深度学习库中激活函数的使用以及特点
激活函数
- 1.引言
- 2.激活函数的用途
- 3.各类激活函数的性质和特点
-
- 3.1 S形状的激活函数及其变体
- 3.2 ReLU函数及其变体
- 3.3 Sin函数类
- 3.4 Shrink函数类
- 3.5 其他激活函数
- 4.在神经网络运算中如何选择合适的激活函数
1.引言
激活函数是在神经网络上运行的函数,将神经元的输入映射到输出端。激活函数在神经网络中进行模型参数的学习、梯度算法求值等等来说具有十分重要的作用。本文详细说明一些常见的激活函数在神经网络中的作用、性质和应用。
2.激活函数的用途
神经网络中的每一个神经元节点接受上一层神经元的输出值作为下一层神经元的输入值。例如,输入向量 X = ( x 1 , x 2 , . . . , x n ) X=(x_{1},x_{2},...,x_{n}) X=(x1,x2,...,xn),进过一个现行变换到下一输入层 Y = ( y 1 , y 2 , . . . , y l ) Y=(y_{1},y_{2},...,y_{l}) Y=(y1,y2,...,yl)。激活函数在这个中间做了一个这样的变换:
Y = f ( W T X + B ) Y=f(W^{T}X+B) Y=f(WTX+B)
其中 f ( x ) f(x) f(x)为激活函数。在多层神经网络中,上层与下层节点之间的函数关系通过激活函数来体现。简单来说,激活函数在神经网络中的作用就是引入一个非线性变换。
激活函数有以下多种性质:
- 非线性: 激活函数为非线性激活函数的时候,基本上两层的神经网络就可以模拟大多数函数。但是如果没有激活函数的时候,对多层的神经网络来说只是做到了一个基本向量空间的线性变换,这与单层的神经网络是等价的。
- 可微性: 在进行梯度优化和计算的时候,必须满足函数可微性的这一个条件以方便进行求导运算。
- 单调性: 当激活函数是单调函数的时候,单层的神经网络能够保持是凸函数。
- f ( x ) ≈ x f(x)\approx x f(x)≈x: 激活函数满足这个值主要为的是设置参数的初始化,以提高神经网络的训练效果。
- 输出的范围: 激活函数输出范围值是一个重要的参数,当输出的范围是有限的时候,基于梯度的优化方法会更加稳定,因为特征量表示受到有限权值的影响会更加显著。当输出范围是一个无限值的收,模型训练更加有效果。
3.各类激活函数的性质和特点
3.1 S形状的激活函数及其变体
早期研究的神经网络激活函数主要使用 sigmoid \text{sigmoid} sigmoid 类型的激活函数,最为常见的激活函数有 sigmoid \text{sigmoid} sigmoid、 tanh \text{tanh} tanh激活函数。更早的Perception中使用 threshold \text{threshold} threshold函数,但是这个函数零点不可导,其他部分导数全是0,无法进行后向传播训练,此处不再介绍。 sigmoid \text{sigmoid} sigmoid函数可以说是 threshold \text{threshold} threshold函数的soft版本。
- Threshold函数
y = { x , if x > threshold value , otherwise y = \begin{cases} x, &\text{ if } x > \text{threshold} \\ \text{value}, &\text{ otherwise } \end{cases} y={x,value, if x>threshold otherwise - Sigmoid函数
sigmoid \text{sigmoid} sigmoid函数是常用的激活函数,它的公式如下所示:
sigmoid ( x ) = 1 1 + e − x \text{sigmoid}(x)=\frac{1}{1+e^{-x}} sigmoid(x)=1+e−x1
函数图像如下所示
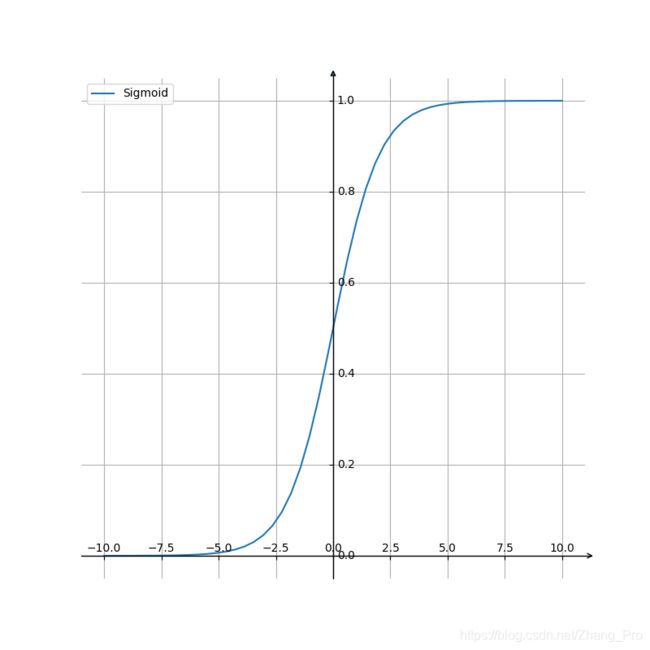 主要的特点是,它能够将输入的连续实数值压缩到0和1之间的输出值。当取到特别的值的时候,趋近于 + ∞ +\infty +∞的时候,输出的值趋近于1;当趋近于 − ∞ -\infty −∞的时候,输出值趋近于0。
主要的特点是,它能够将输入的连续实数值压缩到0和1之间的输出值。当取到特别的值的时候,趋近于 + ∞ +\infty +∞的时候,输出的值趋近于1;当趋近于 − ∞ -\infty −∞的时候,输出值趋近于0。
曾经, sigmoid \text{sigmoid} sigmoid函数为神经网络计算过程中的主要激活函数,但是这里会有很大的问题。首先在深度神经网络中梯度反向传到过程中会导致急剧梯度爆炸或者梯度消失,并不适合用于深度神经网络的学习过程。函数的导函数为
Sigmoid ′ ( x ) = Sigmoid ( x ) ( 1 − Sigmoid ( x ) ) \text{Sigmoid}^{'}(x)=\text{Sigmoid}(x)(1-\text{Sigmoid}(x)) Sigmoid′(x)=Sigmoid(x)(1−Sigmoid(x))
图像如下所示:

由图像可知, sigmoid \text{sigmoid} sigmoid倒数较小,最大的导数地方才0.25,每一层梯度传递会变为原来的0.25倍,在后向传播过程中,梯度衰减比较严重,甚至消失。特别地,权重值在区间 [ 1 , + ∞ ] [1,+\infty] [1,+∞]时候会出现1梯度爆炸情况。第二,激活函数的解析式中包含有幂函数运算,所以说,对于计算机来说,幂函数运算要比多项式以及对数类型的函数计算量较大,规模较大的深度神经网络会消耗时间。第三,由于激活函数是将输入值压缩到区间 [ 0 , 1 ] [0,1] [0,1]内,使得在传播过程中权重值偏向于正值,这使得在梯度更新过程中只往正方向更新梯度,导致梯度更新变慢。所以说这种非0均值的问题会产生一些不良影响。为了解决这个问题,所以有人提出 tanh \text{tanh} tanh函数
- Tanh函数
tanh \text{tanh} tanh函数表达式如下所示:
tanh ( x ) = e x − e − x e x + e − x \text{tanh}(x)=\frac{e^{x}-e^{-x}}{e^{x}+e^{-x}} tanh(x)=ex+e−xex−e−x
导函数表达式如下所示:
tanh ′ ( x ) = 1 − tanh 2 ( x ) \text{tanh}^{'}(x)=1-\text{tanh}^{2}(x) tanh′(x)=1−tanh2(x)
其中它的函数以及导函数图像如下所示:
 tanh \text{tanh} tanh函数有两个扩展函数,即 Symmetrical Sigmoid \text{Symmetrical Sigmoid} Symmetrical Sigmoid函数和 LeCun Tanh \text{LeCun Tanh} LeCun Tanhh函数(也被称作 Scaled Tanh \text{Scaled Tanh} Scaled Tanh函数)。相对于 tanh \text{tanh} tanh函数更平坦的形状和更慢的下降,表明它可以更有效地进行学习。函数表达式如下所示:
tanh \text{tanh} tanh函数有两个扩展函数,即 Symmetrical Sigmoid \text{Symmetrical Sigmoid} Symmetrical Sigmoid函数和 LeCun Tanh \text{LeCun Tanh} LeCun Tanhh函数(也被称作 Scaled Tanh \text{Scaled Tanh} Scaled Tanh函数)。相对于 tanh \text{tanh} tanh函数更平坦的形状和更慢的下降,表明它可以更有效地进行学习。函数表达式如下所示:
SymSigmoid ( x ) = tanh ( x 2 ) = 1 + e − x 1 + e − x \text{SymSigmoid}(x)=\text{tanh}(\frac{x}{2})=\frac{1+e^{-x}}{1+e^{-x}} SymSigmoid(x)=tanh(2x)=1+e−x1+e−x
LeCunTanh ( x ) = 1.7519 ∗ tanh ( 2 3 x ) \text{LeCunTanh}(x)=1.7519*\text{tanh}(\frac{2}{3}x) LeCunTanh(x)=1.7519∗tanh(32x)
tanh \text{tanh} tanh作为sigmoid函数的改进版本,将函数值压缩在了[-1,1]之间,并且是一个关于原点对称的函数。由函数图像可知,可见其导函数图像中导数值有所提升,它是完全可微分的,反对称,对称中心在原点。在梯度的反向传播过程中解决了 sigmoid \text{sigmoid} sigmoid函数中的一些问题,但是幂运算性质和梯度消失问题任然存在。下面是一些 tanh \text{tanh} tanh函数的一些变体
- Sigmoid函数和Tanh函数的变体
softsign \text{softsign} softsign函数:它是 tanh \text{tanh} tanh类激活函数的另一个替代选择。就像 tanh \text{tanh} tanh一样, softsign \text{softsign} softsign 是反对称、去中心、可微分,并返回-1 和 1 之间的值。其更平坦的曲线与更慢的下降导数表明它可以更高效地学习。函数和导函数如下所示:
softsign ( x ) = x 1 + ∣ x ∣ \text{softsign}(x)=\frac{x}{1+|x|} softsign(x)=1+∣x∣x
softsign ′ ( x ) = 1 ( 1 + ∣ x ∣ ) 2 \text{softsign}^{'}(x)=\frac{1}{(1+|x|)^{2}} softsign′(x)=(1+∣x∣)21
图像如下所示
 HardTanh \text{HardTanh} HardTanh函数:是 tanh \text{tanh} tanh激活函数的线性分段近似。相较而言,它更易计算,这使得学习计算的速度更快,尽管首次派生值为零可能导致静默神经元/过慢的学习速率(详细见 relu \text{relu} relu函数)
HardTanh \text{HardTanh} HardTanh函数:是 tanh \text{tanh} tanh激活函数的线性分段近似。相较而言,它更易计算,这使得学习计算的速度更快,尽管首次派生值为零可能导致静默神经元/过慢的学习速率(详细见 relu \text{relu} relu函数)
HardTanh ( x ) = { 1 if x > 1 − 1 if x < − 1 x otherwise \text{HardTanh}(x) = \begin{cases} 1 & \text{ if } x > 1 \\ -1 & \text{ if } x < -1 \\ x & \text{ otherwise } \\ \end{cases} HardTanh(x)=⎩⎪⎨⎪⎧1−1x if x>1 if x<−1 otherwise
HardTanh ′ ( x ) = { 1 if − 1 ≤ x ≤ 1 0 otherwise \text{HardTanh}^{'}(x) = \begin{cases} 1 & \text{ if } -1\leq x \leq 1 \\ 0 & \text{ otherwise } \\ \end{cases} HardTanh′(x)={10 if −1≤x≤1 otherwise
函数以及导函数图像如下所示:

arctan \text{arctan} arctan函数: arctan \text{arctan} arctan激活函数更加平坦,这让它比其他双曲线更加清晰。从导数的函数图中可以看到 arctan \text{arctan} arctan导数较大,估计对学习速度应该会有帮助。在默认情况下,其输出范围在 [ − π 2 , π 2 ] [-\frac{\pi}{2},\frac{\pi}{2}] [−2π,2π]。其导数趋向于零的速度也更慢,这意味着学习的效率更高。但这也意味着,导数的计算比 tanh \tanh tanh更加昂贵。函数以及导函数表达式如下所示:
arctan ( x ) = a r c t a n ( x ) \text{arctan}(x)=arctan(x) arctan(x)=arctan(x)
arctan ′ ( x ) = 1 1 + x 2 \text{arctan}^{'}(x)=\frac{1}{1+x^{2}} arctan′(x)=1+x21
函数以及导函数图像如下所示:
 ISRU \text{ISRU} ISRU函数:又称为反平方根函数,它是一个关于原点对称的函数,相对于tanh函数来说,它将函数运算控制在多项式运算复杂度上,减轻计算量。另外相对于 tanh \text{tanh} tanh函数来说,具有较好的平滑性,易于求导。其中函数及其导函数的表达式为
ISRU \text{ISRU} ISRU函数:又称为反平方根函数,它是一个关于原点对称的函数,相对于tanh函数来说,它将函数运算控制在多项式运算复杂度上,减轻计算量。另外相对于 tanh \text{tanh} tanh函数来说,具有较好的平滑性,易于求导。其中函数及其导函数的表达式为
ISRU ( x ) = x 1 + α x 2 \text{ISRU}(x)=\frac{x}{\sqrt{1+\alpha x^{2}}} ISRU(x)=1+αx2x
ISRU ′ ( x ) = 1 ( 1 + α x 2 ) 3 2 \text{ISRU}^{'}(x)=\frac{1}{(1+\alpha x^{2})^{\frac{3}{2}}} ISRU′(x)=(1+αx2)231
函数以及导函数的图像如下所示(这里的 α = 0.3 \alpha=0.3 α=0.3):
 LogLog \text{LogLog} LogLog函数:此函数是 sigmoid \text{sigmoid} sigmoid函数的一种变体形式,它的值域为 [ 0 , 1 ] [0,1] [0,1],该函数饱和地非常快,有希望替代 sigmoid \text{sigmoid} sigmoid函数,但是缺点是有幂指数运算,增加运算量。函数的表达式为:
LogLog \text{LogLog} LogLog函数:此函数是 sigmoid \text{sigmoid} sigmoid函数的一种变体形式,它的值域为 [ 0 , 1 ] [0,1] [0,1],该函数饱和地非常快,有希望替代 sigmoid \text{sigmoid} sigmoid函数,但是缺点是有幂指数运算,增加运算量。函数的表达式为:
LogLog ( x ) = 1 − e − e x \text{LogLog}(x)=1-e^{-e^{x}} LogLog(x)=1−e−ex
LogLog ′ ( x ) = e x − e x \text{LogLog}^{'}(x)=e^{x-e^{x}} LogLog′(x)=ex−ex
函数及其导函数图像如下所示:

sign \text{sign} sign函数:符号函数作为一种激活函数是二值阶跃激活函数版本,值域为[-1,1],是一种反对称函数,无生物特征。函数以及导函数如下所示:
sign ( x ) = { 1 if x > 0 0 if x = 0 − 1 if x < 0 \text{sign}(x) = \begin{cases} 1 & \text{ if } x >0 \\ 0 & \text{ if } x = 0 \\ -1 & \text{ if } x <0 \\ \end{cases} sign(x)=⎩⎪⎨⎪⎧10−1 if x>0 if x=0 if x<0
sign ′ ( x ) = { N o n e if x = 0 0 if x ≠ 0 \text{sign}^{'}(x) = \begin{cases} None & \text{ if } x = 0 \\ 0 & \text{ if } x \neq 0 \end{cases} sign′(x)={None0 if x=0 if x=0
3.2 ReLU函数及其变体
以上所说的 sigmoid \text{sigmoid} sigmoid函数或多或少都存在着一些梯度消失或者梯度爆炸的问题,这使得更深层次的神经网络更加难以训练。后来有人从生物学角度提出的 ReLU \text{ReLU} ReLU函数基本上解决了这个问题,这样基本保证了在 x > 0 x>0 x>0的时候导数不是减少的,那么这样在梯度传播过程中不会消失。但是新问题出现了, ReLU \text{ReLU} ReLU函数有一个问题就是,负半轴上值为0,导数值也为0,所以说在forward和backward过程中都不能传递有效信息,这种问题有人称为dead neuron问题。在使用 ReLU \text{ReLU} ReLU函数的时候不能使用太大的learning rate,否则会出现一堆dead neuron问题。
- ReLU函数
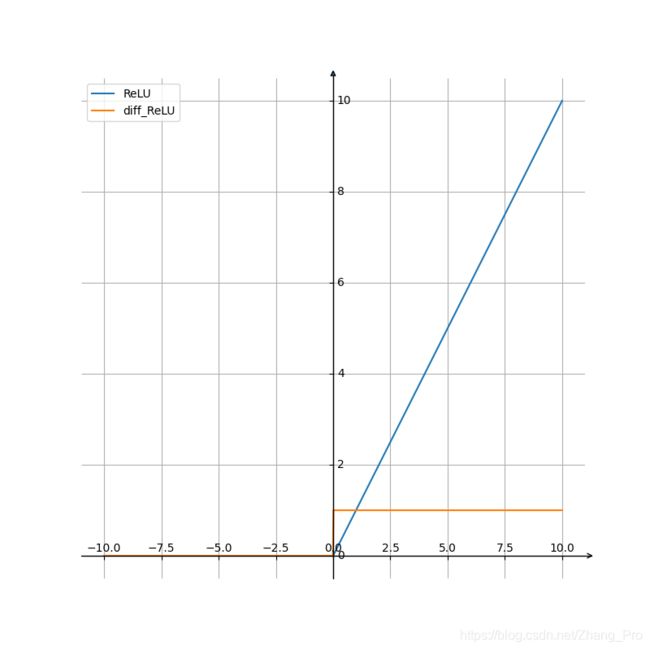
函数和导数的表达式为
ReLU ( x ) = m a x ( 0 , x ) \text{ReLU}(x)=max(0,x) ReLU(x)=max(0,x)
ReLU ′ ( x ) = { 1 , if x > 0 0 , if x < 0 \text{ReLU}^{'}(x)=\begin{cases} 1 & , \text{ if } x >0\\ 0 & , \text{ if } x <0\\ \end{cases} ReLU′(x)={10, if x>0, if x<0
函数和导函数图像为:
 为了改善 ReLU \text{ReLU} ReLU函数的性能,有很多人创建了 ReLU \text{ReLU} ReLU函数的改进版本,下面讲述一些这样的函数。
为了改善 ReLU \text{ReLU} ReLU函数的性能,有很多人创建了 ReLU \text{ReLU} ReLU函数的改进版本,下面讲述一些这样的函数。
ReLU6 \text{ReLU6} ReLU6函数:为限制其 ReLU \text{ReLU} ReLU函数中正半轴的取值范围,所以提出了 ReLU6 \text{ReLU6} ReLU6函数
函数及其导函数为:
ReLU6 ( x ) = m i n ( m a x ( 0 , x ) , 6 ) \text{ReLU6}(x)=min(max(0,x),6) ReLU6(x)=min(max(0,x),6)
ReLU6 ′ ( x ) = { 0 , if x > 6 1 , if 0 ≤ x ≤ 6 0 , if x < 0 \text{ReLU6}^{'}(x)=\begin{cases} 0 & , \text{ if } x > 6\\ 1 & , \text{ if } 0 \leq x \leq 6 \\ 0 & , \text{ if } x < 0 \end{cases} ReLU6′(x)=⎩⎪⎨⎪⎧010, if x>6, if 0≤x≤6, if x<0
Leak ReLU \text{Leak ReLU} Leak ReLU函数:这是为解决上述 ReLU \text{ReLU} ReLU函数中存在的dead neuron问题,而且这个激活函数使得数据分布在 0 0 0的两侧,在一定程度上改进了神经网络学习的过程。函数及其导函数的表达式为:
LeakyRELU ( x ) = { x , if x ≥ 0 negative_slope × x , otherwise \text{LeakyRELU}(x) = \begin{cases} x, & \text{ if } x \geq 0 \\ \text{negative\_slope} \times x, & \text{ otherwise } \end{cases} LeakyRELU(x)={x,negative_slope×x, if x≥0 otherwise
LeakyRELU ( x ) = { 1 , if x ≥ 0 negative_slope , otherwise \text{LeakyRELU}(x) = \begin{cases} 1, & \text{ if } x \geq 0 \\ \text{negative\_slope} , & \text{ otherwise } \end{cases} LeakyRELU(x)={1,negative_slope, if x≥0 otherwise
函数及其导函数图像为:
 softplus \text{softplus} softplus函数: softplus \text{softplus} softplus函数是相对于 ReLU \text{ReLU} ReLU函数更好的一个变体函数,它在每一个点上的导数都部位0,避免了使用 ReLU \text{ReLU} ReLU函数出现的dead neuron问题。这个函数另外的一个优点就是在 0 0 0点处具有比 R e L U ReLU ReLU函数更好的平滑性,而不是非常Hard。 softplus \text{softplus} softplus是 ReLU \text{ReLU} ReLU函数的平滑近似,可用于将输出值始终约束为正。为了获得数值稳定性,对于超过一定值的输入,将恢复为近似线性函数。函数及其导函数的表达式为:
softplus \text{softplus} softplus函数: softplus \text{softplus} softplus函数是相对于 ReLU \text{ReLU} ReLU函数更好的一个变体函数,它在每一个点上的导数都部位0,避免了使用 ReLU \text{ReLU} ReLU函数出现的dead neuron问题。这个函数另外的一个优点就是在 0 0 0点处具有比 R e L U ReLU ReLU函数更好的平滑性,而不是非常Hard。 softplus \text{softplus} softplus是 ReLU \text{ReLU} ReLU函数的平滑近似,可用于将输出值始终约束为正。为了获得数值稳定性,对于超过一定值的输入,将恢复为近似线性函数。函数及其导函数的表达式为:
softplus ( x ) = l n ( 1 + e x ) \text{softplus}(x)=ln(1+e^{x}) softplus(x)=ln(1+ex)
softplus ′ ( x ) = e x 1 + e x \text{softplus}^{'}(x)=\frac{e^{x}}{1+e^{x}} softplus′(x)=1+exex
函数及其导函数的图像为:
 PReLU \text{PReLU} PReLU函数及 RReLU \text{RReLU} RReLU函数:Parametric ReLU( PReLU \text{PReLU} PReLU)及Randomized ReLU( RReLU \text{RReLU} RReLU)函数的出现,是为了改进 ReLU \text{ReLU} ReLU函数中出现的dead neuron问题。特别地,在 PReLU \text{PReLU} PReLU函数中 α \alpha α参数是变量,可以通过BP学习。 RReLU \text{RReLU} RReLU函数中,参数 α \alpha α则是在训练过程中,参数 α \alpha α是在区间 [ lower , upper ] [\text{lower},\text{upper}] [lower,upper]均匀分布中的随机数,在测试中使用均值 E [ α ] = lower + upper 2 E[\alpha] = \frac{\text{lower}+\text{upper}}{2} E[α]=2lower+upper。 RReLU \text{RReLU} RReLU函数是在论文Empirical Evaluation of Rectified Activations in Convolutional Network 提到这样的一个激活函数。函数的表达式为:
PReLU \text{PReLU} PReLU函数及 RReLU \text{RReLU} RReLU函数:Parametric ReLU( PReLU \text{PReLU} PReLU)及Randomized ReLU( RReLU \text{RReLU} RReLU)函数的出现,是为了改进 ReLU \text{ReLU} ReLU函数中出现的dead neuron问题。特别地,在 PReLU \text{PReLU} PReLU函数中 α \alpha α参数是变量,可以通过BP学习。 RReLU \text{RReLU} RReLU函数中,参数 α \alpha α则是在训练过程中,参数 α \alpha α是在区间 [ lower , upper ] [\text{lower},\text{upper}] [lower,upper]均匀分布中的随机数,在测试中使用均值 E [ α ] = lower + upper 2 E[\alpha] = \frac{\text{lower}+\text{upper}}{2} E[α]=2lower+upper。 RReLU \text{RReLU} RReLU函数是在论文Empirical Evaluation of Rectified Activations in Convolutional Network 提到这样的一个激活函数。函数的表达式为:
PReLU ( x ) = { x , if x ≥ 0 α x , otherwise \text{PReLU}(x) = \begin{cases} x, & \text{ if } x \geq 0 \\ \alpha x, & \text{ otherwise } \end{cases} PReLU(x)={x,αx, if x≥0 otherwise
RReLU ( x ) = { x if x ≥ 0 a x otherwise \text{RReLU}(x) = \begin{cases} x & \text{if } x \geq 0 \\ ax & \text{ otherwise } \end{cases} RReLU(x)={xaxif x≥0 otherwise
ELU \text{ELU} ELU函数和 SELU \text{SELU} SELU函数:同样为解决 ReLU \text{ReLU} ReLU函数中出现的问题,提出了Exponential Linear Units( ( E L U ) \text(ELU) (ELU)函数)以及Scaled ELU( SELU \text{SELU} SELU函数)。表达式如下所示
ELU ( x ) = max ( 0 , x ) + min ( 0 , α ∗ ( e x − 1 ) ) \text{ELU}(x) = \max(0,x) + \min(0, \alpha * (e^{x} - 1)) ELU(x)=max(0,x)+min(0,α∗(ex−1))
SELU ( x ) = s ∗ ( max ( 0 , x ) + min ( 0 , α ∗ ( e x − 1 ) ) ) \text{SELU}(x) = s * (\max(0,x) + \min(0, \alpha * (e^{x}- 1))) SELU(x)=s∗(max(0,x)+min(0,α∗(ex−1)))
其中 α = 1.6732632423543772848170429916717 \alpha = 1.6732632423543772848170429916717 α=1.6732632423543772848170429916717 , s = 1.0507009873554804934193349852946 s = 1.0507009873554804934193349852946 s=1.0507009873554804934193349852946
这个激活函数最早由论文Self-Normalizing Neural Networks 提出。在论文中,详细计算并且推导出具体 α \alpha α和 s s s(scaled)的值。
ELU相对于ReLU的优点是其输出在原点两侧且在每个点导数都不为0。SELU在论文中介绍的优点是,如果输入是均值为0,标准差为1的话,经过SELU激活之后,输出的均值也为0,标准差也为1。相比较 Leaky ReLU \text{Leaky ReLU} Leaky ReLU、 ReLU \text{ReLU} ReLU、 ELU \text{ELU} ELU三种激活函数, SELU \text{SELU} SELU激活函数能够极限优化神经网络,但是计算时间稍长。
CELU \text{CELU} CELU函数:与上述的 SELU \text{SELU} SELU类似, CELU \text{CELU} CELU同样采用负数区间为指数计算,整数区间为线性计算。这个激活函数由论文Continuously Differentiable Exponential Linear Units提出。激活函数的表达式为:
CELU ( x ) = max ( 0 , x ) + min ( 0 , α ∗ ( e x α − 1 ) ) \text{CELU}(x) = \max(0,x) + \min(0, \alpha * (e^{\frac{x}{\alpha}} - 1)) CELU(x)=max(0,x)+min(0,α∗(eαx−1))
ISRLU \text{ISRLU} ISRLU函数:这个激活函数也称作是反平方根线性函数。结合了 ISLU \text{ISLU} ISLU函数和 ReLU \text{ReLU} ReLU函数,能更好地处理梯度问题。函数以及其导数表达式为:
ISRLU ( x ) = { x 1 + a x 2 , if x < 0 x , if x > 0 \text{ISRLU}(x)=\begin{cases} \frac{x}{\sqrt{1+ax^{2}}} & , \text{ if } x<0\\ x & , \text{ if } x>0 \end{cases} ISRLU(x)={1+ax2xx, if x<0, if x>0
ISRLU ( x ) = { 1 ( 1 + a x 2 ) 3 2 , if x < 0 1 , if x > 0 \text{ISRLU}(x)=\begin{cases} \frac{1}{(1+ax^{2})^{\frac{3}{2}}} & , \text{ if } x<0\\ 1 & , \text{ if } x>0 \end{cases} ISRLU(x)={(1+ax2)2311, if x<0, if x>0
函数及其导函数的图像为:

3.3 Sin函数类
sin \sin sin函数以及 cos \cos cos函数
激活函数为神经网络引入了周期性。该函数的值域为 [ − 1 , 1 ] [-1,1] [−1,1],且导数处处连续。此外, sin \sin sin激活函数为零点对称的奇函数。余弦激活函数(Cos/Cosine)同样为神经网络引入了周期性。它的值域为 [ − 1 , 1 ] [-1,1] [−1,1],且导数处处连续。和 sin \sin sin函数不同,余弦函数为不以零点对称的偶函数。
sinc \text{sinc} sinc函数:Sinc 函数(全称是 Cardinal Sine)在信号处理中尤为重要,因为它表征了矩形函数的傅立叶变换(Fourier transform)。作为一种激活函数,它的优势在于处处可微和对称的特性,不过它比较容易产生梯度消失的问题。函数及其导函数的表达式为:
sinc ( x ) = { 1 , if x = 0 sin ( x ) x , if , x ≠ 0 \text{sinc}(x)=\begin{cases} 1,& \text{ if } x=0 \\ \frac{\sin(x)}{x},&\text{ if },x\neq 0 \end{cases} sinc(x)={1,xsin(x), if x=0 if ,x=0
sinc ′ ( x ) = { 0 , if x = 0 x cos ( x ) − sin ( x ) x 2 , if , x ≠ 0 \text{sinc}^{'}(x)=\begin{cases} 0,& \text{ if } x=0 \\ \frac{x\cos(x)-\sin(x)}{x^{2}},&\text{ if },x\neq 0 \end{cases} sinc′(x)={0,x2xcos(x)−sin(x), if x=0 if ,x=0
函数及其导函数的图像为:

3.4 Shrink函数类
Shrink函数类主要处理的是函数在 0 0 0点处的变化值。有些变化剧烈,有些变化比较缓和。与 sigmoid \text{sigmoid} sigmoid函数相比较来说,在原点对称的两端变化平和,主要有以下几种函数。
SoftShrink \text{SoftShrink} SoftShrink函数以及 HardShrink \text{HardShrink} HardShrink函数:函数以及其导函数的表达式、图像如下所示:
SoftShrink ( x ) = { x − λ , if x > λ x + λ , if x < − λ 0 , otherwise \text{SoftShrink}(x) = \begin{cases} x - \lambda, & \text{ if } x > \lambda \\ x + \lambda, & \text{ if } x < -\lambda \\ 0, & \text{ otherwise } \end{cases} SoftShrink(x)=⎩⎪⎨⎪⎧x−λ,x+λ,0, if x>λ if x<−λ otherwise
HardShrink ( x ) = { x , if x > λ x , if x < − λ 0 , otherwise \text{HardShrink}(x) = \begin{cases} x, & \text{ if } x > \lambda \\ x, & \text{ if } x < -\lambda \\ 0, & \text{ otherwise } \end{cases} HardShrink(x)=⎩⎪⎨⎪⎧x,x,0, if x>λ if x<−λ otherwise
SoftShrink ′ ( x ) = HardShrink ′ ( x ) = { 0 , if − λ ≤ x ≤ λ 1 , otherwise \text{SoftShrink}^{'}(x) =\text{HardShrink}^{'}(x)= \begin{cases} 0, & \text{ if } -\lambda \leq x \leq \lambda \\ 1, & \text{ otherwise } \end{cases} SoftShrink′(x)=HardShrink′(x)={0,1, if −λ≤x≤λ otherwise

TanhShrink \text{TanhShrink} TanhShrink函数:此函数是SoftShrink函数和HardShrink函数的一个平滑版本,使得函数的求导更为容易和便捷。函数及其导数表达式为:
TanhShrink ( x ) = x − tanh ( x ) \text{TanhShrink}(x) = x - \text{tanh}(x) TanhShrink(x)=x−tanh(x)
TanhShrink ′ ( x ) = tanh 2 ( x ) \text{TanhShrink}^{'}(x)=\text{tanh}^{2}(x) TanhShrink′(x)=tanh2(x)
函数及其导函数图像为:
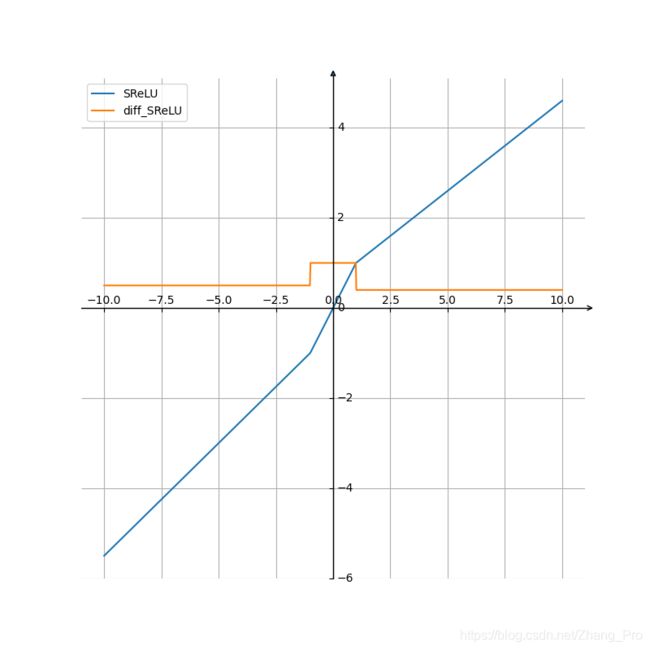
 SReLU \text{SReLU} SReLU函数:这个函数并不常见,函数及其导函数的具体表达式为
SReLU \text{SReLU} SReLU函数:这个函数并不常见,函数及其导函数的具体表达式为
SReLU ( x ) = { t l + a l ( x − t l ) , if x < t l x , if t l ≤ x ≤ t r t r + a r ( x − t r ) , if x > t r \text{SReLU}(x)=\begin{cases} t_{l} + a_{l}(x-t_{l}) &,\text{ if } x < t_{l} \\ x &, \text{ if } t_{l} \leq x \leq t_{r} \\ t_{r} + a_{r}(x-t_{r})&,\text{ if }x > t_{r} \end{cases} SReLU(x)=⎩⎪⎨⎪⎧tl+al(x−tl)xtr+ar(x−tr), if x<tl, if tl≤x≤tr, if x>tr
SReLU ′ ( x ) = { a l , if x < t l 1 , if t l ≤ x ≤ t r a r , if x > t r \text{SReLU}^{'}(x)=\begin{cases} a_{l} &,\text{ if } x< t_{l} \\ 1 &, \text{ if } t_{l} \leq x \leq t_{r} \\ a_{r}&,\text{ if }x > t_{r} \end{cases} SReLU′(x)=⎩⎪⎨⎪⎧al1ar, if x<tl, if tl≤x≤tr, if x>tr
一般地, a l = 0.5 , a r = 0.4 , t l = − 1.0 , t r = 1.0 a_{l} = 0.5,a_{r}=0.4,t_{l}=-1.0,t_{r}=1.0 al=0.5,ar=0.4,tl=−1.0,tr=1.0
函数及其导函数图像为
3.5 其他激活函数
gaussian \text{gaussian} gaussian函数:高斯激活函数(Gaussian)并不是径向基函数网络(RBFN)中常用的高斯核函数,高斯激活函数在多层感知机类的模型中并不是很流行。该函数处处可微且为偶函数,但一阶导会很快收敛到零。函数及其导函数表达式如下所示
gaussian ( x ) = e − x 2 \text{gaussian}(x)=e^{-x^{2}} gaussian(x)=e−x2
gaussian ′ ( x ) = − 2 ∗ x e − x 2 \text{gaussian}^{'}(x)=-2*xe^{-x^{2}} gaussian′(x)=−2∗xe−x2
图像为:

另外一个关于高斯分布函数的激活函数是:
GELU ( x ) = x ∗ Φ ( x ) \text{GELU}(x)=x*\Phi(x) GELU(x)=x∗Φ(x)
其中 Φ ( x ) \Phi(x) Φ(x)是是高斯分布的累积分布函数。
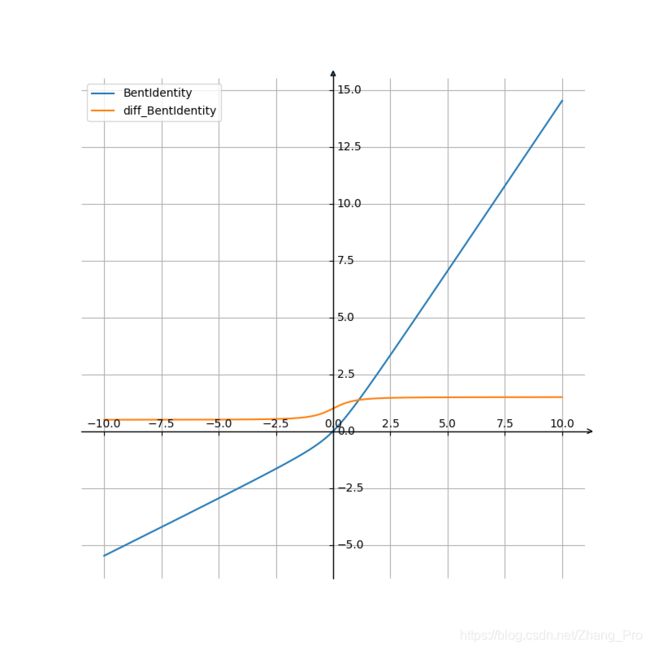
Bent Identity \text{Bent Identity} Bent Identity函激活函数: Bent Identity \text{Bent Identity} Bent Identity是介于线性变换与 ReLU \text{ReLU} ReLU之间的一种折衷选择。它允许非线性行为,尽管其非零导数有效提升了学习并克服了与 ReLU \text{ReLU} ReLU相关的静默神经元的问题。由于其导数可在 1 的任意一侧返回值,因此它可能容易受到梯度爆炸和消失的影响。
f ( x ) = x 2 + 1 − 1 2 + x f(x)=\frac{\sqrt{x^{2}+1}-1}{2}+x f(x)=2x2+1−1+x
f ′ ( x ) = x 2 x 2 + 1 + 1 f^{'}(x)=\frac{x}{2\sqrt{x^{2}+1}}+1 f′(x)=2x2+1x+1
函数及其导函数的图像如下所示:
 SiLU \text{SiLU} SiLU函数:也称为Swish函数,是Google Brain提出的新的激活函数,实际上是一种 sigmoid \text{sigmoid} sigmoid函数的改进版本。函数及其导函数表达式为
SiLU \text{SiLU} SiLU函数:也称为Swish函数,是Google Brain提出的新的激活函数,实际上是一种 sigmoid \text{sigmoid} sigmoid函数的改进版本。函数及其导函数表达式为
SiLU ( x ) = x ∗ σ ( x ) \text{SiLU}(x)=x*\sigma(x) SiLU(x)=x∗σ(x)
SiLU ′ ( x ) = σ ( x ) + x ∗ σ ( x ) ( 1 − σ ( x ) ) \text{SiLU}^{'}(x) = \sigma(x) + x*\sigma(x)(1-\sigma(x)) SiLU′(x)=σ(x)+x∗σ(x)(1−σ(x))
其中 σ ( x ) \sigma(x) σ(x)为 sigmoid 函 数 \text{sigmoid}函数 sigmoid函数
函数及其导函数图像为:

4.在神经网络运算中如何选择合适的激活函数
深度学习旺旺需要大量的时间来训练数据信息,所以说模型的梯度收敛显得尤为重要。总体上来讲,训练深度学习的神经网络尽量使用zero-centered数据信息作为输入和zero-centered作为输出。这使得我们需要使用这一类的激活函数来构建我们的神经网络,例如 ReLU \text{ReLU} ReLU类激活函数。使用 ReLU \text{ReLU} ReLU函数最重要的一点尽量使得神经网络不能出现dea neuron现象,如果出现了这类问题,可以使用 Leaky ReLU \text{Leaky ReLU} Leaky ReLU函数以及改进版本的函数。不过最好不要使用 sigmoid \text{sigmoid} sigmoid函数以避免梯度消失和梯度爆炸现象。总体来说。激活函数的选择要根据经验和数据源的类型来进行选择。
详细见数学分析文章:深度神经网络为什么很难训练 ↩︎