
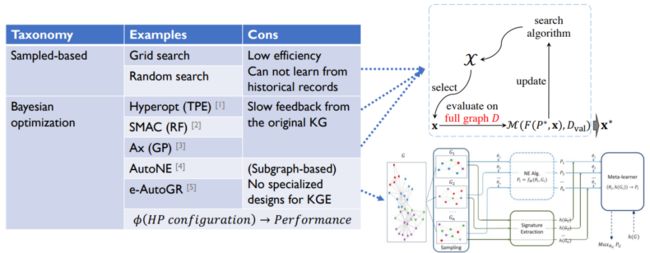
搜索算法会从我们的搜索空间中选择一个超参数配置,这个配置再在整个图上进行一个评估,最后的结果被用于更新算法。
基于采样的方法没有用到历史信息,效率很低。
贝叶斯的模型拿到反馈的效果很慢。AutoNE和e-AutoGR是两个针对图神经网络的超参搜索算法,目前在普通的图上效果好,但是在知识图谱上的效果是一般的,因为其没有考虑到知识图谱的一些特性。
所以我们希望能够为知识图谱学习这样一个场景设计一个高效的专有超参搜索算法。
2
Motivation and Objective
现有的超参搜索方法存在一定的缺陷:
• usually in a time-consuming trial-and-error way
• interaction, importance, and tunability of HPs are unclear
• lacking understanding of KGE components
KGTuner的目的:设计一个高效的超参数搜索算法
• Design a searching algorithm,
• for any given dataset and embedding model with limited budget,
• to efficiently search for the hyper-parameter configuration.
HP searching problem setup
首先,超参数搜索算法可以定义为一个二阶段的优化问题。给定超参数配置之后,我们会优化模型参数,最后拿到超参数反馈。

定义1中存在一些因素影响超参数搜索的效率:
1. the size of search space X
2. the validation curvature of M
3. the evaluation cost in solving argminp
我们要从以下三个方面;来考虑优化搜索效率的策略。
Understanding the HP in KGE
首先是搜索空间的大小。
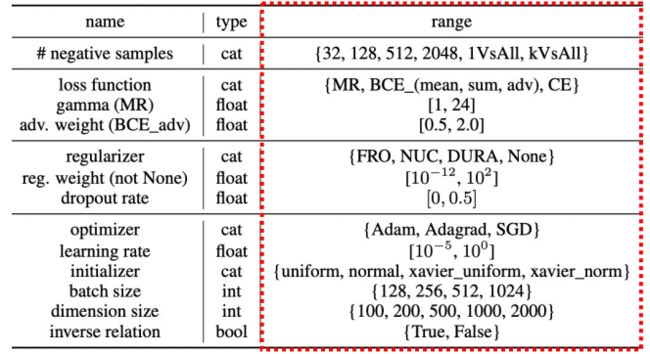
我们能否对空间进行压缩,然后从中提取一些关键的部分呢?
为了探索不同超参数的性质好坏,我们不可能在如此大的搜索空间之中将所有的超参数遍历到,所以我们采取控制变量法。比如固定其他的超参数,然后遍历负样本的超参数。

通过最终实验得到的不同分布,我们可以把超参数分为以下4类:
1. reduced options
2. shrunken range
3. monotonously related
4. no obvious patterns
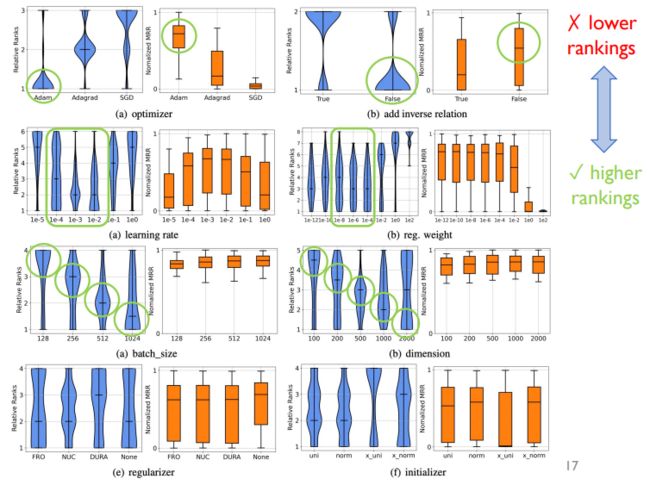
前面评估完了每一个超参数的性质,然后我们来看看我们改变一个超参之后,其他超参的排序是否会是一致的。

之前的做法是固定一个anchor,然后去遍历不同的负样本;这里是固定anchor,变换负样本的选择。
在负样本选项更换之后,anchor对应的排名是否一致需要我们去关注。
Positive and negative Spearman rank correlations
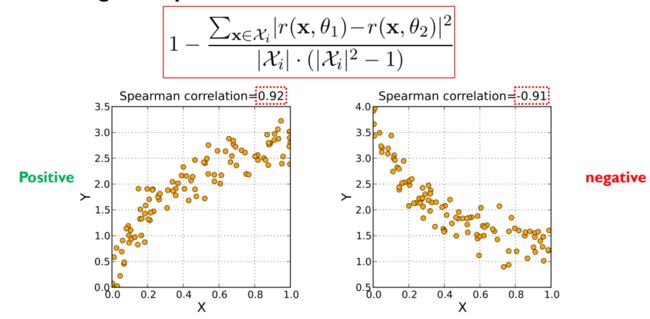
排名的一致性和相关性采用上图指标度量,衡量的是两个变量之间基于排名的相关性。

前面考虑的是两个变量之间的关系,现在对于任意两组变量的遍历计算相关性,最后得到的变量一致性如下图所示:
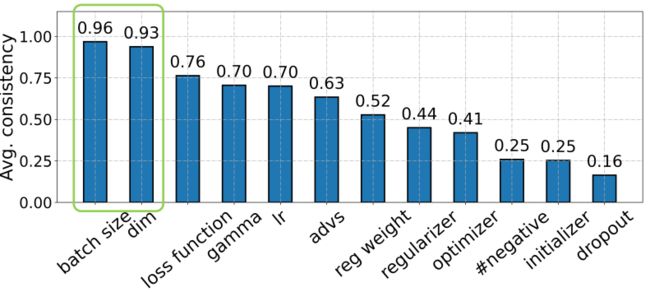
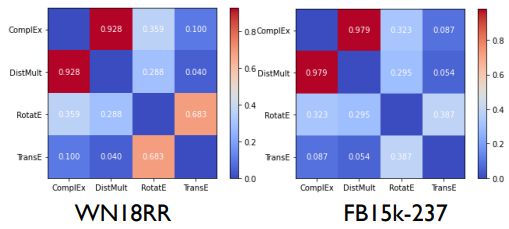
Observation: the batch size and dimension size show higher consistency than the other HPs.
Excavating properties of HPs | from the aspect of predictor
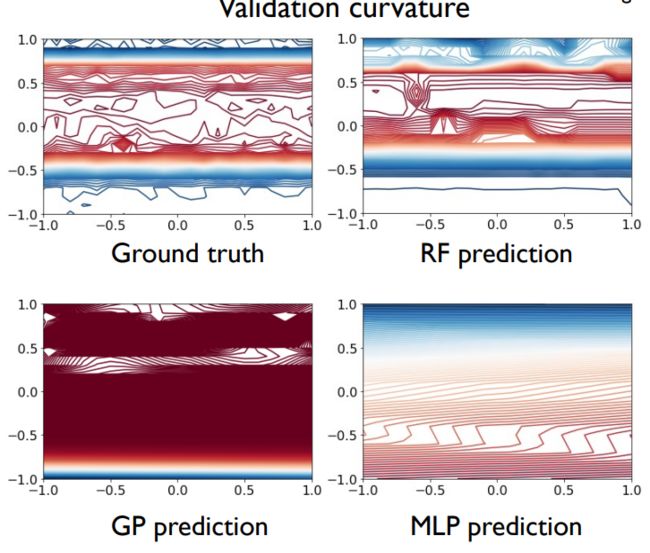
我们用了几个不同的预测器,发现随机森林的匹配效果比较好,能够近似很复杂的空间。
Predictors
• Gaussian process (GP)
• Multi layer perceptron (MLP)
• Random forest (RF)
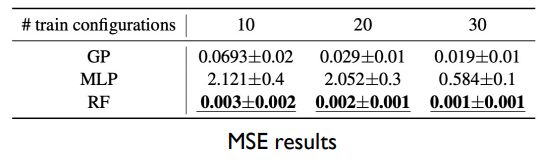
我们就选择随机森林作为近似曲面的模型。
Excavating properties of HPs | Time cost
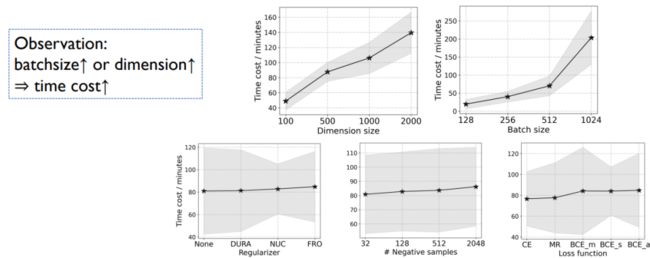
如果我们不去做这些操作,每一个数据集可能需要十几个小时的高昂时间代价。这也可能影响到对超参的分析。
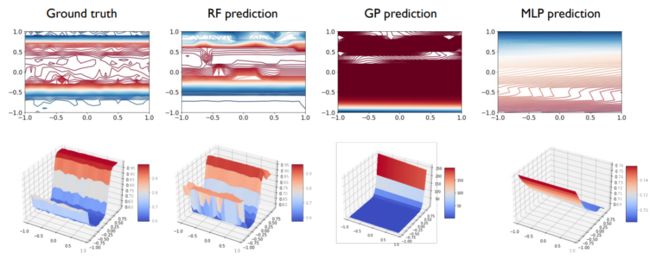
上述是从单个超参的性质考虑的。
Excavating properties of HPs | Transferability of subgraphs
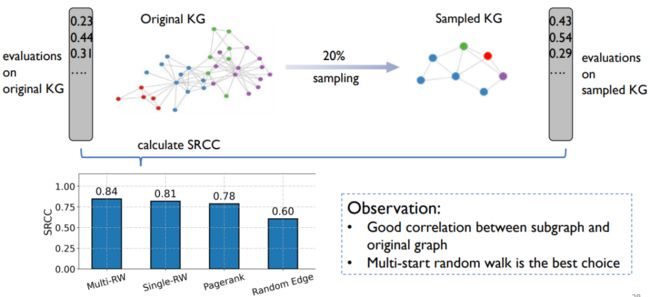
我们还考虑在整张图比较大时的采样问题。我们选取的baseline是在小图上训练预测器迁移到大图上。我们选取的迁移策略是采取多起点随机游走去进行直接的迁移。而对于子图大小来说,我们迁移的图一般是越大越逼近越好,采集20%—30%的节点为佳。
Summary of the observations
总结上述方法,我们一共从三个方向进行了详细的实验评估:
(1)
• Ranking distribution/consistency for each HP’s values
• dimension/batch size
• Full HP range can be shrunken and decoupled
(2)
• The validation curvature is pretty complex
• RF is better than GP/MLP as the predictor
(3)
• Sampling with multi-start random walk can reduce cost while possessing high performance consistency
我们接下来该如何根据这些评估结果设计超参搜索算法呢?
Efficient two-stage HP search algorithm
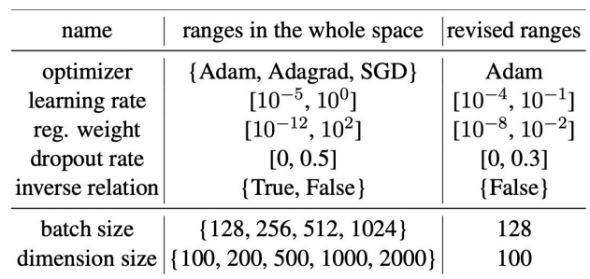
首先,我们根据前面的分布图,对搜索空间进行一定的裁剪。
接着,依据对搜索空间的理解,我们设计了一个二阶段的搜索算法。
这个算法在第一阶段注重对超参数的探索,利用子图和缩减的空间搜索大量超参数。
在第二阶段注重对top10超参数的利用,将batch size/dimension size释放,并在原图上进行充分微调。

我们画了一个简单的示意图,将该算法与传统的搜索算法进行对比。
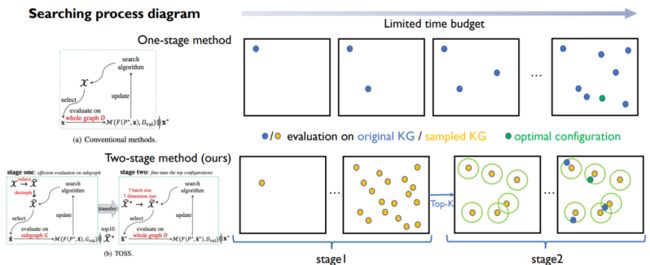
我们设计的这个二阶段搜索算法,可以在第一阶段探索大量的超参数,取得top k的配置进行fine-tuning,就能够在有限的时间内找到最好的超参。
3
Experiment
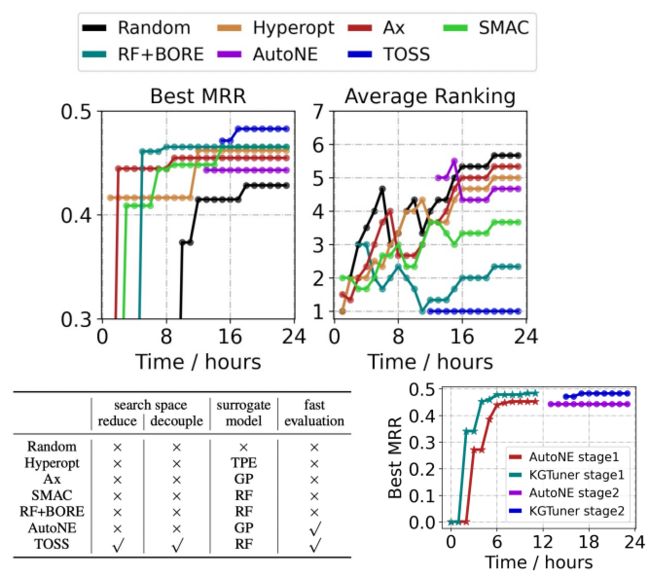
我们的搜索算法会比一些传统算法更好,因为这样的搜索算法同时考虑到了搜索空间、预测器和评估代价。
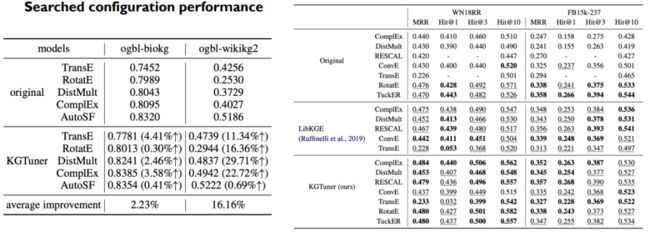
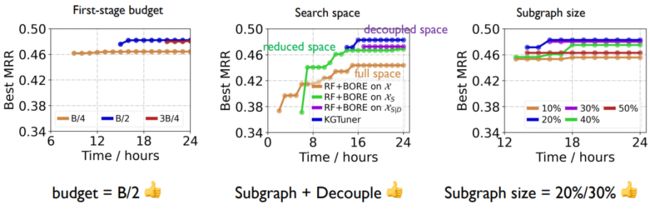
我们也做了一些Ablation study。
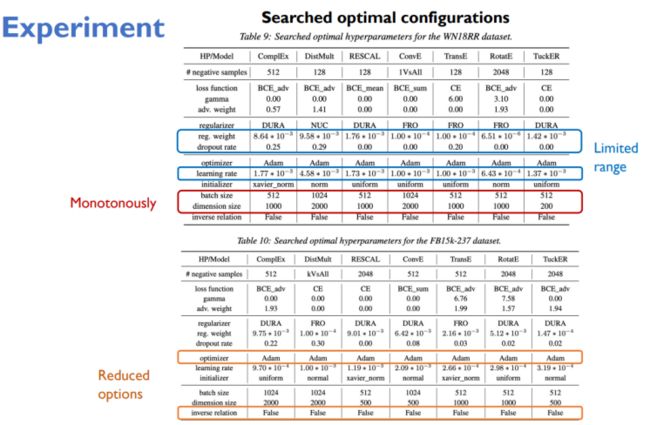
如上图,我们也展示了不同模型下的超参,发现和之前的结论是一致的。
Key takeaways
首先这个工作的难点在于当前对超参数缺乏理解,我们对之进行了详尽的理解和分析。
在超参数搜索方面,传统方法效率低下,我们提出了两阶段的超参搜索算法。

4
Limitation and future directions
Limitation
• Limited to pure embedding models
• Not considering HPs inside the SF model
• Lacking of theoretical analysis and guarantees
Potential directions
• apply with GNN to solve the scaling problem 未来方向也可能先去分析GNN中的配置来帮助我们进行后续的算法设计
• combine HPO with NAS
• transferability across datasets/models/tasks
提
醒
论文题目:
KGTuner: Efficient Hyper-parameter Search for Knowledge Graph Learning
论文链接:
https://openreview.net/pdf?id=cwPFJBwI0hG
点击“阅读原文”,即可观看本场回放
整理:林 则
作者:张永祺
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了600多位海内外讲者,举办了逾300场活动,超150万人次观看。

我知道你
在看
哦
~
![]()
点击 阅读原文 查看回放!