【技术新趋势】合合信息:复杂环境下ocr与印章识别技术理解及研发趋势
点击领取AI产品100元体验金,助力开发者高效工作解决文档难题:
AI产品专享礼遇
总结
合合信息技术团队经过调研复现以及对比实验,对于上述几个印章识别的解决方案,有以下总结,如下表所示:
| 技术方案 |
优点 |
缺点 |
| 印章文本检测+文本矫正(optional)+文本识别 |
检测与识别模块可独立优化 适用不同类型印章识别 |
速度慢 维护成本高 |
| 印章端到端检测识别 |
模型pipeline简单 速度快,便于维护 |
很难训练 不适用方章等特殊印章 |
| 印章序列预测方案 |
模型pipeline简单 适用不同类型印章识别 |
模型容易过拟合 可解释差 无法给出文本位置 |
引言
随着社会经济的发展,印章作为企事业单位、社会团体、政府部门乃至国家的一种具有法律意义的标志和证据,在现代社会生活中发挥着重要作用。随着现代商务活动的不断发展,企业在业务开展的过程中通常会涉及大量的合同签署归档工作,以往会采取人工审核合同照片的方式来判断合同签署的双方是否都加盖了公章,但是这样做人工审核时间成本高、人力成本高,因此,印章识别可自动提取出印章文本,从而实现计算机替代人工审核比对,解决合同管理工作中人工审核时间成本高、人力成本高的难题,降低财税及商务合同签订过程的业务风险,使商务连接更加高效和便捷。
常用印章
日常工作中常见的印章有:公章、财务章、法定代表人章、发票专用章、合同专用章。
技术难点
回到本文的介绍主题,本文希望通过介绍印章识别和常规文本行识别的对比,来阐述两者的差异,从而让读者建立一个较为具象的认知。
| 对比纬度 |
常规文本行识别 |
印章识别 |
示例图像 |
| 文字形状 |
矩形/四边形 |
任意形状 |
|
| 文字遮挡 |
一般而言是无遮挡的独立文本行 |
大概率存在不同程度的遮挡和背景干扰 重叠 |
|
| 排版方式 |
千奇百怪,方形、椭圆形、圆形等各种形状差异都很大 |
|
|
| 阅读顺序 |
人类自然阅读顺序 |
从左到右 从右到左 无序 受盖章方向影响 |
|



OCR领域中较少关于印章文字识别的研究,但是合合技术团队研究论证认为,自然场景文本识别的一些技术可以应用于印章识别。本文下面将介绍一些印章识别的技术方案。
印章识别主流方案
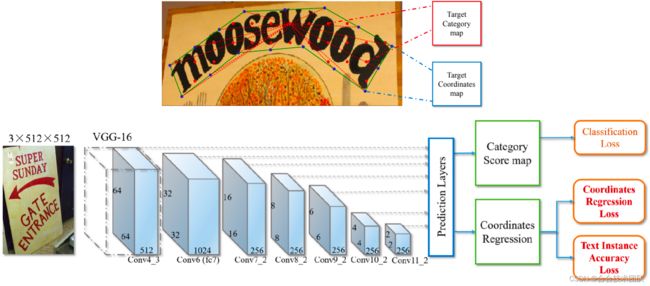
印章识别系统的输入是一张经过裁剪的印章图片,输出是印章中所有文本的坐标框和识别结果,流程如下图所示:

下面介绍一些印章识别的技术方案。
印章文本检测+文本矫正(optional)+文本识别
第一套印章识别方案是传统的级联系统:

经过裁剪的印章图片,首先经过一个支持曲形文本检测的文本检测模型获取文本坐标框,其输出可以直接送入文本识别模型得到最终的识别结果;也可以先利用一个TPS[1]矫正模块,将所有曲形文本拉直成水平文本行图片,再送入文本识别模型。
下面简单介绍一下其中重点模块的选型。
文本检测模型:近年来基于深度学习的场景文本检测领域取得了重大进展,有很多成熟的曲形文本检测方案可供选择,大体上分为两类:
-
基于回归的检测模型,比如Mask RCNN[2]、EAST-like[3]和TextRay[4];
-
基于分割的检测模型,比如PSENet[5]、CRAFT[6]和DBNet[7]。
下面以EAST-like(该模型没有名称,暂且称为EAST-like)为例做简单介绍:
上图是EAST-like的标签生成示意图和网络结构,该模型对经典的EAST[8]模型进行了扩展,通过增加回归点的数目来支持多边形检测;使用了多尺度预测来改善目标的尺度变化问题;另外在Loss方面也做了改进。
文本识别模型:从解码方式来划分,目前学术界主流的文本识别模型分为两类: CTC和Attention。
-
基于CTC的代表模型是CRNN[9],速度快,性能稳定,不过只能处理水平文本行图片(需要先经过TPS模块将曲形文本进行拉直);
-
基于Attention的识别模型有两种思路,第一种是先通过STN[10]进行矫正,然后送入1D Attention的识别模型进行端到端训练,代表模型是ASTER[11];另一种是抛弃STN模块,直接基于2D Attention解码完成(曲形)文本识别,比如SAR[12]、MASTER[13]和SATRN[14]。最近学术界流行的基于多模态的文本识别模型如ABINet[15]、VisionLAN[16]等,其实可以看作是2D Attention模型的延伸。
下面是经典的CRNN模型的网络结构:
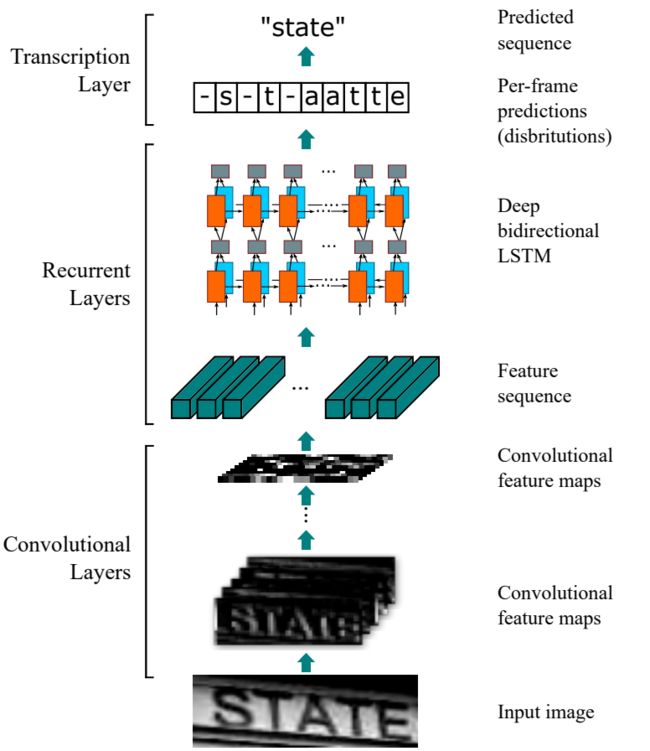
CRNN模型由三部分组成: 卷积层、循环层和转录层。卷积层负责提取图像特征;循环层通过BLSTM进行序列建模,进一步改善特征表征;最后是线性分类层,并通过CTC解码得到最终的预测结果。
总结下来,合合信息技术团队认为多模型级联是较为成熟的印章识别方案。其优点是各个环节可供选择的模型较为丰富,同时将检测与识别模块进行解偶,使其各自的训练互不影响。其缺点主要是级联系统的误差累积问题。
印章端到端检测识别(End2End)
上一节的级联系统中,检测和识别模型单独训练,一方面会造成整个识别系统的次优化效果,另一方面错失了检测和识别head共享主干网络图像特征的机会。
近年来,学术界一直在致力于提出端到端的文本检测识别系统,通过检测和识别头共享主干网络,能有效降低系统的复杂度,同时利用多任务学习进一步提升了模型的整体性能。
印章端到端检测识别模型流程如下所示:

近两年来,不少支持曲形文本识别的端到端模型被提出,下面以ABCNet[17]和Mask TextSpotterv3[18]为例进行简要介绍。
ABCNet网络结构和贝塞尔曲线拟合示意图如下所示:
ABCNet的主要亮点在于引入了贝塞尔曲线用于建模曲形文本边界框,如上图所示,通过三阶贝塞尔曲线(四个控制点)可以灵活地拟合出各种曲线。
网络结构方面,ABCNet由检测模块 + RoI_Transform + 识别模块构成,类似于早期的端到端模型FOTS[19],只是检测模块的回归目标变成了贝塞尔曲线的控制点,以及RoI_Transform部分换成了BezierAlign。
Mask TextSpotterv3网络结构如下图所示:

该模型也是由检测模块 + RoI_Transform + 识别模块构成,但检测模块换成了分割模型,和基于回归的检测模型相比,分割模型能灵活地建模任意形状的文本,同时对文本长度不敏感;RoI_Transform部分直接使用了RoIAlign,利用水平外接框,裁剪出每个RoI文本块,同时对非前景区域进行了zero masking,防止背景干扰;与RoI_Transform配套,识别模块使用了基于attention的识别器。
总结下来,合合信息技术团队认为端到端检测识别算法有如下优点:
-
检测和识别模块进行端到端训练,改善了级联系统的误差累积问题,性能更好
-
通过共享主干网络,端到端检测识别模型的速度更快
-
维护具有相同依赖的统一框架,节省了大量的工程工作
与此同时,印章端到端检测识别算法也存在如下缺点:
-
检测和识别任务所需的训练样本的量级不一样(识别任务需要更多的训练数据),因此对训练数据集的要求更高。
印章序列预测方案(Image2Sequence)
不管是级联模型,还是端到端的检测识别模型,在进行方章识别时都会遇到多方向文本的难题,如下图所示:
真实方章图片中,文本阅读方向可能是从左到右,也可能是从右到左;可能是横排文本,也可能是竖排文本。文本检测模型仅依靠视觉信息,很容易将横排文本检测成竖排文本,同时不同的文本行还需要考虑如何拼接成正确语义顺序的完整字符串。
印章序列预测方案直接抛弃了检测模块:输入经过裁剪的印章图片,模型输出最终的字符串序列,该字符串包含了印章中所有感兴趣文本行:

理论上,序列预测方案可以同时处理所有类型的印章。如果想区分不同的字符串,可在不同字符串之间可插入某个特殊符号(比如'#'),如下图所示:

只需要人为规定印章中不同字符串之间的固定阅读顺序,构造相应的ground truth字符串标签,剩下的就交给模型自己去学习了。针对方章中字符串阅读顺序不固定的问题,本方案可以大大地简化处理流程。
img2seq模型选型没有特别要求,考虑到印章中文字的2D空间布局,可以使用一个基于2D Attention的文本识别模型来完成img2seq任务。为了让img2seq模型能更好地学习全局的上下文特征,推荐使用基于transformer encoder/decoder的识别模型,比如MASTER[12]和SATRN[13],借助其强大的self-attention机制,img2seq模型能获取全局的感受野,以及在解码阶段更好地进行关系建模。
下面以MASTER为例对img2seq模型进行简单介绍,其网络结构如下图所示:
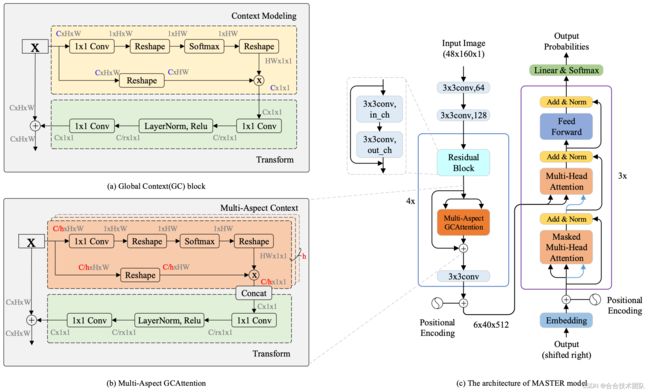 该模型是一个典型的encoder-decoder架构,其中encoder部分是一个定制的,拥有全局感受野的CNN网络,输出一个8倍图的feature map,decoder部分则采用了标准的transformer decoder。同时论文中还使用了memory cache的技术对解码部分进行加速。
该模型是一个典型的encoder-decoder架构,其中encoder部分是一个定制的,拥有全局感受野的CNN网络,输出一个8倍图的feature map,decoder部分则采用了标准的transformer decoder。同时论文中还使用了memory cache的技术对解码部分进行加速。
总结下来,合合信息技术团队认为img2seq模型具备以下的优缺点:
其优点是可以使用单个模型解决不同类型印章的识别问题。部署和维护都相当简单。
其缺点是模型容易过拟合,需要大量的训练数据,这一点可以通过数据合成的方案进行缓解。另外,img2seq模型不能提供每个文本行的位置信息。
感兴趣的小伙伴可以下载体验:
TextinMobile支持Android和iOS平台,Android最低支持4.4,iOS最低支持9
Android下载渠道:小米和华为应用商店;
iOS下载渠道:AppStore应用商店。
下载链接:TextIn - MobileSDK
参考文献
-
Bookstein, Fred L. "Principal warps: Thin-plate splines and the decomposition of deformations." IEEE Transactions on pattern analysis and machine intelligence 11.6 (1989): 567-585.
-
He, Kaiming, et al. "Mask r-cnn." Proceedings of the IEEE international conference on computer vision. 2017.
-
Li, XiaoQian, et al. "Learning to predict more accurate text instances for scene text detection." Neurocomputing 449 (2021): 455-463.
-
Wang, Fangfang, et al. "Textray: Contour-based geometric modeling for arbitrary-shaped scene text detection." Proceedings of the 28th ACM International Conference on Multimedia. 2020.
-
Wang, Wenhai, et al. "Shape robust text detection with progressive scale expansion network." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.
-
Baek, Youngmin, et al. "Character region awareness for text detection." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.
-
Liao, Minghui, et al. "Real-time scene text detection with differentiable binarization." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 34. No. 07. 2020.
-
Zhou, Xinyu, et al. "East: an efficient and accurate scene text detector." Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2017.
-
Shi, Baoguang, Xiang Bai, and Cong Yao. "An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition." IEEE transactions on pattern analysis and machine intelligence 39.11 (2016): 2298-2304.
-
Jaderberg, Max, Karen Simonyan, and Andrew Zisserman. "Spatial transformer networks." Advances in neural information processing systems 28 (2015).
-
Shi, Baoguang, et al. "Aster: An attentional scene text recognizer with flexible rectification." IEEE transactions on pattern analysis and machine intelligence 41.9 (2018): 2035-2048.
-
Li, Hui, et al. "Show, attend and read: A simple and strong baseline for irregular text recognition." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 33. No. 01. 2019.
-
Lu, Ning, et al. "Master: Multi-aspect non-local network for scene text recognition." Pattern Recognition 117 (2021): 107980.
-
Lee, Junyeop, et al. "On recognizing texts of arbitrary shapes with 2D self-attention." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 2020.
-
Fang, Shancheng, et al. "Read like humans: autonomous, bidirectional and iterative language modeling for scene text recognition." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
-
Wang, Yuxin, et al. "From two to one: A new scene text recognizer with visual language modeling network." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
-
Liu, Yuliang, et al. "Abcnet: Real-time scene text spotting with adaptive bezier-curve network." proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020.
-
Liao, Minghui, et al. "Mask textspotter v3: Segmentation proposal network for robust scene text spotting." European Conference on Computer Vision. Springer, Cham, 2020.
-
Liu, Xuebo, et al. "Fots: Fast oriented text spotting with a unified network." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.