【 云原生 | kubernetes 】- kubeadm部署k8s集群(超详细)

Kubeadm 是 kubernetes 社区为了方便普通用户学习k8s,发起的一个简单上手的部署工具。不用把大量时间花费在搭建集群上面。
只需通过两条命令就可以部署一个k8s集群
#创建一个Master节点
$ kubeadm init
# 将一个Node节点加入到当前集群中
$ kubeadm join
安装Kubeadm
实验环境:CentOS7.9
前期准备
- 确认linux内核版本在3.10以上
- 确认Cgroups模块正常
- 确认kubernetes的默认工作端口没有被占用
环境准备(所有机器下操作这一步骤)
- 在所有节点上同步/etc/hosts
[root@master ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.100.10 master
192.168.100.20 slave1
192.168.100.30 slave2
- 在所有节点上配置防火墙和关闭selinux
[root@master ~]# systemctl stop firewalld
[root@master ~]# setenforce 0
- 在所有节点上关闭swap分区,
[root@master ~]# sed -i '/swap/s/UUID/#UUID/g' /etc/fstab
[root@master ~]# swapoff -a ##临时关闭
- 在所有节点配置好yum源
[root@master ~]# wget -c http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
[root@master ~]#cat < /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
- 在所有节点上安装并启动docker,并设置开机自启
#选择自己想要的版本
[root@master ~]# yum list docker-ce --showduplicates|grep "^doc"|sort -r
docker-ce.x86_64 3:20.10.9-3.el7 docker-ce-stable
docker-ce.x86_64 3:20.10.8-3.el7 docker-ce-stable
docker-ce.x86_64 3:20.10.8-3.el7 @docker-ce-stable
docker-ce.x86_64 3:20.10.3-3.el7 docker-ce-stable
[root@master ~]# yum -y install docker-ce-20.10.8-3.el7
[root@master ~]# systemctl enable docker && systemctl start docker
查看确认Docker是否安装成功
[root@master ~]# docker version
Client: Docker Engine - Community
Version: 20.10.18
API version: 1.41
Go version: go1.18.6
Git commit: b40c2f6
Built: Thu Sep 8 23:14:08 2022
OS/Arch: linux/amd64
Context: default
Experimental: true
- 在所有节点设置内核参数(云主机略)
[root@master ~]# cat < /etc/sysctl.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
[root@master ~]# sysctl -p #让其生效
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
[root@master ~]#
注意:如果发现如下错误
#sysctl: cannot stat /proc/sys/net/bridge/bridge-nf-call-ip6tables:没有那个文件或目录
#sysctl: cannot stat /proc/sys/net/bridge/bridge-nf-call-iptables:没有那个文件或目录
#net.ipv4.ip_forward = 1
可通过modrobe br_netfilter 解决,会自动加载br_netfilter模块
- 在所有节点安装软件包
[root@master ~]# yum install -y kubelet-1.21.0-0 kubeadm-1.21.0-0 kubectl-1.21.0-0 --disableexcludes=kubernetes
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
·······
Complete!
[root@master ~]# systemctl restart kubelet ; systemctl enable kubelet
Created symlink from /etc/systemd/system/multi-user.target.wants/kubelet.service to /usr/lib/systemd/system/kubelet.service.
部署Kubernetes
master节点
通过kubeadm查看所需的镜像
[root@master ~]# kubeadm config images list
k8s.gcr.io/kube-apiserver:v1.21.14
k8s.gcr.io/kube-controller-manager:v1.21.14
k8s.gcr.io/kube-scheduler:v1.21.14
k8s.gcr.io/kube-proxy:v1.21.14
k8s.gcr.io/pause:3.4.1
k8s.gcr.io/etcd:3.4.13-0
k8s.gcr.io/coredns/coredns:v1.8.0
拉取镜像
默认的gcr镜像我们是无法之间访问的,我们可以从阿里镜像获取,
#!/bin/bash
image_name=(
kube-apiserver:v1.21.14
kube-controller-manager:v1.21.14
kube-scheduler:v1.21.14
kube-proxy:v1.21.14
pause:3.4.1
etcd:3.4.13-0
coredns:v1.8.0
)
aliyun_registry="registry.aliyuncs.com/google_containers/"
for image in ${image_name[@]};do
docker pull $aliyun_registry$image
echo "###########################################################################"
done
docker tag registry.aliyuncs.com/google_containers/coredns:v1.8.0 registry.aliyuncs.com/google_containers/coredns/coredns:v1.8.0
exit
Docker配置cgroup-driver
由于 cgroup-driver ,默认docker 是 cgroupfs ,而k8s 默认是 systemd,所以需要设置 docker 的 cgroup 为 systemd
修改Docker配置文件,然后加载配置并重新启动Docker
vim /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
[root@master ~]# systemctl daemon-reload
[root@master ~]# systemctl restart docker
部署
现在在master上执行初始化操作
[root@master ~]# kubeadm init --image-repository registry.aliyuncs.com/google_containers --kubernetes-version=v1.21.0 --pod-network-cidr=10.244.0.0/16
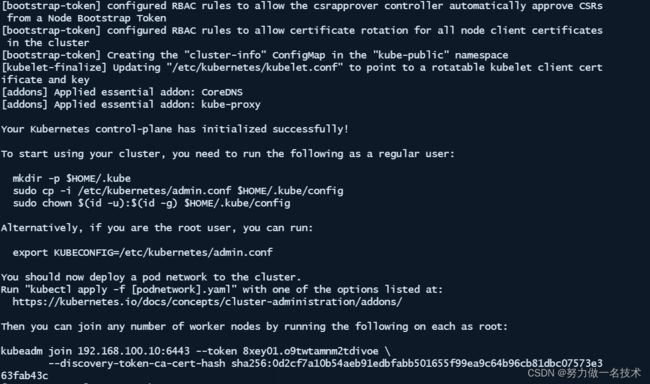
这里我们master节点已经安装成功,
根据提示运行下列命令
[root@master ~]# mkdir -p $HOME/.kube
[root@master ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config
[root@master ~]# export KUBECONFIG=/etc/kubernetes/admin.conf
Kubernetes 集群默认需要加密方式访问。所以这几条命令,就是将刚刚部署生成的 Kubernetes 集群的安全配置文件,保存到当前用户的.kube 目录下,kubectl 默认会使用这个目录下的授权信息访问 Kubernetes 集群。
slave节点
配置slave加入集群
下面的步骤是把slave1和slave2以worker的身份加入到kubernetes集群。
- 在slave1和slave2分别执行。
kubeadm join 192.168.100.10:6443 --token 8xey01.o9twtamnm2tdivoe \
--discovery-token-ca-cert-hash sha256:0d2cf7a10b54aeb91edbfabb501655f99ea9c64b96cb81dbc07573e363fab43c
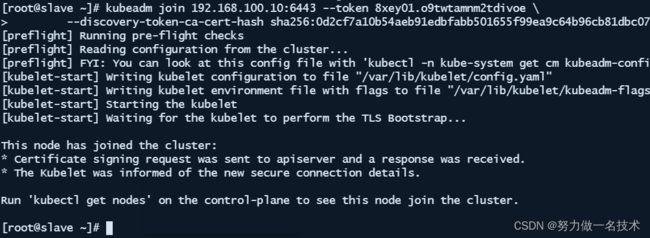
部署网络插件
安装calico
[root@master ~]# kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.24.1/manifests/tigera-operator.yaml
[root@master ~]# curl -O https://raw.githubusercontent.com/projectcalico/calico/v3.24.1/manifests/custom-resources.yaml
需要更改默认 IP 池 CIDR 以匹配您的 pod 网络 CIDR。然后部署,默认在calico-system命名空间
[root@master ~]# vi custom-resources.yaml
··········
cidr: 192.168.0.0/16 替换为 cidr: 10.244.0.0/16
··········
[root@master ~]# kubectl apply -f custom-resources.yaml
installation.operator.tigera.io/default created
apiserver.operator.tigera.io/default created
cidr和初始化集群时保持一致
查看其状态
[root@master ~]# kubectl get po -n calico-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-78687bb75f-62zrs 1/1 Running 0 7m48s
calico-node-78sqm 1/1 Running 0 7m49s
calico-node-f7wb6 1/1 Running 0 7m49s
calico-node-s7qm3 1/1 Running 0 7m49s
calico-typha-84cfb44987-vbrq9 1/1 Running 0 7m49s
csi-node-driver-4dn68 2/2 Running 0 4m21s
可以使用 kubectl get 命令来查看当前节点的状态
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready control-plane,master 8m v1.21.0
slave1 Ready <none> 11m v1.21.0
slave2 Ready <none> 11m v1.21.0
查看组件健康情况
[root@master ~]# kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused
controller-manager Unhealthy Get "http://127.0.0.1:10252/healthz": dial tcp 127.0.0.1:10252: connect: connection refused
etcd-0 Healthy {"health":"true"}
这里提示我们scheduler和controller-manager不健康的,我们先查看下其服务端口是否正常
[root@master ~]# netstat -ntpl | grep contro
tcp 0 0 127.0.0.1:10257 0.0.0.0:* LISTEN 3197/kube-controlle
[root@master ~]# netstat -ntpl | grep scheduler
tcp 0 0 127.0.0.1:10259 0.0.0.0:* LISTEN 3313/kube-scheduler
我们发现这两个服务都正常运行,只不过检测端口不一致,
解决问题
[root@master ~]# kubectl edit po kube-controller-manager-master -n kube-system
········
- --port=0 ###注释掉或删除此行,scheduler同样操作,edit 时需要确认,pod的名称
该–port=0表示禁止使用非安全的http接口,同时 --bind-address 非安全的绑定地址参数失效
再次查看组件,一切正常
[root@master ~]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy {"health":"true"}
这里我们的集群部署就结束了