简单实现,pytorch+全连接网络+MNIST识别
目录
net.py:
train.py
test.py
总结:
在这里简单实现一下基于全连接层的手写体识别,一下是代码部分
定义三层网络结构,在这里设定了三个网络,
第一个 SimpleNet,单纯就是三层网络
第二个 Activation_Net,在每层网络输出后面添加了激活函数
第三个 Batch_Net, 在每层网络输出后经过BatchNorm1d(批标准化),在经过激活函数
注意:
net.py:
# 开发人员: ***
# 开发时间: 2022/7/22 20:48
# 功能作用: 未知
import torch
import torch.nn as nn
from torch.autograd import Variable
from torch import optim
#建立简单的三层全连接神经网络
class SimpleNet(nn.Module):
def __init__(self,in_dim, out_dim, n_hidden_1, n_hidden_2):
super(SimpleNet, self).__init__()
self.layer1 = nn.Linear(in_dim, n_hidden_1)
self.layer2 = nn.Linear(n_hidden_1, n_hidden_2)
self.layer3 = nn.Linear(n_hidden_2, out_dim)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
class Activation_Net(nn.Module):
def __init__(self, in_dim, out_dim, n_hidden_1, n_hidden_2):
super(Activation_Net, self).__init__()
self.layer1 = nn.Sequential(
nn.Linear(in_dim, n_hidden_1),
nn.ReLU(True)
)
self.layer2 = nn.Sequential(
nn.Linear(n_hidden_1, n_hidden_2),
nn.ReLU(True)
)
self.layer3 = nn.Linear(n_hidden_2, out_dim)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
##加batch的话,能加快收敛
class Batch_Net(nn.Module):
def __init__(self, in_dim, out_dim, n_hidden_1, n_hidden_2):
super(Batch_Net, self).__init__()
self.layer1 = nn.Sequential(
nn.Linear(in_dim, n_hidden_1),
nn.BatchNorm1d(n_hidden_1),
nn.ReLU(True)
)
self.layer2 = nn.Sequential(
nn.Linear(n_hidden_1, n_hidden_2),
nn.BatchNorm1d(n_hidden_2),
nn.ReLU(True)
)
self.layer3 = nn.Linear(n_hidden_2, out_dim)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
设定好网络层后,就编写训练层
因为数据集我这里已经下载完了,所以将download改为了False,若为下载则,改为TRUE
train_dataset =mnist.MNIST('./data', train=True, transform=data_tf, download=False)
test_dataset =mnist.MNIST('./data', train=False, transform=data_tf, download=False)
train.py
import torch
import time
import tqdm
import numpy as np
import torch.nn as nn
from torch import optim
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.datasets import mnist # 导入 pytorch 内置的 mnist 数据
import matplotlib.pyplot as plt
import net
##设定一些数据
batch_size = 32
learning_rate = 1e-2
num_epoches = 5
##将图片转为Tensor格式后标准化,减去均值,再除以方差
data_tf = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]) ##因为是灰度值图,所以是单通道
# transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5]) ##因为是彩色图,所以是san通道
])
train_dataset =mnist.MNIST('./data', train=True, transform=data_tf, download=False)
test_dataset =mnist.MNIST('./data', train=False, transform=data_tf, download=False)
##设置迭代器,shuffle询问是否将数据打乱,意思是产生batch_size个数据
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
##导入网络,定义损失函数和优化函数
model = net.Batch_Net(28*28, 10, 300, 100)
if torch.cuda.is_available():
model.cuda()
criterion = nn.CrossEntropyLoss() ##交叉煽函数
##此函数,好像是输入【通道数,类别种类的概率】,标签【通道数,所属类别数字】
optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=0.8)
# 开始训练
losses_men = []
acces_men = []
start = time.time()
for epoche in range(num_epoches):
train_loss = 0
train_acc = 0
print()
print(f"第 {epoche + 1} / {num_epoches} 个 epoche。。。")
for train_img, train_label in tqdm.tqdm(train_loader):
## train_loader的长度为1875,意为60000图片以32为一组分为1875组
if torch.cuda.is_available():
##将 train_img【32,1,28,28】 变成 【32,1,786】这样才能输入进入模型
train_img = torch.reshape(train_img, (batch_size, 1, -1))
train_img = Variable(train_img).cuda()
train_label = Variable(train_label).cuda()
else:
train_img = torch.reshape(train_img, (batch_size, 1, -1))
train_img = Variable(train_img)
train_label = Variable(train_label)
## train_img : 【32,1,786】
## 要变成 : 【32,786】
train_img = train_img.squeeze(1)
# 前向传播
out = model(train_img)
loss = criterion(out, train_label)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# print("***")
# print(train_img.shape)
# print(len(test_loader))
# 记录误差
train_loss += loss.item()
# 计算分类的准确率
_, idx_max = out.max(1)
num_correct = (idx_max == train_label ).sum().item() ##计算每次batch_size正确的个数
acc = num_correct / train_img.shape[0] ##正确率
train_acc +=acc
losses_men.append(train_loss / len(train_loader)) #这里计算的是平均损失函数
acces_men.append(train_acc / len(train_loader))
print()
print("损失率为: ", losses_men)
print("正确率为: ", acces_men)
torch.save(model.state_dict(), './params/simple.pth')
print("参数保存成功")
during = time.time() - start
print()
print('During Time: {:.3f} s'.format(during))
###画出LOSS曲线和准确率曲线
plt.plot(np.arange(len(losses_men)), losses_men, label ='train loss')
plt.plot(np.arange(len(acces_men)), acces_men, label ='train acc')
plt.show()训练好的模型参数保存在文件夹params下,如果没有这个文件夹的话,需自己创建,否则报错
接下来是测试,
test.py
import torch
import time
import tqdm
import numpy as np
import torch.nn as nn
from torch import optim
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.datasets import mnist # 导入 pytorch 内置的 mnist 数据
import matplotlib.pyplot as plt
import three_MNIST
model.load_state_dict(torch.load('./params/simple.pth'))
###测试
##初始化
model.eval()
eval_loss = 0
eval_acc = 0
test_loss = 0
test_acc = 0
for data in test_loader:
img, label = data
img = img.view(img.size(0), -1)
if torch.cuda.is_available():
img = Variable(img).cuda()
label = Variable(label).cuda()
else:
img = Variable(img)
label = Variable(label)
out = model(img)
loss = criterion(out, label)
# 记录误差
test_loss += loss.item()
# 记录准确率
_, pred = out.max(1)
num_correct = (pred == label).sum().item()
acc = num_correct / label.shape[0]
test_acc += acc
eval_loss = test_loss / len(test_loader)
eval_acc = test_acc / len(test_loader)
print("损失率为: ",eval_loss)
print("正确率为: ",eval_acc)总结:
本次只用了5轮Epoche进行训练,网络是三层结构,三种网络
其实从准确率和损失率来看,SimpleNet < Activation_Net < Batch_Net
| NET / epoch | 1 | 2 | 3 | 4 | 5 |
| SimpleNet | 0.875 | 0.900 | 0.905 | 0.90788 | 0.909783 |
| Activation_Net | 0.883 | 0.949 | 0.964 | 0.972 | 0.978 |
| Batch_Net | 0.934 | 0.972 | 0.985 | 0.993 | 0.997 |
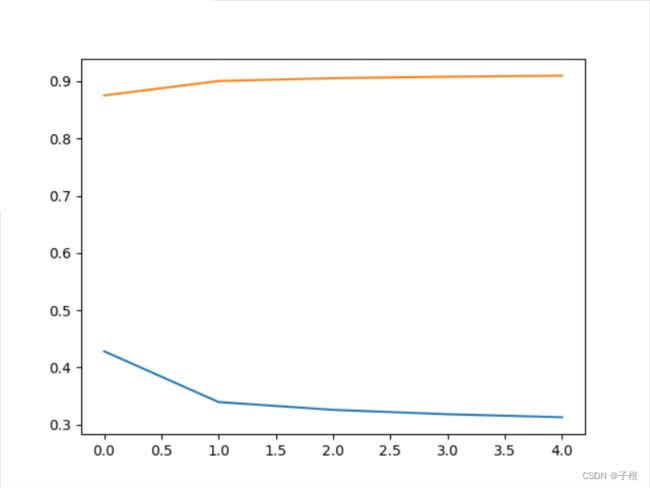 |
 |
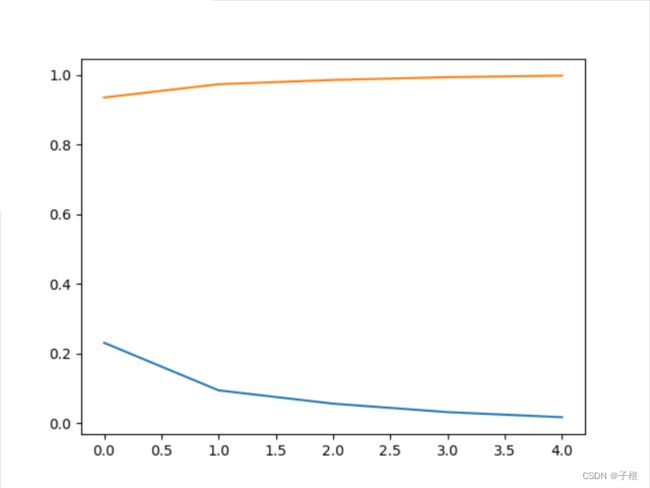 |
| SimpleNet | Activation_Net | Batch_Net |
可以看出,正确率很高了