2021 Lifelong learning(李宏毅
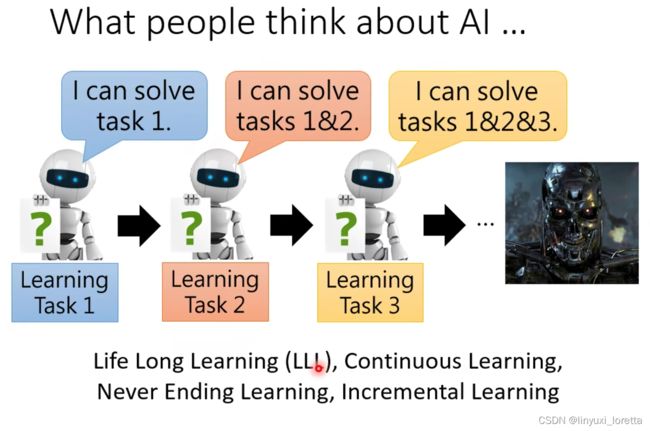
Lifelong learning探讨的问题是,一个模型能否在很多个task上表现都很好。如此下去,模型能力就会越来越强。
Life Long Learning 的難點出在什麼樣的地方:
這個算是同一個任務 不同的 Domain
機器先學個語音辨識、再學個翻譯、再学个影像辨识。。Lifelong learning沒有做到那個程度
一般在 Life Long Learning 的文獻上,所謂的不同任務指的差不多就是我这里例子的等级,

e.g.2 问答系统

人们刚开始想用 Deep Learning 的技術解QA问题时,
Facebook定义了20个简单的QA任务 bAbi训练集、bAbi 裡面的文章都是用某種規則生成的
这里让机器从第一个任务开始学习,学到第20个。
并不是因為機器就是沒有能力多学好几个任务,如果我們把20個任務的資料通通倒在一起:

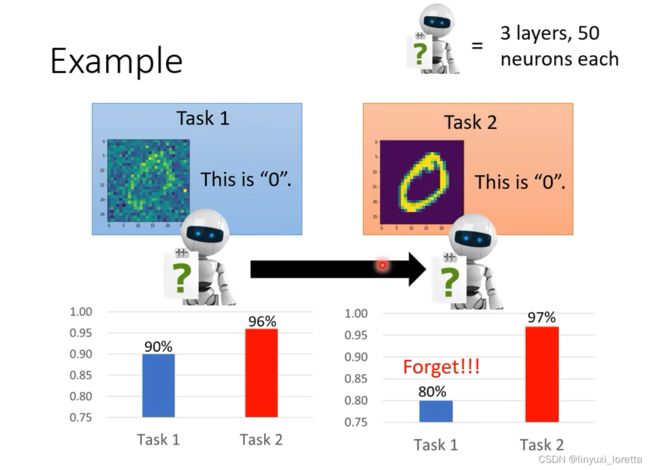
catastrophic forgetting

multi-task training很难实现,要保存所有的旧资料才行,学习可能很久(存储、computation问题),
multi-task training往往视为 Life Long Learning的upper bound


如果我們是不同的任務就用不同的模型、不同任務的資料間就不能夠互通有無、没法从其他的任务里,汲取單一個任務所沒有辦法學到的資訊
二、终身学习v.s.Transfer Learning

Transfer Learning: 虽然也涉及两个任务,但是它关心的是第一个任务上学到的模型在第二个任务上的应用,而不关心它是否仍能解决任务1。
三、终身学习的评估
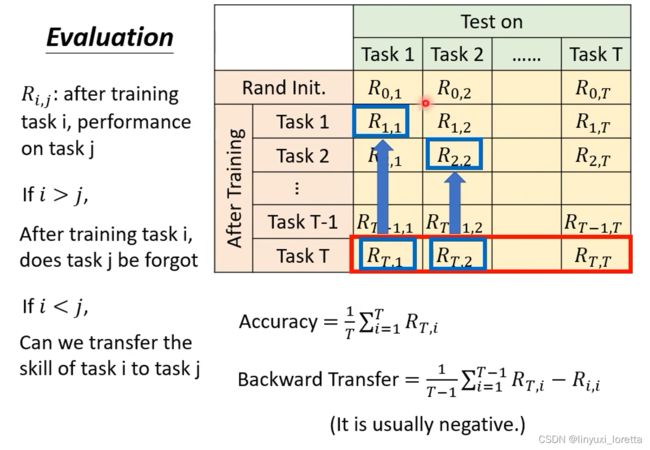
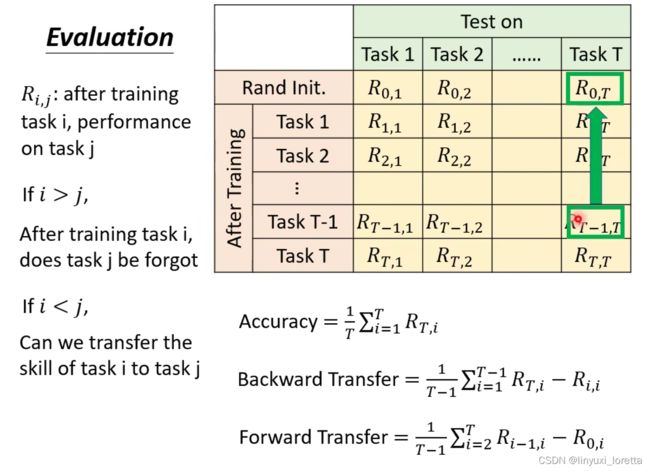
1、首先需要一系列任务
這些是我們把每一個數字用某一種固定的規則把它打亂、每个任务把数字做不同的打乱,

2、先将随机初始化的参数模型用在所有任务上得出每个任务的正确性;接下来学第一个任务,再在t个任务上计算正确率;学完第二个任务后,同样的操作,直到第t个任务。
四、3个life long learning的可能解法
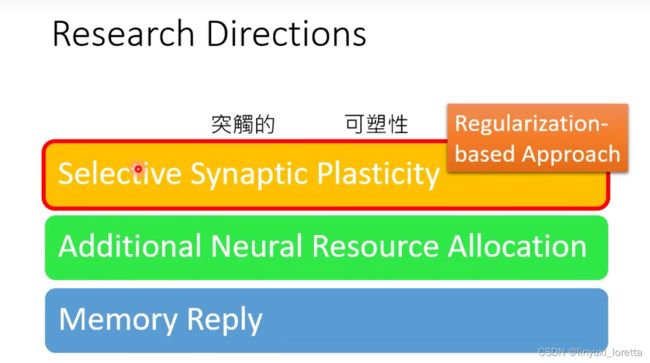
1、选择性突触的可塑性
Synaptic 是突觸的意思,就是我們腦神經中 神經跟神經之間的連結
那像這樣的方法又叫做Regularization-based 的方法、這個研究的面向,在LLL领域里,我覺得是發展得最完整的
(1)Catastrophic Forgetting 的現象是怎麼來的

(2)如何解决
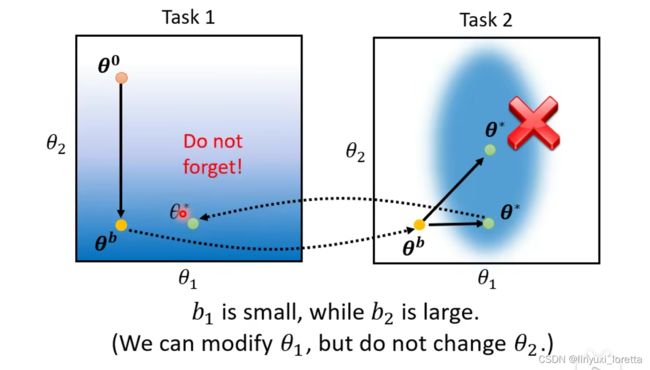
有方法可以讓 NN 加一些約束、讓它和原本的參數不要差太多、讓它記得舊的任務怎麼做嗎、這就是等一下 Life Long Learning 的、其中一個最常用的解法
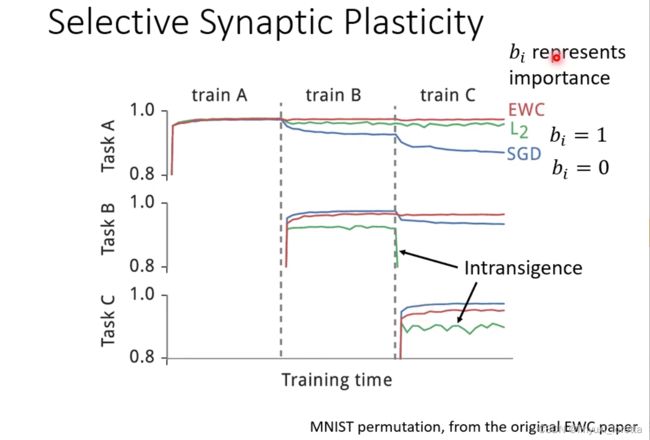
所以解决办法的思想是:一些模型中重要的参数改变很小,而不重要的参数可以改变较大

Intransigence不肯妥協 不肯讓步 顽固
那么怎么找到b呢?
在 Lifelong Learning 的研究裡面、關鍵的技術就在於 我們怎麼設定這個 bi、那如果 bi 用 Learn 的到底行不行呢 可能不太行

Q&A: EWC在 Train 每個新的 Task 之前、為了要算每個 Parameter 的重要性、都會用之前的 Data 去算 Gradient、这样是不是跟GEM一样 存有部分之前的 Data 呢?
就是我們要算 Parameter 的重要性這件事情、在一個任務訓練完之後、馬上就把參數的重要性記錄下來、之后,舊的任務的所有的資料 就都可以被丟掉了、所以和GEM还是不太一样的,
各种bi设的方法:

每一個方法、都有它自己的特色、還有它想要解決的問題
bi怎么算,每一個方法都不一樣、而且每一個方法用的資料不一樣、有的方法 只需要 Model 的 Input 就好、有的方法要 Input 加 Output、也就是假設是影像分類的問題的話,有的方法用image,有的需要考虑label
改變任務的順序、結果就會差很多、所以这些paper里面,他們在做實驗的時候、都不是只做一種任務的順序、他們會窮舉所有任務的順序出來做實驗、然後再取它的平均值
其实 Regularization Based 的方法、還有一個早年的做法GEM,但它不是在參數上做限制、而是在 Gradient Update 的方向上做限制
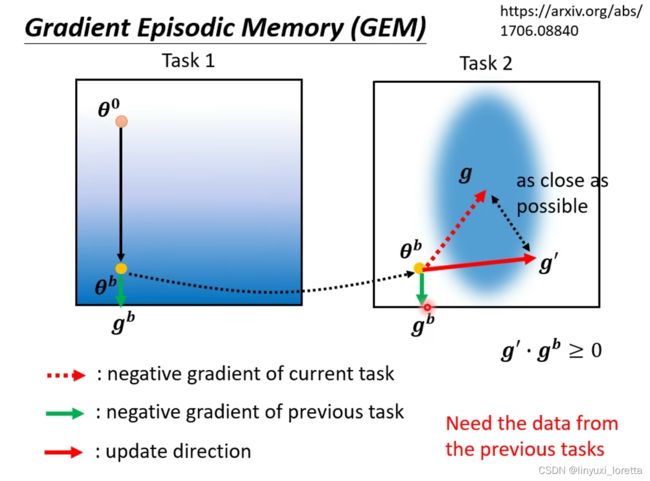
修改的条件是,找到一个新的g`, g`和gb做inner product≥0,g`和g 不能差太多,
gb的计算意味着GEM法需要存task1的资料,但只需要存非常少量的資料就好
但是像EWC这类 Regularization Based 的方法、它們需要佔用額外的空間、來儲存舊的模型跟儲存 bi
2、Additional neural resource allocation
也就是我们改变一下 使用在每一個任務裡面的 Neural 的 Resource
训练任务2时不要动任务1学到的模型,你另外再多開一個 Network、这个network会吃任务1的Hidden Layer 的 Output 作為輸入
任務一學出來的參數、都不要再去動它了、我們只多新增一些額外的參數、我們只 Train 額外的參數
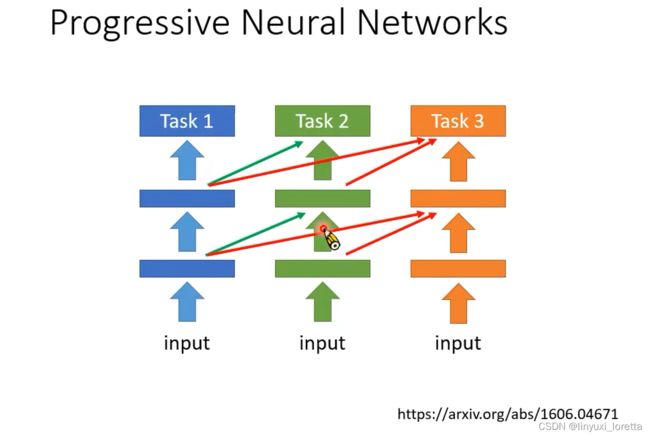

PackNet它是 Progressive Networks 的反過來
Progressive Networks 是每次有新任务进来就多加一些neural,PackNet它說我們先開一個比較大的 Network,每次有新任务进来,只用大network的一部分参数,
PackNet和Progressive Networks可以结合在一起,知名的 CPG,model
既可以增加新的參數、每一次又都只保留部分的參數可以拿來做訓練
三、memory reply

我们实验室的经验表明,這一種 Generate Data 的方法非常有效,往往可以逼近upper bound
我們剛才講的 Lifelong Learning 的 Scenarios,我们都假设每个任务需要的模型就是一樣的
我們甚至強迫限制說,每个任务我们要训练的classifer、它們需要的 Class 量都一样
那假设每个任务需要的class量不一样 怎么解:
其实 我們今天講的 Lifelong Learning只是整個 LLL 領域研究裡面的其中一小塊,其中某一个情景
你可以閱讀一下下面這邊統整的文獻、会告诉你Lifelong Learning 有三個情境

做task的顺序是重要的, 看起来有一些顺序会让我们没有 catastrophic forgetting问题,而研究什么顺序好 叫curriculum learning