【论文笔记】A Transformer-based Siamese network for change detection
论文

论文题目:A TRANSFORMER-BASED SIAMESE NETWORK FOR CHANGE DETECTION
投稿至:CVPR2022
论文地址:https://arxiv.org/abs/2201.01293
论文代码:GitHub - wgcban/ChangeFormer: A Transformer-Based Siamese Network for Change Detection
摘要
论文提出了一种基于Transformer的孪生网络结构(ChangeFormer),用于从一对已配准的遥感图像中进行变化检测(change detection,CD)。
与目前基于全卷积网络的CD框架不同,该方法将分层结构的Transformer编码器与多层感知(MLP)解码器结合在一个孪生网络结构中,有效地呈现精确CD所需要的多尺度远程细节。
在两个公开CD数据集(LEVIR-CD和DSIFN-CD)上取得最优效果。

1 引言
变化检测(CD)目的是检测不同时间获得的一对已配准图像的相关变化。
目前SOTA的CD方法主要基于深度卷积网络ConvNet,因为其具有强大的特征提取能力。
注意力机制能捕获全局信息,但难以关联时空上的长距离信息。
Transformer网络具有更大的有效接受域(ERF)——在图像中任何一对像素之间提供比卷积神经网络强得多的上下文建模能力。最近比较火的Tranformer在CV方面(图像分类、分割)表现出其强大的性能,如ViT、SETR、Swin、Twins和SegFormer等。
虽然Transformer具有更大的接收域和更强的上下文塑造能力,但有关于CD的工作却很少。
Transformer结构与ConvNet编码器(ResNet18)结合使用,能增强特征表示,同时保持基于ConvNet的整体特征提取过程。
本文表明,这种对ConvNet的依赖是非必须的,可以仅使用一个Transformer编码器 + 一个轻量MLP解码器 完成变化检测任务。
2 方法
ChangeFormer网络如图所示。

大概流程:
- 构成孪生网络的分层Transformer编码器(hierarchical transformer encoder)用于提取双时间图像的粗粒度和细粒度特征;
- 四个差异模块(difference modules)计算多尺度特征差异;
- 一个轻量MLP解码器(lightweight MLP decoder)融合这些多尺度特征差异并预测CD mask。
2.1 Hierarchical Transformer Encoder
给定一个输入的双时间图像,用分层Transformer编码器生成多级特征,具有变化检测所需要的高分辨率和低分辨率特征。用Difference Module处理后传入MLP解码器获得变化特征。
主要组成部分: Transformer Block、 Downsampling、 Diffrence Module
Transformer Block

为减少计算量,首先使用Sequence Reduction对图像进行处理,缩小图像。
先利用序列约简比率R对输入patch进行reshape,减小尺寸,扩展通道数。再对通道数进行线性映射到原始通道数。
为增加位置信息,使用两个MLP层和一个深度可分离卷积。不同于ViT的绝对位置编码,这里使用的是相对位置编码,可以在测试时使用不同于训练时的分辨率的图像。


Downsampling
下采样,每个Transformer Block之前都接着一个Downsampling Block,对输入的patch进行下二分之一采样,减小尺寸。 再经历Transformer提取特征,也因此生成了多尺度的差异特征。

Difference Module
共有4个差异模块,接收来自孪生网络两条分支的4种不同尺寸的特征,并进行拼接,再卷积。
并没有使用绝对差值,而是在训练过中学习每个尺度上的最优举例度量。

2.2 MLP Decoder

MLP解码器: 聚合多级特征差异图来预测变化图。
3个主要步骤: MLP & Upsampling、 Concatenation & Fusion、 UPsampling & Classification
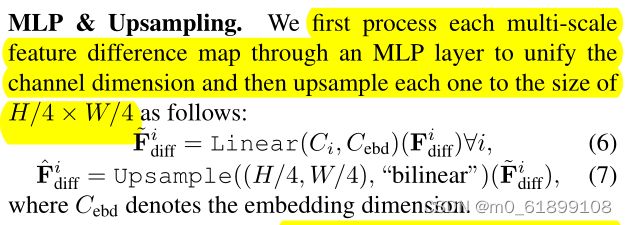
首先利用MMLP层对多尺度差异特征进行处理,上采样到特定尺寸 H/4*W/4 。
再将四个差异特征在通道维度进行拼接,再利用MLP层融合这些特征。
利用转置卷积将融合的特征进行上采样到H*W。
最后,通过另一个MLP层处理H*W*Ncls的特征图,实现分类。


3 实验设置
数据集:两个公开CD数据集:LEVIR-CD 和DSIFN-CD,不重叠切块。
实施细节:随机初始化网络,训练时数据增强,使用交叉熵损失和AdamW优化器。
性能指标:F1,IOU,precision,recall,OA(overall accuarcy)



4 结果讨论

从表中可以看出,关于F1、IoU、OA值,相较于SOTA,
- 在数据集LEVIR-CD中,ChangerFormer分别提高了 1.2%、2.0%、0.1%;
- 在DSIFN-CD中,ChangerFormer分别提高了17.4%、23.5%、6.1%。
视觉化效果如下图:

5 结论
- 提出一个基于Transformer的变化检测孪生网络。
- 网络架构:一个孪生结构的分层Transformer编码器 + 一个简单的MLP解码器。
- 通过比较实验,表明不需要依赖深度ConvNet结构,一个带有轻量MLP解码器的孪生网络就可以很好的实现变化检测。