【Pytorch Lighting】第 4 章:Lightning Flash 中的即食模型
大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
个人主页-Sonhhxg_柒的博客_CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟
文章目录
技术要求
Lightning Flash入门
Flash就像1-2-3一样简单
使用 Flash 进行视频分类
慢速和慢速架构
导入库
加载数据集
配置backbone
微调模型
使用模型进行预测
进一步学习的后续步骤
使用 Flash 进行自动语音识别
安装库
导入库
加载数据集
配置backbone
微调模型
使用模型进行语音预测
进一步学习
概括
构建深度学习( DL ) 模型通常涉及从该领域的顶尖研究论文中重新创建现有架构或实验。例如,AlexNet是 2012 年ImageNet的获奖卷积神经网络( CNN ) 架构计算机视觉挑战。许多数据科学家已经为他们的业务应用程序重新创建了该架构,或者基于它构建了更新更好的算法。在进行自己的实验之前,对数据重复使用现有实验是一种常见的做法。这样做通常涉及阅读原始研究论文以对其进行编码,或者访问作者的 GitHub 页面以了解什么是什么,这都是耗时的选择。如果 DL 中最流行的架构和实验可以很容易地用于执行各种常见的 DL 任务作为框架的一部分呢?认识 PyTorch Lighting!
Flash 提供开箱即用的功能来重新创建流行的深度学习架构,例如图像分类、语音识别和表格数据预测,以便快速实验、原型设计和引导您的模型基线。预定义的开箱即用任务集合非常丰富,跨越各个领域。在图像问题中,它为多个图像任务提供样板代码,例如分割、对象检测、风格迁移和视频分类。在 NLP 中,Flash 还提供了丰富的开箱即用功能,用于进行摘要、分类、问答和翻译。数据科学家还可以轻松地使用标准数据集来训练模型(例如 MNIST 和 ImageNet),并且可以使用现有架构和易于使用的 GPU、CPU 和 TPU 选项进一步重新训练他们的模型。Flash 还通过将一个模型的输出作为另一个模型的输入,为开展新研究提供了一种更简单的方法。Flash 不仅限于 DL 模型,还适用于传统模型表格/CSV 数据集上的机器学习( ML ) 任务,例如时间序列预测问题或多类分类。
在本章中,我们将看到使用 Flash 构建自己的深度学习模型是多么快速和容易。它提供了最高级别的抽象,以使用最少的编码为常见的 DL 任务创建基线模型。对于该领域的初学者和从业者来说,它是一个很好的工具,可以对流行的架构进行快速实验。
我们将简要介绍一些最常用的任务,例如语音识别和视频分类,以及最新的 DL 架构,例如 wav2vec。我们将看到如何使用一些流行的实验数据集以及我们自己的数据集来获得结果。本章将帮助您熟悉 Flash,并向您展示如何使用复杂的 DL 架构,而无需费心理解底层算法的复杂性。这应该让您为解决我们将在后续章节中看到的更高级的问题(例如 GAN 或半监督学习)做好准备。
在本章中,我们将介绍以下用例:
- 使用 Bolts 进行视频分类
- 使用 Bolts 进行自动语音识别
技术要求
本章的代码已经在 macOS 上使用 Anaconda 或 Google Colab 和 Python 3.6 开发和测试。如果您使用的是其他环境,请对您的环境变量进行适当的更改。
在本章中,我们将主要使用以下 Python 模块,并在其版本中提及:
- PyTorch Lightning (version 1.5.10)
- Flash (version 0.7.1)
- Seaborn (version 0.11.2)
- NumPy (version 1.21.5)
- Torch (version 1.10.0)
- pandas (version 1.3.5)
源数据集可在Kinetics 400 数据集源中找到:https ://deepmind.com/research/open-source/kinetics 。
这是 DeepMind 通过抓取 YouTube 视频创建的视频分类数据集。动力学数据集由 Google Inc. 提供,是最常用的基准测试数据集之一。
Lightning Flash入门
想象你有心情吃印度菜。您可以通过多种方式进行烹饪。你可以得到所有的蔬菜、用来做面团的面粉和最重要的香料,然后你将它们一一碾碎。准备好后,您可以按照正确的程序进行烹饪。不用说,这样做需要对香料有丰富的了解,以及哪种咖喱加入哪种咖喱、数量、顺序以及需要煮多长时间。
如果您认为自己不是专家,第二种选择是使用即用型香料(例如鸡肉 tikka masala 或 biryani masala),然后将它们添加到您的原料中并烹饪。虽然这绝对比第一步简化了烹饪,但这仍然需要一些烹饪,但不用太担心细节,你仍然可以获得好的结果。
但即使是第二个选项也有点耗时,如果你想快速获得它,那么你可以尝试“即食”餐,并通过将其与米饭或洋葱混合并调整香料水平来加热它如所须。不出所料,最快的结果来自第三个选项,有点像闪电。
顾名思义,Lightning Flash 是准备好 DL 模型的最快方法。就 PyTorch 上的编码而言,它是最高级别的抽象。如果在 PyTorch 中编码就像从头开始做饭,那么 PyTorch Lightning 本身就是一个抽象层,类似于使用现成的香料来快速做饭。Lightning Flash 是比 PyTorch Lightning 更高的抽象。这就像一堆在架子上准备好的饭菜,你可以挑选然后快速吃掉。
闪电闪光附带了涵盖大多数流行 DL 应用程序的各种任务。它带有用于加载数据的简单钩子,以及对大多数流行数据集和经过验证的网络架构的访问。对于希望依靠学术界的最佳架构开始的行业从业者来说,这是一个特别有吸引力的选择。它用作快速原型设计和生成基线模型的基线模型。
闪电是社区构建,并且开箱即用支持的任务列表不断增加。目前,它支持以下内容:
- 用于分割、分类、对象检测、关键点检测、实例分割、风格迁移等的图像和视频任务
- 语音识别和分类的音频任务
- 表格数据分类和时间序列预测
- 用于分类、问答、总结和翻译的 NLP 任务
- 用于分类的图学习任务
在本章中,我们将看到如何使用 Flash 完成一些任务。
Flash就像1-2-3一样简单
我们从创建 CNN 形式的第一个深度学习模型开始这本书。然后我们使用迁移学习来查看我们可以通过使用在流行数据集上学习的表示来获得更高的准确性并训练模型更快。Lightning Flash 通过提供标准化框架让您快速访问所有预训练模型架构以及一些流行的数据集,将其提升到另一个层次。
使用 Flash 意味着编写一些最小形式的代码来训练 DL 模型。事实上,一个简单的 Flash 模型可以像五行代码一样轻量级。
导入库后,我们只需执行三个基本步骤:
- 提供您的数据:创建一个数据模块以向框架提供数据:
datamodule = yourData.from_json( "yourFile", "text", - 定义你的任务和主干:现在,是时候定义你想对数据做什么了。您可以从前面列出的各种任务(分类、分段等)中进行选择。对于每个任务,都有一个主干列表——即一些可供选择的预定义网络架构。这样的主干为您提供开箱即用的卷积层:
model = SomeRecogntion(backbone="somemodelarchitecture/ResNET50") - 微调模型:现在,您已准备好使用训练器类训练模型并在数据集上进行微调。正如我们在前一章中看到的,所有控制训练的好东西(epochs 和 GPU 选项)都可供您管理训练:
trainer = flash.Trainer(max_epochs=1, gpus=torch.cuda.device_count()) trainer.finetune(model, datamodule=datamodule, strategy="no_freeze")
瞧!你完成了!下一步是进行预测。
与其查看 Flash 中的编码包括什么,不如注意它不包括什么。它排除了定义卷积层、全连接层和 softmax 层、优化器、学习率等的复杂性。当我们选择主干时,所有这些都隐藏在抽象墙后面。这就是为什么 Flash 使构建 DL 模型变得如此简单和快速的原因。
现在,可以切换数据集并将数据传递给数据模块。也可以从广泛的架构列表中进行选择。我们将尝试一一进行。我们将首先通过将视频分类模型换成不同的架构来训练它。稍后,我们将通过交换数据集来训练音频语音识别模型。
在我们开始之前,同样重要的是要了解没有免费的午餐。虽然 Flash 提供了最高和最简单的抽象级别,但同样的特性限制了它的灵活性。它最适合预定义的任务,如果您想执行其他任务、创建新架构或从头开始训练模型,它可能不是理想的选择。
回到我们的烹饪类比,即食食品的味道几乎无法控制。但是,由于它是基于 PyTorch Lightning 构建的,因此它与 PyTorch 完全向后兼容。在易用性和控制方面,也许 PyTorch Lightning 是执行新建模的黄金手段,并且是高级用例的推荐选项,而如果您想成为 DL 的主厨,那么您总是可以使用 PyTorch 走得更远。尽管如此,Flash 是一种很好的入门方式,所以让我们开始使用我们的第一个模型吧!
使用 Flash 进行视频分类
视频分类是DL 中最有趣但最具挑战性的问题之一。简单地说起来,它会尝试对视频剪辑中的动作进行分类并识别它(例如步行、保龄球或打高尔夫球):

图 4.1 - DeepMind 发布的 Kinetics 人体动作视频数据集由来自 YouTube 的带注释的约 10 秒视频剪辑组成
训练这样的 DL 模型是一个具有挑战性的问题,因为与表格或图像数据相比,视频文件的大小更大,训练模型需要大量的计算能力。使用预先训练的模型和架构是开始视频分类实验的好方法。
PyTorch 闪电内部依赖于PyTorchVideo库骨干。PyTorchVideo迎合了视频理解的生态系统。Lightning Flash 通过在底层框架中创建预定义和可配置的钩子来轻松实现。视频分类任务有一些钩子,您可以使用这些钩子,而不会被定义网络层、优化器或损失函数的细节所淹没。此外,Facebook AI 发布的 Model Zoo 中还有大量 SOTA 架构可供选择。Model Zoo 包含各种 SOTA 模型架构的视频任务基准。
在本节中,我们将使用 Kinetics 400 数据集,然后尝试开箱即用的不同视频分类架构来微调模型。
重要提示 - 模型动物园
PyTorch 视频的完整 Model Zoo 及其基准测试可在此处访问:https ://github.com/facebookresearch/pytorchvideo/blob/main/docs/source/model_zoo.md 。Model Zoo 由 Facebook AI 研究团队提供,并包含指向预训练模型的链接,以防您需要覆盖 Lightning Flash 提供的钩子。
慢速和慢速架构
慢快是一种广泛使用的视频分类模型架构。它基本上由两个路径组成,慢速和快速,用于视频分类。它首先由 Facebook AI Research 在Christoph Feichtenhofer 等人的SlowFast Networks for Video Recognition论文中提出:
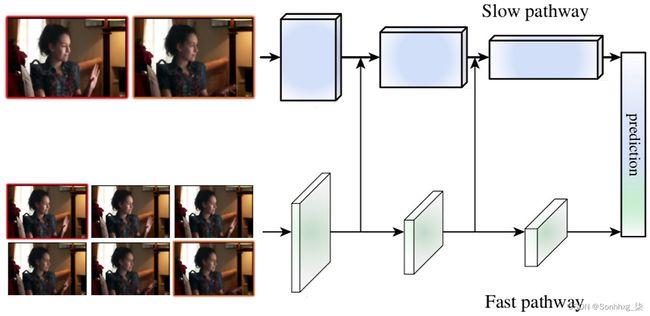
图 4.2——SlowFast 网络的高级图示(来源——SlowFast)
该模型建筑基于慢速和快速时间频率的概念来识别移动物体,这受到我们眼睛视网膜的启发。它由一个用于分析静态内容的高清慢速通道和一个用于分析动态内容的低清晰度快速通道组成。两种路径在内部都使用 CNN 的 ResNet 卷积架构,但使用不同的时间步长。快速路径使用较小的时间步幅但频率较高(每秒 15 帧),而慢速路径使用较大的时间步幅但频率较低(每秒 2 帧)。出于这个原因,慢速路径比快速路径的计算量更大。
虽然 SlowFast 架构的结果令人印象深刻,并且被认为是最好的(大约 94%),但也公布了仅使用慢速或快速架构的结果。慢速架构的结果也不错(大约 91%)。这两种模型架构(以及许多其他模型架构)在 Flash 中都是开箱即用的。在这个例子中,我们将使用慢速架构微调视频分类模型。
使用 Flash 的视频分类模型将包括以下五个步骤:
- 导入库
- 加载数据集
- 配置 backbone
- 训练和微调模型
- 基于模型预测动作
现在,我们将开始模型构建过程。
导入库
我们将开始以下步骤:
我们将从导入必要的库开始:
!pip install torch==1.10.0 torchvision==0.11.1 torchtext==0.11.0 torchaudio==0.10.0 --quiet
!pip install pytorch-lightning==1.5.10 --quiet
!pip install Lightning-flash==0.7.1 --quiet
!pip install 'lightning-flash [audio,image, video, text]' --quiet
!pip install Pillow==9.0.0安装后,您可以导入库:
import pytorch_lightning as pl
import torch
import pandas as pd
import numpy as np
import seaborn as sns
import flash
from flash.core.data.utils import download_data
from flash.video import VideoClassificationData, VideoClassifier在前面的步骤中导入库后,您可以检查版本:
print("pandas version:",pd.__version__)
print("numpy version:",np.__version__)
print("seaborn version:",sns.__version__)
print("torch version:",torch.__version__)
print("flash version:",flash.__version__)
print("pytorch ligthening version:",pl.__version__)此代码段应显示以下输出:

图 4.3 – 用于视频分类的包版本
现在,我们已准备好加载数据集。
加载数据集
数据集我们将在本节中使用 Kinetics 400 数据集。该数据集最初由 DeepMind 策划,包含 400 个用于视频分类任务的人类动作。视频剪辑动作包括一系列活动,例如体育运动或团体互动,例如跳舞。该数据集也可作为 Lightning Flash(和 PyTorch 视频)数据集集合的一部分。这使得直接加载数据集变得非常容易。
第一步,我们下载数据:
download_data("https://pl-flash-data.s3.amazonaws.com/kinetics.zip", "./data")从 Flash 服务器下载数据集后,我们可以将数据加载到DataModule中。它还将创建一个训练和测试验证数据集文件夹。我们正在使用from_folders钩子来做到这一点:
kinetics_videodatamodule = VideoClassificationData.from_folders(
train_folder="data/kinetics/train",
val_folder="data/kinetics/val",
clip_sampler="uniform",
clip_duration=2,
decode_audio=False,
batch_size=4
)在前面的代码片段中,我们使用了from_folders挂钩来加载数据并指定关键特征:
- train_folder和val_folder 分别定义数据集中训练和验证文件夹的位置。
- clip_sampler用于确定如何从底层视频文件中采样帧,而clip_duration定义以秒为单位的持续时间。在这种情况下,我们在每次迭代时从视频中统一采样 2 秒的剪辑。
- decode_audio定义我们是否希望将音频与视频一起加载。在这种情况下,我们选择不使用音频。如果您将其设置为 true,则视频剪辑会被选择性地读取或解码为具有形状(C、T、H 和 W)的规范视频张量和具有形状 (S) 的音频张量。
- 最后,batch_size确定单个批次中的视频数量。在这种情况下,我们将其设置为四个。批大小越大,环境中对内存的需求就越高。
一旦数据是加载完毕后,我们就可以选择预训练的模型架构了。
重要的提示
DataModule是一个预定义的加载数据集的钩子,其结构如下:dir_path/
配置backbone
在本节中,我们将执行以下操作:
- 选择主干
- 配置任务
我们的下一步现在是在 Flash 中选择预训练的模型架构,也称为“骨干”。您可以通过打印列出可用的模型架构选项:
print(VideoClassifier.available_backbones())这应该显示所有可用的架构,例如:
对于此示例,我们将选择slowfast_r50模型架构。在 Model Zoo 中,前 5 名的准确率接近 91%。
我们可以使用以下语句打印模型参数的详细信息:
打印(VideoClassifier.get_backbone_details(“slowfast_r50”))
print(VideoClassifier.get_backbone_details("slowfast_r50"))这应该显示一个我们可以在此模型之上构建任务时定义的参数:
现在,是时候了让我们使用 SlowFast 架构创建任务:
# 2. 构建任务
slowfastr50_model = VideoClassifier(backbone="slowfast_r50", labels=kinetics_videodatamodule.labels, pretrained=True)我们定义VideoClassfier并将slowfast_r50作为我们的主干,以及我们之前加载的动力学数据标签。
我们将使用预训练选项;因此,我们将其选为True。否则,模型将从头开始训练。
这应该显示以下输出:
现在我们的任务已经定义好了,我们都准备好为 Kinetics 数据集微调我们的模型了。
微调模型
现在,我们可以训练模型(或微调它,具体来说):
trainer = flash.Trainer(max_epochs=25, gpus=torch.cuda.device_count(),precision=16)
trainer.finetune(slowr50_model, datamodule=kinetics_videodatamodule, strategy="freeze")我们首先使用 ( flash.Trainer ) 创建一个Trainer类并定义超参数。在这种情况下,我们将使用所有可用的 GPU 并以 16 位精度运行 25 个 epoch。16 位精度模型通过减少计算维度使训练更快。
我们将定义一个trainer.finetune类,它接受我们之前定义的模型任务和数据集的参数。
这应该显示以下输出:

图 4.4 – 微调模型输出
尽你所能看,我们在验证集上获得了超过 87% 的相当不错的准确率。这个模型现在似乎已经准备好做出预测了。
使用模型进行预测
现在模型经过微调,我们可以使用它来进行预测。
您可以保存模型检查点并使用predict方法稍后进行预测。此模型针对视频进行了优化,因此如果您正在创建移动应用程序,部署将很容易:
trainer.save_checkpoint("finetuned_kinetics_slowr50_video_classification.pt")
datamodule = VideoClassificationData.from_folders(predict_folder="data/kinetics/predict", batch_size=1)
predictions = trainer.predict(slowr50_model, datamodule=datamodule, output="labels")
print(predictions)这应该显示该视频剪辑的前五个预测:
图 4.5 – 模型的预测
如您所见,我们得到了剪辑中视频的前五个预测动作。
就是这样。那是使用 Flash 微调模型是多么容易——只需五个步骤,几乎只需要一行代码。
重要的提示
为了查看您自己的视频剪辑的预测,您需要部署此模型。我们将在第 9 章“部署和评分模型”中介绍部署。此外,Flash 还提供了一些易于部署的功能以及作为 CLI 的 Flash Zero。这些功能目前处于测试阶段,因此请谨慎使用。
进一步学习的后续步骤
如您所见,它就像选择正确的钩子并指定几个参数来训练您的 Flash 模型一样简单。这是为您的应用程序对特定视频任务进行基准测试和原型制作的快速方法。您可以继续做更多的事情,例如:
- PyTorch 视频数据集集合中有更多可用的视频数据集,例如 Charades、Domsev、EpicKitchen、HMDB51、SSV2 和 UCF101。您可以尝试将它们作为额外的学习。
- 另一件要改变然后比较结果的事情是模型架构。SlowFast 是另一种广泛使用的视频分类架构。您可以直接从 Model Zoo 中试用。该架构的参数可在此处找到:https ://pytorchvideo.readthedocs.io/en/latest/api/models/slowfast.html 。
- 下一步是在需要时借助一些数据预处理将视频数据集更改为您自己的自定义数据集,并训练视频分类模型。一个非常好的数据集是 YouTube 视频数据集,可以在这里找到:https ://research.google.com/youtube8m/download.html 。
在下一节中,我们将使用 Flash 来创建自定义数据集,它可以在这些练习中派上用场。
使用 Flash 进行自动语音识别
识别语音来自音频文件可能是最人工智能的广泛应用。它是 Alexa 等智能手机扬声器的一部分,以及为 YouTube 等视频流媒体平台和许多音乐平台自动生成的字幕。它可以检测音频文件中的语音并将其转换为文本。语音检测涉及各种挑战,例如说话者的模态、音高和发音,以及方言和语言本身:
图 4.6 – 自动语音识别的概念
训练模型对于自动语音识别( ASR ),我们需要一个训练数据集,它是音频文件的集合以及相应的描述该音频的文本转录。来自不同年龄组、种族、方言等的人的音频文件集越多样化,ASR 模型对于看不见的音频文件就越健壮。
在上一节中,我们使用现成的数据集创建了一个模型;在本节中,我们将使用自定义数据集并使用现成的模型架构(例如用于 ASR 的 wav2vec)对其进行训练。
虽然有许多可用于 ASR 的架构,但 wav2vec 是由 Facebook AI 开发的非常好的跨语言架构。可以说它可以在任何语言上工作,并且具有极强的可扩展性。它最近的表现优于 LibriSpeech 基准。它首次发表在Steffen Schneider、Alexei Baevski、Ronan Collobert 和 Michael Auli的论文wav2sec: Unsupervised Pre-training for Speech Recognition中: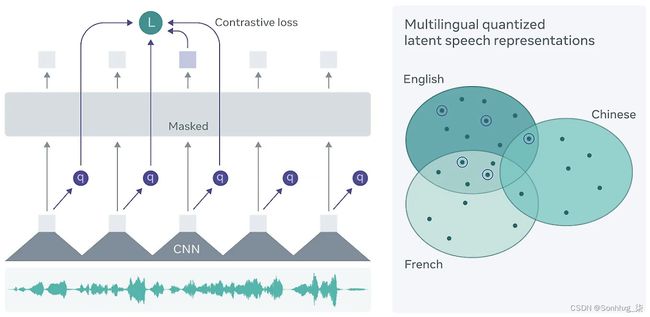
图 4.7 – wav2vec 架构 – 图片来源 – https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/
wav2vec模型是对 BERT 的改进Transformer 模型,我们在第 3 章,使用预训练模型中看到。该模型使用的标记数据比其他模型少得多,因为它依赖于“自我监督学习”。它在一组比现象组更短的小语音单元 (25 ms) 中学习音频文件的潜在表示。这些小的潜在表示与来自整个序列的知识一起以掩码形式输入到转换器中。对比损失函数用于找到掩蔽位置和语音单元的收敛。它使用自我监督和对比损失的概念,我们将在第 8 章自我监督学习中更深入地介绍。
预训练模型在近 960 小时的音频上进行了训练。该架构最有趣的部分是它是跨语言的,并且已经在各种语言中进行了尝试。我们将为苏格兰语言数据集尝试这个模型。
使用 Flash 的 ASR 模型由以下五个步骤组成,类似于视频分类任务:
- 导入库
- 加载数据集
- 配置骨干网
- 训练和微调模型
- 基于模型预测语音
现在,我们将开始模型构建过程。
安装库
我们将运行以下块将所需的包安装到我们的环境中。
!pip install torch==1.10.0 torchvision==0.11.1 torchtext==0.11.0 torchaudio==0.10.0 --quiet
!pip install pytorch-lightning==1.5.10 --quiet
!pip install lightning-flash==0.7.1 --quiet
!pip install 'lightning-flash[audio,image, video, text]' --quiet
!pip install Pillow==9.0.0导入库
我们将从导入必要的库:
import pandas as pd
import random
import torch
import flash
from sklearn.model_selection import train_test_split
from flash import Trainer
from flash.audio import SpeechRecognitionData, SpeechRecognition在上述步骤中导入库后,您可以检查版本:
print("pandas version:",pd.__version__)
print("torch version:",torch.__version__)
print("flash version:",flash.__version__)此代码段应显示以下输出:

图 4.8 – 用于 ASR 的包版本
现在,我们已准备好加载数据集。
加载数据集
我们将使用苏格兰语言数据集。您可以根据您的工作环境将数据集下载到您的 Google 驱动器或本地驱动器。
在此示例中,我们正在下载Scottish_english_female的音频文件,其中包含来自以下位置的 894 人的语音文件:https ://www.openslr.org/83/ 。音频文件为.wav格式,而文本文件为.csv格式。
作为第一步,我们将下载数据并将其添加到我们的驱动器中。我们在前面的章节中分享了安装驱动器的步骤;如果需要,请参考它们:
from google.colab import drive
drive.mount('/content/gdrive')
!unzip '/content/gdrive/My Drive/Colab Notebooks/scottish_english_female.zip'
random.seed(10)
df_scottish = pd.read_csv("line_index.csv", header=None, names=['not_required', 'speech_files', 'targets'])
df_scottish = df_scottish.sample(frac=0.06)
print(df_scottish.shape)
df_scottish.head()在前面的代码片段中,我们正在收集数据集并对其进行下采样以仅使用 6% 的数据集。这样做是因为计算资源限制。如果您有更多可用计算,您可以尝试更大的数字或整个数据集。然后我们打印数据帧的头部,如下所示:

图 4.9 – 文件视图的输出
如您所见,我们有 WAV 格式的音频语音文件以及文本转录。
现在,我们将为数据集创建一个训练测试拆分:
df_scottish = df_scottish[['speech_files', 'targets']]
df_scottish['speech_files'] = df_scottish['speech_files'].str.lstrip()
df_scottish['speech_files'] = df_scottish['speech_files'].astype(str) + '.wav'
df_scottish.head()
random.seed(10)
train_scottish, test_scottish_raw = train_test_split(df_scottish, test_size=0.2)
test_scottish = test_scottish_raw['speech_files']
test_scottish.head()
train_scottish.to_csv('train_scottish.csv')
test_scottish.to_csv('test_scottish.csv')在里面前面的代码片段,我们做了以下工作:
- 为我们的数据集创建了 DataFrame
- 使用 80% 的训练数据和 20% 的测试数据创建了 80-20% 的训练测试拆分
这应该显示以下输出以打印一些测试文件。

图 4.10 – 分割后测试音频文件视图的输出
现在,我们准备为这个数据集创建一个数据模块:
datamodule = SpeechRecognitionData.from_csv(
"speech_files",
"targets",
train_file="train_scottish.csv",
predict_file="test_scottish.csv",
batch_size=10)在前面的代码片段中,我们使用了Flash 中的数据模块挂钩,并通过了训练和测试文件以及语音。
在这个用例中,我们使用 10 个文件的批量大小。
执行此代码段后,您应该会看到以下输出:
图 4.11 – 音频数据模块的输出
现在,我们是准备为这个模型选择我们的主干。
重要的提示
就微调模型的内存要求而言,批量大小是一个关键参数。通常,batch size 越大,所需的 GPU 和内存就越高,尽管您可以通过 epoch 数对其进行调整。新语言的非常小的批量大小也可能不会产生任何学习效果,因此请明智地选择。
比较批量大小的一个关键方面是平均 WAV/音频文件的大小。在 Flash 文档中给出的示例中,WAV 文件更小;然而,在苏格兰数据集中,平均语音文件更大。文件越大,对内存和计算的需求就越大。
配置backbone
在这个部分,我们将执行以下操作:
- 选择主干
- 配置任务
我们的下一步是在 Flash 中选择预训练的模型架构,也称为“骨干”。您可以通过打印列出可用的模型架构选项:
SpeechRecognition.available_backbones()这应该显示所有可用的架构,例如:

图 4.12 – ASR 可用主干的输出
对于这个用例,我们将使用由 Hugging Face/transformers ( https://github.com/huggingface/transformers ) 提供的'facebook/wav2vec2-base-960h'。
现在,是我们的时候了使用 wav2vec2-base-960h 架构创建任务:
model = SpeechRecogntion(backbone="facebook/wav2vec2-base-960h")在此代码片段中,我们定义了模型架构。
现在我们的任务已经定义好了,我们都准备好为苏格兰语言数据集微调我们的模型了。
微调模型
现在,我们可以训练模型(或微调,具体而言):
trainer = Trainer(max_epochs=4, gpus=-1, precision=16)
trainer.finetune(model, datamodule=datamodule, strategy="no_freeze")我们首先使用 ( flash.Trainer ) 创建一个Trainer类并定义超参数。在这种情况下,我们将使用所有可用的 GPU 并以 16 位精度运行 4 个 epoch,没有冻结策略。16 位精度模型通过减少计算维度使训练更快。在“不冻结”战略中,我们从一开始就保持我们的骨干和它的头不被冻结。这意味着所有层都将接受微调的训练;但是,这意味着将使用更长的计算资源。我们将定义一个trainer.fintune类,它接受我们之前定义的模型任务和数据集的参数。
这应该显示以下输出:

图 4.13 – 微调模型输出
从此是一个解冻模型,我们只训练了 3 个 epoch;但是,我们将看到它仍然在预测方面给出了非常好的结果。
使用模型进行语音预测
现在,模型经过微调,我们可以使用它来进行预测。
您可以保存模型检查点并使用predict方法稍后进行预测。我们将首先尝试获得一些预测:
trainer.predict(model, datamodule=datamodule)在这里,我们使用predict类方法来获取模型预测:

图 4.14 – 模型的预测
如您所见,能够从音频文件中预测语音..
现在,我们可以在我们的测试数据集上进行尝试,并挑选一些看不见的音频文件来预测使用 Flash 构建的 ASR 模型的结果:
test_scottish_raw.head()
datamodule = SpeechRecognitionData.from_files(predict_files='scf_02484_01925002707.wav', batch_size=10) # Scottish
predictions = trainer.predict(model, datamodule=datamodule)
print(predictions)这应该显示此音频文件的以下预测(您可以尝试在计算机上收听特定的音频文件,以亲自查看结果的准确性)。供参考,这里是原始成绩单:
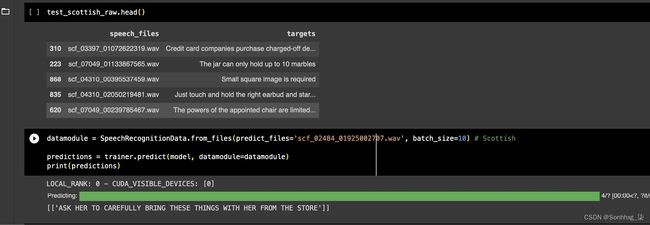
图 4.15 – 测试数据集的输出
将其与原始成绩单进行比较,您可以看到这是完全匹配的。这意味着我们的模型运行良好。您还可以使用model.serve方法提供模型以获取模型输出并将其与您的应用程序集成。
而已。这就是为高度复杂的任务(例如音频识别和视频分类)训练模型的流畅程度。
进一步学习
- 其他语言:我们使用苏格兰语言数据集的 ASR 数据集还包含许多其他语言,例如僧伽罗语,以及许多印度语言,例如印地语、马拉地语和孟加拉语。下一个合乎逻辑的步骤是尝试将此 ASR 模型用于另一种语言并比较结果。这也是学习如何管理培训要求的好方法,因为这些数据集中的一些音频文件更大;因此,他们将需要更多的计算能力。
许多非英语语言没有在移动设备上广泛使用的应用程序(例如,印度使用的马拉地语),并且缺乏母语技术工具限制了许多工具在世界偏远地区的采用。以您的本地语言创建 ASR 也可以为技术生态系统增加巨大的价值。
- 音频和视频一起:另一个有趣的任务是将我们今天看到的音频语音识别和视频分类任务结合起来,使用机器学习对视频动作进行分类,以及显示字幕。
- 濒危语言:很少讨论的挑战之一是世界各地稀有语言的消亡。有数千种语言被列为濒危语言,由于缺乏这些语言的可用资源,它们正在消亡。以印度中部为背景的《丛林之书》为例;那里的部落讲 Gond-Madia 语言,与许多濒临灭绝的语言一样,没有文字。拥有 ASR 不仅可以成为此类语言的救星,还可以成为社会赋权的重要工具。请考虑使用 ASR 为一种此类未提供服务的语言从头开始创建应用程序。
概括
Lightning Flash 仍处于早期发展阶段,并将继续快速发展。Flash 也是一个社区项目,模型代码可以由数据科学从业者贡献,因此代码的质量可能因架构而异。我们建议您对任何模型代码的来源进行尽职调查,因为它可能并不总是来自 PyTorch Lightning 团队;尽量避免错误。
但是,无论您是 DL 的初学者还是希望为新项目建立基线的高级从业者,Flash 都非常有用。第一个顺序是从该领域最新和最伟大的架构开始。它可以帮助您轻松地使用您的数据集,并为您的用例的不同算法设置基线。Flash 具有适用于最先进的 DL 架构的开箱即用功能,不仅可以节省时间,而且可以大大提高生产力。
视觉神经网络被广泛使用,并且发展非常迅速。在本章中,我们了解了如何使用 PyTorch Lightning Flash 中的开箱即用模型,而无需定义任何卷积层、执行大量预处理或从头开始训练模型。Flash 模型使我们能够轻松地配置、训练和构建模型。但是,Flash 模型可能并不总是能产生完美的结果,对于一些复杂的应用程序,它们将需要调整或编码,这就是我们回到 PyTorch Lightning 的时候。
我们看到了 Flash 帮助我们构建音频和视频任务模型的速度有多快。有更多现成的模型可用于图形、表格预测或 NLP 任务。
到目前为止,我们已经在本书中看到了 DL 模型的基本类型。在本书的下一部分中,我们将把重点转向如何使用 PyTorch Lightning 来解决一些具有复杂 FE 和大规模训练的实际用例。我们将从时间序列预测用例开始,看看 PyTorch Lightning 如何帮助我们创建工业规模的解决方案。