酒店评论情感分类
文章目录
- 代码实践
-
- 读取数据
- 数据预处理
-
- 数据划分
- 文档转化向量
-
- 读取停用词
- 分词
- 文本向量表示
- 训练集和测试集划分
- 特征选择
- 构建不同的分类器
- 模型比较
- 结果分析
- 知识点补充
-
- 特征工程总结
- SVC和LinearSVC的比较
- 完整数据和代码
- 参考资料
代码实践
读取数据
读入酒店评论数据,统计正面评价和负面评价,共计9999条评论数据
import numpy as np
import os
from time import time
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import jieba
from sklearn.datasets import fetch_20newsgroups#引入新闻数据包
from sklearn.feature_extraction.text import TfidfVectorizer#做tfidf编码
from sklearn.feature_selection import SelectKBest, chi2#卡方检验——特征筛选
from sklearn.linear_model import RidgeClassifier
from sklearn.svm import LinearSVC,SVC
from sklearn.naive_bayes import MultinomialNB, BernoulliNB #引入多项式和伯努利的贝叶斯
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
# # SMOTE上采样
from sklearn.model_selection import train_test_split
# from imblearn.over_sampling import SMOTE
from collections import Counter
from sklearn import metrics
plt.rcParams['font.sans-serif'] = ['SimHei']
# # 数据路径
os.chdir('D:\codePractice\data\\ChnSentiCorp_htl_unba_10000\\')
# 读取正面评论
positive = pd.read_csv('./pos.csv')
# 增加极性标签
positive['pos_neg']=1
# 正面评论数据统计
pos_len = len(positive)
print("积极评论",pos_len,"条")
# positive.head()
# positive.info()
negative = pd.read_csv('./neg.csv')
# 增加极性标签
negative['pos_neg']=-1
# 负面评论
neg_len = len(negative)
print("消极评论",neg_len,"条")
# negative.head()
# negative.info()
# 合并评论
comments = pd.concat([positive,negative])
print(comments.info())
# 9899条
comments.head()
积极评论 6900 条
消极评论 2999 条
Int64Index: 9899 entries, 0 to 2998
Data columns (total 2 columns):
comment 9899 non-null object
pos_neg 9899 non-null int64
dtypes: int64(1), object(1)
memory usage: 232.0+ KB
None
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| comment | pos_neg | |
|---|---|---|
| 0 | 距离川沙公路较近,但是公交指示不对,如果是"蔡陆线"的话,会非常麻烦.建议用别的路线.房间较... | 1 |
| 1 | 商务大床房,房间很大,床有2M宽,整体感觉经济实惠不错! | 1 |
| 2 | 早餐太差,无论去多少人,那边也不加食品的。酒店应该重视一下这个问题了。房间本身很好。 | 1 |
| 3 | 宾馆在小街道上,不大好找,但还好北京热心同胞很多~宾馆设施跟介绍的差不多,房间很小,确实挺小... | 1 |
| 4 | CBD中心,周围没什么店铺,说5星有点勉强.不知道为什么卫生间没有电吹风 | 1 |
数据预处理
数据划分
将数据划为特征x和标签y
# # # 样本不均衡
x = pd.DataFrame(comments.comment)
y = comments.pos_neg
# 查看SMOTE之前的数据分布
print("总评论中的正负样本:",Counter(y))
x.head()
总评论中的正负样本: Counter({1: 6900, -1: 2999})
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| comment | |
|---|---|
| 0 | 距离川沙公路较近,但是公交指示不对,如果是"蔡陆线"的话,会非常麻烦.建议用别的路线.房间较... |
| 1 | 商务大床房,房间很大,床有2M宽,整体感觉经济实惠不错! |
| 2 | 早餐太差,无论去多少人,那边也不加食品的。酒店应该重视一下这个问题了。房间本身很好。 |
| 3 | 宾馆在小街道上,不大好找,但还好北京热心同胞很多~宾馆设施跟介绍的差不多,房间很小,确实挺小... |
| 4 | CBD中心,周围没什么店铺,说5星有点勉强.不知道为什么卫生间没有电吹风 |
文档转化向量
读取停用词
读取停用词词典,共计1234个停用词。
# 读取停用词词库
def get_stopwords(stop_words_file):
with open(stop_words_file,'r',encoding='utf-8') as f:
stopwords = f.read()
stopwords_list = stopwords.split('\n')
custom_stopwords_list = [i for i in stopwords_list]
return custom_stopwords_list
# 中科院停用词
stop_words_file ="./stopWord.txt"
# 读取停用词
stopwords = get_stopwords(stop_words_file)[1:]
# 统计停用词个数
print("一共含有%d个停用词" % len(stopwords))
# 查看前10个停用词
stopwords[-10:]
一共含有1207个停用词
['如下', '汝', '三番两次', '三番五次', '三天两头', '瑟瑟', '沙沙', '上', '上来', '上去']
分词
结巴分词,并去除英文和数字
import re
# 分词预处理
def clean_text(line):
if line!=' ':
line = line.strip()
# 去除英文和数字
line = re.sub("[a-zA-Z0-9]","",line)
# 去除文本中的中文符号和英文符号
line = re.sub("[\s+\.\,\!\/_,$%^*(+\"\';:“”.]+|[+——!,。??、~@#¥%……&*()]+", "", line)
return line
else:
return "Empyt Line."
# 结巴分词
def chinese_word_cut(line):
line = clean_text(line)
segList = jieba.cut(line,cut_all=False)
segSentence = ''
for word in segList:
if word!='\t' and (word not in stopwords):
segSentence += (word+" ")
return segSentence.strip()
# 评论分词
x['cutted_comment'] = x.comment.apply(chinese_word_cut)
print(x.shape)
# (9899, 2)
# # 分词结果
x.cutted_comment[:5]
## BOW TFIDF WORD2VECh获取特征
(9899, 2)
0 距离 川沙 公路 较近 公交 指示 蔡陆线 麻烦 建议 路线 房间 较为简单
1 商务 大床 房 房间 很大 床有 宽 整体 感觉 经济 实惠 不错
2 早餐 太 差 人 不加 食品 酒店 应该 重视 一下 问题 房间 好
3 宾馆 小 街道 不大好 找 还好 北京 热心 同胞 宾馆 设施 介绍 房间 很小 确实 挺 ...
4 中心 周围 没什么 店铺 说星 有点 勉强 知道 卫生间 电吹风
Name: cutted_comment, dtype: object
文本向量表示
利用词袋模型将文本向量化。
- 利用停用词过滤;
- max_df = 0.9设置为0.9,即一个词语在90%以上的文件中出现则不能作为特征词语;
- min_df=3设置为3,即一个词语最少在3个文件中出现过才能当作特征词语;
from sklearn.feature_extraction.text import CountVectorizer
# 过滤部分特征
# 最大比例
max_df = 0.9
# 最小支持度
min_df = 3
# 加入token
token_pattern = u'(?u)\\b[^\\d\\W]\\w+\\b'
# 构建cbow向量
vectorizer = CountVectorizer(min_df = min_df,
token_pattern=token_pattern,
stop_words=frozenset(stopwords))
训练集和测试集划分
按照8:2将数据集划为为训练集和测试集
# 数据集划分
x_train,x_test,y_train,y_test = train_test_split(x,y,
test_size=0.2,
random_state=0)
# 训练集和测试集
x_train = x_train['cutted_comment']
x_test = x_test['cutted_comment']
# 文本向量化
train_x = vectorizer.fit_transform(x_train)
test_x = vectorizer.transform(x_test)
# # 训练集
x_train[:5]
print("训练集中的正负样本:",Counter(y_train))
print("训练集样本个数:%d,特征个数:%d" % train_x.shape)
# # 测试集
x_test[:5]
print("测试集中的正负样本:",Counter(y_test))
print("测试集样本个数:%d,特征个数:%d\n" % test_x.shape)
feature_names = np.asarray(vectorizer.get_feature_names())
print("特征筛选前特征个数:{}\n词汇:{}".format(len(feature_names),feature_names))
# # 训练文本
x_train.head()
训练集中的正负样本: Counter({1: 5516, -1: 2403})
训练集样本个数:7919,特征个数:8347
测试集中的正负样本: Counter({1: 1384, -1: 596})
测试集样本个数:1980,特征个数:8347
特征筛选前特征个数:8347
词汇:['一一' '一下' '一下下' ... '龙卡' '龙头' '龙门石窟']
5279 交通 便利 环境 尚可 提供 早餐 比较 好 旧 一点 总体 说 令人满意
2929 喜欢 下次
5496 六号楼 龙岩 地区 目前 最好 宾馆 硬件 新 服务 感觉 不错 美中不足 暖气 不行 晚上...
5253 白天 恐龙 园 游玩 过后 月 号 富 商贸 酒店 住 一晚 住 元 高级 双床 房 最 普...
3078 总体 感觉 比较 好 环境 一点 吵 挨近 一条 高架路 服务态度 好
Name: cutted_comment, dtype: object
特征选择
上一步可以看到,通过停用词和min_df、max_df的筛选之后,特征词语有8347个,为了降维,此步通过卡方进行特征选择。卡方进行特征值选择之后保留与y最相关的1000个词。
# # 特征选择
ch2 = SelectKBest(chi2,k=1000)
x_train = ch2.fit_transform(train_x,y_train)
x_test = ch2.transform(test_x)
feature_names = [feature_names[i] for i in
ch2.get_support(indices=True)]
# # 特征词查看
print("特征筛选后特征个数:{}\n\n1000个特征词汇为:\n {}".format(len(feature_names),feature_names))
特征筛选后特征个数:1000
1000个特征词汇为:
['一下', '一个', '一会', '一分', '一分货', '一口咬定', '一句', '一只', '一块', '一堆', '一塌糊涂', '一夜', '一天', '一座', '一张', '一无是处', '一早', '一晚', '一次', '一次性', '一流', '一直', '一看', '一碰', '一米', '一股', '一间', '万豪', '三个', '三思', '三星', '三星级', '上当', '上面', '下午', '下咽', '下来', '下楼', '下次', '下水管', '下水道', '不住', '不信', '不值', '不停', '不到', '不去', '不可思议', '不好', '不想', '不敢', '不敢恭维', '不来', '不热', '不爽', '不理', '不知', '不符', '不肯', '不行', '不见', '不象话', '不负责任', '不足', '不远', '不错', '东西', '丢人', '两个', '两张', '两样', '严重', '中午', '中央空调', '中年男人', '丰富', '丰盛', '临时', '为此', '久久', '义务', '之下', '之后', '之差', '之星', '九洲', '乱收费', '争执', '事件', '事先', '事情', '二十分钟', '二星', '交涉', '交警', '交通', '产生', '亲切', '亲戚', '人员', '人理', '今后', '从没', '付钱', '代理', '令人', '令人气愤', '以上', '以为', '以后', '以来', '价格合理', '企业', '休闲', '会员', '会员卡', '传真', '估计', '位置', '低下', '低档', '低级', '住天', '住店', '依然', '便利', '保安', '保证', '信任', '信号', '信用卡', '修好', '修理', '值得', '值班', '偏僻', '做事', '做出', '停电', '催促', '傻子', '先到', '免费', '入主', '入住', '入睡', '全价', '全国', '全是', '全部', '八点', '公园', '公安部门', '六点', '关不上', '关不紧', '关了', '其他人', '具体', '典型', '再也', '再也不会', '再住', '再换', '再次', '写字台', '写明', '冰冷', '冲凉', '决不会', '冷冰冰', '冷水', '冷淡', '冷热水', '冻死', '冻结', '凉水', '凌晨', '凑合', '几个', '几十块', '凯悦', '出奇', '出水', '出现', '出面', '分数', '分钟', '划算', '刚刚', '删除', '到位', '到极点', '到达', '刷卡', '刺鼻', '剃须刀', '前台', '剥落', '剩下', '办公楼', '办法', '办理', '加收', '劣质', '动手', '勉强', '千万别', '升级', '半个', '半夜', '半天', '半小时', '半岛', '协议', '单据', '卡车', '卫生', '卫生条件', '卫生间', '厕所', '厕纸', '原本', '原来', '反感', '反映', '反正', '反锁', '发现', '发生', '发票', '发脾气', '发誓', '发霉', '发黄', '发黑', '取消', '受不了', '受气', '变成', '口味', '只好', '只能', '只见', '可怕', '可怜', '可恶', '可想而知', '可气', '可笑', '号称', '合作', '合作伙伴', '合理', '吉林省', '同事', '同意', '同样', '后悔', '后来者', '后面', '吓人', '君悦', '听到', '吵得', '吵架', '告知', '告诉', '周到', '周末', '呵呵', '咸菜', '品种', '商场', '喀什', '喇叭', '喜来登', '喜欢', '噩梦', '噪音', '四星', '四星级', '四点', '回复', '回来', '回答', '图片', '地上', '地下室', '地址', '地方', '地板', '地步', '地毯', '地理位置', '坑人', '坚决', '坚持', '垃圾', '堵塞', '塑料', '墙体', '墙壁', '墙纸', '声音', '处理', '备用', '复杂', '外机', '外面', '多年', '多收', '夜里', '大声', '大失所望', '大跌眼镜', '太乱', '太低', '太偏', '太吵', '太差', '太旧', '太烂', '太高', '失望', '头发', '奇差', '奇慢', '奉劝', '好不容易', '好像', '好点', '如家', '字差', '安装', '安静', '完全', '定单', '定房', '宜家', '实在', '实惠', '实际', '客人', '客户', '客房', '客房部', '客服', '客观', '家具', '宽敞', '宾馆', '密封', '对不起', '对方', '对此', '导航', '尊重', '小到', '小姐', '小得', '小时', '少得', '尤其', '就让', '屋子里', '屋里', '岂有此理', '崩溃', '工地', '差劲', '差多', '差太差', '差差', '差得', '差远了', '已经', '市中心', '市场经济', '师傅', '帐单', '帐户', '席梦思', '干净', '干吗', '平安', '平方米', '平遥', '年代', '幽静', '广告业务', '广场', '床上', '床单', '店大欺客', '度假', '延时', '延迟', '建议', '开发票', '开房', '开裂', '开门', '异味', '弄脏', '弄脏了', '弥漫着', '弹簧', '强烈', '强烈建议', '强烈要求', '当天', '当时', '形容', '很大', '很小', '很差', '很快', '很棒', '很浓', '很漂亮', '很烂', '很脏', '很近', '很远', '得到', '心寒', '心情', '忍受', '快捷酒店', '怀疑', '态度', '态度恶劣', '态度生硬', '怎么回事', '性价比', '怪味', '总体', '总台', '总算', '恐怖', '恶劣', '恶心', '恼火', '情况', '情愿', '惊喜', '惬意', '想想', '想着', '愉快', '意思', '意识', '感冒', '感动', '感觉', '感觉不好', '慎重', '慎重考虑', '懒得', '我用', '我能', '我花', '我要', '房价', '房到', '房卡', '房客', '房租', '房费', '房钱', '房门', '房间', '所有', '所谓', '手机', '手段', '手续', '手续费', '才行', '扑鼻', '打不开', '打个', '打印', '打开', '打扫', '打电话', '打算', '打车', '批评', '找钱', '承担', '承认', '承诺', '投诉', '折腾', '报警', '抱歉', '押金', '抽水马桶', '拒绝', '拖拉机', '招待所', '拨打', '持续', '损坏', '换房', '授权', '掉下来', '排气扇', '接到', '接线', '接线员', '描述', '提出', '插座', '搞笑', '搞错', '搬家', '搬走', '携城', '携程', '携程网', '支付', '收到', '收拾', '收费', '收银', '改进', '放在', '教育', '散步', '敲门', '整个', '整体', '整晚', '整洁', '斑驳', '方便', '方巾', '施工', '旅店', '旅游局', '旅馆', '旋转', '无奈', '无法', '无能为力', '无表情', '无语', '早上', '早就', '早晨', '早餐', '早餐券', '时说', '时间', '明明', '明显', '明白', '昏暗', '星座', '星级', '昨晚', '是不是', '是否', '晓得', '晕倒', '晕死', '晚上', '景色', '暖气', '曲阜', '更别', '更换', '更让人', '最可气', '最后', '最多', '最好', '最小', '最差', '最烂', '最让人', '有人', '有房', '有无', '有没有', '有点', '服务', '服务员', '服务周到', '服务质量', '本店', '本来', '机器', '杜绝', '来说', '杭州', '杯子', '极低', '极小', '极差', '查房', '标准间', '标榜', '样子', '核对', '根本', '根本就是', '桌子', '椅子', '欺诈', '欺骗', '歉意', '正常', '正规', '正面', '此事', '此种', '步行', '死活', '段时间', '每间', '比例', '比较', '比较满意', '毛巾', '气味', '气愤', '气死', '气派', '水土不服', '水平', '水果', '水管', '水箱', '水龙头', '永远', '汉庭', '汕尾', '污水', '污渍', '污迹', '沟通', '没人', '没人来', '没想到', '没敢', '没法', '没洗', '没用', '没睡', '没窗', '没见', '没门', '河南人', '油漆', '注册', '洗不掉', '洗个', '洗手', '洗洁精', '洗涤', '洗澡', '洗脸', '浴巾', '海景', '海鲜', '消毒', '消费', '消费者', '淘汰', '深表歉意', '混乱', '清楚', '温馨', '游泳池', '满意', '漂亮', '漏水', '潮湿', '灰尘', '点前', '点半', '点多', '点评', '烂尾楼', '烟味', '烧水', '热情', '热情周到', '热水', '照片', '燕赵', '牙刷', '物品', '物有所值', '物超所值', '特价', '特色', '状态', '狡辩', '狭小', '环境', '现在', '现金', '理由', '理直气壮', '理睬', '理论', '甚远', '生存', '生手', '生日', '生气', '用户', '用车', '用过', '甲醛', '电梯', '电源', '电灯', '电视', '电视信号', '电话', '男友', '男子', '男服务员', '略显', '登记', '白色', '皇家', '皮球', '监控', '盒子', '盖章', '直到', '直接', '相信', '相关', '相同', '相差', '看看', '看着', '真不知道', '真是', '真是太', '真的', '真诚', '眼睛', '睡不着', '睡个', '睡着', '睡觉', '知道', '矿泉水瓶', '破旧', '破洞', '确定', '确实', '确认', '福州', '离开', '积分', '稍后', '空调', '突然', '窗户', '竟是', '第一', '第一个', '第一印象', '第一次', '第一间', '第三', '第二', '第二天', '第二间', '第五', '第四', '第天', '等待', '答复', '答应', '签字', '签约', '简陋', '算了', '算是', '管理', '管理人员', '箱子', '精致', '糟糕', '素质', '索引', '细心', '细节', '终于', '经历', '经理', '结帐', '结算', '绝不会', '维修', '缺点', '网上', '网站', '网管', '网线', '美中不足', '老鼠', '考察', '聊天', '联系', '肮脏', '脏乱差', '脏兮兮', '脏得', '脾气', '自动', '自助餐', '自来水', '自称', '臭味', '致电', '舒服', '舒适', '花园', '英才', '莫泰', '蛮横', '蟑螂', '血迹', '行为', '行政', '街边', '补偿', '补充', '表示', '被单', '被子', '被罩', '裸露', '西湖', '要加', '要命', '要收', '要死', '要求', '见过', '规定', '解决', '解决问题', '解释', '订单', '认识', '讲话', '设备陈旧', '设置', '证明', '评分', '诚信', '诚意', '诚聘', '误导', '说明', '说水', '说话', '请问', '调换', '调整', '调查', '调试', '谈不上', '象是', '负责人', '责任', '质疑', '质问', '购物', '贴心', '贵阳', '费用', '赔偿', '赚钱', '赠送', '走人', '走廊', '赶紧', '起床', '超值', '超小', '超差', '足疗', '足足', '跟前', '跟着', '跟踪', '跳蚤', '身份', '身份证', '转到', '转身', '轰鸣', '较差', '过分', '过敏', '过来', '过道', '过问', '近点', '返还', '还会', '还要', '这家', '这种', '这话', '进行', '进门', '连个', '连锁', '迹象', '退房', '适中', '适合', '逃走', '通知', '遇到', '道歉', '遗憾', '遥控器', '遭遇', '那间', '郁闷', '鄙视', '酒店', '里面', '金牌', '针对', '钟才', '钟点房', '钥匙', '钻石', '银行', '锅炉房', '错误', '锦地', '锦江', '长期', '门卡', '门卫', '门锁', '问题', '闹中取静', '闻所未闻', '阳台', '阴暗', '陈旧', '随后', '隔壁', '隔音', '难以', '难以忍受', '难受', '难吃', '难闻', '震惊', '霉味', '非常重视', '面上', '鞍山', '顾客', '预付', '预定', '预订', '领教', '风扇', '风景', '风格', '飞机', '食堂', '餐具', '餐券', '饮水机', '饮用水', '馒头', '首选', '香港', '马桶', '骗人', '高价', '鸡蛋', '黄色', '黑乎乎', '黑店', '黑色', '黑黑的', '齐全']
构建不同的分类器
- 构建多种分类器:线性最小二乘L2正则(RidgeClassifier)、K近邻 (KNeighborsClassifier)、朴素贝叶斯(MultinomialNB)、随机森林(RandomForestClassifier)、SVM(SVC:hinge损失 的绝对值)、线性核SVM(LinearSVC:平方hinge损失+L1正则)、线性核SVM(LinearSVC:平方hinge损失+L2正则)
- 通过网格搜索找到最优参数
# # 基准模型
def benchmark(clf,name):
print("分类器:",clf)
# 设置最优参数,5折交叉验证
alpha_can = np.logspace(-2,1,10)
model = GridSearchCV(clf,param_grid={'alpha':
alpha_can}, cv=5)
m = alpha_can.size
# alpha参数
if hasattr(clf,'alpha'):
model.set_params(param_grid={'alpha':alpha_can})
m = alpha_can.size
# k近邻
if hasattr(clf,'n_neighbors'):
neighbors_can = np.arange(1,15)
model.set_params(param_grid={'n_neighbors':
neighbors_can})
m = neighbors_can.size
# LinearSVC参数
if hasattr(clf,'C'):
C_can = np.logspace(1,3,3)
model.set_params(param_grid={'C':C_can})
# SVM参数
if hasattr(clf,'C') & hasattr(clf,'gamma'):
C_can = np.logspace(1,3,3)
gamma_can = np.logspace(-3,0,3)
model.set_params(param_grid={'C':C_can,'gamma':gamma_can})
m = C_can.size*gamma_can.size
# 深度参数
if hasattr(clf,'max_depth'):
max_depth_can = np.arange(4,10)
model.set_params(param_grid={'max_depth':max_depth_can})
m = max_depth_can.size
# # 训练模型
t_start = time()
model.fit(train_x,y_train)
t_end = time()
t_train = (t_end-t_start)/(5*m)
print("5折交叉验证的训练时间为:%.3f/(5*%d)=%.3f秒"
%((t_end-t_start),m,t_train))
print("最优参数为:",model.best_params_)
# # 模型预测
t_start = time()
y_hat = model.predict(test_x)
t_end = time()
t_test = t_end -t_start
print("测试时间:%.3f秒"%t_test)
# # 模型评估
# # 训练集
train_acc = metrics.accuracy_score(y_train,
model.predict(
train_x))
# # 测试集
test_acc = metrics.accuracy_score(y_test,y_hat)
print("训练集准确率:%.2f%%"%(100*train_acc))
print("测试集准确率:%.2f%%"%(100*test_acc))
# # 返回结果
return t_train,t_test,1-train_acc,1-test_acc,name
# # 不同分类器比较
print("分类器的比较:\n")
clfs = [
[RidgeClassifier(),'Ridge'],# 线性分类器-最小二乘+L2正则
[KNeighborsClassifier(),'KNN'],# K临近
[MultinomialNB(),'MultinomialNB'],# 朴素贝叶斯
[RandomForestClassifier(n_estimators=200),'RandomForest'],# 随机森林
[SVC(),'SVM'],# svm:采用svc(),损失是hinge损失的绝对值
[LinearSVC(loss='squared_hinge',penalty='l1', # 线性可分支持向量积,平方Hinge损失+L1正则
dual=False,tol=1e-4),'LinearSVC-l1'],
[LinearSVC(loss='squared_hinge',penalty='l2', # 线性可分支持向量积,平方Hinge损失+L2正则
dual=False,tol=1e-4),'LinearSVC-l2']
]
# # 训练数据保存到列表
result = []
for clf,name in clfs:
# 计算结果
a = benchmark(clf,name)
result.append(a)
print('\n')
# #
result = np.array(result)
分类器的比较:
分类器: RidgeClassifier(alpha=1.0, class_weight=None, copy_X=True, fit_intercept=True,
max_iter=None, normalize=False, random_state=None, solver='auto',
tol=0.001)
5折交叉验证的训练时间为:41.859/(5*10)=0.837秒
最优参数为: {'alpha': 0.21544346900318834}
测试时间:0.000秒
训练集准确率:88.95%
测试集准确率:86.62%
分类器: KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=5, p=2,
weights='uniform')
5折交叉验证的训练时间为:95.239/(5*14)=1.361秒
最优参数为: {'n_neighbors': 1}
测试时间:0.389秒
训练集准确率:99.97%
测试集准确率:80.61%
分类器: MultinomialNB(alpha=1.0, class_prior=None, fit_prior=True)
5折交叉验证的训练时间为:0.325/(5*10)=0.007秒
最优参数为: {'alpha': 0.21544346900318834}
测试时间:0.000秒
训练集准确率:91.67%
测试集准确率:87.07%
分类器: RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=200, n_jobs=1,
oob_score=False, random_state=None, verbose=0,
warm_start=False)
5折交叉验证的训练时间为:17.168/(5*6)=0.572秒
最优参数为: {'max_depth': 9}
测试时间:0.044秒
训练集准确率:72.82%
测试集准确率:72.27%
分类器: SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
5折交叉验证的训练时间为:477.596/(5*9)=10.613秒
最优参数为: {'C': 100.0, 'gamma': 0.001}
测试时间:0.864秒
训练集准确率:97.47%
测试集准确率:89.49%
分类器: LinearSVC(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, loss='squared_hinge', max_iter=1000,
multi_class='ovr', penalty='l1', random_state=None, tol=0.0001,
verbose=0)
5折交叉验证的训练时间为:15.466/(5*10)=0.309秒
最优参数为: {'C': 10.0}
测试时间:0.001秒
训练集准确率:99.87%
测试集准确率:87.07%
分类器: LinearSVC(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, loss='squared_hinge', max_iter=1000,
multi_class='ovr', penalty='l2', random_state=None, tol=0.0001,
verbose=0)
5折交叉验证的训练时间为:17.259/(5*10)=0.345秒
最优参数为: {'C': 10.0}
测试时间:0.001秒
训练集准确率:99.85%
测试集准确率:86.97%
模型比较
# 数据
result = [[x[i] for x in result] for i in range(5)]
training_time,test_time,traning_err,test_err,clf_names = result
training_time = np.array(training_time).astype(np.float)
test_time = np.array(test_time).astype(np.float)
traning_err = np.array(traning_err).astype(np.float)
test_err = np.array(test_err).astype(np.float)
# 可视化
x = np.arange(len(training_time))
plt.figure(figsize=(10,7),facecolor='w')
ax = plt.axes()
b0 = ax.bar(x+0.1,traning_err,width=0.2,color='#77E0A0')
b1 = ax.bar(x+0.3,test_err,width=0.2,color='#8800FF')
ax2 = ax.twinx()
b2 = ax.bar(x+0.5,training_time,width=0.2,color='#FFA0A0')
b3 = ax2.bar(x+0.7,test_time,width=0.2,color='#FF8080')
plt.xticks(x+0.5,clf_names)
plt.legend([b0[0],b1[0],b2[0],b3[0]],("训练集错误率:",
"测试集错误率",
"训练时间",
"预测时间"),
loc = 'upper left',
shadow = True)
plt.title("酒店评论文本分类及不同分类器比较",fontsize=18)
plt.xlabel("分类器名称")
plt.grid(True)
plt.tight_layout(2)
plt.show()
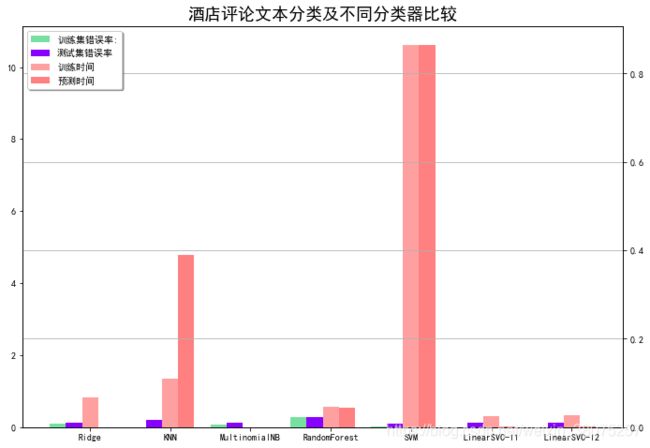
结果分析
- 多种分类器中,SVM和KNN依然训练时间高于其他分类,Ridg线性分类器训练时间也相对较长。但是SVM虽然训练时间长,其分类准确率在训练集和测试集都很高,表现良好。KNN在文本分类中效率较为低下,耗时长且错误率高。其余的分类器表现差异不大。
- 但在模型训练过程中,LinearSVC-l1报了收敛警告,LinearSVC-l2没有收敛警告,且表现不错。对比高斯核SVM(利用SVC类),线性核LinearSVC-l1(利用LinearSVC类,hinge损失的绝对值,惩罚项是l1)以及线性核LinearSVC-l2(利用 hinge损失的绝对值,惩罚项是l2)。 高斯核SVM虽然时间消耗大,但是表现良好。由于非线性核函数,该项目中是针对文本情感分类,利用CBOW模型进 行向量化,提取部分特征之后非线性变化。分析认为是文本信息和数值数据本身就不一样,文本数据的模型刻画中已 经进行了很多抽象化的操作,所以非线性变化较为合适。
- LinearSVC类是基于liblinear,罚函数是对截矩进行惩罚,损失函数是基于hing损失的平方,可以用梯度下降优化。 SVC基于libsvm,罚函数不是对截矩进行惩罚,损失函数基于hing损失(非凸),无法使用梯度下降求解。SVM解决问 题时,问题是分为线性可分和线性不可分问题的,liblinear对线性可分问题做了优化,故在大量数据上收敛速度比 libsvm快。这也合理的解释了上图中时间维度信息。 对于不同的惩罚函数,线性核LinearSVC-l1采用l1作为惩罚项,线性核LinearSVC-l2采用l2作为惩罚项,LinearSVC-l1 有收敛性警告,但LinearSVC-l2没有,分析原因主要是该项目中在向量化之前已经进行了特征筛选,剩余1000个特征 词汇,对于一条评论命中一个词汇概率已经较低。LinearSVC-l1利用l1作为惩罚项,本身就具备特征筛选的作用,对 于很多评论而言,这很可能导致参数为0,所以收敛性无法保证。
通过三者对比,特征选择与否以及数据本身特征对于模型的选择和建立很重要。
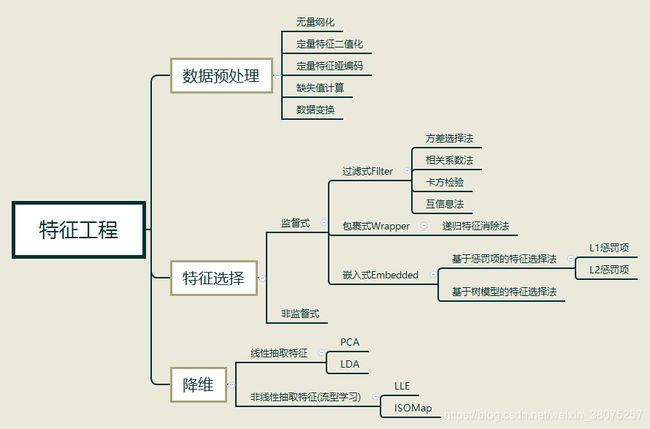
知识点补充
特征工程总结
SVC和LinearSVC的比较
- 损失函数的不同。SVC是hinge损失,不可导,所以不能使用梯度下降求解;LinearSVC的损失函数是hinge损失的平方,可导,可以使用梯度下降求解。
- 多分类的处理方式。SVC处理多分类问题是采用one vs one模式;LinearSVC是采用one vs all模型。
- 惩罚项的不同。SVC基于libsvm,不对截距项惩罚;LinearSVC是基于libLinear,对截距项惩罚。
- 适用范围的不同。SVC适用于线性可分数据和非线性数据,但是linearSVC更适用于大规模线性可分数据。
完整数据和代码
数据和代码
参考资料
机器学习中,有哪些特征选择的工程方法?
03 贝叶斯算法 - 案例二 - 新闻数据分类sification/traditional_ML)