Mybatis补充知识
一.对于orm框架的了解
了解orm,先了解以下概念:
1.1什么是“持久化”
持久(Persistence),即把数据(如内存中的对象)保存到可永久保存的存储设备中(如磁盘)。持久化的主要应用是将内存中的数据存储在关系型的数据库中,当然也可以存储在磁盘文件中、XML数据文件中等等。
1.2什么是 “持久层”
持久层(Persistence Layer),即专注于实现数据持久化应用领域的某个特定系统的一个逻辑层面,将数据使用者和数据实体相关联。
1.3什么是ORM
对象关系映射(英语:Object Relational Mapping,简称ORM,或O/RM,或O/R mapping),是一种程序设计技术,用于实现面向对象编程语言里不同类型系统的数据之间的转换。从效果上说,它其实是创建了一个可在编程语言里使用的“虚拟对象数据库”。
ORM是面向对象程序设计语言和关系型数据库发展不同步时的解决方案,采用 ORM框架后,应用程序不再直接访问底层数据库,而是以面向对象的方式来操作持久化对象,而ORM框架则将这些面向对象的操作转换成底层的 SQL 操作。
1.4为什么要做持久化和ORM设计(重要)
在目前的企业应用系统设计中,MVC,即 Model(模型)- View(视图)- Control(控制)为主要的系统架构模式。MVC 中的 Model 包含了复杂的业务逻辑和数据逻辑,以及数据存取机制(如 JDBC的连接、SQL生成和Statement创建、还有ResultSet结果集的读取等)等。将这些复杂的业务逻辑和数据逻辑分离,以将系统的紧耦 合关系转化为松耦合关系(即解耦合),是降低系统耦合度迫切要做的,也是持久化要做的工作。MVC 模式实现了架构上将表现层(即View)和数据处理层(即Model)分离的解耦合,而持久化的设计则实现了数据处理层内部的业务逻辑和数据逻辑分离的解耦合。 而 ORM 作为持久化设计中的最重要也最复杂的技术,也是目前业界热点技术。
简单来说,按通常的系统设计,使用 JDBC 操作数据库,业务处理逻辑和数据存取逻辑是混杂在一起的。
一般基本都是如下几个步骤:
1、建立数据库连接,获得 Connection 对象。
2、根据用户的输入组装查询 SQL 语句。
3、根据 SQL 语句建立 Statement 对象 或者 PreparedStatement 对象。
4、用 Connection 对象执行 SQL语句,获得结果集 ResultSet 对象。
5、然后一条一条读取结果集 ResultSet 对象中的数据。
6、根据读取到的数据,按特定的业务逻辑进行计算。
7、根据计算得到的结果再组装更新 SQL 语句。
8、再使用 Connection 对象执行更新 SQL 语句,以更新数据库中的数据。
7、最后依次关闭各个 Statement 对象和 Connection 对象。
由上可看出代码逻辑非常复杂,这还不包括某条语句执行失败的处理逻辑。其中的业务处理逻辑和数据存取逻辑完全混杂在一块。而一个完整的系统要包含成 千上万个这样重复的而又混杂的处理过程,假如要对其中某些业务逻辑或者一些相关联的业务流程做修改,要改动的代码量将不可想象。另一方面,假如要换数据库 产品或者运行环境也可能是个不可能完成的任务。而用户的运行环境和要求却千差万别,我们不可能为每一个用户每一种运行环境设计一套一样的系统。
所 以就要将一样的处理代码即业务逻辑和可能不一样的处理即数据存取逻辑分离开来,另一方面,关系型数据库中的数据基本都是以一行行的数据进行存取的,而程序 运行却是一个个对象进行处理,而目前大部分数据库驱动技术(如ADO.NET、JDBC、ODBC等等)均是以行集的结果集一条条进行处理的。所以为解决 这一困难,就出现 ORM 这一个对象和数据之间映射技术。
举例来说,比如要完成一个购物打折促销的程序,用 ORM 思想将如下实现(引自《深入浅出Hibernate》):
业务逻辑如下:
public Double calcAmount(String customerid, double amount)
{
// 根据客户ID获得客户记录
Customer customer = CustomerManager.getCustomer(custmerid);
// 根据客户等级获得打折规则
Promotion promotion = PromotionManager.getPromotion(customer.getLevel());
// 累积客户总消费额,并保存累计结果
customer.setSumAmount(customer.getSumAmount().add(amount);
CustomerManager.save(customer);
// 返回打折后的金额
return amount.multiply(protomtion.getRatio());
}
这 样代码就非常清晰了,而且与数据存取逻辑完全分离。设计业务逻辑代码的时候完全不需要考虑数据库JDBC的那些千篇一
律的操作,而将它交给 CustomerManager 和 PromotionManager 两个类去完成。这就是一个简单的 ORM 设计,实际的 ORM
实现框架比这个要复杂的多。
二.半自动框架和全自动框架的区别
2.1为什么说 Mybatis是半自动 ORM框架,而 Hibenate是全自动 ORM框架?
我们先来看看在持久层框架出现以前我们是如何对数据库进行操作的?
毋庸置疑,我们都使用 JDBC(Java Database Connectivity) 对数据库进行操作。操作步骤如下:
1、加载驱动程序
Class.forName(driverClass)
//加载MySql驱动
Class.forName(“com.mysql.jdbc.Driver”)
2、获取数据库连接
DriverManager.getConnection(“jdbc:mysql://localhost:3306/test”, “root”, “root”);
3、创建 Statement / PerparedStatement 对象
conn.createStatement();
conn.prepareStatement(sql);
4、操作数据库
stmt.executeQuery(“…”);
5、关闭连接
stmt.close();
conn.close();
2.2Mybatis的实现机制
1、读取 Mybatis的全局配置文件 mybatis-config.xml
2、创建 SqlSessionFactory会话工厂
3、创建 SqlSession会话
4、执行查询操作
mybatis-config.xml文件中包括一系列配置信息,其中包括标签 ,此标签配置了映射节点,映射节点内部定义了SQL语句。
Mybatis将 SQL的定义工作独立出来,让用户自定义,而 SQL的解析,执行等工作交由 Mybatis处理执行。
2.3Hibenate 的实现机制
1、构建 Configuration实例,初始化该实例中的变量
2、加载 hibenate.cfg.xml 文件到内存
3、通过 hibenate.cfg.xml 文件中的 mapping 节点配置并加载 xxx.hbm.xml 文件至内存
4、利用 Configuration实例构建 SessionFactory 实例
5、由SessionFactory 实例构建 session实例
6、由 session实例创建事务操作接口 Transaction 实例
7、执行查询操作
总结
传统的 jdbc 是手工的,需要程序员加载驱动、建立连接、创建 Statement 对象、定义SQL语句、处理返回结果、关闭连接等操作。
Hibernate 是自动化的,内部封装了JDBC,连 SQL 语句都封装了,理念是即使开发人员不懂SQL语言也可以进行开发工作,向应用程序提供调用接口,直接调用即可。
Mybatis 是半自动化的,是介于 jdbc 和 Hibernate之间的持久层框架,也是对 JDBC 进行了封装,不过将SQL的定义工作独立了出来交给用户实现,负责完成剩下的SQL解析,处理等工
三.动态sql(一对一,一对多,多对多)的理解
通过Mybatis的学习,我们大致了解了相关知识,并且可以使用基础的sql语句来操作数据库。在关系型的数据库中,表存在 ``
一对一,一对多,多对多的几种映射关系。映射关系是mysql的核心知识,在今后的工作我们也会经常用到这几种映射关系,
因此我们需要好好了解。
一、mybatis 一对一映射关系
1.一对一映射关系
- 什么是一对一映射关系?:从数据库的角度出发就是在任意一个表中引入另外一个表的主键作为外键。在本类的定义中定义另外一个类的对象。
- 在mybatis中,我们通过resultMap元素的子元素 association来进行处理。
- association元素具有以下配置属性
- 属性名称 作用
property 指定映射到的实体类对象属性,与表字段一一对应
column 指定表中对应的字段
select 指定引入嵌套查询的子SQL 语句,该属性用于关联映射中的嵌套查询。
javaType 指定映射到实体对象属性的类型
用户表和订单表的关系为,一个用户有多个订单,一个订单只从属于一个用户
一对一查询的需求:查询一个订单,与此同时查询出该订单所属的用户

对应对应的sql语句:
-
select * from orders;
-
select * from user where id=查询出订单的uid;
使用注解配置Mapper
@Select("select * from orders")/*因为order 表中有user对象,跟查询的字段都不匹配,所以需要我们人为的封装*/
@Results({
@Result(column = "id",property = "id"),
@Result(column = "ordertime",property = "ordertime"),
@Result(column = "total",property = "total"),
@Result(
property = "user", //要封装的属性名称
column = "uid", //根据哪个字段去查询user表的数据
javaType = User.class, //要封装的实体类型
//select属性 代表查询那个接口的方法获得数据
one = @One(select = "mapper.UserMapper.findById")
)
})
public List<Order> findAll();
public interface OrderMapper {
List<Order> findAll();
}
二、mybatis 一对多映射关系
1.一对多映射关系
-
什么是一对多关系:一对多关系就是表A中一条数据对应表B中的多条数据,例如,用户和订单之间的关系,一个用户可以有多个订单信息。
-
用户表和订单表的关系为,一个用户有多个订单,一个订单只从属于一个用户
一对多查询的需求:查询一个用户,与此同时查询出该用户具有的订单
- 在mybatis中,我们通过resultMap元素的子元素 collection来进行处理。
属性名称
作用
property 指定映射到的实体类对象属性,与表字段一一对应
column 指定表中对应的字段
select 指定引入嵌套查询的子SQL 语句,该属性用于关联映射中的嵌套查询。
javaType 指定映射到实体对象属性的类型
ofType ofType 属性与javaType 属性对应,它用于指定实体对象中集合类属性所包含的元素类型。
对应的sql语句
select * from user;
select * from orders where uid=查询出用户的id;
public interface UserMapper {
@Select("select * from user")
@Results({
@Result(id = true,property = "id",column = "id"),
@Result(property = "username",column = "username"),
@Result(property = "password",column = "password"),
@Result(property = "birthday",column = "birthday"),
@Result(property = "orderList",column = "id",
javaType = List.class,
many = @Many(select = "mapper.OrderMapper.findByUid"))
})
List<User> findAllUserAndOrder();
}
public interface OrderMapper {
@Select("select * from orders where uid=#{uid}")
List<Order> findByUid(int uid);
}
三、mybatis 多对多映射关系
1.多对多映射关系
什么是多对多关系: 一对多关系就是表A中一条数据对应表B中的多条数据,例如,用户和订单之间的关系,一个用户可以有多个订单信息。
在mybatis中,与一对多映射一致,我们通过resultMap元素的子元素 collection来进行处理。这里就不再多collection元素属性与上文一致。
用户表和角色表的关系为,一个用户有多个角色,一个角色被多个用户使用
多对多查询的需求:查询用户同时查询出该用户的所有角色

需要注意的是:在一对多映射和多对多映射中,collection 元素属行中使用的是ofType属性来指定实体对象,而不是使用JavaType属性。
public interface UserMapper {
@Select("select * from user")
@Results({
@Result(id = true,property = "id",column = "id"),
@Result(property = "username",column = "username"),
@Result(property = "password",column = "password"),
@Result(property = "birthday",column = "birthday"),
@Result(property = "roleList",column = "id",
javaType = List.class,
many = @Many(select = "com.itheima.mapper.RoleMapper.findByUid"))
})
List<User> findAllUserAndRole();}
public interface RoleMapper {
@Select("select * from role r,user_role ur where r.id=ur.role_id and ur.user_id=#{uid}")
List<Role> findByUid(int uid);
}
4.一级缓存,二级缓存
4.1、MyBatis的一级缓存(默认开启的)
[Mybatisde 的缓存主要针对是 Mubatis的查询功能,可以将当前查询的数据进行缓存,当下一次需要查询下相同的东西时,就不需要去mysql中区查询相同的数据,就会从缓存中直接获取,不会从数据库重新访问
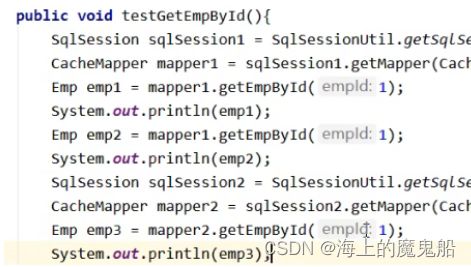
emp1是通过查询得到的,emp2是在缓存中查到的,emp3由于新建了一个sqlSession所以也是查询得到的
使一级缓存失效的四种情况:
-
不同的SqlSession对应不同的一级缓存
-
同一个SqlSession但是查询条件不同
-
同一个SqlSession两次查询期间执行了任何一次增删改操作
-
同一个SqlSession两次查询期间手动清空了缓存
4.2、MyBatis的二级缓存
二级缓存是SqlSessionFactory级别,通过同一个SqlSessionFactory创建的SqlSession查询的结果会被缓存;此后若再次执行相同的查询语句,结果就会从缓存中获取
SqlSessionFactory 有多个个方法创建SqlSession 实例。常用的有如下两个:

二级缓存开启的条件:
a>在核心配置文件中,设置全局配置属性cacheEnabled=“true”,默认为true,不需要设置
b>在映射文件中设置标签
<!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-data-redis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>2.7.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-cache -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
<version>2.7.0</version>
</dependency>
c>二级缓存必须在SqlSession关闭或提交之后有效
d>查询的数据所转换的实体类类型必须实现序列化的接口
使二级缓存失效的情况:
两次查询之间执行了任意的增删改,会使一级和二级缓存同时失效
四.对分页查询插件的了解
6.1plugins标签
MyBatis可以使用第三方的插件来对功能进行扩展,分页助手PageHelper是将分页的复杂操作进行封装,使用简单的方式即可获得分页的相关数据
开发步骤:
①导入通用PageHelper的坐标
②在mybatis核心配置文件中配置PageHelper插件
③测试分页数据获取
①导入通用PageHelper坐标
<!-- 分页助手 -->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>3.7.5</version>
</dependency>
<dependency>
<groupId>com.github.jsqlparser</groupId>
<artifactId>jsqlparser</artifactId>
<version>0.9.1</version>
</dependency>
②在mybatis核心配置文件中配置PageHelper插件
<!-- 注意:分页助手的插件 配置在通用馆mapper之前 -->
<plugin interceptor="com.github.pagehelper.PageHelper">
<!-- 指定方言 -->
<property name="dialect" value="mysql"/>
</plugin>
③测试分页代码实现
@Test
public void testPageHelper(){
//设置分页参数
PageHelper.startPage(1,2);
List<User> select = userMapper2.select(null);
for(User user : select){
System.out.println(user);
}
}
获得分页相关的其他参数
//其他分页的数据
PageInfo<User> pageInfo = new PageInfo<User>(select);
System.out.println("总条数:"+pageInfo.getTotal());
System.out.println("总页数:"+pageInfo.getPages());
System.out.println("当前页:"+pageInfo.getPageNum());
System.out.println("每页显示长度:"+pageInfo.getPageSize());
System.out.println("是否第一页:"+pageInfo.isIsFirstPage());
System.out.println("是否最后一页:"+pageInfo.isIsLastPage());
五.延迟加载
一、延迟加载的定义与原理
延迟加载是开发过程中灵活获取对象的一种求值策略,该策略在定义目标对象时并不会立即计算实际对象值,而是在该对象后续被实际调用时才去求值。在计算机科学中,延迟加载对应一个专门术语:惰性求值,其维基百科定义如下。
在编程语言理论中,惰性求值(Lazy Evaluation),又译为惰性计算、懒惰求值,也称为传需求调用(call-by-need),是计算
机编程中的一个概念,目的是要最小化计算机要做的工作。延迟求值特别用于匿名式函数编程,在使用延迟求值的时候,表达
式不在它被绑定到变量之后就立即求值,而是在该值被取用的时候求值。
简单来说,延迟加载就是指表达式只在必要时才求值,而非被赋给某个变量时立即求值。与惰性求值相对应的是及早求值,其维基百科定义如下。
及早求值(Eager evaluation)又译热切求值,也被称为贪婪求值(Greedy evaluation),是多数传统编程语言的求值策略。在
及早求值中,表达式在它被约束到变量的时候就立即求值。这在简单编程语言中作为低层策略是更有效率的,因为不需要建造
和管理表示未求值的表达式的中介数据结构。
简单理解就是:在查询一对象时,它相关联的对象的查询尽量往后延时查询,延时到我们在程序需要访问相关系对象时,再查询相关联对象。
主要分为局部延时加载和全局延时加载。
二:分类
1.局部延时加载
在association、collection标签有一个fetchType属性,该属性的默认值为eager(立即加载)
fetchType="eager",如果想用延时加载设置fetchType=”Lazy”
2.全局延时加载
在核心配置文件中settings标签中的setting标签进行配置
所有的分表查询都使用延时加载,如果某一些不想使用延时加载,可以单独进行设置
fetchType=“eager”
三.为什么要使用延迟加载
其实是为了提高数据库的访问效率,因为往往设计到多表查询的时候,这样很影响查询效率 ,所以引入了延迟加载, 提高执行效率,来实现优化性能的目的,因为查询的表越少,效率越高。
四.在什么场合下使用延迟加载
按需加载,就是需要的时候才加载,比如订单表,加载订单数据的时候,如果只是用到订单信息,而不需要用户信息,这样就直接查询订单表,即可,但是如果需要用户信息,List orders 中遍历查出来的订单对象,调用order的getUser时,就会根据user_id 查询用户信息,实现按需加载!!
六.在Mybatis中"#“和”$"de 的区别是什么
MyBatis获取参数值的两种方式
MyBatis获取参数值的两种方式:${}和#{}
${}的本质就是字符串拼接,#{}的本质就是占位符赋值
${}使用字符串拼接的方式拼接sql,若为字符串类型或日期类型的字段进行赋值时,需要手动加单引
号;但是#{}使用占位符赋值的方式拼接sql,此时为字符串类型或日期类型的字段进行赋值时,
可以自动添加单引号
6.1、单个字面量类型的参数
若mapper接口中的方法参数为单个的字面量类型
此时可以使用${}和#{}以任意的名称获取参数的值,注意${}需要手动加单引号
6.2、多个字面量类型的参数
若mapper接口中的方法参数为多个时
此时MyBatis会自动将这些参数放在一个map集合中,以arg0,arg1...为键,以参数为值;以
param1,param2...为键,以参数为值;因此只需要通过${}和#{}访问map集合的键就可以获取相对应的值,注意${}需要手动加单引号
6.3、两者区别
#:
<select id="selectPerson" parameterType="int" resultType="hashmap">
SELECT * FROM PERSON WHERE ID = #{id}
</select>
参数符号:
#{id}
这就告诉 MyBatis 创建一个预处理语句参数,通过 JDBC,这样的一个参数在 SQL 中会由一个 “?” 来标识,并被传递到一个新的预处理语句中,就像这样:
// Similar JDBC code, NOT MyBatis…
String selectPerson = "SELECT * FROM PERSON WHERE ID=?";
PreparedStatement ps = conn.prepareStatement(selectPerson);
ps.setInt(1,id);
$:
默认情况下,使用#{}格式的语法会导致 MyBatis 创建预处理语句属性并安全地设置值(比如?)。这样做更安全,更迅速,通常也是首选做法,不过有时你只是想直接在 SQL 语句中插入一个不改变的字符串。比如,像 ORDER BY,你可以这样来使用:
ORDER BY ${columnName}
这里 MyBatis 不会修改或转义字符串,实质上是字符串拼接。
NOTE(注意) 以这种方式接受从用户输出的内容并提供给语句中不变的字符串是不安全的,会导致潜在的 SQL 注入攻击,因此要么不允许用户输入这些字段,要么自行转义并检验。
sql注入问题:
SQL注入就是将原本的SQL语句的逻辑结构改变,使得SQL语句的执行结果和原本开发者的意图不一样.
比如:使用Statement语句执行者,执行sql,会造成sql注入的问题,
String sql = “select * from tb_name where name= '”+varname+“’ and passwd=’”+varpasswd+“’”;
如果我们把[’ or ‘1’ = '1]作为varpasswd传入进来,执行查询的时候 sql会变成,
String sql = "select * from tb_name where name= ‘’ and passwd = ‘’ or ‘1’ = ‘1’,1=1是永远成立的,所以,前面的条件已经不起作用,
我们使用预编译语句执行者就可以避免这个问题,prepareStatement将sql预编译,传参数的时候,不会改变sql语句结构,就可以避免注入。