BDD100K:大规模不同驾驶视频数据库
BDD100K:大规模不同驾驶视频数据库
TL;博士,我们释放了最大和最多样化的驾驶视频数据集与丰富 注释叫做BDD100K。 你现在可以访问数据的研究http://bdd-data.berkeley.edu。 我们有 最近发布的一个arXiv 报告在上面。 还有时间来参与我们2018年CVPR挑战!
大规模、多样化,开车,视频:选择四个
自主驾驶将改变在每一个社区的生活。 然而, 最近的事件表明,目前还不清楚如何人为的感知系统 避免甚至看似显而易见的错误当驱动系统的部署 现实世界。 作为计算机视觉的研究人员,我们探索感兴趣 前沿的感知算法自动驾驶更安全。 设计 和测试潜在的算法,我们想要使用的所有信息 从数据收集到一个真正的驾驶平台。 这些数据有四个专业 属性:大规模、多样化,在街上捕捉, 时间信息。 数据的多样性来测试尤为重要 感知算法的鲁棒性。 然而,当前只能打开数据集 封面上面描述的属性的一个子集。 因此,的帮助下Nexar,我们释放BDD100K 数据库,数据库是最大和最多样化的开放驾驶视频数据集 计算机视觉研究。 这个项目组织和赞助伯克利DeepDrive行业 财团,探讨先进的计算机视觉技术 汽车应用程序和机器学习。
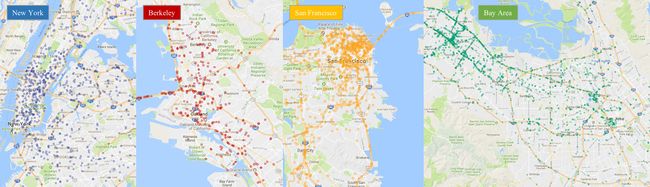
一个随机的位置视频子集。
正如名字所表明的,我们的数据集包含100000个视频。 每个视频 长约40秒,720 p和30 fps。 视频也有GPS / IMU 信息记录的手机显示粗糙的行驶轨迹。 我们的 视频收集来自不同地点在美国,如图所示 上面的图。 我们的数据库涵盖了不同的天气条件,包括 阳光,阴天,下雨,一天中不同时段包括白天 和夜间。 下面的表总结了比较与先前的数据集, 显示我们的数据集是更大、更多样化。
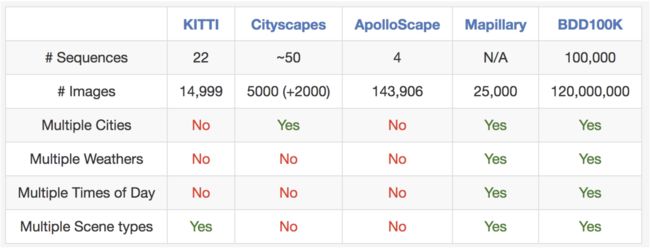
比较与其他街景数据集。 很难比较 #之间的图像数据集,但我们这里作为一个粗略的参考列表。 #序列多样性列表作为参考,但不同的数据集有不同的序列长度。
视频和他们的轨迹的模仿学习是非常有用的 推动政策,如在我们的CVPR 2017 纸。 促进计算机视觉研究大型数据集,我们 还提供基本的注释在视频关键帧,详细的在未来 部分。 你现在可以下载数据和注释http://bdd-data.berkeley.edu。
注释
我们样品从每个视频关键帧在10秒,并提供注释 对于那些关键帧。 他们在几个层次:标记图像标记,道路 车道标记对象边界框,可行驶的领域,和帧实例 分割。 这些注释会帮助我们理解的多样性 数据和对象统计在不同类型的场景。 我们将讨论 标签的过程在不同的博客。 更多的信息 注释可以在我们找到arXiv 报告。
概述我们的注释。
道路目标检测
我们标签对象边界框的对象通常出现在马路上 所有的100000个关键帧的分布对象和理解 他们的位置。 以下条形图显示对象计数。 也有 其他方法来玩统计在我们的注释。 例如,我们可以 比较对象计数在不同天气条件下或在不同 类型的场景。 这个图表还显示出现在不同的一组对象 我们的数据集,数据集的规模——超过100万辆汽车。 的 读者应该提醒,这些都是不同的对象和不同 外表和背景。
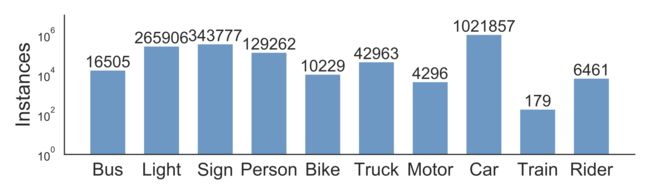
不同类型的对象的统计信息。
我们的数据集也适合学习一些特定的领域。 例如, 如果你有兴趣检测和避免行人在街上,你 也有一个理由去学习我们的数据集,因为它包含更多的行人 比之前的专业数据集实例如下表所示。

比较与其他行人有关训练集规模的数据集。
车道标记
说明人类司机车道标记是重要的道路。 他们也 行驶方向和本地化的关键线索自动驾驶 系统当GPS或地图没有准确的全球覆盖。 我们把 车道标记分为两类基于他们如何指导的车辆 车道。 垂直车道标记(在下面的数据用红色标注) 标记沿着车道的行驶方向。 平行车道 下面的数字标记(标记为蓝色)指出的那些 车道的车辆停下来。 我们还提供属性的标记 的固体与破灭和双与非单身。
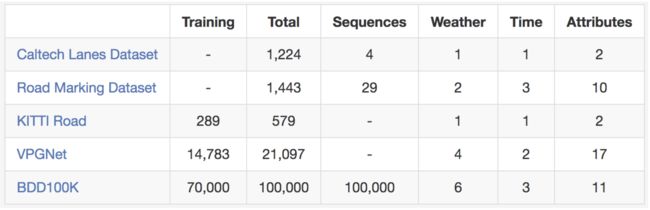
如果你准备尝试车道标记预测算法,请看看 没有进一步。 这是与现有的车道标记数据集。
可行驶的区域
我们是否能开车在路上不仅取决于路面标志和交通 设备。 它还依赖于复杂的交互与其他对象 共享的道路。 最后,重要的是要理解哪些区域 驱动的。 探讨这个问题,我们还提供细分注释 可行驶的区域,如下所示。 我们将可行驶的区域划分为两个 分类基于自我车辆的轨迹:直接可行驶的, 替代可行驶的。 直接可行驶的,用红色标注的,意味着自我的车辆 道路优先级和可以继续开车。 替代可行驶的, 标记为蓝色,意味着自我车辆可以开车,但是必须 谨慎自道路优先可能属于其他车辆。
帧分割
它已被证明在城市数据集这枚好实例 分割可以大大提高密度预测和研究对象 检测,广泛的计算机视觉应用的支柱。 作为 我们的视频是在一个不同的领域,我们提供实例分割 注释也由不同的数据集相对比较领域转变。 它可以是昂贵的和艰苦的获得进行像素级分割。 幸运的是,用我们自己的标记工具,可以降低标签成本 50%。 最后,我们标签的一个子集10 k图像帧实例 分割。 我们的标签设置兼容培训注释 城市,让它更容易研究领域数据集之间的转变。

开车的挑战
我们正在举办三个 挑战2018年CVPR研讨会自主驾驶基于我们的数据: 路对象检测、可行驶的区域预测和域的改编 语义分割。 检测算法来找到所有的任务需要 目标对象在我们的测试图像和可行驶的区域预测需要 细分领域的汽车可以开车。 领域适应气候变化的测试数据 在中国收集。 系统因此挑战模式学到的 我们在拥挤的街道工作在北京,中国。 你可以提交你的结果 现在后登录我们的 在线提交门户网站。 一定要看看我们的工具箱启动你的 参与。
加入我们CVPR车间挑战索取现金奖励! ! !
未来的工作
感知系统自动驾驶绝不是只有单眼 视频。 它可能还包括全景和立体视频以及其他类型 传感器的激光雷达和雷达。 我们希望提供和研究这些 多模传感器数据在不久的将来。
参考链接
加州理工学院, KITTI, CityPerson, 城市风光, ApolloScape, Mapillary, 加州理工学院车道数据集,道路标记数据集,KITTI路, VPGNet