机器学习实验——BP神经网络之手写数字识别
机器学习实验——BP神经网络之手写数字识别
手写数字识别可以说是神经网络入门必学的一个经典案例,我很清楚各位大佬都已经对各种神经网络的知识烂熟于心,所以这篇文章主要是分享一下我的一些感悟和想法,各位大佬看个乐。
数据集
手写数字的数据集取自Mnist,5000个训练样本
网络结构
把20×20的样本图像的每一个像素作为一个输入神经元,所以输入层的维度是400,由于手写数字识别的任务比较简单,所以只用一层隐藏层,这个简单的网络由输入层(1) + 隐藏层(1) + 输出层(1)组成,输出层有10个神经元。
400个输入层神经元对应了20×20输入图像的每一个像素,神经元中的数字就是像素的灰度值,我们更习惯称之为“激活值”,激活值越大越接近1,点着就越亮,0表示纯黑1表示纯白。
输出层有10个神经元,代表0到9这十个数字,也一样有激活值,对应着模型认为输入图像对应着哪个数字的可能性
我们凭什么觉得这些层状结构可以做到只能判断?——当我们人类在识别数字的时候,我们其实在组合数字的各个部件,假设有两层隐藏层,我们希望倒数第二层中的各个神经元能分别对应一个笔画部件,输入图像包含对应部件时对应神经元激活值就会接近1,很亮。 接下来我们可以再拆,我们希望第二层的各神经元能对应各种各样的短边。
我们需要设计一个机制, 能够把像素拼成短边,把短边拼成笔画部件,把部件拼成数字。
比如关注第二层的一个神经元,我们来设计让他能够正确识别某个上方区域是否存在一条边,这个小小的区域我们就暂且称为b吧,当b内有短边也就是说这个区域里的像素点灰度值都挺高,挺亮的,那么按理说这个神经元也应该很亮,为了达到这个目的,我们把b区域的权重赋为正,其他地方全为0,这样子加权和的结果就只会累加我们关注的区域b的像素值了,然后只需要给周围一圈的像素赋予负的权重就能拿来识别b里的短边了。
加权和的结果需要转成0-1之间的激活值,那就需要激活函数(sigmoid/ReLU)来把其压缩到0-1的范围内,其实就是评估系统觉得这个区域存在短边的可能性有多大,对加权和有多正的打分
有时即使加权和大于0我也不想把神经元点亮,我想有把握一些,我希望当其加权和大于10才让那个神经元激发,这时就需要加上一个偏置bias,保证不能随随便便过了0就激发
总之,权重侧面告诉了我们第二层神经元都关注的是什么样的短边和像素图案,偏置告诉我们加权和得有多大才能让神经元的激发有意义。
隐藏层的25个神经元中的每一个都会连着输入层的400条线
训练/学习
当我们讨论机器如何学习时,我们其实在说电脑应该如何设置这一大坨的数字参数。
每一层的每个神经元都与上一层的所有神经元相连接,权重表示连接强弱,或者说影响的显著水平。偏置表示神经元有多容易被激活。一开始初始化的权重和偏置,输出层的情况绝对一团糟,该亮的不亮,不该亮的都亮。
我需要定义一个loss函数告诉电脑,你大错特错了。完全正确的输出激活值应该是只有一个神经元激活值是1,其他全是0,更具体的说你需要对那些错误的激活值狠狠地惩罚(平方差/交叉熵),这时只是针对单个训练样本。
考虑手上5000个训练样本中loss的平均值,来衡量这个模型有多糟糕,电脑该有多愧疚,这个就叫做代价,取决于网络对5000个样本的综合表现
网络中所有权重和偏置组成了代价函数的参数,代价值表示这些权重和偏置有多差。但是电脑想的是你只是告诉我它很糟糕没用啊,你得告诉我怎么调整它们才能不那么糟糕,我们就告诉电脑,用梯度下降法。函数的梯度指出了函数的最陡增长方向,沿着梯度反方向自然下降最快,这么海量参数的负梯度正是指出了具体如何改变每一个参数才能让代价下降得最快,走了一步之后,5000个样本输出层的激活值更接近期待的真实结果。
学习实际上就是让代价函数最小,代价函数非常有必要是平滑连续的,这样才能一次挪一点找到局部最小,这也解释了为什么人工神经元的激活值是连续的,而非像生物学神经元那样要么激活要么不激活。
负梯度中每一项的正负号很明显是在告诉我们这一项该调大还是调小,更重要的是每一项的相对大小在告诉我们改变哪个值的影响更大,可以理解为相对重要度,反映了改变哪个参数性价比最高。总结:代价函数的梯度能告诉我们如何调整参数才可以让代价改变得最快,也可以理解为改变哪些参数影响力最大性价比最高。
还记得吗,我上面说隐藏层能识别出短边和部件,但是实际上网络真的有这么做吗?其实我骗了你们,它并没有这么做,与其说识别出各种散落的短边,实际上看起来没有什么规律,看不出来是想要识别什么图案。看个最明显的例子,把一个混乱随机的图像输入进去,和任何数字八字没一撇,如果网络很智能最后输出层的激活值应该是要么都暗着,要么都亮了,但是结果却是这个逼总是很自信地给你一个没道理的回答,就像它能把一张5确信是数字5一样,它也可能把一张随机噪声图确信是数字5。 究其原因,我们试着当一次电脑,当一次这个神经网络,从我的视角看整个宇宙都是由神经元内清洗定义的静止数字组成的,我能很准地识别出数字是因为按甲方的标准发现代价很小,那我就很自信了,我就很确信我判断对了,也就是说甲方的代价函数只会促使我对最后的判断有绝对的自信,管你是正经的数字图还是随机噪声图,反正在我眼里就是一大坨数字,所以我最后一定会很自信地给你一个答案。
反向传播
所谓学习就是我们要找到特定的权重偏置,从而使一个代价函数最小化,
怎么计算这个梯度呢,那就涉及反向传播算法BP
现在我们关注一个训练样本——一张数字“2”, 这个时候网络没训练好,输出层的激活值就很随机,也许会出现0.5 0.8 0.6等等亮了好几个,我们希望的是10个神经元中只有一个很亮(2对应的神经元),其他数字对应的神经元都很暗也就是激活值几乎为0。 那么我们希望改变权重和偏置之后,2代表的神经元激活值变大,其他神经元的激活值变小。 每个神经元对如何改变倒数第二层都有自己的想法,把10个神经元的期待的改变加起来得到的一串对倒数第二层改动的变化量,作为对如何改变倒数第二层神经元的指示。重复这个过程,一直循环到第一层输入层,这其实就在实现反向传播。
放眼大局,这只是那个“2”期待的,需要关注所有训练样本的需求, 对5000个样本都需要进行反向传播,记录下每个样本想要怎样修改权重和偏置,最后取一个平均值。
顺带说一下,如果梯度下降的每一步都要用上每一个训练样本计算的话,很费时,幸好我们只有5000个样本,所以没关系,但是到了真正的项目里一般会分成很多组minibatch,每个minibatch包含几百到几千个样本,算出这个minibatch下降的一步,这虽然不是代价函数真正的梯度,但都是一个不错的近似,最重要的是计算量减轻很多,通俗地说,minibatch就像一个醉汉迷迷糊糊地溜下山,但起码步伐很快,而不是像原来那样一个清醒理性的人,精打细算计算好下山的方向,小心谨慎地迈着小步下山。这是一个技巧,它有个好听的名字叫做随机梯度下降。
代码用到的公式

实验代码
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
def softmax(Z):
row_max = np.max(Z, axis=1) # 每行的最大值 axis=1是每一行的所有元素之和
row_max = row_max.reshape(-1, 1)
Z = Z - row_max
Z_exp = np.exp(Z)
Z_exp_sum = np.sum(Z_exp, axis=1, keepdims=True)
return Z_exp / Z_exp_sum
def sigmoid(x):
return 1. / (1 + np.exp(-x))
def onehotEncoder(Y, ny): # 转one-hot编码
return np.eye(ny)[Y]
# 初始化权重和偏置
def initWeights(M): # M = [400, 25, 10] [输入层维度 隐藏层维度 输出层维度]
l = len(M)
W = []
B = []
for i in range(1, l): # i = 1,2
W.append(np.random.randn(M[i-1], M[i])) # 标准正态分布
B.append(np.zeros([1, M[i]]))
# W = [(400,25),(25,10)] B = [(1,25),(1,10)]
return W, B
# 前向传播
def networkForward(X, W, B):
l = len(W)
# [A[0],A[1],A[2]] 计算每一层神经元的激活值
A = [None for i in range(l+1)]
A[0] = X # (5000,400) 输入层
A[1] = sigmoid(np.dot(A[0], W[0]) + B[0]) # (5000,25) 隐藏层
A[2] = softmax(np.dot(A[1], W[1]) + B[1]) # (5000,10) 输出层 Y_hat
return A
# 反向传播
def networkBackward(Y, A, W):
l = len(W)
dW = [None for i in range(l)]
dB = [None for i in range(l)]
dZ = [None for i in range(l)]
dZ[1] = A[2] - Y # (5000,10)
dW[1] = A[1].T @ dZ[1] # (25,10)
dB[1] = 1/n * np.sum(dZ[1], axis=0) # (1,10)
dZ[0] = A[1] * (1-A[1]) * np.dot(dZ[1], W[1].T) # (5000,25)
dW[0] = A[0].T @ dZ[0] # (400,25)
dB[0] = 1/n * np.sum(dZ[0], axis=0)
return dW, dB
# 更新权重和偏置
def updateWeights(W, B, dW, dB, lr):
l = len(W)
# 梯度下降法
for i in range(l):
W[i] = W[i] - lr*dW[i]
B[i] = B[i] - lr*dB[i]
return W, B
# 计算代价
def cost(A_l, Y, W):
n = Y.shape[0] # (5000,10) n=5000
c = -np.sum(Y*np.log(A_l + 1e-5)) / n
return c
# 训练网络
def train(X, Y, M, lr = 0.1, iterations = 3000): # 默认
costs = []
W, B = initWeights(M) # 随机初始化
# 迭代:前向传播 - 算代价 - 反向传播 - 更新参数
for i in range(iterations):
A = networkForward(X, W, B)
c = cost(A[-1], Y, W) # a[L] = Y_hat
dW, dB = networkBackward(Y, A, W)
W, B = updateWeights(W, B, dW, dB, lr)
if i % 100 == 0:
print("Cost after iteration %i: %f" %(i, c))
costs.append(c)
return W, B, costs
def predict(X, W, B, Y):
Y_out = np.zeros([X.shape[0], Y.shape[1]])
A = networkForward(X, W, B)
idx = np.argmax(A[-1], axis=1)
Y_out[range(Y.shape[0]), idx] = 1
return Y_out
def NNtest(Y, X, W, B):
Y_out = predict(X, W, B, Y)
acc = np.sum(Y_out*Y) / Y.shape[0]
print("Training accuracy is: %f" %(acc))
return acc
iterations = 3500
lr = 0.001
data = np.load("data.npy") # (5000,401)
# 5000个样本 输入400维 10分类问题
X = data[:,:-1] # (5000,400)
Y = data[:,-1].astype(np.int32) # (5000,1)
(n, m) = X.shape # n = 5000 m = 400
Y = onehotEncoder(Y, 10) # (5000,10)
'''400=20*20 其实是Mnist书写数字识别的'''
M = [400, 25, 10]
W, B, costs = train(X, Y, M, lr, iterations)
plt.figure()
plt.plot(range(len(costs)), costs)
plt.show()
NNtest(Y, X, W, B)
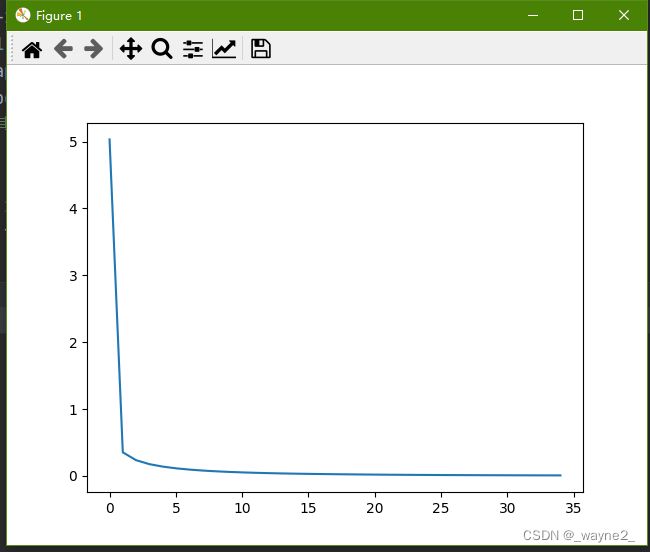
顺便说一下,一开始我的学习率使用默认的0.1,迭代次数是默认的3000。把实验给的框架补充完毕后运行报错了,都是一些莫名其妙的溢出和除零错误,按着提示改来改去,但是却好似拆东墙补西墙,代价越训练越高,或者居高不下,一直持平不下降。最终已经十分无奈的时候,随手把学习率调成0.001,惊奇地发现所有问题一口气解决了,损失下降得很快,用训练集作为测试集,发现识别准确率达到100%(当然这绝对不科学,况且训练样本很少,但作为一个实验这就足够了)结果如下:


代价函数的变化: