refinedet:Single-Shot Refinement Neural Network for Object Detection
这是中国科学院自动化所在CVPR2018发表的论文。
论文链接:https://arxiv.org/abs/1711.06897
pytorch代码链接:https://github.com/luuuyi/RefineDet.PyTorch
Refinedet模型大致上是将RPN、SSD和FPN融合到了一起。
对于物体检测任务而言,两个阶段的方法two stage method(比如faster RCNN及其变体)能够获得较高的性能,而一个阶段的方法one stage method(比如YOLO,SSD)性能/准确率虽然不如two stage method,但是其速度快很多。Refinedet网络希望融合两种类型detector的优点,实现性能好、检测速度快的检测器。
two stage object detector:通常是sparse detection稀疏检测,首先通过传统的图像处理算法(如selective search)或者RPN(卷积网络模型)产生一些region proposal,这些被称为候选框,也就是通过传统特征提取或者深度学习的特征提取并进行前景和背景的分类之后,很大概率上是前景框的候选框,然后再对这些region proposal进行位置微调,得到最终所预测的包围框。也就是说,两个阶段的检测器可以认为是具有cascaded的结构,进行了coarse-to-fine的位置调整,先由RPN预测出粗略的位置,再由Fast RCNN进行位置精修,这样会获得较高的检测性能,但是速度会很慢。两个阶段的检测器在很多数据集上(如PASCAL VOC和MS COCO)都能超过一个阶段的检测器,达到最高的性能。
one stage object detector:通常是dense detection密集检测。即通过在特征图的每个像素点(对应到原始输入图像上的一个图像块)上产生一系列固定面积、宽高比的anchor boxes,然后由网络预测出这些anchor boxes相比于ground truth boxes之间的偏移量。one stage method的速度很快,但是检测性能准确率通常不如two stage method,其中一个很大的原因就是类别不平衡问题,因为one stage method产生的anchor boxes中有很大的一部分是都是背景框(negative examples)。当然,之前跟老师讨论过,one stage object detector性能比two stage object detector差很多的原因很大程度上是因为,two stage object detector进行了两次的位置调整,具有级联的结构,故而能输出更准确的位置偏移量。
其实无论是one stage object detector或者是two stage object detector,都会物体检测中非常常见的问题:样本类别不平衡,即会面临非常多的负样本,处理这个问题的常用策略有以下两种:(1)kaiming大神的focal loss,alpha是类别不平衡的权重,而gamma能够让loss函数更多倾向于那些loss值非常大的样本(即困难样本)(2)OHEM:on line hard example mining,在线困难样本挖掘, 按照1:60, 1:30, 1:10, 1:5, 1:3的比例这样递减,前面5个epoch, 1:60, 然后调整成1:30, 再跑5个epoch, 再调整成1:10跑5个epoch,依次类推,这是工程经验了,一般的SSD中就设置的固定比例,正负样本1:3.对于所有正样本的loss值取出,然后将所有负样本对应的loss值取出,从大到小排序,取出前3*(pos_num)个负样本对应的loss值,与所有正负样本的loss值相加,再除以正样本的数量pos_num,则得到分类损失值。对于两个阶段的物体检测器,OHEM通常用在RPN的地方,因为RON相当于一层的SSD,RPN和SSD一样都属于密集检测,故而都会出现正负样本不平衡的问题。
这里其实有个问题需要注意,就是物体检测处理的通常是两个类别的类别不平衡问题。这使用focal loss和OHEM都可以,但是focal loss通常可以处理多个类别的不平衡问题,而OHEM通常是处理两个类别的不平衡问题,focal loss考虑了各个类别样本的权重,而OHEM一般不考虑。比如对于图像的语义分割问题,如果图像中只存在背景和前景两个类别,则使用focal loss和OHEM均可以,但是如果图像中存在多个前景类别,则最好使用focal loss,而很少使用OHEM。
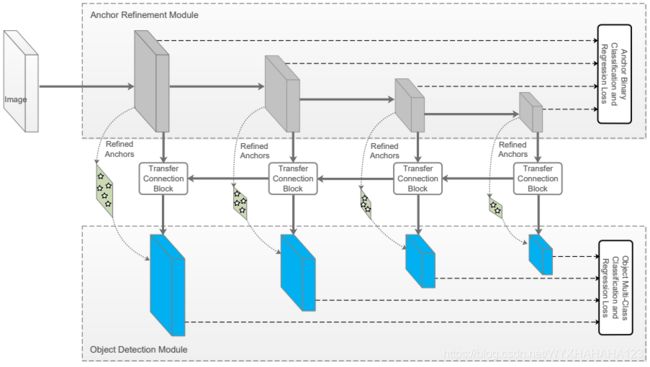
RefineDet网络主要由以下三个模块构成:
1.anchor refinement module ARM:功能类似于RPN,只不过是在多个不同尺度的特征图上进行了anchor boxes的预测(实际上就可以看作是SSD+FPN,只不过RefineDet把SSD的预测结果看成了region proposal,还需要ODM模块对于region proposal的位置进行微调)(1)首先类似于SSD的操作,在4个不同尺度的特征图上:分别是output stride=8,16,32,64(要注意,一般的经典分类网络如resnet系列和VGG,output stride=32,故而这里的64需要额外进行下采样),在每个尺度的特征图上按照固定的先验areas和aspect ratio设置,产生anchor boxes,然后每个尺度的特征图分别预测出coordinate bbox deltas和前景/背景confidence,这里类似于RPN只进行二分类,(注意在ARM的前向传播过程中并没有用到FPN模型,只是单纯地卷积核和下采样,在ODM模块中使用的特征图才是经过FPN融合了高阶语义特征图的feature map),(2)ARM的一个重要作用就是产生region proposal(具体包括滤除高概率的负样本和对anchor 的位置粗略调整),从大量的anchor boxes中滤除负样本,在测试阶段和训练阶段都是需要滤除负样本anchor boxes:ARM对于在特征图上产生的anchor boxes进行前景/背景类别预测,经过softmax函数后,产生对于两个类别的概率预测值,将所有背景分数大于0.99(事先设定的阈值)的anchor boxes滤除,不送入ODM模块中,ARM中滤除负样本的机制可以有效减少ODM模块的搜索空间。对于训练阶段所设置的滤除负样本阈值是0.99,在inference阶段则需要另外设定。
ARM预测的region proposal的特征图和ODM模块进行位置精修所使用的特征图不同,而在faster RCNN中RPN和Fast RCNN所使用的特征图相同,Fast RCNN根据RPN所提出的region proposal在两个模块shared feature map上抠取特征块(ROI Align),然后进行后续的分类和位置精修,之前有结论说ROI Pooling(无论是使用ROI Pooling ROI Cropping或者是精度最高的ROI Align),都会对于region proposal的卷积特征产生进一步的损失,而RefineDet则很巧妙地避免了从shared feature map上进行抠图,而是将ARM模块中下采样所使用到4个不同尺度的特征图通过FPN方式连接起来,以实现对于ARM输出的region proposal进行类别细分和位置精修。
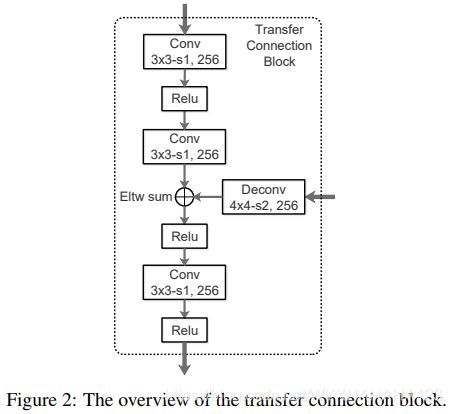
2.transfer connection block TCB:
TCB模块就是模仿two stage detector中的ROI Align层,也就是根据RPN产生的region proposal,产生候选框所对应的特张图或者特征块
3.object detection module:ODM 类似于Faster RCNN中Fast RCNN模型的功能,对于ARM所提出的region proposal (包括所有负样本分数值小于固定阈值的region proposal,这里称为候选框而不是anchor boxes,是因为ARM已经对于anchor boxes进行了anchor的refinement)位置进行精修。(这点靠看代码进行考证)
ARM所基于的backbone来自于resnet101或者VGG16,
物体检测的目标实际上就是通过深度神经网络输出一系列带有class confidence 的bounding boxes。
RefineDet的两步级联回归(two stage cascaded regression)
one stage method由于对于anchor boxes只有一次的位置调整,故而对于小物体的检测非常不准确。
RefineDet是基于在特征图上产生固定数量的anchor boxes(假设在特征图上的每个像素点上设置n个anchor boxes,n=num_aspect_ratos*num_scales,通常n=9),对于不同内容但分辨率相同的输入图像,anchor boxes在输入图像分辨率上的位置通常都是固定的,在特征图的每个像素点上,ARM为该点上的n个anchor boxes预测出相对于当前anchor boxes的位置偏移量和前景背景的分数,故而经过ARM后将会得到每个特征图上每个像素点上的n个带有前景背景分数和位置偏移量的anchor boxes(经过ARM修正后的anchor boxes被称为refined anchor boxes),然后通过ARM模块中前向传播的CNN(注意ARM中仅仅包括卷积层和下采样层,并不包含上采样层和FPN),预测出每个anchor boxes的类别(前景/背景)和位置偏移量,将背景概率值大于一定阈值的anchor boxes滤除掉,将剩下的region proposal送入ODM,这个送入的过程中是需要将ARM中对应特征图上产生的region proposal输入到ODM中对应level的特征图上进行进一步预测的,ODM进行预测所基于的特征图来自于TCB,即对于ARM前向传播得到的4个不同尺度的特征图经过FPN融合了高阶语义信息后得到的高分辨率高级的特征图,在这些特征图上对于region proposal进行多个前景类别和背景的分类,并进行位置精修,ODM的位置偏移量ground truth是相对于ARM输出的region proposal编码。RefineDet对于小物体的检测性能特别好。
损失函数:
