【图像分割】Segmenter: Transformer for Semantic Segmentation
声明
不定期更新自己精读的论文,通俗易懂,初级小白也可以理解
涉及范围:深度学习方向,包括 CV、NLP、Data fusion、Digital Twin

论文题目:Segmenter: Transformer for Semantic Segmentation
论文链接:https://arxiv.org/abs/2105.05633
论文代码:https://github.com/rstrudel/segmenter
发表时间:2021年9月
Abstract
图像分割在单个图像块的层次上通常是模糊的,需要上下文信息才能达成一致。本文介绍了一种用于语义切分的转换模型 Segmenter。与基于卷积的方法相比,我们的方法允许在第一层和整个网络中对全局上下文进行建模。我们以最近的视觉转换器(ViT)为基础,将其扩展到语义分割。为此,我们依赖于与图像块对应的输出嵌入,并使用逐点线性解码器或掩码 Transformer 解码器从这些嵌入中获取类标签。
我们利用预先训练的图像分类模型,并表明我们可以在中等大小的数据集上对其进行微调,以进行语义分割。线性解码器已经可以获得很好的结果,但是通过生成类掩码的掩码转换器可以进一步提高性能。我们进行了广泛的消融研究,以显示不同参数的影响,尤其是对于大型模型和小面积贴片,性能更好。Segmenter在语义分割方面取得了很好的效果。它在 Ade20K 和 Pascal 上下文数据集上都优于最先进的技术,在城市景观数据集上具有竞争力。
创新点
1)提出了一种基于 Vision Transformer 的语义分割的新颖方法,该方法不使用卷积,通过设计捕获上下文信息并优于基于 FCN 的方法;
2)提出了一系列具有不同分辨率级别的模型,允许在精度和运行时间之间进行权衡,从最先进的性能到模型具有快速推理和良好性能的模型;
3)提出了一种基于 Transformer 的解码器生成类掩码,其性能优于我们的线性结构,并且可以扩展以执行更一般的图像分割任务;
4)证明了此方法在 ADE20K 和 Pascal Context 数据集上产生了最先进的结果,并且在Cityscapes 上具有竞争力。
Method

Encoder
一幅图像 x ∈ R(H×W×C)被分割成一系列补丁 x = [x1, ..., xN] ∈ R(N×P2×C),其中 (P, P) 是补丁大小,N 是补丁的数量,C 是通道的数量
每一块补丁扁平化成一维向量,然后线性投影到补丁嵌入以产生补丁嵌入序列 x0 = [Ex1, ..., ExN] ∈ R(N×D),为了捕获位置信息,将可学习的位置嵌入 pos = [pos1, ..., posN] ∈ R(N×D)添加到补丁序列中,以获得令牌的结果输入序列 z0 = x0 + pos
由 L 层组成的 Transformer 编码器将具有位置编码的嵌入式补丁的输入序列 z0 = [z0,1, ..., z0,N] 映射到 zL = [zL,1, ..., zL,N],这是一个上下文化编码序列,包含解码器使用的丰富语义信息
Decoder
将补丁编码序列 zL 解码为分割图 s ∈ R(h × w × k),其中 k 是类的数量。解码器学习将来自编码器的补丁级编码映射到补丁级类分数
Linear 将逐点线性层应用于补丁编码 zL,以产生补丁级类标记 Z-lin ∈ R(n × k)。然后将序列重塑为 2D 特征图 S-lin ∈ R(H/p × w/p × k),并对其进行双上采样,以达到原始图像大小 s。然后在维度上应用 softmax 以获得最终的分割图
Mask Transformer 对于基于 Transformer 的解码器,我们引入了一组 K 个可学习的类嵌入cls = [cls1,...,clsK] ∈ R(k × d),其中 K 是类的数量。每个类嵌入都是随机初始化的,并分配给单个语义类。它将用于生成类掩码。类嵌入 cls 由解码器与补丁编码 zL 联合处理
Experiments
Datasets and metrics
数据集
ADE20K、Pascal Context、Cityscapes
指标
所有类别的平均交集比联合(mIoU)
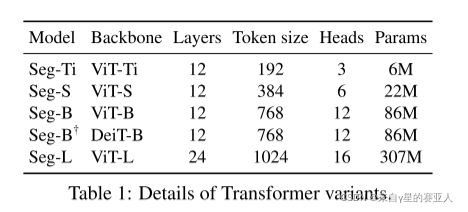
实验目标:Transformer models 对比
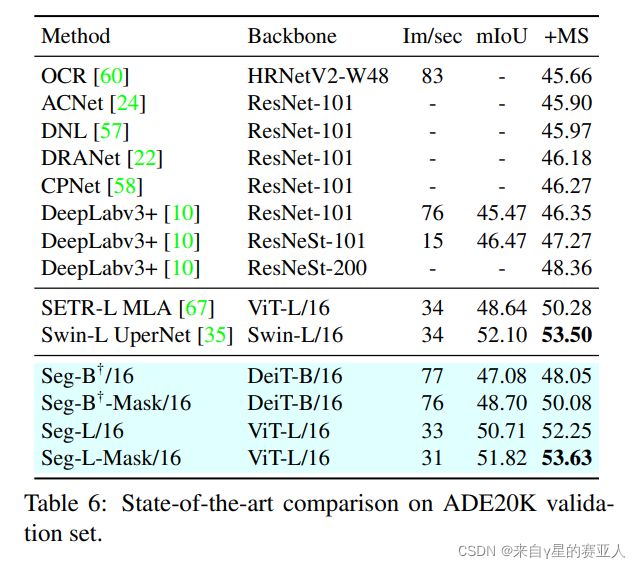
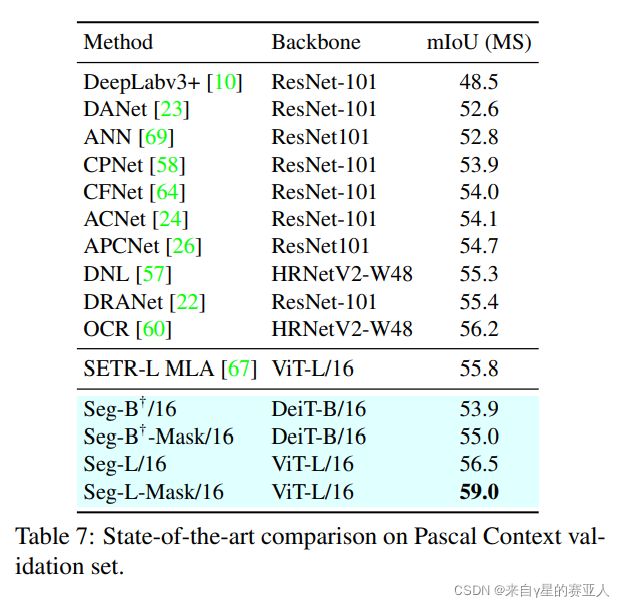
实验目标:ADE20K、Pascal Context、Cityscapes 验证集的最新方法比较
实验结果: