李宏毅机器学习笔记——卷积神经网络
卷积神经网络
- 为什么CNN来做图片识别
- CNN的整体框架
-
- 卷积 Convolution
- 最大池化 Max Pooling
- 压平 Flatten
- CNN in Keras
- CNN学习了什么
- Deep Dream
- CNN的应用
为什么CNN来做图片识别
图片一般有很多个像素,如果一个像素表示一个data的话,一般的神经网络的参数会很多很多,训练起来将会耗费大量时间。
- 我们要求神经网络要做的其实是识别patterns,而patterns一般要比整个图片要小很多;
- 同时含义一样的patterns可能出现在图片的不同位置,我们想要神经网络可以不多设置额外的参数去识别;
- Subsampling(下采样)对图片的含义的影响是可以忽略的,我们希望可以下采样来减小图片的大小。
CNN模型可以满足上面的要求。
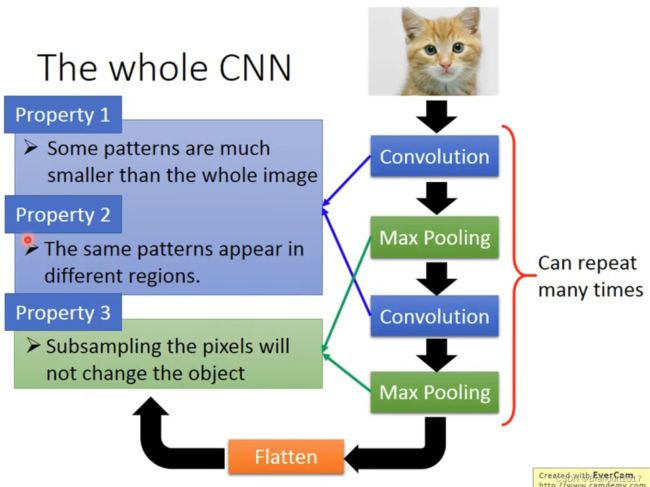
CNN的整体框架
卷积 Convolution
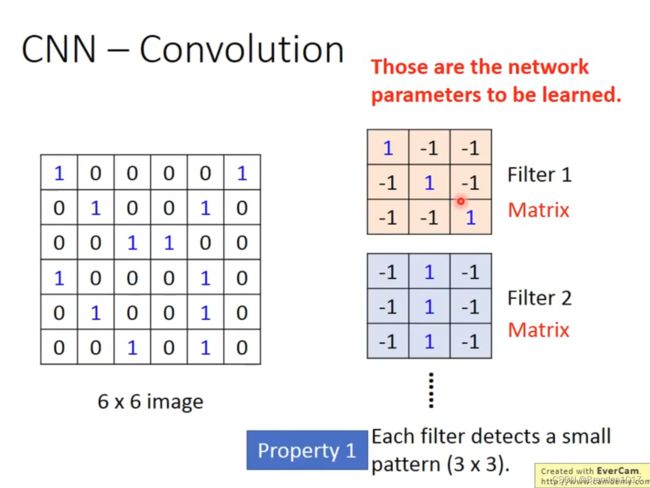
我们会设置几个Filters,作为需要被学习的patterns。Filter的大小是比图片要小许多的。
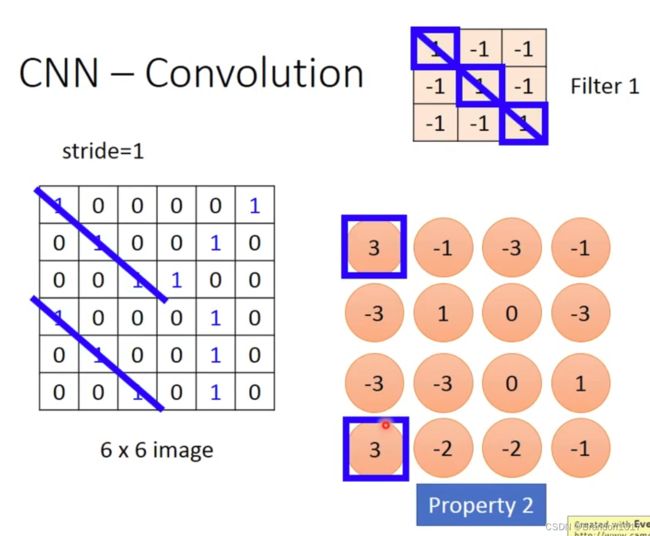
在训练时,我们会将Filter和图片中从左到右、从上到下同样大小的区域作内积。在图片中移动的长度我们称为步长(stride)。将整张图片扫描完成后,我们会得到大小为 ( ⌊ m − n s ⌋ + 1 ) ∗ ( ⌊ m − n s ⌋ + 1 ) (\lfloor \frac{m-n}{s}\rfloor+1)*(\lfloor \frac{m-n}{s}\rfloor+1) (⌊sm−n⌋+1)∗(⌊sm−n⌋+1)的矩阵,其中 m m m是原来图片的长(默认为正方形图片), n n n为Filter的长, s s s为步长。
将所有Filter与图片内积完成后,我们就会得到与Fliters相应数量的矩阵,我们称为Feature Map。
如果是一张具有颜色的图片,那么图片的表示其实是一个mm3的立方体,对应的Filter也是nn3的立方体,其他运算是与前面相同的。
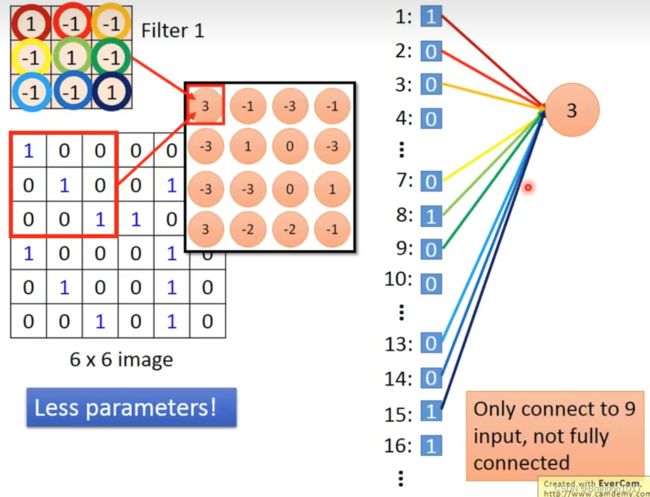
所以在CNN中并不是全连接,并且同一层神经中参数都是固定的(取决于Filters)。
最大池化 Max Pooling
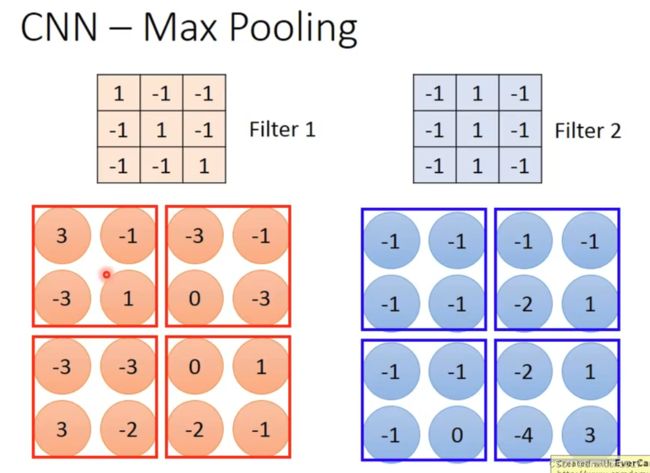
我们将Filter内积后得到的矩阵(image)进行分组,如图是四个一组,然后取最大的(或平均)保留下来,重新得到新的矩阵。这样,我们就将原来的图片压缩成很小(文中例子是66⇒44⇒2*2)
我们可以将Convolution和Max Pooling重复很多次,将图片不断地进行提取特征、压缩,得到更小的图片。
压平 Flatten
就是将最后得到的图片(矩阵),拉伸成一维的数据,再丢进全连接神经网络进行学习。
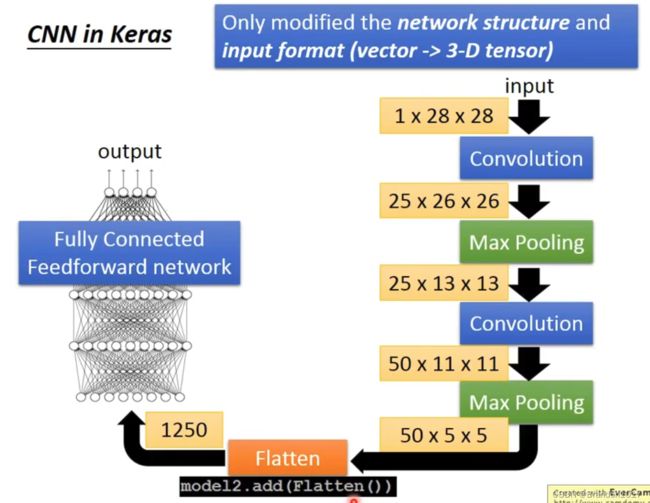
CNN in Keras
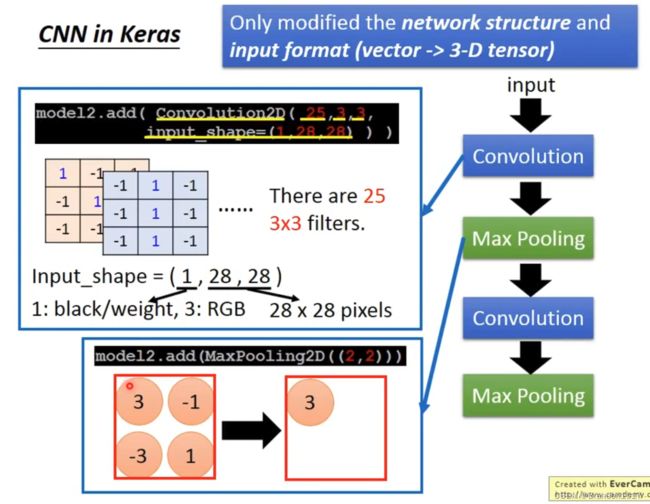
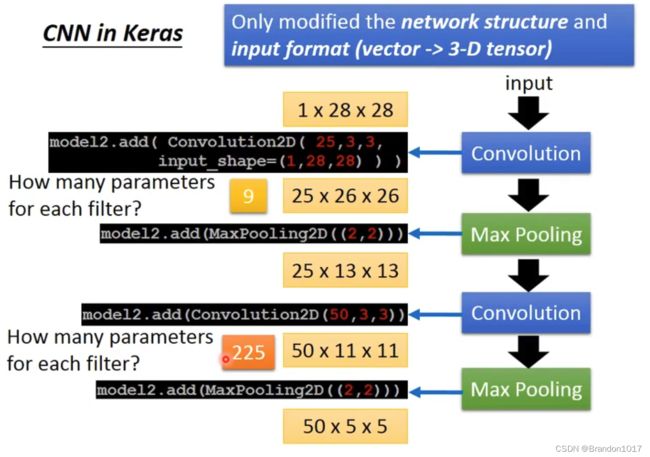
CNN学习了什么
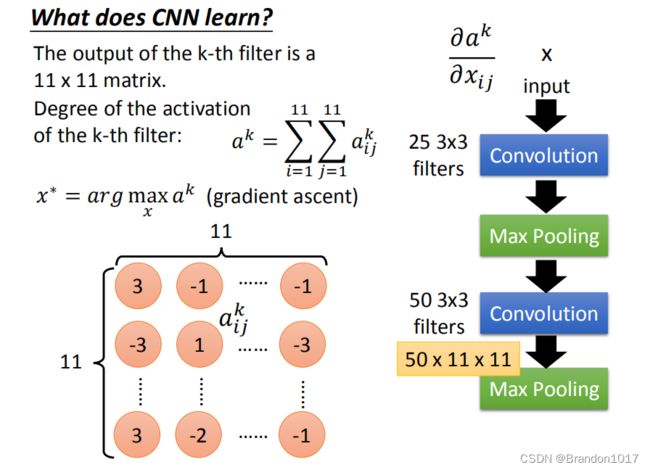
如何分析CNN中间得到了什么。对于第一层,我们分析会比较容易,25个filter,对应生成的25层image,每层的image是原始image和filter内积移动得到的矩阵,所以很容易将原始image和处理后的值对应起来。
而对于第二层往后,我们有一种方法。我们从50个filter中取出一个,它所对应的和image内积的矩阵如图所示。我们定义一个值叫做"Degree of the activation of the k-th filter",是说现在这个filter被激活了多少(或匹配了多少),它是内积后的矩阵中所有元素相加得到: a k = Σ i = 1 11 Σ j = 1 11 a i j k a^k=\Sigma^{11}_{i=1}\Sigma^{11}_{j=1}a^k_{ij} ak=Σi=111Σj=111aijk。
我们想知道第k个filter的作用是什么,我们就找一张image,让这张image可以让第k个filter被激活的程度最大,即 a k a^k ak的值越大: x ∗ = a r g m a x x a k x^*=arg max_xa^k x∗=argmaxxak。我们用gradient ascent就可以做到这件事(minimize使用gradient descent,maximize使用gradient ascent)。在原来训练模型时,我们是固定data来训练参数,但现在是反过来,固定参数来更新data,使得 a k a^k ak最大。
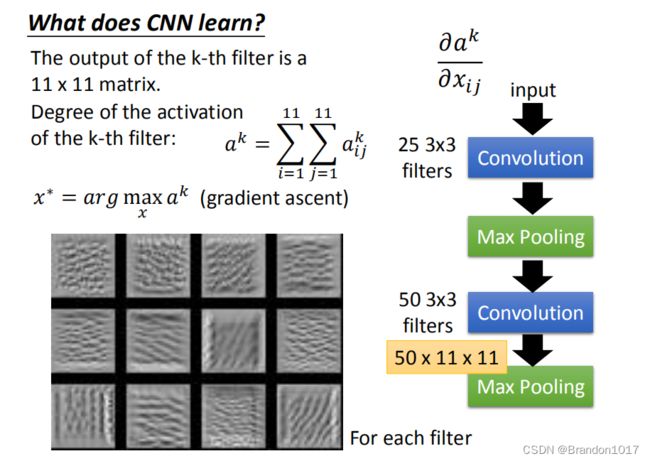
上图是得到的结果,我们取12个Filter出来,让它最被激活的image找出来。我们发现每个filter的工作就是识别某一个pattern。
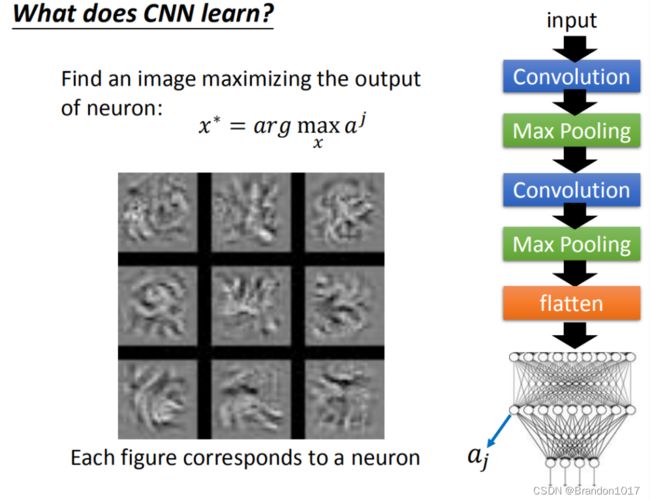
在做完convolution和Max Pooling以后,我们需要将矩阵Flatten,然后再丢进神经网络里面去。那我们接下来想知道,神经网络里面的每一个神经元的工作是什么。我们就定义第j个神经元,它的输出叫做 a j a_j aj。接下来类似于之前的步骤,我们要找一张image,让这张image丢进神经网络后能使得 a j a_j aj的值最大。其中九个神经元找到的image就是上图中这九个。
这些图不像之前观察到的fliter所对应的pattern图,更像是一张完整的图。因为Filter所考虑的是图上一个小小的部分的特征。现在在做完Flatten之后,每个神经元的工作就是去看整张图,而不是一小部分。
 如果我们现在看的是神经网络的输出,一共有十个输出,每一个输出分别代表了对应的数字的可能。假设我们现在找一张image,使得它能够让对应数字1的输出结果最大,那么那张image要显然看起来就像数字1。但实际结果并不是,上图是我们找到的使得对应数字0到8的输出结果最大的9张图片,但每张图片看起来都不像是数字。所以神经网络可能所学到的东西跟我们人类是不太一样的。
如果我们现在看的是神经网络的输出,一共有十个输出,每一个输出分别代表了对应的数字的可能。假设我们现在找一张image,使得它能够让对应数字1的输出结果最大,那么那张image要显然看起来就像数字1。但实际结果并不是,上图是我们找到的使得对应数字0到8的输出结果最大的9张图片,但每张图片看起来都不像是数字。所以神经网络可能所学到的东西跟我们人类是不太一样的。

那怎么使得这些图片看起来更像是数字呢?我们这里调整了寻找image的公式: x ∗ = a r g m a x x ( y i − Σ i , j ∣ x i j ∣ ) x^*=arg max_x(y^i-\Sigma_{i,j}|x_{ij}|) x∗=argmaxx(yi−Σi,j∣xij∣)。
我们的想法是,在数字图片中,会有很大一部分都是空白,而只有数字笔画的部分是黑色的,我们就在式子的后面加上绝对值那一项,即加入正则项,想要告诉机器,希望被识别出来的数字图片中,空白部分越多越好。我们就得到上面图中右边部分的image。它比左边部分要更像数字一些,尽管还是难以辨认。当然,这也是其中一种让image更像数字的方法,还有很多其他的方法能让这点做得更好,这里就不继续探讨了。
Deep Dream

Deep Dream讲的是,如果我们让机器加深它所“看到”或者“识别”出来的部分,减弱“看不见”的部分,重新反馈在image中。比如将上面的照片丢进CNN中,然后把其中某个隐藏层拿出来,它是一个向量,将向量中正项部分的值调大,负项的值调小。然后把这个向量当作是新的image的目标,即找一张image,用梯度提升的办法去接近调整的向量的值,这样就是让CNN夸大它所看到的东西。那么上面那张图片做Deep Dream的结果就是下图。

Deep Dream还有一个进阶的版本,叫做Deep Style。

Deep Style的作用就有点像风格迁移。输入一张image,然后再输入另一张image,让机器去修改第一张图,让它有另外一张图的风格 。
原来的image丢给CNN,然后得到CNN的filter的output,CNN的filter的output代表这张image有什么关系。接下来你把呐喊这张图也丢到CNN里面,也得到filter的output。我们并不在意一个filter ,而是在意filter和filter之间的convolution,这个convolution代表了这张image的style。
接下来你用同一个CNN找一张image,这张image它的content像左边这张相片,但同时这张image的style像右边这张相片。你找一张image同时可以maximize左边的图,也可以maximize右边的图。那你得到的结果就是像最底下的这张图。用的就是刚才讲的梯度提升的方法找一张image,然后maximize这两张图,得到就是底下的这张图。
CNN的应用
CNN除了在图像上有广泛的应用,在其他问题中同样也可以使用。
-
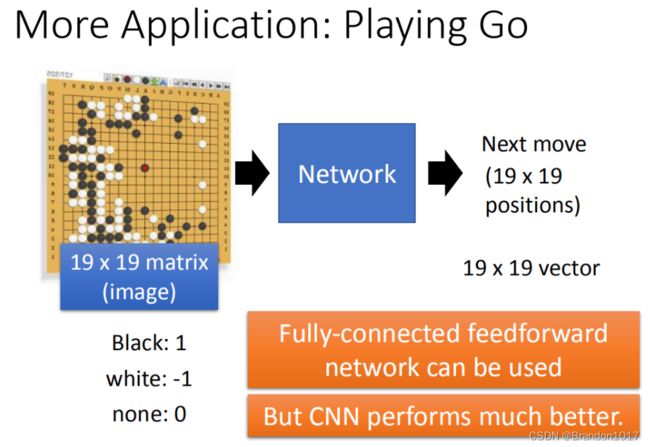
围棋
例如Alpha Go中就运用了CNN。围棋是比较符合使用CNN的特性的:有局部pattern、pattern出现的位置可能不一样、pattern比整个图像要小。但Alpha Go并没有用到CNN中的Max Pooling,它并不适用在棋盘上。
-
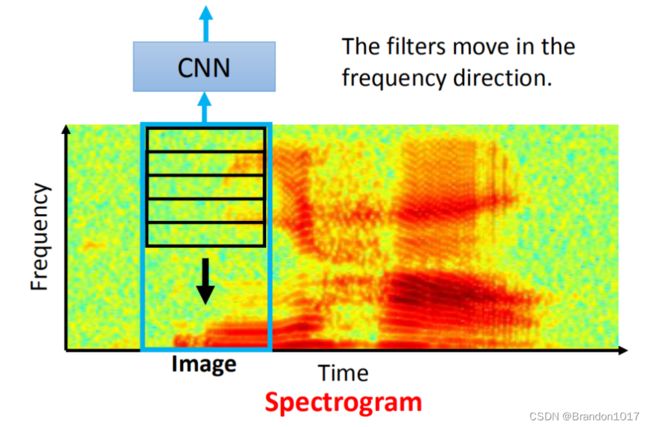
语音
语音会有一段声音讯号的波形,是由频率和时间两个维度构成,也有符合使用CNN的特性。
-
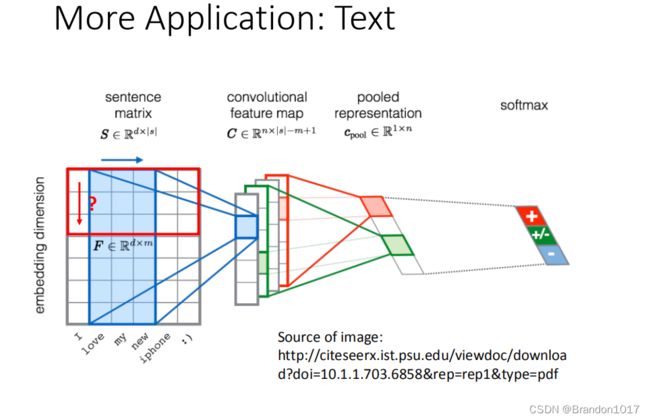
文本
这里需要将文本做成词向量,两个语义相近的词或字,它们的词向量应该是在向量空间中比较接近的。当我们把每个字词排在一起,所有的词向量就会变成一个矩阵或者image。我们就可以把CNN套用在上面。