【路径探索篇】(5)全局路径规划
系列文章目录
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
TODO:写完再整理
文章目录
- 系列文章目录
- 前言
- 一、曲线拟合的方法
-
- 1.dubins曲线
-
- 一、dubins曲线的理论推导
-
- 1.理论定理
- 2.Dubins曲线最短路径的分析
- 3.Dubins曲线的六种类型
- 4.Dubins曲线的约束条件
- 5.Dubins曲线实现代码及流程
-
- (0)dubins曲线拟合出来后,检查是否符合长度要求、判断是否与环境障碍物碰撞
- (1)dubins曲线的流程函数
- (2)六种类型LSL, LSR, RSL, RSR, RLR or LRL的曲线计算方法实现函数
- (3)获取计算出来的dubins曲线的各种参数的调用函数
-
- 1、计算路径长度
- 2、返回路径类型
- 3、计算下一段Dubins路径段的位置
- 4、对一段路径进行采样(根据路径长度t和路径参数path,生成长度为t的节点的位置)
- 5、根据路径参数path, 返回线段末节点参数
- 6、 将一段路径path,按路径长度t,划分为多个子线段
- 二、二维dubins曲线的工程实现
-
- 1.先输入dubins曲线的起点位姿start_pose、目标点位姿goal_pose、圆弧曲率,再计算6种类型的dubins曲线三段t、q、p参数,最后选择直线代价cost最小的一条dubins曲线
-
- (1)6种dubins曲线三段参数的计算公式
- 2.根据t、p、q和给定的curve生成一条具体的dubins曲线path
- 3.相关初始化参数设置
- 2.Reeds-Shepp曲线
-
- (1)Reeds-Shepp曲线的理论推导
-
- 1.理论定理
- 2.Reeds-Shepp曲线的由来
- 3.Reeds-Shepp曲线的46种类型
- 4.Reeds-Shepp曲线的约束条件
- 5.Reeds-Shepp曲线的应用场景
- 6.Reeds-Shepp曲线的代码实现
- (2)Dubins曲线与Reeds-Shepp曲线的功能及对比
- (3)算法实现
- (4)总结
- (5)参考资料
- 二、图搜索的方法
-
- 0、基于栅格地图的路径搜索--把栅格地图转换成搜索图
- 1.DFS\BFS\DFS-ID搜索算法
-
- (1)深度优先搜索Depth-First-Searching(DFS)
-
- 1.适合的路径规划应用场景
- 2.维护容器
- 3.搜索过程图例
- 4.伪代码
- (2)广度优先搜索Breadth-First Searching(BFS)
-
- 1.适合的路径规划应用场景
- 2.维护容器
- 3.搜索过程图例
- 4.伪代码(Graph Based的BFS最短路径规划)
- (3)迭代加深Best-First Searching(DFS-ID)的深度优先搜索
- (4)总结
- 2.贪心算法、Dijkstra和A*类路径搜索算法
-
- (1)greedy best frist search贪心算法
-
- 1.核心思想
- 2.构造启发式猜测h(n)方法
- 3.启发式的搜索方法优势
- 4.栅格地图二维形式(一个直捣黄龙的搜索形状)
- 5.伪代码
- (2)Dijkstra算法
-
- 1.核心思想
- 2.伪代码
- 3.图例(一个直捣黄龙的搜索形状)【广而优】
- 4.优点分析
- 5.缺点分析
- 6.参考资料
- (3)A*算法
-
- 1.核心思想
- 2.构造启发式猜测h(n)方法
- 3.栅格地图二维形式(一个直捣黄龙的搜索形状)【广而优】
- 4.代码实现
-
- (0)搜索流程伪代码即步骤解析
- 所涉及到的主要数据结构
- (1)A*算法搜索的流程代码
- (2)创建可能的下一个扩展节点方法
- (3)计算当前节点的代价G值与启发代价H值(欧式距离)
- (4)算法对比
-
- 1.Greedy Best First Search和贪心算法对比
- 2.Greedy Best First Search 、A* 和Weighted A*的对比
- 3.Dijkstra算法和A*算法的对比
- 4.Dijksta算法、A*算法、hybrid A*算法/kinodynamic A*算法的open_list创建方式对比
- (5)总结
-
- 1.启发式作用
- 2.启发式的图搜索算法优点
- 3.启发式的图搜索算法缺点
- (6)参考资料
- 3.jump point search(JPS)跳点搜索算法
-
- (1)核心思想
-
- 定义一,强迫邻居(forced neighbour)
- 定义二,跳点(jump point)
- 规则一
- 规则二
- 规则三
- (2)算法过程
-
- 中文版解释横向纵向的格子的单位消耗为10,对角单位消耗为14。
- 获取邻居点
- 递归跳跃
- 计算G,H代价值
- (3)Astar和JPS算法的流程对比
- (4)JPS在A*的基础上进行改进的点
- (5)JPS算法与A*算法的效果对比
- 总结
- 参考资料
- 效果验证平台
- 4.hybird A*算法
-
- (1)hybird A*算法应用场景
- (2)hybird A*算法算法原理步骤
-
- 1.stage 1:在连续坐标系下进行启发式搜索(使用改进的启发式搜索A*算法)
-
- (1)hybrid A* 和A*的相同点
- (2)hybrid A*在A*基础上改进的点
-
- (1)hybrid A*满足车辆非完整性约束(作用于节点采样【控制状态采样方式】)
- (2)hybrid A*是在连续坐标系下使用进行节点连接(作用于节点连接过程)
- (3)hybrid A*启发函数的选取不同(作用于节点启发式扩张过程)
- (3)路径节点探索的过程【重要】
-
- (1)【节点控制采样】结合离散状态空间+离散控制空间的采样的过程
- (2)【节点连接】节点连接的过程
- (3)【节点启发式扩张】生成子节点搜索的过程
- 2.stage 2:对路径进行优化的后处理(代价函数+梯度下降)
-
- (1)对路径进行优化的后处理目的
- (2)后处理步骤一:采用目标函数的设计进行轨迹优化
-
- 1)优化的目标
- 2)目标函数设计方法
- 1、曲率项
- 2、光滑度项smoothness项
- 3、代价地图障碍物项
- 4、Voronoi图避障项(源码实际上好像没有用到这一项)
- (3)后处理步骤二:采用梯度下降方法进行轨迹优化
-
- 理论过程
- (3)hybird A*算法伪代码及代码流程
-
- 0.hybrid A*算法实现的流程
- stage1 :路径探索
- 1.hybrid A* 算法伪代码
- 2. hybrid A*的流程步骤实现源码【对应上面的步骤的】【节点扩张的过程】
- 3.创建下一个节点的方式
- 4.计算总代价值C(总估计代价值C = 当前代价值G + 启发代价值H)
- 5、计算当前真实代价值G
- 6、计算启发式代价值H
- 7、A*算法(在第一个启发式函数H中使用)
- 8、dubins算法(在第二个启发式函数H中使用)
- stage2:轨迹优化
- 9.使用梯度下降的方式对路径进行平滑
-
- 障碍物优化项
- Voronoi人工势场优化项(没有用到)
- 光滑度优化项
- 曲率优化项
- (4)hybird A*算法总结
- (5)hybird A*算法参考论文、github源码、效果展示
- 5.Kinodynamic A*算法
-
- 1、前端kinodynamic A*算法动力学路径搜索的功能
- 2、步骤一:进行实时采样,离散的获得一些轨迹点(节点point_set,即创建open_list)以及起始点的速度与加速度
- 3、步骤二:设置算法搜索参数setParam()
- 4、步骤三:整体的搜索过程search()--包括进行节点扩张-剪枝
- 5、步骤四:获取规划得到的路径点getKinoTraj()
- 6、关键函数分析【重点】
-
- (1)计算启发代价值H estimateHeuristic()
- (2)计算当前节点的真实的代价G值
- (3)计算一条直达曲线computeShotTraj()
- (4)节点扩张、节点剪枝流程
- 7、总结
- 8、参考资料
- 6.Kinodynamic RRT*算法
-
- (1)Kinodynamic-RRT*的目的
- (2)Kinodynamic-RRT*基本思路
- (3)Kinodynamic-RRT*伪代码
- (4)参考资料
- 三、采样的方法
-
- 1.在gridmap地图上构建一张图(graph)的思想
-
- 一、方法一:通过离散控制空间进行采样的方法【control space search】
-
- (1)算法步骤
- (2)算法优点
- (3)算法缺点
- (4)无人车的离散控制空间采样方法举例--DWA
- (5)无人机的离散控制空间采样方法举例
- 二、方法二:通过离散状态空间进行采样的方法【state space search】
-
- (1)算法步骤
- (2)算法优点
- (3)算法缺点
- 三、control space search和state lspace search两种算法的对比
- 总结
- 参考资料
- 2.Rapidly exploring Random Trees(RRT)类算法
-
- (1)基于采样的普通路径规划算法--RRT(Rapidly Exploring Random Tree)
-
- 1.RRT图例
- 2.RRT原理
- 3.RRT伪代码
- 4.RRT总结
- 5.RRT实现的改进【节点搜索改进、节点连接改进】
- (2)基于采样的最优路径规划算法--RRT*(Rapidly Exploring Random Tree*)
-
- 1.RRT*的目的
- 2.RRT*算法原理
- 3.RRT*伪代码
- 4.RRT*算法演示动图(大概能看出RRT*效果)
- (3)RRT算法 VS RRT*算法
- (4)偏重于得到路径后的优化--informed RRT*算法
-
- 1.informed RRT*目的
- 2.informed RRT*算法原理
- 3.informed RRT*伪代码
- 4.informed RRT*缺点
- 5.RRT* VS informed RRT*
- (5)Cross-entropy motion planning算法
-
- 1.算法步骤
- 2.论文参考
- 3.算法效果
- (6)RRT算法其他的变种
- 总结
- 参考资料
- 3.概率路线图probabilistic Roadmap搜索
-
- (1)PRM算法泛化过程
-
- 1.概率路线图
- 2.采样构建阶段
- 3.概率图搜索阶段
- (2)lazy PRM懒惰障碍物检测算法过程(一种高效的算法)
- (3)总结
- (4)参考资料
- 4.
- 四、地图的方法
-
- 1.维诺图Voronoi的生成--避障路径Voronoi Planner
-
- 一、生成与更新代价地图costmap的方式
- 二、生成与更新Distance Map(DM)的方式
- 三、生成与更新Voronoi地图的方式
-
- 1、Voronoi数据结构
- 2、DM和GVD的栅格用dataCell二维数组表示,gridMap_是输入的二值占据栅格地图
- 3、Voronoi地图数据初始化
- 4、添加障碍物
- 5、移除障碍物
- 6、更新障碍物
- 7、更新DM图
- 8、检查Voronoi的条件
- 9、剪枝
- 10、栅格模式匹配
- 11、Voronoi图可视化
- 四、Voronoi Planner的理论详解--Voronoi Edge
- 参考资料
- 五、智能算法的方法
-
- (1)蚁群算法
-
- 一、算法简介的算法思想
- 二、算法实现
-
- 1.计算信息素公式--第一只蚂蚁探索路径的时候的核心思想和计算公式
- 2.更新信息素公式--第二只以后的蚂蚁探索路径的时候的核心思想和计算公式
- 三、总结
- (2)动态规划DP算法
-
- 一、动态规划DP算法简介与核心思想
- 二、动态规划DP算法的适用范围
- 三、动态规划DP算法的步骤【正向求解-逆向寻优的过程】
-
- 1.先遍历最后一个阶段--求最优
- 2.遍历第3阶段--求最优
- 3.遍历第2阶段--求最优
- 4.遍历第1阶段--求最优【这个就是全局最优】
- 5.当从终点阶段开始,向起点阶段进行逆向遍历寻优的过程中,到达起点阶段时就能计算出来最优路径
- 四、动态规划DP算法的难点
- 总结
- 参考资料
前言
认知有限,望大家多多包涵,有什么问题也希望能够与大家多交流,共同成长!本文先对全局路径规划做个简单的介绍,具体内容后续再更,其他模块可以参考去我其他文章
提示:以下是本篇文章正文内容
1、VFH是用地图的方法做运动规划。
2、DWA是用控制采样的方法做运动规划。
3、Astartu Dijkstra是用路径探索及优化的方法做规划。
一、曲线拟合的方法
1.dubins曲线
一、dubins曲线的理论推导
参考下面这个连接,非常详细
https://zhuanlan.zhihu.com/p/120272035
1.理论定理
在1957年, Lester Eli Dubins (1920–2010) 【防盗标记–盒子君hzj】证明任何路径都可以由最大曲率的圆弧段与直线段组成(前提是连接两点之间的路径必须存在)。 换句话说,连接两点的最短路径将通过最大曲率的曲的圆弧和直线段的构成
2.Dubins曲线最短路径的分析

3.Dubins曲线的六种类型
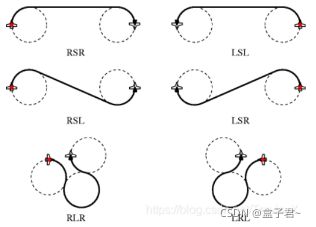
RSR、RSL、LSR、LSL、RLR、LRL(R代表右转, L代表左转,S代表直行)
4.Dubins曲线的约束条件
(1)汽车只能朝前开,不能后退(不能挂倒挡)【防盗标记–盒子君hzj】
5.Dubins曲线实现代码及流程
(0)dubins曲线拟合出来后,检查是否符合长度要求、判断是否与环境障碍物碰撞
//###################################################
// Dubins曲线的调用函数(用Dubins曲线去命中目标点)
//核心原理:
//###################################################
Node3D* dubinsShot(Node3D& start, const Node3D& goal, CollisionDetection& configurationSpace) {
//(1)获取dubins曲线起点
double q0[] = { start.getX(), start.getY(), start.getT() };
//(2)获取dubins曲线目标点
double q1[] = { goal.getX(), goal.getY(), goal.getT() };
//(3)依据始点、目标点位置和最小转弯半径生成一条Dubin路径,保存在path
DubinsPath path;//初始化路径
dubins_init(q0, q1, Constants::r, &path);
int i = 0;
float x = 0.f;
float length = dubins_path_length(&path);
//(4)检查dubins拟合出来的曲线,是否满足长度要求和时候会发生碰撞(若不满足就不输出路径),并把拟合出来曲线的格式改成Node3D
Node3D* dubinsNodes = new Node3D [(int)(length / Constants::dubinsStepSize) + 1];
while (x < length) {//这是跳出循环的条件之一:生成的路径没有达到所需要的长度
double q[3];
dubins_path_sample(&path, x, q); //对一段路径进行采样(根据路径长度t和路径参数path,生成长度为t的节点的位置)
dubinsNodes[i].setX(q[0]);
dubinsNodes[i].setY(q[1]);
dubinsNodes[i].setT(Helper::normalizeHeadingRad(q[2]));
//碰撞检测
if (configurationSpace.isTraversable(&dubinsNodes[i])) {//跳出循环的条件之二:生成的路径存在碰撞节点
//把前一个节点设置到本节点,因为节点是迭代的
if (i > 0) {
dubinsNodes[i].setPred(&dubinsNodes[i - 1]);
} else {
dubinsNodes[i].setPred(&start);
}
if (&dubinsNodes[i] == dubinsNodes[i].getPred()) {
std::cout << "looping shot";
}
x += Constants::dubinsStepSize;
i++;
} else {
// std::cout << "Dubins shot collided, discarding the path" << "\n";
// delete all nodes
delete [] dubinsNodes;
return nullptr;
}
}
// std::cout << "Dubins shot connected, returning the path" << "\n";
//返回末节点,通过getPred()可以找到前一节点。
return &dubinsNodes[i - 1];
}
(1)dubins曲线的流程函数
下面这两个函数主要是准备好dubins曲线的起点和目标点,计算好弧线的半径。
其次是循环调用dubins曲线的六种类型的实现,看看哪种实现的结果最好,代价最低就原则该种类型的曲线实现
/**
* @brief 【核心】依据始点、末点位置和最小转弯半径生成一条Dubin路径
* @param q0 始点
* @param q1 末点
* @param rho 最小转弯半径
* @param path 生成的路径
* @return int
*/
int dubins_init( double q0[3], double q1[3], double rho, DubinsPath* path )
{
double alpha = mod2pi(q0[2] - theta); //计算起点朝向
//计算dubins曲线的准备参数,两点距离d、起点朝向alpha、终点朝向beta
int i;
double dx = q1[0] - q0[0]; //计算两点x坐标偏差
double dy = q1[1] - q0[1]; //计算两点y坐标偏差
double D = sqrt( dx * dx + dy * dy ); //计算两点距离
double d = D / rho; //计算归一化距离d,将两点距离除以最小转弯半径得到归一化距离d
if( rho <= 0. ) { //若曲线最小转弯半径小于0,这是一个不正常的情况
return EDUBBADRHO;
}
double theta = mod2pi(atan2( dy, dx )); //将两点之间的角度范围限制在(-2pi, 2*pi)之间
double alpha = mod2pi(q0[2] - theta); //计算起点朝向
double beta = mod2pi(q1[2] - theta); //计算终点朝向
for( i = 0; i < 3; i ++ ) { //将起点(x,y,yaw)放入path->qi变量
path->qi[i] = q0[i];
}
path->rho = rho;//最小转弯半径,(注意,这里确定了弧线曲率,曲线计算弧线的角度范围就行)
//开始计算dubins曲线
return dubins_init_normalised( alpha, beta, d, path );
}
/**
* @brief 根据alpha, beta, d三个参数找出Dubins类型(LSL, LSR, RSL, RSR, RLR or LRL)
* 并将每段曲线的线段长度(代价)存放到path->param和path->type中
* 注:这是一种简单的穷举尝试策略,与文章“Classification of the Dubins set”描述的策略不同。
*
* @param alpha :角度参数,表示起点朝向
* @param beta : 角度参数,表示终点朝向
* @param d : 起点和终点的距离
* @param path 存放结果,用到两个: path->param代价和path->type
* @return int 返回值:非0值表示出错;0表示正常
*/
int dubins_init_normalised( double alpha, double beta, double d, DubinsPath* path)
{
double best_cost = INFINITY; //没计算出来之前代价是无穷的
int best_word; //可能提供最佳路径类型的解算器
int i;
best_word = -1;
for( i = 0; i < 6; i++ ) { //遍历dubins曲线的六种类型
double params[3];
//【核心】分别调用六种不同的Dubins函数曲线,计算得到角度t,路径p, 节点位置q,存放于params
int err = dubins_words[i](alpha, beta, d, params);
if(err == EDUBOK) {//若能够计算出来dubins曲线,就计算对应的曲线长度代价,选择长度代价最小的dubins路径
//计算三段线段组成的总代价
double cost = params[0] + params[1] + params[2];
//将最好的结果曲线参数保存到path->param,最好的结果曲线参数就是三段代价最低的
if(cost < best_cost) {
best_word = i; //曲线类型
best_cost = cost;
path->param[0] = params[0];
path->param[1] = params[1];
path->param[2] = params[2];
path->type = i; //曲线类型
}
}
}
if(best_word == -1) {
return EDUBNOPATH;
}
path->type = best_word;
return EDUBOK;
}
(2)六种类型LSL, LSR, RSL, RSR, RLR or LRL的曲线计算方法实现函数
//函数指针数组,可以指向不同的函数
//原型为 typedef int (*DubinsWord)(double, double, double, double* );
//下面六个元素是函数名,通过遍历函数名,给定对应函数的参数来计算出来dubins曲线
DubinsWord dubins_words[] = {
dubins_LSL,
dubins_LSR,
dubins_RSL,
dubins_RSR,
dubins_RLR,
dubins_LRL,
};
//这里定义宏展开,方便简化代码
//alpha :角度参数,表示起点朝向
//beta : 角度参数,表示终点朝向
#define UNPACK_INPUTS(alpha, beta) \
double sa = sin(alpha); \
double sb = sin(beta); \
double ca = cos(alpha); \
double cb = cos(beta); \
double c_ab = cos(alpha - beta); \
//定义宏展开,方便简化代码
//outputs
//t :dubins_RSR曲线上第一段曲线的角度代价,以该角度的画圆弧
//p :dubins_RSR曲线上第二段曲线的长度代价,以该长度的画圆弧
//q :dubins_RSR曲线上第三段曲线的角度代价,以该角度的画圆弧
#define PACK_OUTPUTS(outputs) \
outputs[0] = t; \
outputs[1] = p; \
outputs[2] = q;
/**
* 两浮点数取模(就是取长度)
* 对于角量,fmod不能正常工作,此函数可以
*/
double fmodr( double x, double y)
{
return x - y*floor(x/y);
}
/**
* @brief 将角度范围限制在(-2pi, 2*pi)之间
* @param theta 角度
* @return double 计算结果
*/
double mod2pi( double theta )
{
return fmodr( theta, 2 * M_PI );
}
//构造LSL路径类型的的函数
//inputs alpha : 起点朝向
//inputs beta : 终点朝向
//inputs d :两点间归一化距离长度
//outputs t :dubins_RSR曲线上第一段路径长度/圆弧角度
//outputs p :dubins_RSR曲线上第二段路径的直线长度/圆弧角度
//outputs q :dubins_RSR曲线上第三段路径直线长度/圆弧长角度
int dubins_LSL( double alpha, double beta, double d, double* outputs )
{
UNPACK_INPUTS(alpha, beta);
double tmp0 = d+sa-sb;
double p_squared = 2 + (d*d) -(2*c_ab) + (2*d*(sa - sb));
if( p_squared < 0 ) {
return EDUBNOPATH;
}
double tmp1 = atan2( (cb-ca), tmp0 );
double t = mod2pi(-alpha + tmp1 );
double p = sqrt( p_squared );
double q = mod2pi(beta - tmp1 );
PACK_OUTPUTS(outputs);
return EDUBOK;
}
//构造RSR路径类型的的函数
//inputs alpha : 起点朝向
//inputs beta : 终点朝向
//inputs d :两点间归一化距离长度
//outputs t :dubins_RSR曲线上第一段路径长度/圆弧长度
//outputs p :dubins_RSR曲线上第二段路径的直线长度/圆弧长度
//outputs q :dubins_RSR曲线上第三段路径直线长度/圆弧长度
int dubins_RSR( double alpha, double beta, double d, double* outputs )
{
UNPACK_INPUTS(alpha, beta); //输入起点朝向、终点朝向,计算对应的正余弦参数
double tmp0 = d-sa+sb;
double p_squared = 2 + (d*d) -(2*c_ab) + (2*d*(sb-sa));
if( p_squared < 0 ) {
return EDUBNOPATH;
}
double tmp1 = atan2( (ca-cb), tmp0 );
double t = mod2pi( alpha - tmp1 ); //dubins_RSR曲线上第一段曲线的角度代价
double p = sqrt( p_squared ); //dubins_RSR曲线上第二段曲线的长度代价
double q = mod2pi( -beta + tmp1 ); //dubins_RSR曲线上第三段曲线的角度代价
PACK_OUTPUTS(outputs); //输出dubins_RSR曲线的参数(代价)
return EDUBOK;
}
//构造LSR路径类型的的函数
//inputs alpha : 起点朝向
//inputs beta : 终点朝向
//inputs d :两点间归一化距离长度
//outputs t :dubins_RSR曲线上第一段路径长度/圆弧长度
//outputs p :dubins_RSR曲线上第二段路径的直线长度/圆弧长度
//outputs q :dubins_RSR曲线上第三段路径直线长度/圆弧长度
int dubins_LSR( double alpha, double beta, double d, double* outputs )
{
UNPACK_INPUTS(alpha, beta);
double p_squared = -2 + (d*d) + (2*c_ab) + (2*d*(sa+sb));
if( p_squared < 0 ) {
return EDUBNOPATH;
}
double p = sqrt( p_squared );
double tmp2 = atan2( (-ca-cb), (d+sa+sb) ) - atan2(-2.0, p);
double t = mod2pi(-alpha + tmp2);
double q = mod2pi( -mod2pi(beta) + tmp2 );
PACK_OUTPUTS(outputs);
return EDUBOK;
}
//构造RSL路径类型的的函数
//inputs alpha : 起点朝向
//inputs beta : 终点朝向
//inputs d :两点间归一化距离长度
//outputs t :dubins_RSR曲线上第一段路径长度/圆弧长度
//outputs p :dubins_RSR曲线上第二段路径的直线长度/圆弧长度
//outputs q :dubins_RSR曲线上第三段路径直线长度/圆弧长度
int dubins_RSL( double alpha, double beta, double d, double* outputs )
{
UNPACK_INPUTS(alpha, beta);
double p_squared = (d*d) -2 + (2*c_ab) - (2*d*(sa+sb));
if( p_squared< 0 ) {
return EDUBNOPATH;
}
double p = sqrt( p_squared );
double tmp2 = atan2( (ca+cb), (d-sa-sb) ) - atan2(2.0, p);
double t = mod2pi(alpha - tmp2);
double q = mod2pi(beta - tmp2);
PACK_OUTPUTS(outputs);
return EDUBOK;
}
//构造RLR路径类型的的函数
//inputs alpha : 起点朝向
//inputs beta : 终点朝向
//inputs d :两点间归一化距离长度
//outputs t :dubins_RSR曲线上第一段路径长度/圆弧长度
//outputs p :dubins_RSR曲线上第二段路径的直线长度/圆弧长度
//outputs q :dubins_RSR曲线上第三段路径直线长度/圆弧长度
int dubins_RLR( double alpha, double beta, double d, double* outputs )
{
UNPACK_INPUTS(alpha, beta);
double tmp_rlr = (6. - d*d + 2*c_ab + 2*d*(sa-sb)) / 8.;
if( fabs(tmp_rlr) > 1) {
return EDUBNOPATH;
}
double p = mod2pi( 2*M_PI - acos( tmp_rlr ) );
double t = mod2pi(alpha - atan2( ca-cb, d-sa+sb ) + mod2pi(p/2.));
double q = mod2pi(alpha - beta - t + mod2pi(p));
PACK_OUTPUTS( outputs );
return EDUBOK;
}
//构造LRL路径类型的的函数
//inputs alpha : 起点朝向
//inputs beta : 终点朝向
//inputs d :两点间归一化距离长度
//outputs t :dubins_RSR曲线上第一段路径长度/圆弧长度
//outputs p :dubins_RSR曲线上第二段路径的直线长度/圆弧长度
//outputs q :dubins_RSR曲线上第三段路径直线长度/圆弧长度
int dubins_LRL( double alpha, double beta, double d, double* outputs )
{
UNPACK_INPUTS(alpha, beta);
double tmp_lrl = (6. - d*d + 2*c_ab + 2*d*(- sa + sb)) / 8.;
if( fabs(tmp_lrl) > 1) {
return EDUBNOPATH;
}
double p = mod2pi( 2*M_PI - acos( tmp_lrl ) );
double t = mod2pi(-alpha - atan2( ca-cb, d+sa-sb ) + p/2.);
double q = mod2pi(mod2pi(beta) - alpha -t + mod2pi(p));
PACK_OUTPUTS( outputs );
return EDUBOK;
}
(3)获取计算出来的dubins曲线的各种参数的调用函数
1、计算路径长度
/**
* @brief 计算路径长度
*
* @param path : 三个参数表示角度
* @return double :返回值,表示路径长度
*/
double dubins_path_length( DubinsPath* path )
{
double length = 0.;
length += path->param[0];
length += path->param[1];
length += path->param[2];
length = length * path->rho;//反归一化,就是按比例恢复成真实长度
return length;
}
2、返回路径类型
/**
* @brief 返回路径类型
*
* @param path 输入:路径
* @return int 返回值:路径类型
*/
int dubins_path_type( DubinsPath* path ) {
return path->type;
}
3、计算下一段Dubins路径段的位置
/**
* @brief 计算下一段Dubins路径段的位置
*
* @param t 角度
* @param qi 该段起始位置
* @param qt 该段终点位置
* @param type 路径类型
*/
void dubins_segment( double t, double qi[3], double qt[3], int type)
{
assert( type == L_SEG || type == S_SEG || type == R_SEG );
//Shkel A M, Lumelsky V. Classification of the Dubins set[J]. Robotics and Autonomous Systems, 2001, 34(4): 179-202.
if( type == L_SEG ) {//公式 (1)的第一个式子,此处经过归一化后v=1
qt[0] = qi[0] + sin(qi[2]+t) - sin(qi[2]);
qt[1] = qi[1] - cos(qi[2]+t) + cos(qi[2]);
qt[2] = qi[2] + t;
}
else if( type == R_SEG ) {//公式(1)的第二个式子,此处经过归一化后v=1
qt[0] = qi[0] - sin(qi[2]-t) + sin(qi[2]);
qt[1] = qi[1] + cos(qi[2]-t) - cos(qi[2]);
qt[2] = qi[2] - t;
}
else if( type == S_SEG ) {//公式(1)的第三个式子,此处经过归一化后v=1
qt[0] = qi[0] + cos(qi[2]) * t;
qt[1] = qi[1] + sin(qi[2]) * t;
qt[2] = qi[2];
}
}
4、对一段路径进行采样(根据路径长度t和路径参数path,生成长度为t的节点的位置)
/**
* @brief 通过回调函数多次调用dubins_path_sample
*
* @param path
* @param cb
* @param stepSize
* @param user_data
* @return int
*/
int dubins_path_sample_many( DubinsPath* path, DubinsPathSamplingCallback cb, double stepSize, void* user_data )
{
double x = 0.0;
double length = dubins_path_length(path);
while( x < length ) {
double q[3];
dubins_path_sample( path, x, q );
int retcode = cb(q, x, user_data);
if( retcode != 0 ) {
return retcode;
}
x += stepSize;
}
return 0;
}
int dubins_path_sample( DubinsPath* path, double t, double q[3] )
{
if( t < 0 || t >= dubins_path_length(path) ) {
// error, parameter out of bounds
return EDUBPARAM;
}
// tprime is the normalised variant of the parameter t
double tprime = t / path->rho;
// In order to take rho != 1 into account this function needs to be more complex
// than it would be otherwise. The transformation is done in five stages.
//
// 1. translate the components of the initial configuration to the origin
// 2. generate the target configuration
// 3. transform the target configuration
// scale the target configuration
// translate the target configration back to the original starting point
// normalise the target configurations angular component
// The translated initial configuration
// 将路径放在原点(0, 0),此时,只需要将角度保留即可
double qi[3] = { 0, 0, path->qi[2] };
// Generate the target configuration
// 生成中间点的位置
const int* types = DIRDATA[path->type];
double p1 = path->param[0];//路径的第一个角度
double p2 = path->param[1];//路径的第二个角度
double q1[3]; // end-of segment 1
double q2[3]; // end-of segment 2
//从第qi点为起点,根据类型types[0],生成后一个点q1的configuration(即计算下一个节点的位置)
dubins_segment( p1, qi, q1, types[0] );
//从第q1点为起点,根据类型types[1],生成后一个点q2的configuration(即计算下一个节点的位置)
dubins_segment( p2, q1, q2, types[1] );
//生成q点的configuration
if( tprime < p1 ) {
dubins_segment( tprime, qi, q, types[0] );
}
else if( tprime < (p1+p2) ) {
dubins_segment( tprime-p1, q1, q, types[1] );
}
else {
dubins_segment( tprime-p1-p2, q2, q, types[2] );
}
// scale the target configuration, translate back to the original starting point
q[0] = q[0] * path->rho + path->qi[0];
q[1] = q[1] * path->rho + path->qi[1];
q[2] = mod2pi( q[2] );
return 0;
}
5、根据路径参数path, 返回线段末节点参数
/**
* @brief 根据路径参数path, 返回线段末节点参数
*
* @param path
* @param q
* @return int
*/
int dubins_path_endpoint( DubinsPath* path, double q[3] )
{
// TODO - introduce a new constant rather than just using EPSILON
return dubins_path_sample( path, dubins_path_length(path) - EPSILON, q );
}
6、 将一段路径path,按路径长度t,划分为多个子线段
/**
* @brief 将一段路径path,按路径长度t,划分为多个子线段。
*
* @param path 输入的路径
* @param t 子线段长度
* @param newpath 生成的新的路径
* @return int
*/
int dubins_extract_subpath( DubinsPath* path, double t, DubinsPath* newpath )
{
// calculate the true parameter
double tprime = t / path->rho;
// copy most of the data
newpath->qi[0] = path->qi[0];
newpath->qi[1] = path->qi[1];
newpath->qi[2] = path->qi[2];
newpath->rho = path->rho;
newpath->type = path->type;
// fix the parameters
newpath->param[0] = fmin( path->param[0], tprime );
newpath->param[1] = fmin( path->param[1], tprime - newpath->param[0]);
newpath->param[2] = fmin( path->param[2], tprime - newpath->param[0] - newpath->param[1]);
return 0;
}
.
.
.
.
二、二维dubins曲线的工程实现
1.先输入dubins曲线的起点位姿start_pose、目标点位姿goal_pose、圆弧曲率,再计算6种类型的dubins曲线三段t、q、p参数,最后选择直线代价cost最小的一条dubins曲线
/**
* @brief 依据始点、末点位置和最小转弯半径生成一条Dubin路径
* 原理:输入dubins曲线的起点和目标点,计算好弧线的半径。
其次是循环调用dubins曲线的六种类型的实现,看看哪种实现的结果最好,代价最低就原则该种类型的曲线实现
* @param start 始点(包含角度)
* @param goal_ 末点(包含角度)
* @param curve 指定的最小转弯半径
* @param path 生成的路径
* @param alpha_ 起点朝向
* @param beta_ 终点朝向
* @param dist_ 两点间归一化距离长度
* @return bool
*/
bool DubinsCurves::plan(Pose& start, Pose& goal_, float curve,
AgileX::VectorAgx<AgileX::Pose>& path) {
PointF new_goal, new_goal2;
Transformation transform;
start_yaw_ = start.yaw_;
new_goal.x() = goal_.point_.x() - start.point_.x();
new_goal.y() = goal_.point_.y() - start.point_.y();
transform.start_pos_ = start.point_;
transform.theta_ = start.yaw_;
transform.cosTheta_ = std::cos(transform.theta_);
transform.sinTheta_ = std::sin(transform.theta_);
AgileX::convertPointToLocal(&transform, goal_.point_, &new_goal2);
dist_ = new_goal2.norm() * curve;
float theta = mod2pi(std::atan2(new_goal2.y(), new_goal2.x()));
alpha_ = mod2pi(-theta);
beta_ = mod2pi(goal_.yaw_ - start.yaw_ - theta);
sin_a = std::sin(alpha_);
sin_b = std::sin(beta_);
cos_a = std::cos(alpha_);
cos_b = std::cos(beta_);
cos_a_b = std::cos(alpha_ - beta_);
float t, p, q, min_cost = 1e7f, cost;
float best_t, best_p, best_q;
//调用dubins曲线的六种类型的实现,看看哪种实现的结果最好,代价最低就原则该种类型的曲线实现
//全局输入起点朝向alpha_,终点朝向beta_和两点距离dist_,输出t, p, q
//代价优化:只算圆弧的长度,直线的代价为0
if (LSL(t, p, q)) {
cost = fabs(t) + fabs(p) + fabs(q);
if (cost < min_cost) {
min_cost = cost;
best_t = t;
best_p = p;
best_q = q;
p_is_arc_ = false;
}
}
if (RSR(t, p, q)) {
cost = fabs(t) + fabs(p) + fabs(q);
if (cost < min_cost) {
min_cost = cost;
best_t = t;
best_p = p;
best_q = q;
p_is_arc_ = false;
}
}
if (LSR(t, p, q)) {
cost = fabs(t) + fabs(p) + fabs(q);
if (cost < min_cost) {
min_cost = cost;
best_t = t;
best_p = p;
best_q = q;
p_is_arc_ = false;
}
}
if (RSL(t, p, q)) {
cost = fabs(t) + fabs(p) + fabs(q);
if (cost < min_cost) {
min_cost = cost;
best_t = t;
best_p = p;
best_q = q;
p_is_arc_ = false;
}
}
if (RLR(t, p, q)) {
cost = fabs(t) + fabs(p) + fabs(q);
if (cost < min_cost) {
min_cost = cost;
best_t = t;
best_p = p;
best_q = q;
p_is_arc_ = true; //中间段是曲线就是true
}
}
if (LRL(t, p, q)) {
cost = fabs(t) + fabs(p) + fabs(q);
if (cost < min_cost) {
min_cost = cost;
best_t = t;
best_p = p;
best_q = q;
p_is_arc_ = true;
}
}
if (min_cost < 1e7f - 1) {
path.clear();
Pose path_tmp[200];
int size = calPath(best_t, best_p, best_q, p_is_arc_, curve, path_tmp);
path.resize(size);
for (int i = 0; i < size; ++i) {
AgileX::convertPointToGlobal(&transform, path_tmp[i].point_,
&path[i].point_);
path[i].yaw_ = AgileX::pi2pi(path_tmp[i].yaw_ + start_yaw_);
}
MCU_LOG("dubin size %d\n", size);
return true;
} else
return false;
}
(1)6种dubins曲线三段参数的计算公式
// dist_: 两点间归一化距离长度
bool DubinsCurves::LSL(float& t, float& p, float& q) {
p = 2 + pow(dist_, 2) - 2 * cos_a_b + 2 * dist_ * (sin_a - sin_b);
if (p < 0)
return false;
else
p = std::sqrt(p);
float tmp = dist_ + sin_a - sin_b;
float tmp2 = std::atan2(cos_b - cos_a, tmp);
t = mod2pi(-alpha_ + tmp2);
q = mod2pi(beta_ - tmp2);
return true;
}
bool DubinsCurves::RSR(float& t, float& p, float& q) {
p = 2 + pow(dist_, 2) - 2 * cos_a_b + 2 * dist_ * (sin_b - sin_a);
if (p < 0)
return false;
else
p = std::sqrt(p);
float tmp = dist_ - sin_a + sin_b;
float tmp2 = std::atan2(cos_a - cos_b, tmp);
t = mod2pi(alpha_ - tmp2);
q = mod2pi(-beta_ + tmp2);
t = -t;
q = -q;
return true;
}
bool DubinsCurves::LSR(float& t, float& p, float& q) {
p = -2 + pow(dist_, 2) + 2 * cos_a_b + 2 * dist_ * (sin_a + sin_b);
if (p < 0)
return false;
else
p = std::sqrt(p);
float tmp = std::atan2(-cos_a - cos_b, dist_ + sin_a + sin_b) -
std::atan2(-2.0f, p);
t = mod2pi(-alpha_ + tmp);
q = mod2pi(-mod2pi(beta_) + tmp);
q = -q;
return true;
}
bool DubinsCurves::RSL(float& t, float& p, float& q) {
p = -2 + pow(dist_, 2) + 2 * cos_a_b - 2 * dist_ * (sin_a + sin_b);
if (p < 0)
return false;
else
p = std::sqrt(p);
float tmp =
std::atan2(cos_a + cos_b, dist_ - sin_a - sin_b) - std::atan2(2.0f, p);
t = mod2pi(alpha_ - tmp);
q = mod2pi(beta_ - tmp);
t = -t;
return true;
}
bool DubinsCurves::RLR(float& t, float& p, float& q) {
float tmp = (6.0f - pow(dist_, 2) + 2.0f * cos_a_b +
2.0f * dist_ * (sin_a - sin_b)) /
8.0f;
if (abs(tmp) > 1.0f) return false;
p = mod2pi(2 * M_PI - acos(tmp));
t = mod2pi(alpha_ - std::atan2(cos_a - cos_b, dist_ - sin_a + sin_b) +
mod2pi(p / 2.0f));
q = mod2pi(alpha_ - beta_ - t + mod2pi(p));
t = -t;
q = -q;
return true;
}
bool DubinsCurves::LRL(float& t, float& p, float& q) {
float tmp = (6.0f - pow(dist_, 2) + 2.0f * cos_a_b +
2.0f * dist_ * (sin_b - sin_a)) /
8.0f;
if (abs(tmp) > 1.0f) return false;
p = mod2pi(2 * M_PI - acos(tmp));
t = mod2pi(-alpha_ - std::atan2(cos_a - cos_b, dist_ + sin_a - sin_b) +
p / 2.0f);
q = mod2pi(mod2pi(beta_) - alpha_ - t + mod2pi(p));
p = -p;
return true;
}
2.根据t、p、q和给定的curve生成一条具体的dubins曲线path
// 根据t、p、q和给定的curve生成一条具体的dubins曲线path
// t :dubins曲线上第一段路径长度/圆弧角度
// p :dubins曲线上第二段路径的直线长度/圆弧角度
// q :dubins_曲线上第三段路径直线长度/圆弧长角度
// curve : 最小转弯半径
// p_is_arc:是否有中间的直线段
int DubinsCurves::calPath(float t, float p, float q, bool p_is_arc, float curve,
Pose path[]) {
PointF center_point;
float r = 1 / curve;
float step, l;
float angle1, angle2, angle3;
int flag;
int size, n;
for (int k = 0; k < 3; ++k) {
if (k == 0) {
l = t;
size = 0;
flag = l > 0 ? 1 : -1;
n = ceil(fabs(l) * r / point_interval_dis_) + 1;
step = fabs(l) / (n - 1) * flag;
angle1 = -M_PI * 0.5f * flag;
center_point = PointF(0, flag * r);
} else {
if (k == 1) {
if (!p_is_arc) {
n++;
path[n - 1].point_.x() =
path[n - 2].point_.x() + cos(path[n - 2].yaw_) * p * r;
path[n - 1].point_.y() =
path[n - 2].point_.y() + sin(path[n - 2].yaw_) * p * r;
path[n - 1].yaw_ = path[n - 2].yaw_;
continue;
}
l = p;
} else
l = q;
size += n;
flag = l > 0 ? 1 : -1;
angle3 = AgileX::pi2pi(path[size - 1].yaw_ + M_PI_F * 0.5f * flag);
center_point.x() = path[size - 1].point_.x() + cos(angle3) * r;
center_point.y() = path[size - 1].point_.y() + sin(angle3) * r;
n = ceil(fabs(l) * r / point_interval_dis_) + 1;
step = fabs(l) / (n - 1) * flag;
angle1 = AgileX::pi2pi(path[size - 1].yaw_ - M_PI_F * 0.5f * flag);
}
for (int i = 0; i < n - 1; i++) {
angle2 = i * step;
path[size + i].point_.x() =
center_point.x() + cos(angle1 + angle2) * r;
path[size + i].point_.y() =
center_point.y() + sin(angle1 + angle2) * r;
if (size != 0)
path[size + i].yaw_ =
AgileX::pi2pi(angle2 + path[size - 1].yaw_);
else
path[size + i].yaw_ = AgileX::pi2pi(angle2);
}
path[size + n - 1].point_.x() = center_point.x() + cos(angle1 + l) * r;
path[size + n - 1].point_.y() = center_point.y() + sin(angle1 + l) * r;
if (size != 0)
path[size + n - 1].yaw_ = AgileX::pi2pi(l + path[size - 1].yaw_);
else
path[size + n - 1].yaw_ = AgileX::pi2pi(l);
if (k == 2) {
size = size + n;
break;
}
}
return size;
}
3.相关初始化参数设置
class DubinsCurves {
public:
DubinsCurves() {
point_interval_dis_ = 0.3f;
curve1_ = 1 / 0.8f;
curve2_ = 1 / 0.5f;
front_dis_ = 2.0f;
charge_point_compare_dis_ = 2.0f;
charge_point_dis_ = charge_point_compare_dis_;
left_right_interval_ = 0.5f;
angle_offset_ = 2 * M_PI / DUBINS_START_POINTS_N;
start_pose_id_ = 0;
alpha_ = beta_ = dist_ = start_yaw_ = 0;
sin_a = sin_b = 0;
cos_a = cos_b = cos_a_b = 1;
p_is_arc_ = false;
// all_path_.resize(DUBINS_START_POINTS_N * 2);
// for (int i = 0; i < DUBINS_START_POINTS_N * 2; ++i)
// all_path_[i].setDefaultValueZeroWhenNoRealConstructionObject();
};
private:
bool plan(Pose& start, Pose& goal, float curve,
AgileX::VectorAgx<AgileX::Pose>& path);
private:
float mod2pi(float theta) {
return theta - 2.0f * M_PI_F * floor(theta / M_PI_F * 0.5f);
};
bool LSL(float& t, float& p, float& q);
bool RSR(float& t, float& p, float& q);
bool LSR(float& t, float& p, float& q);
bool RSL(float& t, float& p, float& q);
bool RLR(float& t, float& p, float& q);
bool LRL(float& t, float& p, float& q);
int calPath(float t, float p, float q, bool p_is_arc, float curve,
Pose path[]);
private:
Pose robot_pose_;
Pose goal_;
float point_interval_dis_, curve1_, curve2_;
float alpha_, beta_, dist_, charge_point_compare_dis_;
float start_yaw_;
float sin_a, sin_b, cos_a, cos_b, cos_a_b;
float front_dis_, charge_point_dis_;
float left_right_interval_;
float angle_offset_;
int start_pose_id_;
bool p_is_arc_;
};
2.Reeds-Shepp曲线
(1)Reeds-Shepp曲线的理论推导
参考下面这个连接,非常详细
https://zhuanlan.zhihu.com/p/122544884
.
.
1.理论定理
J Reeds和L Shepp证明车辆从起点到终点的最短路径一定是下面的46种类型的其中之一
2.Reeds-Shepp曲线的由来
【泊车场景】想象你下班开车回家,到了小区后把车停到车位里。【防盗标记–盒子君hzj】作为一个喜欢追求挑战的老司机,你想找一条最短的路径把车停进去。那么这样的路径就是Reeds-Shepp曲线
最短路径的分析
(1)直线情况
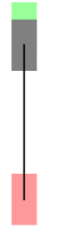
汽车车头刚好对准了停车位(绿色表示停车位,红色表示汽车的起始状态,灰色表示汽车)
(2)Reeds-Shepp曲线情况

.
.
3.Reeds-Shepp曲线的46种类型

表格中的"|"表示车辆运动朝向由正向转为反向或者由反向转为正向
4.Reeds-Shepp曲线的约束条件
汽车既能朝前开,又能后退(能挂倒挡)的情况下,【防盗标记–盒子君hzj】行驶的必须是最短路径
5.Reeds-Shepp曲线的应用场景
(1)自动泊车的路径规划replan
(2)车辆180度转弯的路径规划replan
6.Reeds-Shepp曲线的代码实现
(1)OMPL的Reeds Sheep实现代码
https://ompl.kavrakilab.org/ReedsSheppStateSpace_8cpp_source.html
(2)hybrid a*的Reeds Sheep实现代码
.
.
(2)Dubins曲线与Reeds-Shepp曲线的功能及对比
1.功能对比
Dubins曲线是在满足曲率约束和规定的始端和末端的切线方向的条件下,【防盗标记–盒子君hzj】连接两个二维平面(即X-Y平面)的最短路径,并假设车辆行驶的道路只能向前行进。如果车辆也可以在反向行驶,则路径为Reeds–Shepp曲线
2.异同点对比
(1)对比图例

红线表示Dubins曲线,绿线表示Reeds-Shepp曲线
(2)Reeds-Shepp曲线优点
可以通过先前进再倒车的方式,【防盗标记–盒子君hzj】实现更短的路径完成规划任务,例如自动泊车
(3)用法对比
(1)都是通过圆弧和直线相连接形成的路径作为规划的路径
(2)Reeds-Shepp曲线和Dubins曲线是实现同一类型功能的两种不同方法
(3)不存在障碍物时,Reeds-Shepp曲线和Dubins曲线对任意的起止位姿都存在
(4)存在障碍物时,【防盗标记–盒子君hzj】Reeds-Shepp曲线和Dubins曲线特指没有障碍物时的最短路径。如果存在障碍物,只要存在连接起止位姿的无碰撞路径,那么就存在无碰撞的Reeds-Shepp曲线,但是不一定存在Dubins曲线
(3)算法实现
这两种曲线实现有库可以调用,可以用ompl运动规划库实现。
(4)总结
Dubins曲线插值拟合算法是双圆弧轨迹插值拟合算法的升级版,Dubins曲线理论上也是不符合车辆运动学的,因为曲线的曲率不能突变
Dubins曲线与Reeds-Shepp曲线,经过优化后都可以用于无人驾驶自动泊车
(5)参考资料
(1)参考链接
https://zhuanlan.zhihu.com/p/120272035
https://zhuanlan.zhihu.com/p/122544884
https://blog.csdn.net/robinvista/article/details/95137143
https://www.cnblogs.com/-wenli/p/11848076.html
(2)参考论文
(1)dubins曲线参考论文
[1]Shkel A Mc Lumelsky V. Classification of the Dubins set[J]. Robotics and Autonomous Systems 34(4): 179-202.
[2]Giese A. A Comprehensive Step-by-Step Tutorial on Computing Dubins’s Curves[J]. 2014.
[3]Eriksson-Bique S Kirkpatrick D%2c Polishchuk V. Discrete dubins paths[J]. arXiv preprint arXiv 2012
(2)Reeds-Shepp曲线参考论文
[1]Reeds J, Shepp L. Optimal paths for a car that goes both forwards and backwards[J]. Pacific journal of mathematics, 1990, 145(2): 367-393.
(3)视频展示
https://www.bilibili.com/video/BV1g44y1279h?spm_id_from=333.999.0.0
https://www.bilibili.com/video/BV1pq4y1N7so?spm_id_from=333.999.0.0
类汽车型机器人的转向功能
https://www.bilibili.com/video/BV1vg411L7ii?spm_id_from=333.999.0.0
(4)源码链接
dubins曲线工程链接
https://github.com/AndrewWalker/Dubins-Curves/
.
.
二、图搜索的方法
0、基于栅格地图的路径搜索–把栅格地图转换成搜索图

1.DFS\BFS\DFS-ID搜索算法
(1)深度优先搜索Depth-First-Searching(DFS)
1.适合的路径规划应用场景
存在在狭窄的通道中环境,依此弹出每条最深的路径,一条路走到黑【防盗标记–盒子君hzj】
.
2.维护容器

用的是队列(先入先出的数据结构)来维护容器
.
3.搜索过程图例
1)节点图一维形式(一条路走到黑a的搜索形状)【防盗标记–盒子君hzj】

2)栅格地图二维形式(一条路的搜索形状)
【把栅格地图中填充值并确定方向进行深度搜索】

4.伪代码
TODO:待补充
…
(2)广度优先搜索Breadth-First Searching(BFS)
1.适合的路径规划应用场景
有连续成片的障碍物,依此弹出每条最广(浅)的路径,一层一层的走
2.维护容器

用的是队列(先入后出的数据结构)来维护容器
3.搜索过程图例
(1)节点图一维形式(一个圆的搜索形状)

(2)栅格地图二维形式(一个圆的搜索形状)
【把栅格地图中填充值并确定方向进行深度搜索】

4.伪代码(Graph Based的BFS最短路径规划)
可参考下面链接的python代码
https://zhuanlan.zhihu.com/p/114406315
.
.
(3)迭代加深Best-First Searching(DFS-ID)的深度优先搜索
(4)总结
(1)DFS\BFS\DFS-ID搜索算法对比
1)算法工作原理
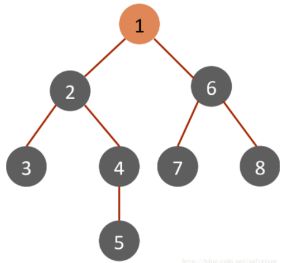
1、深度优先搜索:1->2->3 1->2->4->5 1->6->7 1->6->8
2、广度优先搜索:1->2 1->6 1->2->3 1->2->4 1->6->7 1->6->8 1->2->4->5
3、迭代加深(DFS-ID)的深度优先搜索::1->2 1->6 2->3 2->4->5 6->7 6->8 4->5
(2)三种算法的选择
1)选择深度优先搜索:当树很深、【防盗标记–盒子君hzj】分支因子不大、在树中解出现的位置相对较深时
2)选择广度优先搜索:当搜索树的分支因子不太大、在树中解出现的位置在合理的深度级别、路径不是非常深
3)选择迭代加深的深度优先搜索(DFS-ID):DFS-ID同时具备DFS和BFS的有利性
核心思想:盲目式的图搜索算法
.
.
2.贪心算法、Dijkstra和A*类路径搜索算法
(1)greedy best frist search贪心算法
1.核心思想
构造一个启发式的猜测h(n)来实现现在如何更靠近目标点,【防盗标记–盒子君hzj】没有计算代价值g(n),仅仅靠启发函数代价值h(n)【防盗标记–盒子君hzj】
.
2.构造启发式猜测h(n)方法
(1)欧式距离(Euclidean distance)
(2)曼哈式距离(manhattan distance)
.
如何选择什么样的启发函数?
【没有最好的启发函数,只有适合的启发函数】
.
3.启发式的搜索方法优势
(1)启发式的搜索会指导一个靠近目标点的正确方向【防盗标记–盒子君hzj】
(2)启发式的搜索计算量会更少
4.栅格地图二维形式(一个直捣黄龙的搜索形状)
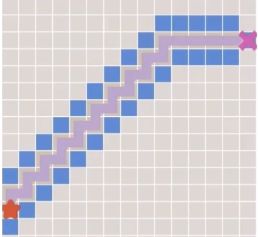
5.伪代码
TODO:待补充
…
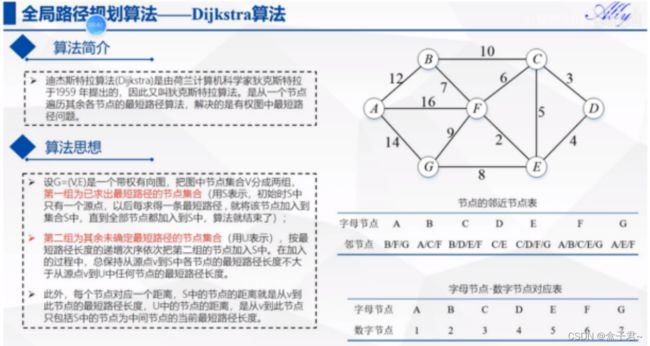
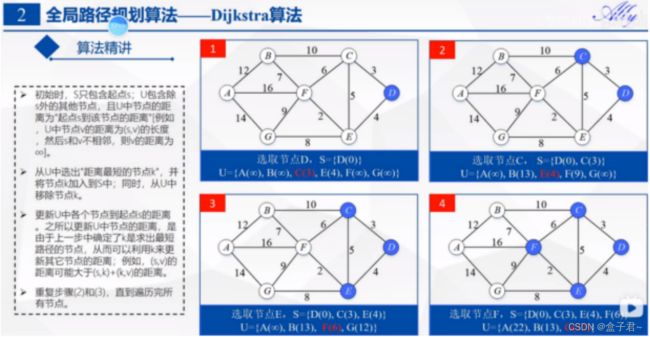
(2)Dijkstra算法
1.核心思想
处理路径规划中的代价最优问题,全局搜索的策略,Dijkstar是单源最短路径算法的一个实现。如果给定了目标节点,则当到达该节点时,算法停止;否则,它将继续,直到找到从源节点到所有其他节点的路径。接受一个可选cost(或“weight”)函数,该函数将在每次迭代时调用。【防盗标记–盒子君hzj】还接受一个可选的启发式函数,该函数用于将算法推向目标,而不是在每个方向上展开。使用这种启发式函数将Dijkstra转换为*(这就是“Dijkstar”这个名字的由来)
搜索每一个节点的时候会计算一个代价值g(n),【防盗标记–盒子君hzj】最终弹出的事代价值最小的节点,用于图中寻找最短(代价)路径
2.伪代码


策略:
每次取出容器中累计代价g(n)最小的节点
过程:
g(n):从初始点到点n的累计代价
g(m):更新节点“n”的所有未拓展邻居“m”的累计成本
已扩展节点的累计代价应为到起始点的最短路径代价
(1)算法过程如下
第一步:从未访问的节点选择距离(代价)最小的节点收录,【防盗标记–盒子君hzj】g(n)表示从起点开始到当前节点的代价累加值(基于贪心思想)
贪心算法只管(当前节点)相对于(已经收录的节点)的最优的选择,不会全局进行考虑
第二步:2.收录节点后遍历该节点的邻接节点,【防盗标记–盒子君hzj】更新计算n节点的所有临近节点m的代价值g(m)【防盗标记–盒子君hzj】
(2)算法复杂度分析
3.图例(一个直捣黄龙的搜索形状)【广而优】
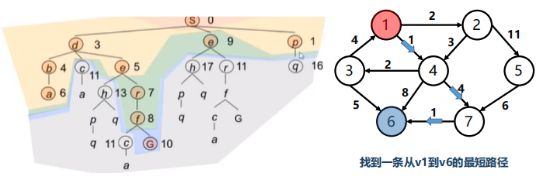
圆圈表示路径的中间节点,有向射线代表的是两个相邻节点路径上的代价【通过两点间的距离公式计算出来】
.
4.优点分析
Dijkstra算法得到的路径代价值肯定是最优的【防盗标记–盒子君hzj】
.
5.缺点分析
知道前面3步就做前面3步的优化搜索,知道前面5步就做前面5步的优化搜索
【基于贪心的思想】
【通过迭代计算局部最优的方式进而求得全局最优,【防盗标记–盒子君hzj】本质上式可以,但是效率不高】
计算量大,像广度优先算法一样发散的去寻找最优解(代价最低的节点),扩展不具有方向性,没有利用到目标点的信息
.
6.参考资料
https://github.com/lh9171338/Astar
https://zhuanlan.zhihu.com/p/162995649
每个list中的节点包含节点的位置和代价。有权图的全部节点=开集的节点+闭集的节点
(2)算法步骤
在开集中,若是当前节点的邻节点将会被更新代价,若不是当前节点的邻节点其代价为无穷大。在开集open_list中代价最低的节点将会被放入闭集close_list,没有被选中的节点依然会保留在开集open_list中。不断搜索迭代,直到找到目标点或者遍历完开集
(3)A*算法
1.核心思想
A算法是移动机器人路径规划领域非常经典的一种规划方式,【防盗标记–盒子君hzj】应用于机器人的移动路径主要由估值函数来决定。A算法的具体运行原理是从机器人的运动起始点作为初始点,以此搜索周围的八个节点,然后运用估价函数计算八个节点的最低代价值的点作为下个运行节点,之后以此循环过程直至到达终止点
现在比较好的规划算法本质都是从A算法的基础上衍生发展而来的,A算法一个带有启发式的Dijkstra算法(一般用启发式距离(两点的直线距离)表示),当A算法的h(n)恒=0时,A算法就退化成为一个Dijkstra算法了,A算法和Dijkstra算法的实现是相当像的,.意在寻找一个从起点到目标节点的最短路径.
【防盗标记–盒子君hzj】A算法的本质是广度优先的图搜索.意在寻找一个从起点到目标节点的最短路径.

Dijkstra仅仅只有g(n)的代价、贪心算法仅仅只有h(n)的代价、A*算法同时拥有g(n)、h(n)的两个代价
.
.
2.构造启发式猜测h(n)方法
(1)欧式距离(Euclidean distance)
(2)曼哈式距离(manhattan distance)
如何选择什么样的启发函数?
【没有最好的启发函数,只有适合的启发函数】
.
.
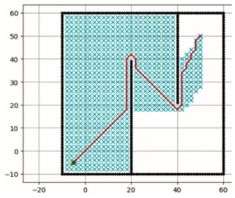
3.栅格地图二维形式(一个直捣黄龙的搜索形状)【广而优】
4.代码实现



(0)搜索流程伪代码即步骤解析

累计代价
g(n):从起始状态到节点“n”的最小估计代价
• 启发式函数
h(n):从节点到目标点的最小估计代价
• 从起始状态到目标状态,经过节点“n”的最小估计代价为
f(n)=g(n)+h(n)
• 策略
取出具有最小f(n)的节点
步骤:
步骤(0)初始化open_list搜索节点的队列,确定代价函数G(n)、H(n)的启发方式(代价函数就是使用起点到终点的两点欧式距离公式),先计算起点的启发值H,并把起点push到open_list【准备好才是进行搜索的阶段】
【下面进行A*搜索的阶段–循环实现】
步骤(1)如果open_list的队列不是空的,就继续进行路径探索(如果open_list的队列为空,证明构型空间内的节点都遍历过一次了,没有必要在继续遍历了)
步骤(2)从Open_list中找出总代价值f(n)【f(n) = g(n) + h(n)】最低的元素(一般就是先从起点开始),如果节点已扩展,则从open_list中移除,处理下一个节点,如果节点没有进行扩展,这进行节点扩展(创建可能的下一个扩展节点的代码与原理下面给出了)
步骤(3)若当前节点为目标点,计算返回当前点的G代价值g(m)
步骤(4)若当前节点不是目标点,则根据前向集成节点中的状态,从可能的方向寻找下一个有可能的扩展点,更新计算当前节点的所有临近节点m的代价值g(m)与代价值h(m)【g(m)值记录从起点到该节点真实的代价值,h(m)值是从起点到下一个扩展点的启发代价值】【防盗标记–盒子君hzj】
步骤(1)(2)(3)(4)不断迭代进行搜索,直到open_list被前部遍历完成或者提前找到了目标点,此时地图中的节点就有了对应从起点到该节点的代价g(m)值(g(m) = g(n)+Cnm),回溯所有代价最小的g(m)值就可以得到A*算法的探索路径
注意:
1、a*算法经过遍历节点搜索后,每个节点都会带有真实代价值g(n)和启发代价值h(n),但是我们最后用的是从起点到每个节点的真实代价值g(m)来从搜索树中选择最优的路径
2、真实代价值g()用于记录并回溯探索出来的路径,启发式代价值h()用于确定路径探索的方向
3、上述A*算法步骤除了步骤(2)中的从Open_list中找出总代价值f(n)【f(n) = g(n) + h(n)】最低的元素之外,其他步骤都与Dijksta算法一致
4、与A*算法类似,算法也是维护两个列表,一个open list, 一个是closed list。算法的结束条件是:open list为空或者已经搜索到终点。
5、算法不一定会准确搜索到终点,因此引入RoundState函数,在判断当前节点是否到达终点之前对此进行估算。如果没有达到终点,算法会通过执行动作空间中的所有动作对路径节点进行扩张。
更新真实的代价G值cost-so-far的思想:
如果生成的节点不在closed list中(也就是没有被算法遍历过),则直接计算代价G值cost-so-far
如果生成的节点不在open list中(已被遍历过)或者所得到的代价G值cost-so-far小于当前节点已有的代价G值,这时用当前得到的较小的cost更新cost-so-far
所涉及到的主要数据结构

(1)open_list:要找到一张图中两点之间的path,我们需要一个最基本的graph数据结构。在本文中,我们只需要得到某一点的邻近点,在这里我们的代码调用graph.neighbors(current),该函数返回点current周围的所有邻近点构成的一个列表,由for循环可以遍历这个列表。
(2)queue队列 :假设此时frontier为空,current当前是A点,它的neighbors将返回B、C、D、E四个点,在将这4个点都添加到frontier当中以后,下一轮while循环,frontier.get()将返回B点(根据FIFO原则,B点最早入队,应当最早出队),此时调用neighbors,返回A、f、g、h四个点,除了A点,其他3个点又被添加到frontier当中去。再到下一轮循环,此时frontier当中有C、D、f、g、h这几个点,由于队列的FIFO原则,frontier.get()将返回C点。这样就保证了整个扩散过程是由近到远,由内而外的,这也是广度优先搜索的原则。可以看到,frontier.get()从队列中取出一个元素(该元素将从队列中被删除)。而frontier.put()将current的邻近点又添加进去,整个过程不断重复,直到图中的所有点都被遍历一遍。
(3)close_list:graph.neighbors(A)将返回B、C、D、E 4个点,随后这4个点被添加到frontier当中,下一轮graph.neighbors(B)将返回A、h、f、g四个点,而加入此时A再被添加到frontier当中就导致遍历陷入死循环,为了避免这种状况出现,我们需要将已经遍历过了的点添加到visited列表当中,之后在将点放入frontier之前,首先判断该点是否已经在visited列表当中。
.
.
(1)A*算法搜索的流程代码
//###################################################
// (二维的路径探索)2D A*算法
//原始A*算法,用来搜索计算(带障碍的完整启发式G)
//返回在现在位置start到goal的H代价值cost-so-far[nSucc->updateH(goal)]
//核心思想:
//A*算法的具体运行原理是从机器人的运动起始点作为初始点,
//以此搜索周围的八个节点,然后运用代价函数计算八个节点的最低代价值G\H的点作为下个运行节点,
//之后以此循环过程直至到达终止点(或者是遍历完成open_list)
//###################################################
float aStar(Node2D& start, //规划起点
Node2D& goal, //规划目标点
Node2D* nodes2D, //表示R^2中配置空间C的2D节点数组
int width, //地图宽度(以单元格为单位)
int height, //地图高度
CollisionDetection& configurationSpace, //配置的查找表及空间占据计数
Visualize& visualization) { //可视化对象将搜索发布到RViz
//1)定义现在的节点和下一个扩展节点
int iPred, iSucc;
float newG;
//2)nodes2D节点数组重置
for (int i = 0; i < width * height; ++i) {
nodes2D[i].reset();
}
//3)设置可视化延迟时间
ros::Duration d(0.001);
//4)定义Open_list, 注意是一个heap堆栈
boost::heap::binomial_heap<Node2D*,
boost::heap::compare<CompareNodes>> O;
//5)A*计算起点的H代价值,就是当前点到目标点的欧式距离
start.updateH(goal);
//6)把起点push到open_list中
start.open();
O.push(&start);
iPred = start.setIdx(width);
nodes2D[iPred] = start;
//7)定义当前节点指针、下一个扩展节点的指针
Node2D* nPred;
Node2D* nSucc;
//8)【核心】开始进行路径探索,遍历open_list,直到把open_list 的节点全部push到close_list中
while (!O.empty()) {
//(0)从Open_list中找出代价最低的元素,并设置相应的index
nPred = O.top();
iPred = nPred->setIdx(width);
// (1)如果节点已扩展,则从open_list中移除,处理下一个
if (nodes2D[iPred].isClosed()) {
O.pop();
continue;
}
// (2)如果节点没有进行扩展,这进行扩展
else if (nodes2D[iPred].isOpen()) {
nodes2D[iPred].close(); //节点标记为close
nodes2D[iPred].discover(); //节点标记为discover
O.pop(); //把该节点从open list移除
// 1、RViz 可视化
if (Constants::visualization2D) {
visualization.publishNode2DPoses(*nPred);
visualization.publishNode2DPose(*nPred);
// d.sleep();
}
// 2、若当前节点为目标点,计算返回当前点的G代价值
if (*nPred == goal) {
return nPred->getG();//返回当前点的G代价值
}
// 3、若当前节点不是目标点,则从可能的方向寻找下一个有可能的扩展点
else {
for (int i = 0; i < Node2D::dir; i++) {//A*算法是8个方向:4个正方向和4个45度的方向,覆盖360度(这个不考虑动力学)
// 1)在指定遍历的方向下,创建可能的下一个扩展节点
nSucc = nPred->createSuccessor(i);
iSucc = nSucc->setIdx(width); // 设置扩展节点在地图的索引idx
// 2)约束性检查:在有效网格范围内、且不是障碍、没有扩展过,否则删除这个扩展节点(hybrid A*这里会有运动学约束)
if (nSucc->isOnGrid(width, height) && configurationSpace.isTraversable(nSucc) && !nodes2D[iSucc].isClosed()) {
//更新G代价值,G代价值代价就是上一个节点到目标点的距离
nSucc->updateG();
newG = nSucc->getG();
// 如果子节点并在open集中,或者它的G值(cost-so-far)比之前要小,则为可行的方向,,否则删除这个扩展节点
if (!nodes2D[iSucc].isOpen() || newG < nodes2D[iSucc].getG()) {
//计算H代价值,H代价值就是当前点到目标点的欧式距离
nSucc->updateH(goal);
//将该点移到open set中
nSucc->open();
nodes2D[iSucc] = *nSucc;
O.push(&nodes2D[iSucc]);
delete nSucc;
} else { delete nSucc; }
} else { delete nSucc; }
}
}
}
}
//9)返回一个大的代价值以引导搜索(代价值这么大是不会选择的),正常不会进来这里,正常会搜到一个目标点,
return 1000;
}
(2)创建可能的下一个扩展节点方法
//###################################################
// CREATE SUCCESSOR
//函数功能:创建下一个扩展的节点
//实现原理:
//在该节点位置(x,y)的基础上,加一个增量(x+dx,y+dy)
//###################################################
Node2D* Node2D::createSuccessor(const int i) {
int xSucc = x + Node2D::dx[i];
int ySucc = y + Node2D::dy[i];
return new Node2D(xSucc, ySucc, g, 0, this);
}
(3)计算当前节点的代价G值与启发代价H值(欧式距离)
// UPDATE METHODS
// 更新G的值(当前节点的代价),并将其设置为已discovered
void updateG() { g += movementCost(*pred); d = true; }
//更新启发值,即离目标的代价
void updateH(const Node2D& goal) { h = movementCost(goal); }
// 行走代价,定义为欧式距离
// 这个是A*的代价计算方式,就是欧式距离公式,H代价值就是当前点到目标点的欧式距离,G值代价就是上一个节点到目标点的距离
float movementCost(const Node2D& pred) const { return sqrt((x - pred.x) * (x - pred.x) + (y - pred.y) * (y - pred.y)); }
(4)算法对比
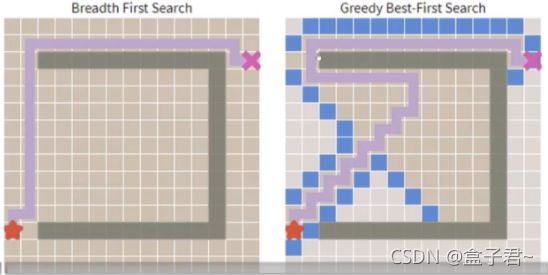
1.Greedy Best First Search和贪心算法对比
2.Greedy Best First Search 、A* 和Weighted A*的对比
这三类都是启发式算法,需要调参进行效果验证。
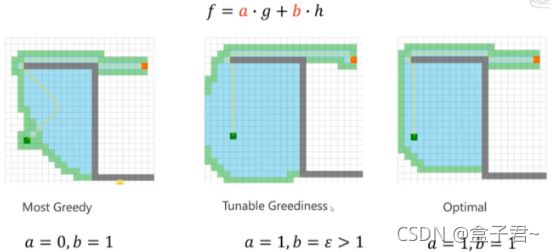
代价函数
(1)Greedy Best First Search: a = 0, b= 1
(2)Weighted A*: a= 1, b= > 1
(3)A*: a = 1, b= 1
3.Dijkstra算法和A*算法的对比
(1)伪代码对比
1.Dijkstra算法在所有方向上进行搜索扩展

(2)搜索方向对比
(1)Dijkstra算法在所有方向上进行搜索扩展

(2)A*算法向者目标的方向进行搜索扩展,但是不能很好的躲避连续性的障碍物

(3)整体效果对比
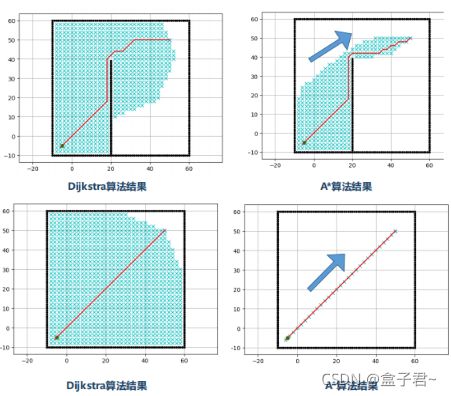
.
.
(4)完备性对比
Dijksta算法与A算法相比,Dijksta算法的搜索具有完备性,效果也比A效果相对要好,就是相对耗算力,做了更多无意义的盲目探索,要效果还是要算力平衡一下选择用Dijksta、还是A*吧
.
.
4.Dijksta算法、A算法、hybrid A算法/kinodynamic A*算法的open_list创建方式对比
(1)open_list的创建是围绕当前节点的邻居节点集合,关键就是怎么理解邻居节点这个概念了,如Dijksta、A算法的邻居节点就是当前节点一圈的八个节点(九宫格来看)、hybrid A算法/kinodynamic A*算法是考虑运动学的,这种算法的邻居节点是基于运动学推演的,一般是车前方的3~6个节点【防盗标记–盒子君hzj】
下图是我简单手撕的三种算法的open_list遍历范围图例,原理对应上面
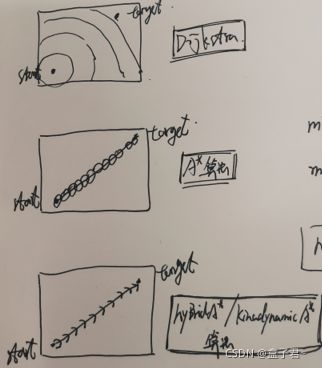
(5)总结
1.启发式作用
启发法是一个提高复杂问题解决效率的实用策略,【防盗标记–盒子君hzj】它引导程序沿着一条最可能的路径到达解,忽略最没有希望的路径,能避免去检查死角,只使用已搜集的数据
2.启发式的图搜索算法优点
(1)通过代价的方式决定接下来扩展的节点,而不是严格按照广度优先或深度优先的方式进行扩展
(2)在生成节点的过程中,决定哪个节点是后继节点,以及待生成的后继节点,而不是一次性生成所有可能的节点
(3)确定某些节点应该从搜索树中丢弃(或裁剪掉)
3.启发式的图搜索算法缺点
(1)几何复杂性不够,对显示场景可能不太够用,【防盗标记–盒子君hzj】毕竟是用质点模型去处理的
(2)空间维度不够,把无人车看成一个点,但是车辆模型从控制的角度上角不能看成一个质点,无人车是一个刚体,一个质点能过去不代表一个刚体能够过去的
(6)参考资料
基于图搜索的规划算法汇总
https://blog.csdn.net/Travis_X/article/details/112916637
.
3.jump point search(JPS)跳点搜索算法
(1)核心思想


JPS算法是A*算法的进阶,JPS很智能地探索,因为它总是基于一个规则向前看。JPS解决了搜索的效率的问题,Jump Point Search跳点搜索也有人称之为“拐点寻路”,JPS算法根据当前节点的方向、基于搜索跳点的策略来扩展后继节点,遵循“两个定义、三个规则”(两个定义确定强迫邻居、跳点,三个规则确定节点)的拓展策略。
Jps搜索下一个节点加入到open_list的方法是直接通过横、纵、对角线三个方向从占据栅格地图中找到击中障碍物的“跳变点”,然后把跳变点直接加入到open_list,在open_list中使用占据代价和启发式代价选择代价最小的节点
上述方法与A算法不同的是,A算法会把临近的八个节点都加入open_list,列表的操作复杂度比较高
定义一,强迫邻居(forced neighbour)
如果节点n是x的邻居,并且节点n的邻居有阻挡(不可行走的格子),并且从parent(x)、x、n的路径长度比其他任何从parent(x)到n且不经过x的路径短,其中parent(x)为路径中x的前一个点,则n为x的强迫邻居,x为n的跳点
定义二,跳点(jump point)
(1)如果点y是起点或目标点,则y是跳点
(2)如果y有强迫邻居则y是跳点, 例如I是跳点,请注意此类跳点和强迫邻居是伴生关系,从定义一强迫邻居的定义来看n是强迫邻居,x是跳点,
(3)如果parent(y)到y是对角线移动,并且y经过水平或垂直方向移动可以到达跳点,则y是跳点
规则一
JPS搜索跳点的过程中,如果直线方向(为了和对角线区分,直线方向代表水平方向和垂直方向,且不包括对角线等斜线方向,下文所说的直线均为水平方向和垂直方向)
对角线方向都可以移动,则首先在直线方向搜索跳点,再在对角线方向搜索跳点。
规则二
(1)如果从parent(x)到x是直线移动,n是x的邻居,若有从parent(x)到n的路径不经过x且路径长度小于或等于从parent(x)经过x到n的路径,则走到x后下一个点不会走到n;
(2)如果从parent(x)到x是对角线移动,n是x的邻居,若有从parent(x)到n的路径不经过x且路径长度小于从parent(x)经过x到n的路径,则走到x后下一个点不会走到n(相关证明见论文)。
规则三
只有跳点才会加入openset,因为跳点会改变行走方向,而非跳点不会改变行走方向,最后寻找出来的路径点也都是跳点。
.
.
(2)算法过程
中文版解释横向纵向的格子的单位消耗为10,对角单位消耗为14。
定义一个OpenList,用于存储和搜索当前最小值的格子。
定义一个CloseList,用于标记已经处理过的格子,以防止重复搜索。
def 获取邻居点
if 当前点是起点
返回当前点九宫格内的非障碍点
elseif 当前点与父节点是对角向
判断并添加相对位置右方的邻居点
判断并添加相对位置下方的邻居点
判断并添加相对位置对角的邻居点
判断并添加相对位置左下角的强迫邻居
判断并添加相对位置左上角的强迫邻居
elseif 当前点与其父节点是横向
判断并添加相对位置右方的邻居点
判断并添加相对位置上方的强迫邻居
判断并添加相对位置下方的强迫邻居
elseif 当前点与父节点是纵向
同横向逻辑,判断并处理下方,左右向强迫邻居
def 递归寻找跳跃点
if 传入点是终点
返回终点
if 传入朝向是对角向
if 传入点存在强迫邻居
返回此传入点
if (递归寻找跳跃点 传入点:横向+1 朝向:横向)结果不为空
返回此传入点
if (递归寻找跳跃点 传入点:纵向+1 朝向:纵向)结果不为空
返回此传入点
elseif 横向
if 上下方有强迫邻居
返回此传入点
elseif 纵向
if 左右方有强迫邻居
返回此传入点
返回 递归寻找跳跃点 传入点:横向+1,纵向+1 朝向 对角
def Main
起点加进OpenList中
While(OpenList.Count > 0):
从OpenList中取出F值最小的点并设置为当前点
把当前点加进CloseList
邻居点s = 获取邻居点(当前点)
for 邻居点s
跳跃点 = 递归寻找跳跃点(邻居点)
if 跳跃点不再CloseList中
计算并设置当前点与跳跃点的G值
计算并设置当前点与跳跃点的H值
计算并设置跳跃点的F值
将当前点设置为跳跃点的父节点
如果邻居点在OpenList中
计算当前值的G与该邻居点的G值
如果G值比该邻居点的G值小
将当前点设置为该邻居点的父节点
更新该邻居点的GF值
若不在
计算并设置当前点与该邻居点的G值
计算并设置当前点与该邻居点的H值
计算并设置该邻居点的F值
将当前点设置为该邻居点的父节
获取邻居点
public List<Point> GetNeighbors(Point point)
{
var points = new List<Point>();
Point parent = point.ParentPoint;
if (parent == null)
{
//获取此点的邻居
//起点则parent点为null,遍历邻居非障碍点加入。
for (int x = -1; x <= 1; x++)
{
for (int y = -1; y <= 1; y++)
{
if (x == 0 && y == 0)
continue;
if (IsWalkable(x + point.X, y + point.Y))
{
points.Add(new Point(x + point.X, y + point.Y));
}
}
}
return points;
}
//非起点邻居点判断
int xDirection = Mathf.Clamp(point.X - parent.X, -1, 1);
int yDirection = Mathf.Clamp(point.Y - parent.Y, -1, 1);
if (xDirection != 0 && yDirection != 0)
{
//对角方向
bool neighbourForward =IsWalkable(point.X, point.Y + yDirection);
bool neighbourRight =IsWalkable(point.X + xDirection, point.Y);
bool neighbourLeft =IsWalkable(point.X - xDirection, point.Y);
bool neighbourBack =IsWalkable(point.X, point.Y - yDirection);
if (neighbourForward)
{
points.Add(new Point(point.X, point.Y + yDirection));
}
if (neighbourRight)
{
points.Add(new Point(point.X + xDirection, point.Y));
}
if ((neighbourForward || neighbourRight) && IsWalkable(point.X + xDirection, point.Y + yDirection))
{
points.Add(new Point(point.X + xDirection, point.Y + yDirection));
}
//强迫邻居的处理
if (!neighbourLeft && neighbourForward)
{
if (IsWalkable(point.X - xDirection, point.Y + yDirection))
{
points.Add(new Point(point.X - xDirection, point.Y + yDirection));
}
}
if (!neighbourBack && neighbourRight)
{
if (IsWalkable(point.X + xDirection, point.Y - yDirection))
{
points.Add(new Point(point.X + xDirection, point.Y - yDirection));
}
}
}
else
{
if (xDirection == 0)
{
//纵向
if (IsWalkable(point.X, point.Y + yDirection))
{
points.Add(new Point(point.X, point.Y + yDirection));
//强迫邻居
if (!IsWalkable(point.X + 1, point.Y) &&IsWalkable(point.X + 1, point.Y + yDirection))
{
points.Add(new Point(point.X + 1, point.Y + yDirection));
}
if (!IsWalkable(point.X - 1, point.Y) &&IsWalkable(point.X - 1, point.Y + yDirection))
{
points.Add(new Point(point.X - 1, point.Y + yDirection));
}
}
}
else
{
//横向
if (IsWalkable(point.X + xDirection, point.Y))
{
points.Add(new Point(point.X, point.Y + yDirection));
//强迫邻居
if (!IsWalkable(point.X, point.Y + 1) &&IsWalkable(point.X + xDirection, point.Y + 1))
{
points.Add(new Point(point.X + xDirection, point.Y + 1));
}
if (!IsWalkable(point.X, point.Y - 1) &&IsWalkable(point.X + xDirection, point.Y - 1))
{
points.Add(new Point(point.X + xDirection, point.Y - 1));
}
}
}
}
return points;
}
递归跳跃
private Point Jump(int curPosx, int curPosY, int xDirection, int yDirection, int depth, Point end)
{
if (!IsWalkable(curPosx, curPosY))
return null;
CallSearch(curPosx, curPosY);
//递归最大深度 || 搜索到终点
if (depth == 0 || (end.X == curPosx && end.Y == curPosY))
return new Point(curPosx, curPosY);
//对角向
if (xDirection != 0 && yDirection != 0)
{
if ((IsWalkable(curPosx + xDirection, curPosY - yDirection) && !IsWalkable(curPosx, curPosY - yDirection)) || (IsWalkable(curPosx - xDirection, curPosY + yDirection) && !IsWalkable(curPosx - xDirection, curPosY)))
{
return new Point(curPosx, curPosY);
}
//横向递归寻找强迫邻居
if (Jump(curPosx + xDirection, curPosY, xDirection, 0, depth - 1, end) != null)
{
return new Point(curPosx, curPosY);
}
//纵向向递归寻找强迫邻居
if (Jump(curPosx, curPosY + yDirection, 0, yDirection, depth - 1, end) != null)
{
return new Point(curPosx, curPosY);
}
}
else if (xDirection != 0)
{
//横向
if ((IsWalkable(curPosx + xDirection, curPosY + 1) && !IsWalkable(curPosx, curPosY + 1)) || (IsWalkable(curPosx + xDirection, curPosY - 1) && !IsWalkable(curPosx, curPosY - 1)))
{
return new Point(curPosx, curPosY);
}
}
else if (yDirection != 0)
{
//纵向
if ((IsWalkable(curPosx + 1, curPosY + yDirection) && !IsWalkable(curPosx + 1, curPosY)) || (IsWalkable(curPosx - 1, curPosY + yDirection) && !IsWalkable(curPosx - 1, curPosY)))
{
return new Point(curPosx, curPosY);
}
}
return Jump(curPosx + xDirection, curPosY + yDirection, xDirection, yDirection, depth - 1, end);
}
计算G,H代价值
protected int CalcG(Point start, Point point)
{
int distX = Math.Abs(point.X - start.X);
int distY = Math.Abs(point.Y - start.Y);
int G = 0;
if (distX > distY)
G = 14 * distY + 10 * (distX - distY);
else
G = 14 * distX + 10 * (distY - distX);
int parentG = point.ParentPoint != null ? point.ParentPoint.G : 0;
return G + parentG;
}
protected int CalcH(Point end, Point point)
{
int step = Math.Abs(point.X - end.X) + Math.Abs(point.Y - end.Y);
return step * 10;
}
(3)Astar和JPS算法的流程对比
不同于A算法中直接获取当前节点的所有非关闭的可达邻居节点来进行拓展的策略,JPS算法根据当前节点的方向、基于搜索跳点的策略来扩展后继节点,遵循“两个定义、三个规则”(两个定义确定强迫邻居、跳点,三个规则确定节点)的拓展策略。
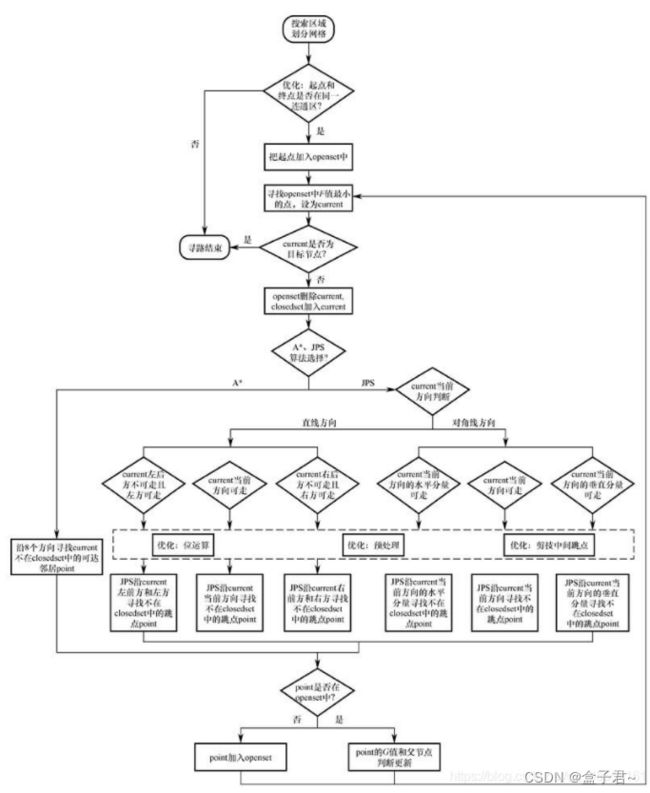
JSP算法了流程, JPS算法流程如下
(1)若current当前方向是直线方向:
① 如果current左后方不可走且左方可走(即左方是强迫邻居),则沿current左前方和左方寻找不在closedset中的跳点。
② 如果current当前方向可走,则沿current当前方向寻找不在closedset中的跳点。
③ 如果current右后方不可走且右方可走(右方是强迫邻居),则沿current右前方和右方寻找不在closedset中的跳点。
(2)若current当前方向为对角线方向:
① 如果current当前方向的水平分量可走(例如,current当前方向为东北方向,则水平分量为东,垂直分量为北),则沿current当前方向的水平分量寻找不在closedset中的跳点。
② 如果current当前方向可走,则沿current当前方向寻找不在closedset中的跳点。
③ 如果current当前方向的垂直分量可走,则沿current当前方向的垂直分量寻找不在closedset中的跳点。
。
(4)JPS在A*的基础上进行改进的点
JPS保留了一些A星的算法模型,Jps在A Star算法模型的基础之上,优化了搜索后继节点的操作。A星的处理是把周边能搜索到的格子,加进OpenList,然后在OpenList中弹出最小值……。JPS也是这样的操作,但相对于A星来说,JPS操作OpenList的次数很少,它会先用一种更高效的方法来搜索需要加进OpenList的点,然后在OpenList中弹出最小值……

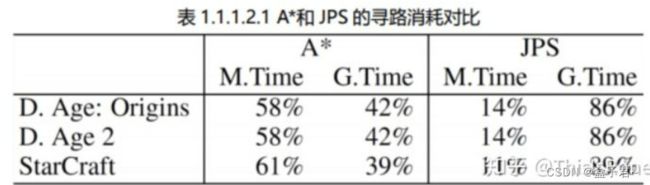
M.Time 表示操作 openset 和 closedset 的时间
G.Time 表示搜索后继节点的时间
A*大约有 58%的时间在操作 openset 和 closedset,42%时间在搜索后继节点
JPS 大约 14%时间在操作 openset 和 closedset,86%时间在搜索后继节点
(5)JPS算法与A*算法的效果对比
JPS算法搜索出来的路径更多的是折线的形式(因为节点扩展只有横、纵、对角线三个方向),而A*算法搜索出来的路径更多的是贴合障碍物边缘的路径形式
JPS算法里只有跳点才会被加入openlist里,排除了大量不必要的点,最后找出来的最短路径也是由跳点组成。这也是 JPS/JPS+ 高效的主要原因。
JPS算法不仅会标记撞到障碍物的跳点作为节点,逃离障碍物的跳点也是节点,在横纵方向能击中目标点的也是节点
A* 会遍历每一个附近的点,然后把符合要求的放到openset列表中,但是 JSP算法 通过一些规则,设置跳点(类似于方向相同,规律相近的点都用跳点表示)的方式,减少需要放入openset列表中的点.减少遍历,减少 需要维护的数据.
所以数据上JPS会比A* 快很多 . 但是 由于 一部分点都用一个点来表示 . 路径表现上 会感觉出寻路出的点 并不是最优路径.
总结
(1)优点
在A的优点上,规划的路线更加笔直,【防盗标记–盒子君hzj】不会像A一样拐来拐去,实现框架和A*是很像的
(2)缺点
JPS仅仅能用在固定的栅格地图中
.
参考资料
高飞在深蓝学院上有开课具体的讲,可以看看,demo在github也有很多
https://github.com/KumarRobotics/jps3d
https://github.com/eborghi10/jps_global_planner
参考论文
github Harabor, Daniel Damir, and Alban Grastien. “Online Graph Pruning for Pathfinding On Grid Maps.” AAAI. 2011
Planning Dynamically Feasible Trajectories for Quadrotors using Safe Flight Corridors in 3-D Complex Environments, Sikang Liu, RAL 2017
源码工程demo
https://github.com/KumarRobotics/jps3d
效果验证平台
http://xiexuefeng.cc/lab/369.html
下面这个更好一些
http://qiao.github.io/PathFinding.js/visual/
.
4.hybird A*算法
(1)hybird A*算法应用场景
(1)考虑优化与车的动力学问题的两点间路径探索,根据车起始点的位置和朝向,行驶到指定的终止点和朝向
(2)自动泊车
高飞的无人机路径探索,autoware无人驾驶都有案例

hybird A算法的输入输出(把hybird A算法看成一个小黑盒)
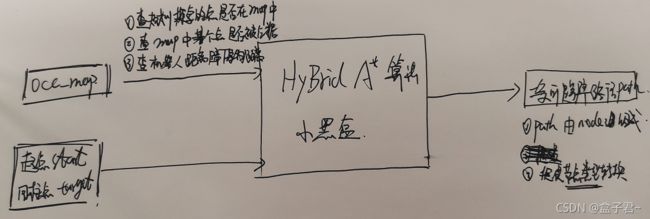
.
(2)hybird A*算法算法原理步骤
1.stage 1:在连续坐标系下进行启发式搜索(使用改进的启发式搜索A*算法)
目的:高效的寻找出一条较好的可通行路径
.
(1)hybrid A* 和A*的相同点
两种算法都是基于世界网格的(grid world)
.
(2)hybrid A在A基础上改进的点
(1)hybrid A*满足车辆非完整性约束(作用于节点采样【控制状态采样方式】)
(车辆的微分/运动学约束)
1、车辆的非完整性约束条件为:【先给出结论】
![]()
hybrid A*探索出来的的轨迹满足上述约束
.
.
2、车辆的非完整性约束(车辆的微分/运动学约束)条件的推导如下:
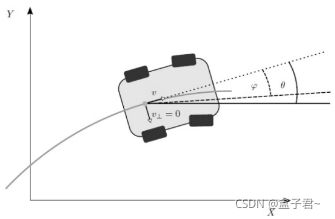
假设车辆基本的构型空间是![]()
假设车辆的速度是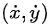
但在实际行驶中,车辆不能直接向左向右平移,【防盗标记–盒子君hzj】也就是说垂直于车辆heading方向的速度为0,将下图中的v分解到XY坐标下可以得到:
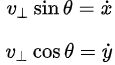
两者联立可以得到:
![]()
最终可以得到车辆的非完整性约束条件为:
![]()
.
.
(2)hybrid A*是在连续坐标系下使用进行节点连接(作用于节点连接过程)
A* 是赋予每个网格的中心点相应的损失并且算法只访问这些中心点,而hybrid A* 是先在这些网格中挑选满足车辆3D连续状态的点,并将损失赋值给这些点。

传统的A算法是用直线进行连接的,但是hybrid A算法可以用加速过程的dubins曲线和RS曲线进行节点连接,因为节点是位于网格grid中心的,这里没有用到节点探索,用的是曲线拟合的方式进行路径探索,自然就得到连续的曲线了,对比如上图所示
.
.
(3)hybrid A*启发函数的选取不同(作用于节点启发式扩张过程)
启发函数计算到目标的启发值(cost_H)【提供方向】
传统的A* 算法的启发函数一般是2D欧几里得距离,而hybrid A* 算法构造了两个启发函数(Constrained heuristics、Unconstrained heuristics)
由于启发函数的选取不同,运行算法后节点扩张(expansion)的效率也就不同(目的是希望算法在遍历最少的节点的情况下找到最优路径)
.Heuristic design想要解决的问题
(a) 二维欧式距离
(b)考虑车辆模型,运动学(不能够侧滑)
(c)走入死胡同
(d)考虑障碍物,在2D地图上找最短路径.
1)启发函数一:Constrained heuristics 【忽略了环境中的障碍物等信息,只考虑车辆的运动学特性】
该启发函数忽略了环境中的障碍物等信息,只考虑车辆的运动学特性,从终止点开始,计算从该点到其他点的最短路径。
(优点是相比直接用欧几里得距离损失要好一个数量级)【防盗标记–盒子君hzj】
启发函数具体的返回值是:
![]()
其中:non-holonomic-no-obstacles-cost是dubins曲线的代价

.
.
2)启发函数二:Unconstrained heuristics【忽略车辆的动力学约束条件,只考虑欧式距离场障碍物信息】(与传统的A*算法很像)
与第一个启发函数的对偶,【防盗标记–盒子君hzj】只考虑障碍物信息而不考虑车辆的非完整性约束条件(优点是引入该启发函数后能够发现2D空间中所有的U形障碍物和死胡同dead end)。随后使用2D动态规划的方法(其实就是传统的2D A* 算法)计算每个节点到终点的最短路径。

注意
启发式函数有两种,但是Unconstrained heuristics是一定会启用的(保证安全避障),constrained heuristics是选择性启用
算法使用的代价函数就是两种启发函数的最大值
.
.
.
.
(3)路径节点探索的过程【重要】
这个是大概的过程,自己画的,我也觉得丑,不喜勿喷~~


先进行完成stage 1阶段 ,再进行stage 2阶段
.
(1)【节点控制采样】结合离散状态空间+离散控制空间的采样的过程
采样的时候要符合车辆的运动学约束


(2)【节点连接】节点连接的过程
A是用直线相连接;hybrid a是用直线或圆弧连接–Reed-Shepp曲线,RS曲线计算的更快,用于加速计算过程
hybrid A* 的搜索过程则是使用三种控制动作:【防盗标记–盒子君hzj】
1、最大左转
2、最大右转
3、不转向
来生成路径
因此该路径是一些受车辆转弯半径约束的圆弧和直线,为了进一步改进搜索速度和提高准确度,这就可以利用Reed-Shepp曲线

可以看出与直线相比,Reed-Shepp曲线的计算量是很大的。所以论文中作者使用简单的selection rule,在每N个节点中选取一个计算Reed-Shepp曲线(这里的N随启发函数递减而减少,即越发靠近终点时,N越小)。
两种算法节点连接的过程对比图例

(3)【节点启发式扩张】生成子节点搜索的过程
(1)第一步:假设不考虑环境(对应第一个启发函数)【防盗标记–盒子君hzj】,算法会通过计算从起点到终点的最优Reed-Shepp曲线的方式,再生成一个额外的子节点;
(2)第二步:算法基于现有的障碍物地图对该路径进行碰撞检测,无碰撞路径对应的点会加到扩张树中。

.
.
2.stage 2:对路径进行优化的后处理(代价函数+梯度下降)
(1)对路径进行优化的后处理目的
在上一步子节点扩张的过程中,路径会有一些额外的不必要控制动作(即steering),所以算法的第二个部分就是对生成点曲线进行平滑处理。,轨迹优化后让汽车可以进行跟随路径
.
(2)后处理步骤一:采用目标函数的设计进行轨迹优化
1)优化的目标
1、路径长度或代价应该是接近最优的;
2、路径必须是光滑的
3、生成的路径必须与障碍物保持一定的距离
注意:对生成路径的要求太多,会造成优化难度增加
.
.
2)目标函数设计方法
1、曲率项
(1)目的:对路径的每个节点的瞬时曲率变化设置一个上限【防盗标记–盒子君hzj】
(2)代价函数公式:
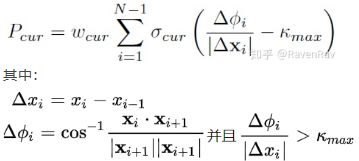
(3)代价函数的效果:瞬时曲率变化过大,代价就很高
2、光滑度项smoothness项
(1)目的:将代价值赋给非均匀分布和方向变化的节点,【防盗标记–盒子君hzj】以保证路径的平滑性
(2)代价函数公式:
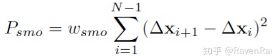
光滑度项计算每个节点之间位移向量的差值的平方
3、代价地图障碍物项
(1)目的:惩罚与障碍物的碰撞
(2)代价函数公式

(3)代价函数的效果
从公式可以看出,节点靠近障碍物的时候,第一项【防盗标记–盒子君hzj】![]() 的值会增大。即靠近节点靠近障碍物的时候,代价值会变大
的值会增大。即靠近节点靠近障碍物的时候,代价值会变大
4、Voronoi图避障项(源码实际上好像没有用到这一项)
(1)目的:使用voronoi场之后车辆也能很好地通过狭窄路段,使路径远离障碍物
(2)代价函数公式(构造voronoi图)
voronoi 场表明到最近的 voronoi 边缘和最近的障碍物的距离。【防盗标记–盒子君hzj】要创建 voronoi 场,您首先需要创建一个 voronoi 图,它告诉最近障碍物的距离(边界也是障碍物)
通过下面三项连乘即可构造Voronoi势场函数

voronoi场的值随着导航中所有可行空间的大小成比例缩放。公式中分别代表路径节点到最近的障碍物和最近的GVD(广义voronoi图)的长度,控制场的衰减率(Falloff Rate)

Voronoi图是在收到栅格地图的回调函数处理生成的,Voronoi图就是根据栅格地图障碍物代价生成的一系列原理障碍物的蓝色点路径,蓝色点路径和之前路径探索得到的路径是不完全吻合和,【防盗标记–盒子君hzj】使用蓝色点路径优化原有路径可以实现车辆也能很好地通过狭窄路段,使路径远离障碍物
(3)后处理步骤二:采用梯度下降方法进行轨迹优化
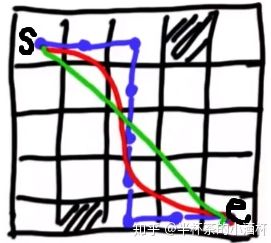
–s表示运动规划的起点,e表示运动规划终点
–斜线填充的网格表示障碍物位置
–蓝色的线为运动规划算法规划出的路线,曲折不平
–红色为平滑后的运动曲线,对车辆的实际行驶比较友好
理论过程
–(1)假设运动规划的结果点序列为
![]()
–(2)假设平滑后的运动规划的点序列:
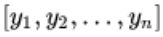
–(3)定义如下的平滑Cost函数:
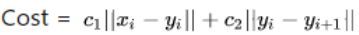
其中第一项用于衡量平滑后的点偏离原始点的程度;第二项用于衡量平滑点之间的距离;这两个Cost项相互制衡,平滑的过程就是最小化Cost的过程。其中c1与c2是对目标路线平滑程度的参数,【防盗标记–盒子君hzj】c1相对于 c2越大,平滑后的点就越接近于原始点,反之,路线就越平滑。
–(4)采用梯度下降法(gradient descent)求解cost的最小值
–起始值:
![]()
–迭代: 遍历除起点和终点外的所有点,更新yi: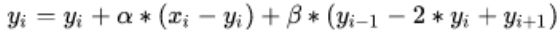
循环执行迭代过程直到达到迭代次数上限或者Cost Function梯度下降至指定阈值。
.
(3)hybird A*算法伪代码及代码流程
0.hybrid A*算法实现的流程
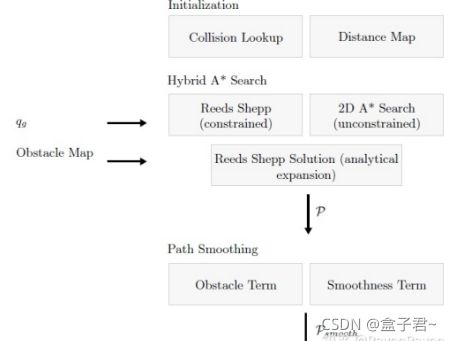
算法的输入为事先定义好的障碍物代价栅格地图,【防盗标记–盒子君hzj】经过hybrid A* 搜索和路径平滑之后在rviz中显示路径
【规划前提条件】:订阅从rviz中发布过来的起点start、目标点goal、同时订阅到map_server发布过来的静态/动态地图数据,同时满足三者才会启动hybrid A*规划进行路径探索
.
.
stage1 :路径探索
1.hybrid A* 算法伪代码
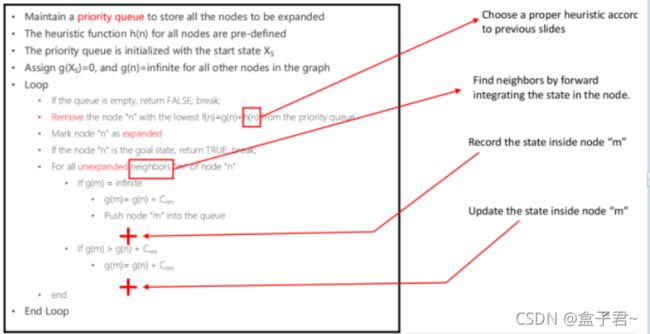
维护一个优先队列来存储所有要扩展的节点
•所有节点的启发式函数h(n)是预先定义的
•优先队列初始化为启动状态X S
•对图中所有其他节点赋值g(X S)=0, g(n)=infinite
•循环
理解open_list、close_list的创建方法(怎么把open_list的节点放到close_list的逻辑)
步骤一:BOOST库运行节点比较CompareNodes,并定义open_list(这里不知道有没有用到地图的数据,open_list的顺序应该是通过地图和机器人当前位置定义的吧)
步骤二:把刚刚启动机器人的起点start推进去open_list,并记录索引
步骤三:从open_list中取出一个总代价值最低的节点,并记录索引【防盗标记–盒子君hzj】
步骤四:检查该节点是否closed状态,如果为closed,说明该点已经处理过,忽略(将它从open_list中移除);如果为open,说明该点未处理过,则进行节点扩张,继续搜索
步骤五:把该节点放入close_list,同时把该节点从open_list中移除【这样open_list会越来越小,close_list会越来越大】【防盗标记–盒子君hzj】
把地图看成占据栅格地图就好【防盗标记–盒子君hzj】
.
.
2. hybrid A*的流程步骤实现源码【对应上面的步骤的】【节点扩张的过程】
hybrid A 算法代码流程解释*

步骤(0)初始化open_list搜索节点的队列,确定代价函数G(n)、H(n)的启发方式(代价函数就是使用起点到终点的两点欧式距离公式),先计算起点的启发值H(决定第一个点先往哪一个方向进行搜索),并把起点push到open_list【准备好才是进行搜索的阶段】
【下面进行A*搜索的阶段–循环实现】
步骤(1)如果open_list的队列不是空的,就继续进行路径探索(如果open_list的队列为空,证明构型空间内的节点都遍历过一次了,没有必要在继续遍历了)【防盗标记–盒子君hzj】
步骤(2)从Open_list中找出总代价值f(n)【f(n) = g(n) + h(n)】最低的元素(这里的h(n)是启发式代价值,A使用欧氏距离,hybrid A 会根据前面的节点选择合适的启发式函数(上面的两条启发式函数二选一) )(一般就是先从起点开始),如果节点已扩展,则从open_list中移除,处理下一个节点,如果节点没有进行扩展,这进行节点扩展(创建可能的下一个扩展节点的代码与原理下面给出了)【防盗标记–盒子君hzj】
步骤(3)若当前节点为目标点,计算返回当前点的G代价值g(m)
步骤(4)若当前节点不是目标点,则根据前向集成节点中的状态,从可能的方向寻找下一个有可能的扩展点,更新计算当前节点的所有临近节点m的代价值g(m)与代价值h(m)【g(m)值记录从起点到该节点真实的代价值,h(m)值是从起点到下一个扩展点的启发代价值】
步骤(1)(2)(3)(4)不断迭代进行搜索,直到open_list被前部遍历完成或者提前找到了目标点,此时地图中的节点就有了对应从起点到该节点的代价g(m)值(g(m) = g(n)+Cnm),回溯所有代价最小的g(m)值就可以得到A*算法的探索路径【防盗标记–盒子君hzj】
算法主要流程如上,但是hybrid A*还有一个用dubins曲线加速搜索的技巧,代码流程如下
在步骤三之后,加入一个是否可以用dubins曲线加速搜索的判断
步骤(4.5)若车子是在前进方向,优先考虑用Dubins去命中目标点,如果Dubins方法能直接命中目标点,即不需要进入Hybrid A*搜索了,直接返回结果
这时候使用的是dubins曲线的长度作为当前节点的代价值g(m)【防盗标记–盒子君hzj】
.
.
注意:
1、hybrid a*算法经过遍历节点搜索后,每个节点都会带有真实代价值g(n)和启发代价值h(n),但是我们最后用的是从起点到每个节点的真实代价值g(m)来从搜索树中选择最优的路径
2、真实代价值g()用于记录并回溯探索出来的路径,启发式代价值h()用于确定路径探索的方向【防盗标记–盒子君hzj】
3、上述hybrid A算法步骤除了步骤(2)中的从Open_list中找出总代价值f(n)【f(n) = g(n) + h(n)】最低的元素之外,其他步骤都与Dijksta、A算法都是一致的
4、与A*算法类似,算法也是维护两个列表,一个open list, 一个是closed list。算法的结束条件是:open list为空或者已经搜索到终点。
5、算法不一定会准确搜索到终点,因此引入RoundState函数,在判断当前节点是否到达终点之前对此进行估算。如果没有达到终点,算法会通过执行动作空间中的所有动作对路径节点进行扩张。【防盗标记–盒子君hzj】
更新真实的代价G值cost-so-far的思想:
如果生成的节点不在closed list中(也就是没有被算法遍历过),则直接计算代价G值cost-so-far
如果生成的节点不在open list中(已被遍历过)或者所得到的代价G值cost-so-far小于当前节点已有的代价G值,这时用当前得到的较小的cost更新cost-so-far
.
.
//###################################################
// [主要的入口] (三维的路径探索)3D A*
// Hybrid A* 的主调用函数
// 函数返回一个三维的路径点Node3D,返回满足目标条件的节点指针
//###################################################
Node3D* Algorithm::hybridAStar(Node3D& start, //规划起点
const Node3D& goal, //规划目标点
Node3D* nodes3D, //表示R^3中配置空间C的3D节点数组
Node2D* nodes2D, //表示R^2中配置空间C的2D节点数组
int width, //地图宽度(以单元格为单位)
int height, //地图高度
CollisionDetection& configurationSpace, //配置的查找表及空间占据计数
float* dubinsLookup, //解析解的查找(Dubin路径)
Visualize& visualization){ //可视化对象将搜索发布到RViz
//(1)定义相关变量
//定义前置索引和后继索引
int iPred, iSucc;
//定义新的目标点
float newG;
//定义车辆方向,3个用于向前行驶,另外3个用于倒车
int dir = Constants::reverse ? 6 : 3;//前进方向为6;否则为3
//定义迭代计数, 为了让算法停止
int iterations = 0;
//可视化延迟
ros::Duration d(0.003);
//(2)定义open_list,open集的数据结构是优先级队列,注意是一个heap堆栈
typedef boost::heap::binomial_heap<Node3D*,
boost::heap::compare<CompareNodes>
> priorityQueue;
priorityQueue O;//定义Open_list
//(3)计算起点到目标点的启发式值cost【核心】【提供规划方向和短暂路径】
updateH(start, goal, nodes2D, dubinsLookup, width, height, configurationSpace, visualization);
//(4)将全局起点start加入open_list
start.open();
O.push(&start);
//(5)设置规划的起点到nodes3D的idx
iPred = start.setIdx(width, height); //设置并获取三维网格中节点的索引
nodes3D[iPred] = start; //设置规划的起点
//(6)一直循环迭代,从open_list中寻找节点,直到open_list为空【open_list加入到close_list】(路径节点扩张搜索的过程)
//节点指针
Node3D* nPred;
Node3D* nSucc;
// float max = 0.f;
while (!O.empty()) {
// // DEBUG
{
// Node3D* pre = nullptr;
// Node3D* succ = nullptr;
// std::cout << "\t--->>>" << std::endl;
// for (priorityQueue::ordered_iterator it = O.ordered_begin(); it != O.ordered_end(); ++it) {
// succ = (*it);
// std::cout << "VAL"
// << " | C:" << succ->getC()
// << " | x:" << succ->getX()
// << " | y:" << succ->getY()
// << " | t:" << helper::toDeg(succ->getT())
// << " | i:" << succ->getIdx()
// << " | O:" << succ->isOpen()
// << " | pred:" << succ->getPred()
// << std::endl;
// if (pre != nullptr) {
// if (pre->getC() > succ->getC()) {
// std::cout << "PRE"
// << " | C:" << pre->getC()
// << " | x:" << pre->getX()
// << " | y:" << pre->getY()
// << " | t:" << helper::toDeg(pre->getT())
// << " | i:" << pre->getIdx()
// << " | O:" << pre->isOpen()
// << " | pred:" << pre->getPred()
// << std::endl;
// std::cout << "SCC"
// << " | C:" << succ->getC()
// << " | x:" << succ->getX()
// << " | y:" << succ->getY()
// << " | t:" << helper::toDeg(succ->getT())
// << " | i:" << succ->getIdx()
// << " | O:" << succ->isOpen()
// << " | pred:" << succ->getPred()
// << std::endl;
// if (pre->getC() - succ->getC() > max) {
// max = pre->getC() - succ->getC();
// }
// }
// }
// pre = succ;
// }
}
//(1)从open_list优先级队列中取出g(n)代价值最小的节点,并记录索引
nPred = O.top();
iPred = nPred->setIdx(width, height);//获取该点在nodes3D的索引 (前缀i表示index, n表示node)
//(2)记录迭代次数(控制迭代次数的)
iterations++;
//(3)RViz可视化
if (Constants::visualization) {
visualization.publishNode3DPoses(*nPred);
visualization.publishNode3DPose(*nPred);
d.sleep();//用这样的方式控制发布频率
}
//(4)检查该节点是否closed状态,如果为closed,说明该点已经处理过,忽略(将它从open_list中移除)
if (nodes3D[iPred].isClosed()) {
// 从“打开”列表中弹出节点,并从新节点开始
O.pop();
continue;
}
//(5)检查该节点是否open状态,如果为open,说明该点未处理过,则进行节点扩张,继续搜索(现在正在处理该节点了)
else if (nodes3D[iPred].isOpen()) {
//1)将节点添加到已close列表,即把它的状态标记为closed
nodes3D[iPred].close();
//2)从open set中移除节点
O.pop();
//3)检测当前节点是否是终点或者是否超出解算的最大时间(最大迭代次数),是的话直接返回路径,表示搜索结束;不是的话就继续搜索
if (*nPred == goal || iterations > Constants::iterations) {
// DEBUG
return nPred;
}
//4)继续搜索,直到找到目标点
else {
// _______________________
//(1)【核心】若车子是在前进方向,优先考虑用Dubins去命中目标点
if (Constants::dubinsShot && nPred->isInRange(goal) && nPred->getPrim() < 3) {
nSucc = dubinsShot(*nPred, goal, configurationSpace);//【核心】使用dubins曲线来探索路径
//如果Dubins方法能直接命中终点,即不需要进入Hybrid A*搜索了,直接返回结果【这个就是加速路径探索的过程了】
if (nSucc != nullptr && *nSucc == goal) {
//DEBUG
// std::cout << "max diff " << max << std::endl;
return nSucc;//如果下一步是目标点,可以返回了
}
}
// ______________________________
// (2)【核心】Dubins去命中目标点失败,根据控制状态采样,进行更广的前向搜索模拟,每个方向都搜索
for (int i = 0; i < dir; i++) {
//(1) 创建下一个扩展节点(基于控制量采样的下一个点Node3D)
// 这里有三种可能的运动方向(左转、右转、直行),如果可以倒车的话是6种运动方向
nSucc = nPred->createSuccessor(i);//返回基于控制量采样的下一个点Node3D,【这里通过dis方向进行控制采样,这里才是符合动力学的for遍历】
//(2)设置节点遍历地图标识
iSucc = nSucc->setIdx(width, height);//地图索引值
//(3)判断扩展节点是否满足地图可视范围与非碰撞约束,继续进行遍历节点
// 扩展条件核心原理:
// 首先判断产生的节点是否在范围内【nSucc->isOnGrid(width, height)判断节点是否在地图里面】;
// 其次判断产生的节点在配置空间会不会产生碰撞【configurationSpace.isTraversable(nSucc))】;
// 只有同时满足在可视范围内且不产生碰撞的节点才是合格的节点
//更新真实的代价G值、启发式代价H值的思想:
//如果生成的节点不在closed list中(也就是没有被算法遍历过),则直接计算代价G值cost-so-far**;
//如果生成的节点不在open list中(已被遍历过)或者所得到的代价G值cost-so-far小于当前节点已有的代价G值,这时用当前得到的较小的cost更新cost-so-far
if (nSucc->isOnGrid(width, height) && configurationSpace.isTraversable(nSucc)) {
// 1)如果新扩展的节点不在close list中(没有遍历过),或者该节点索引与前一节点在同一网格中
if (!nodes3D[iSucc].isClosed() || iPred == iSucc) {
//更新合格点的G值-【核心--代价G值是当前节点动作的代价值cost-so-far】
nSucc->updateG();
newG = nSucc->getG();
//2)如果扩展节点不在open_list中
// 或者找到了更短G值的路径,或者该节点索引与前一节点在同一网格中(用新点代替旧点)
if (!nodes3D[iSucc].isOpen() || newG < nodes3D[iSucc].getG() || iPred == iSucc) {
//更新合格点的H值: 更新【核心--代价H值是计算下一个节点的动作代价值cost-to-go】
updateH(*nSucc, goal, nodes2D, dubinsLookup, width, height, configurationSpace, visualization);
//3) 如果下一个扩展节点在同一单元格中,但C值(g + h启发值)较大,那就删除掉现在扩展的节点继续找
// 如果cost-so-far的启发式G值比cost-to-come的启发式H值更大时,算法应选择上一个扩展节点predecessor而不是下一个扩展节点successor。
// 这样会导致successor从不会被选择的情况发生,该单元格永远只能扩展一个节点。tieBreaker可以人为地增加
// predecessor的代价,允许successor放置在同一个单元中。它的使用见algorithm.cpp,
if (iPred == iSucc && nSucc->getC() > nPred->getC() + Constants::tieBreaker) {
delete nSucc;//如果下一个点仍在相同的cell、并且cost变大,那就删除掉现在扩展的节点继续找
continue;
}
//4) 如果下一扩展节点仍在相同的cell, 但是代价值要小,则用当前扩展的节点替代前一个节点(这里仅更改指针,数据留在内存中)
else if (iPred == iSucc && nSucc->getC() <= nPred->getC() + Constants::tieBreaker) {
nSucc->setPred(nPred->getPred());//如果下一个点仍在相同的cell、并且cost变小,成功
}
if (nSucc->getPred() == nSucc) {
std::cout << "looping";//给出原地踏步的提示
}
//5)将生成的子节点加入到open list中
nSucc->open();
nodes3D[iSucc] = *nSucc;
O.push(&nodes3D[iSucc]);
delete nSucc;
} else { delete nSucc; }
} else { delete nSucc; }
} else { delete nSucc; }
}
}
}
}
3.创建下一个节点的方式
A算法用的是8连接的方式,hybrid A算法就是三个还是四个dir方向取遍历好像,【防盗标记–盒子君hzj】回头看看
实现原理:
给定当前点位姿pose(x,y,yaw),根据给定的每个方向的变化量dx, dy, dt叠加产生下一个点Successor
//###################################################
// (创建基于控制序列的下一个扩展点)CREATE SUCCESSOR
//函数功能:
//计算当前位姿pose(x,y,yaw),创建基于控制状态的下一个扩展节点pose(xSucc,ySucc,tSucc)
//当前源码的dx, dy, dt为人为指定的值,可以根据实际需要进行修改
//返回return
//返回基于控制量采样的下一个点Node3D
//###################################################
Node3D* Node3D::createSuccessor(const int i) {
float xSucc;
float ySucc;
float tSucc;
//前向的下一个点Successor
if (i < 3) {
xSucc = x + dx[i] * cos(t) - dy[i] * sin(t);
ySucc = y + dx[i] * sin(t) + dy[i] * cos(t);
tSucc = Helper::normalizeHeadingRad(t + dt[i]);
}
//后向的下一个点Successor
else {
xSucc = x - dx[i - 3] * cos(t) - dy[i - 3] * sin(t);
ySucc = y - dx[i - 3] * sin(t) + dy[i - 3] * cos(t);
tSucc = Helper::normalizeHeadingRad(t - dt[i - 3]);
}
return new Node3D(xSucc, ySucc, tSucc, g, 0, this, i);
}
4.计算总代价值C(总估计代价值C = 当前代价值G + 启发代价值H)
总估计代价值C = 当前代价值G + 启发代价值H
//###################################################
// (节点比较,通过启发值C(总估计代价)对3D节点进行排序,用于创建open_list) NODE COMPARISON
//对堆结构中的节点进行排序的结构。
//重载运算符,用来生成节点的比较 逻辑,該函數在“boost::heap::compare”获得使用
//###################################################
struct CompareNodes {
///通过启发值C(总估计代价值C = 当前代价值G + 启发代价值H)对3D节点进行排序
bool operator()(const Node3D* lhs, const Node3D* rhs) const {
return lhs->getC() > rhs->getC();//判断语句,启发值判断
}
///通过启发值C(总估计代价值C = 当前代价值G + 启发代价值H)对2D节点进行排序
bool operator()(const Node2D* lhs, const Node2D* rhs) const {
return lhs->getC() > rhs->getC();//判断语句,启发值判断
}
};
5、计算当前真实代价值G
与A四面八方寻找不同,hybrid A是控制输入演化的邻居节点
在Hybrid A Star就考虑很多其他因素,比如说转向角转向角的改变,是否倒车,车辆行驶方向是否改变等。如果用 δ \deltaδ表示车辆的转向角,D表示车辆的行驶方向,s表示每次搜索所走的路程。下图是该计算实际花费的过程

计算当前真实代价值G核心思想:
每一个子动作都会有一个代价系数,一个总的动作是由多个子动作组合而成的,因此,一个总的动作的代价系数=每个子动作代价系数的乘积【防盗标记–盒子君hzj】
子动作类型包括:单单左转/右转、左右转弯切换(打完左转打右转,打完右转打左转)、掉头
//###################################################
// 计算当前动作变化的代价值MOVEMENT COST(更新代价函数:cost-so-far)
//核心思想:
//每一个子动作都会有一个代价系数,一个总的动作是由多个子动作组合而成的,
//因此,一个总的动作的代价系数=每个子动作代价系数的乘积
//子动作类型包括:单单左转/右转、左右转弯切换(打完左转打右转,打完右转打左转)、掉头
//###################################################
void Node3D::updateG() {
//前进情况
if (prim < 3) {
if (pred->prim != prim) {//方向发生改变时
if (pred->prim > 2) { //计算改变方向的代价值
g += dx[0] * Constants::penaltyTurning * Constants::penaltyCOD;//计算转弯动作+左右切换方向动作的代价
} else {
g += dx[0] * Constants::penaltyTurning; //计算单单转弯动作的代价
}
}
//方向没有发生变化
else {
g += dx[0]; //方向没有改变,代价值不变
}
}
//后退情况
else {
if (pred->prim != prim) {//方向发生改变时
if (pred->prim < 3) { //计算转弯与掉头的代价值
g += dx[0] * Constants::penaltyTurning * Constants::penaltyReversing * Constants::penaltyCOD; //计算掉头动作+转弯动作+左右切换方向动作的代价
} else {
g += dx[0] * Constants::penaltyTurning * Constants::penaltyReversing; //计算掉头动作+单单转弯动作的代价
}
} else {
g += dx[0] * Constants::penaltyReversing; //计算单单掉头动作的代价
}
}
}
.
.
6、计算启发式代价值H
计算启发式代价值H核心思想
这里的cost由三项组成,分别是reedsSheppCost曲线启发值、dubinsCost曲线启发值、twoDCost启发值
使用第一个启发式计算代价值(只考虑运动学、不考虑障碍物来启发)–使用dubins/RS曲线进行探索并计算长度代价
- “non-holonomic-without-obstacles” heuristic:(只考虑运动学、不考虑障碍物来启发,用于指导搜索向目标方向前进)
受运动学约束的无障碍启发式值。论文的计算建议为: max(Reed-Shepp距离/Dubins距离, 欧氏距离) 表示
至于用Reed-Shepp距离还是Dubins距离取决于车辆是否可倒退
.
使用第二个启发式计算代价值(不考虑运动学、只考虑障碍物来启发)–使用A*算法进行探索并计算长度代价
2) “holonomic-with-obstacles” heuristic:(不考虑运动学、只考虑障碍物来启发,用于发现U形转弯(U-shaped obstacles)/死路(dead-ends))
// (不受运动学约束的)有障约束启发式值(即:A*)【防盗标记–盒子君hzj】
注意事项
注1: 实际计算时,优先考虑运动学启发式值,A作为可选项。至于是否启用欧氏距离和A的启发式值,取决于计算的精度和CPU性能(可作为调优手段之一)
注2: 实际计算与论文中的描述存在差异:
(1)实际计算的第一步用的启发式值为“Reed-Shepp距离/Dubins距离”,而论文为“max(Reed-Shepp距离/Dubins距离, 欧氏距离)”【防盗标记–盒子君hzj】
(2)实际计算的第二步用的启发式值为A*的启发式值 减去 “start与goal各自相对自身所在2D网格的偏移量(二维向量)的欧氏距离”
该步计算的意义还需仔细分析,目前我还没想明白代码这样设计的理由。
个人理解如下:
【理解节点控制采样(rviz确定目标点goal,在这里实现使用dubins\RS曲线就默认满足了运动学约束)】
【理解节点连接(dubins\RS、A*直线)】
【理解节点启发式扩张(总的代价值选择扩张方向路线)都在这里实现了)】【防盗标记–盒子君hzj】
【更新启发代价值H----短暂路径探索+代价值计算】:基于当前点使用dubins/RS曲线、2D A算法进行路径探索【这里能得到短暂路径】,并计算探索出来的路径的欧氏距离代价值【这里可以得到迭代路径探索的方向】
(实现的方法具体分为两种启发式方向的路径探索,每一种探索根据前进/后退条件选择不同的算法(上面三种算法之一)进行路径探索,最后比较两种启发式函数的代价值,选择代价最低的路径,这样就确定了探索方向了)【至此,通过模拟一条短暂的可选路径了,但是我们不会直接用这条路径,而是在这条路径基础上继续虚拟向前走一步改变起点位置,再重复进行步骤二的探索,进而实现片状区域的搜索树】【防盗标记–盒子君hzj】
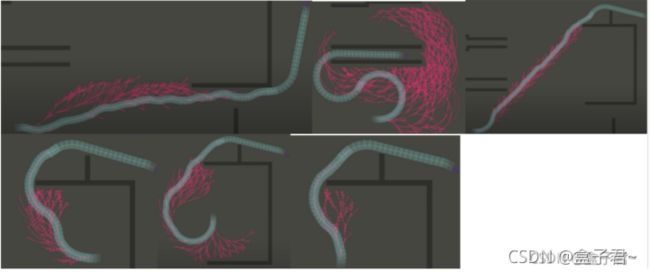
【步骤二注意的是】
1、dubins/RS曲线进行路径探索是不考虑障碍物的进行启发的,但是考虑到安全性,需要用到占据地图数据判断dubins曲线是否在地图中,判断dubins曲线是否与障碍物发生碰撞
2、传统A算法进行路径探索是考虑障碍物的进行启发的,会用到占据地图数据,得到的路径是安全的但是不是最优的,因为不符合车辆的运动学
3、当通过dubins/RS曲线、2D A算法进行路径探索失败的时候就不会再进行探索了,即搜索树会停止生长,这是就会警告replan失败【防盗标记–盒子君hzj】
4、评价代价值的代价函数是起始/终止点的欧式距离代价公式,或者,碰撞代价公式(dubins/RS长度代价公式),因为路径通过探索已经定下来了,代价函数仅仅是做路径的选择(dubins/RS曲线探索出来的路径符合动力学但是绕了大弯的时候就不会选择它【但是一般不会绕大弯】;A算法探索出来的路径因为要躲避障碍物,一般就会绕大弯,此时就不会选择A的路径,两种启发函数的代价通过比较不断切换可能的前进方向)
实际计算时,优先考虑基于运动学启发式方向(即只考虑运动学,不考虑障碍物的启发函数),A(不考虑运动学,只考虑障碍物的启发函数)作为可选项,若车子是在前进方向,优先考虑用Dubins去命中目标点,如果Dubins方法能直接命中终点,即不需要进入Hybrid A搜索了,直接返回结果【这个就是加速路径探索的过程了】
5、步骤二规划出来的路径不是执行路径,它只是局部的一小段路径,我们仅仅只信赖它的下一个路径点而已,并不是信任它整条路径(要决定当前下一步怎么走,我要考虑得非常长远,整条路径以后的发展方向都的考虑)【防盗标记–盒子君hzj】
6、通过hybrid A计算出来的最终路径是dubins/RS曲线、2D A算法中的两种方法叠加起来的,一般情况就是圆弧(dubins/RS曲线)+直线(2D A算法)的组合,经过后面的轨迹优化后就更加平滑了
参考论文
《Practical Search Techniques in Path Planning for Autonomous Driving》
//###################################################
// (代价值H计算) 计算当前点到目标点goal的启发式代价(即:cost-to-go)
//下一步的代价函数
// 计算并return到目标的启发值(start.setH(cost_H))
//###################################################
void updateH(Node3D& start, const Node3D& goal, Node2D* nodes2D, float* dubinsLookup, int width, int height,
CollisionDetection& configurationSpace, Visualize& visualization) {
float dubinsCost = 0;
float reedsSheppCost = 0;
float twoDCost = 0;
float twoDoffset = 0;
//(1)计算无障碍约束的代价值
//1)假如车子不能后退,则启动dubins曲线,则计算最短路径[dubins曲线],及计算该路径无障碍约束的代价值
if (Constants::dubins) {
// 方式一:自己实现dubins曲线
// ONLY FOR dubinsLookup
// int uX = std::abs((int)goal.getX() - (int)start.getX());
// int uY = std::abs((int)goal.getY() - (int)start.getY());
// // if the lookup table flag is set and the vehicle is in the lookup area
// if (Constants::dubinsLookup && uX < Constants::dubinsWidth - 1 && uY < Constants::dubinsWidth - 1) {
// int X = (int)goal.getX() - (int)start.getX();
// int Y = (int)goal.getY() - (int)start.getY();
// int h0;
// int h1;
// // mirror on x axis
// if (X >= 0 && Y <= 0) {
// h0 = (int)(helper::normalizeHeadingRad(M_PI_2 - t) / Constants::deltaHeadingRad);
// h1 = (int)(helper::normalizeHeadingRad(M_PI_2 - goal.getT()) / Constants::deltaHeadingRad);
// }
// // mirror on y axis
// else if (X <= 0 && Y >= 0) {
// h0 = (int)(helper::normalizeHeadingRad(M_PI_2 - t) / Constants::deltaHeadingRad);
// h1 = (int)(helper::normalizeHeadingRad(M_PI_2 - goal.getT()) / Constants::deltaHeadingRad);
// }
// // mirror on xy axis
// else if (X <= 0 && Y <= 0) {
// h0 = (int)(helper::normalizeHeadingRad(M_PI - t) / Constants::deltaHeadingRad);
// h1 = (int)(helper::normalizeHeadingRad(M_PI - goal.getT()) / Constants::deltaHeadingRad);
// } else {
// h0 = (int)(t / Constants::deltaHeadingRad);
// h1 = (int)(goal.getT() / Constants::deltaHeadingRad);
// }
// dubinsCost = dubinsLookup[uX * Constants::dubinsWidth * Constants::headings * Constants::headings
// + uY * Constants::headings * Constants::headings
// + h0 * Constants::headings
// + h1];
// } else {
/*if (Constants::dubinsShot && std::abs(start.getX() - goal.getX()) >= 10 && std::abs(start.getY() - goal.getY()) >= 10)*/
// // start
// double q0[] = { start.getX(), start.getY(), start.getT()};
// // goal
// double q1[] = { goal.getX(), goal.getY(), goal.getT()};
// DubinsPath dubinsPath;
// dubins_init(q0, q1, Constants::r, &dubinsPath);
//计算代价值
// dubinsCost = dubins_path_length(&dubinsPath);
//方式二: 用open motion planning library(ompl)的库实现dubins曲线
ompl::base::DubinsStateSpace dubinsPath(Constants::r);
State* dbStart = (State*)dubinsPath.allocState();
State* dbEnd = (State*)dubinsPath.allocState();
dbStart->setXY(start.getX(), start.getY());
dbStart->setYaw(start.getT());
dbEnd->setXY(goal.getX(), goal.getY());
dbEnd->setYaw(goal.getT());
//计算dubins曲线代价值()
dubinsCost = dubinsPath.distance(dbStart, dbEnd);
}
//2)假如车子可以后退,则可以启动Reeds-Shepp 曲线[opml库实现RS曲线],及计算该路径无障碍约束的代价值
if (Constants::reverse && !Constants::dubins)
{
// ros::Time t0 = ros::Time::now();
ompl::base::ReedsSheppStateSpace reedsSheppPath(Constants::r);
State* rsStart = (State*)reedsSheppPath.allocState();
State* rsEnd = (State*)reedsSheppPath.allocState();
rsStart->setXY(start.getX(), start.getY());
rsStart->setYaw(start.getT());
rsEnd->setXY(goal.getX(), goal.getY());
rsEnd->setYaw(goal.getT());
//计算Reeds-Shepp 曲线代价值
reedsSheppCost = reedsSheppPath.distance(rsStart, rsEnd);
// ros::Time t1 = ros::Time::now();
// ros::Duration d(t1 - t0);
// std::cout << "calculated Reed-Sheep Heuristic in ms: " << d * 1000 << std::endl;
}
//(2)带障碍约束,计算障碍约束的代价值
//1)【核心】调用A*算法进行路径探索,返回cost-so-far, 并在2D网格中设置相应的代价值
if (Constants::twoD && !nodes2D[(int)start.getY() * width + (int)start.getX()].isDiscovered()) {//如果激活了twoD 启发式来确定最短路径,就加入unconstrained with obstacles障碍约束
// ros::Time t0 = ros::Time::now();
// 创建二维起始节点
Node2D start2d(start.getX(), start.getY(), 0, 0, nullptr);
//创建二维目标节点
Node2D goal2d(goal.getX(), goal.getY(), 0, 0, nullptr);
//运行2d astar并返回该节点最小的路径代价值 【把A*计算得到的总代价值作为hybrid A*的当前代价值G】
nodes2D[(int)start.getY() * width + (int)start.getX()].setG(
aStar(goal2d, start2d, nodes2D, width, height, configurationSpace, visualization)//A*返回在现在位置start到goal的H代价值cost-so-far[nSucc->updateH(goal)]
);
// ros::Time t1 = ros::Time::now();
// ros::Duration d(t1 - t0);
// std::cout << "calculated 2D Heuristic in ms: " << d * 1000 << std::endl;
}
//2)计算带障碍约束的代价值
if (Constants::twoD) {
//计算twoDoffset,twoDoffset为start与goal各自相对自身所在2D网格的偏移量的欧氏距离
twoDoffset = sqrt( ((start.getX() - (long)start.getX()) - (goal.getX() - (long)goal.getX())) *
((start.getX() - (long)start.getX()) - (goal.getX() - (long)goal.getX())) +
((start.getY() - (long)start.getY()) - (goal.getY() - (long)goal.getY())) *
((start.getY() - (long)start.getY()) - (goal.getY() - (long)goal.getY()))
);
//getG()返回A*的启发式代价
twoDCost = nodes2D[(int)start.getY() * width + (int)start.getX()].getG() - twoDoffset;
}
//(3)将两种代价中的最大值作为启发式值
//注:虽然这里有三个数值,但Dubins Cost的启用和Reeds-Shepp Cost的启用是互斥的,所以实际上是计算两种cost而已
start.setH(std::max(reedsSheppCost, std::max(dubinsCost, twoDCost)));
}
.
7、A*算法(在第一个启发式函数H中使用)
A算法具体实现原理转战我写A/Dijksta的那个博客【防盗标记–盒子君hzj】
嗯,就这样~
核心思想:
A*算法的具体运行原理是从机器人的运动起始点作为初始点,以此搜索周围的八个节点,然后运用代价函数计算八个节点的最低代价值G\H的点作为下个运行节点,之后以此循环过程直至到达终止点(或者是遍历完成open_list)
//###################################################
// (二维的路径探索)2D A*算法
//原始A*算法,用来搜索计算(带障碍的完整启发式G)
//返回在现在位置start到goal的H代价值cost-so-far
//###################################################
float aStar(Node2D& start, //规划起点
Node2D& goal, //规划目标点
Node2D* nodes2D, //表示R^2中配置空间C的2D节点数组
int width, //地图宽度(以单元格为单位)
int height, //地图高度
CollisionDetection& configurationSpace, //配置的查找表及空间占据计数
Visualize& visualization) { //可视化对象将搜索发布到RViz
//1)定义现在的节点和下一个扩展节点
int iPred, iSucc;
float newG;
//2)nodes2D节点数组重置
for (int i = 0; i < width * height; ++i) {
nodes2D[i].reset();
}
//3)设置可视化延迟时间
ros::Duration d(0.001);
//4)定义Open_list, 注意是一个heap堆栈
boost::heap::binomial_heap<Node2D*,
boost::heap::compare<CompareNodes>> O;
//5)A*计算起点的H代价值,就是当前点到目标点的欧式距离
start.updateH(goal);
//6)把起点push到open_list中
start.open();
O.push(&start);
iPred = start.setIdx(width);
nodes2D[iPred] = start;
//7)定义当前节点指针、下一个扩展节点的指针
Node2D* nPred;
Node2D* nSucc;
//8)【核心】开始进行路径探索,遍历open_list,直到把open_list 的节点全部push到close_list中
while (!O.empty()) {
//(0)从open_list优先级队列中取出g(n)代价值最小的节点,并记录索引
nPred = O.top();
iPred = nPred->setIdx(width);
// (1)如果节点已扩展,则从open_list中移除,处理下一个
if (nodes2D[iPred].isClosed()) {
O.pop();
continue;
}
// (2)如果节点没有进行扩展,这进行扩展
else if (nodes2D[iPred].isOpen()) {
nodes2D[iPred].close(); //节点标记为close
nodes2D[iPred].discover(); //节点标记为discover
O.pop(); //把该节点从open list移除
// 1、RViz 可视化
if (Constants::visualization2D) {
visualization.publishNode2DPoses(*nPred);
visualization.publishNode2DPose(*nPred);
// d.sleep();
}
// 2、若当前节点为目标点,计算返回当前点的G代价值
if (*nPred == goal) {
return nPred->getG();//返回当前点的G代价值
}
// 3、若当前节点不是目标点,则从可能的方向寻找下一个有可能的扩展点
else {
for (int i = 0; i < Node2D::dir; i++) {//A*算法是8个方向:4个正方向和4个45度的方向,覆盖360度(这个不考虑动力学)
// 1)在指定遍历的方向下,创建可能的下一个扩展节点
nSucc = nPred->createSuccessor(i);
iSucc = nSucc->setIdx(width); // 设置扩展节点在地图的索引idx
// 2)约束性检查:在有效网格范围内、且不是障碍、没有扩展过,否则删除这个扩展节点(hybrid A*这里会有运动学约束)
if (nSucc->isOnGrid(width, height) && configurationSpace.isTraversable(nSucc) && !nodes2D[iSucc].isClosed()) {
//更新G代价值,G代价值代价就是上一个节点到目标点的距离
nSucc->updateG();
newG = nSucc->getG();
// 如果子节点并在open集中,或者它的G值(cost-so-far)比之前要小,则为可行的方向,,否则删除这个扩展节点
if (!nodes2D[iSucc].isOpen() || newG < nodes2D[iSucc].getG()) {
//计算H代价值,H代价值就是当前点到目标点的欧式距离
nSucc->updateH(goal);
//将该点移到open set中
nSucc->open();
nodes2D[iSucc] = *nSucc;
O.push(&nodes2D[iSucc]);
delete nSucc;
} else { delete nSucc; }
} else { delete nSucc; }
}
}
}
}
//9)返回一个大的代价值以引导搜索(代价值这么大是不会选择的),正常不会进来这里,正常会搜到一个目标点,
return 1000;
}
.
.
8、dubins算法(在第二个启发式函数H中使用)
基于前进的控制状态规划和dubins曲线rs曲线规划都是符合运动学的,能用dubins曲线规划就用dubins曲线因为减少运算量(巧妙加速)
dubins算法具体实现原理转战我写dubins/RS曲线的那个博客
嗯,就这样~
//###################################################
// Dubins曲线的调用函数(用Dubins曲线去命中目标点)
//核心原理:
//###################################################
Node3D* dubinsShot(Node3D& start, const Node3D& goal, CollisionDetection& configurationSpace) {
//(1)获取dubins曲线起点
double q0[] = { start.getX(), start.getY(), start.getT() };
//(2)获取dubins曲线目标点
double q1[] = { goal.getX(), goal.getY(), goal.getT() };
//(3)依据始点、目标点位置和最小转弯半径生成一条Dubin路径,保存在path
DubinsPath path;//初始化路径
dubins_init(q0, q1, Constants::r, &path);
int i = 0;
float x = 0.f;
float length = dubins_path_length(&path);
//(4)检查dubins拟合出来的曲线,是否满足长度要求和时候会发生碰撞(若不满足就不输出路径),并把拟合出来曲线的格式改成Node3D
Node3D* dubinsNodes = new Node3D [(int)(length / Constants::dubinsStepSize) + 1];
while (x < length) {//这是跳出循环的条件之一:生成的路径没有达到所需要的长度
double q[3];
dubins_path_sample(&path, x, q); //对一段路径进行采样(根据路径长度t和路径参数path,生成长度为t的节点的位置)
dubinsNodes[i].setX(q[0]);
dubinsNodes[i].setY(q[1]);
dubinsNodes[i].setT(Helper::normalizeHeadingRad(q[2]));
//碰撞检测
if (configurationSpace.isTraversable(&dubinsNodes[i])) {//跳出循环的条件之二:生成的路径存在碰撞节点
//把前一个节点设置到本节点,因为节点是迭代的
if (i > 0) {
dubinsNodes[i].setPred(&dubinsNodes[i - 1]);
} else {
dubinsNodes[i].setPred(&start);
}
if (&dubinsNodes[i] == dubinsNodes[i].getPred()) {
std::cout << "looping shot";
}
x += Constants::dubinsStepSize;
i++;
} else {
// std::cout << "Dubins shot collided, discarding the path" << "\n";
// delete all nodes
delete [] dubinsNodes;
return nullptr;
}
}
// std::cout << "Dubins shot connected, returning the path" << "\n";
//返回末节点,通过getPred()可以找到前一节点。
return &dubinsNodes[i - 1];
}
stage2:轨迹优化
9.使用梯度下降的方式对路径进行平滑
//###################################################
// 平滑算法SMOOTHING ALGORITHM
//计算返回一条优化完成的路径
//###################################################
void Smoother::smoothPath(DynamicVoronoi& voronoi) {
//(1)将当前voronoi图加载到smoother中【voronoi图在初始化的时候拿到的】
this->voronoi = voronoi;
this->width = voronoi.getSizeX();
this->height = voronoi.getSizeY();
//(2)定义梯度下降平滑器的当前迭代次数
int iterations = 0;
//(3)梯度下降平滑器的最大迭代次数
int maxIterations = 500;
//(4)路径的长度(以节点数为单位)
int pathLength = 0;
//(5)具有所有节点的路径对象,oldPath为原始路径,newPath为生成的平滑路径
pathLength = path.size();
std::vector<Node3D> newPath = path;
//(6)定义四个优化项的总权重
float totalWeight = wSmoothness + wCurvature + wVoronoi + wObstacle;
//(7)进行循环,沿梯度下降,直到达到最大迭代次数500
//梯度下降思想的比喻:
//梯度下降的方式可以认为是路径path的每个节点对应的每个项的代价值不断叠加的过程,像梳头发这样梳头发500次头发就顺滑了
while (iterations < maxIterations) {
//开始平滑,选择路径的前后两个节点,一共5个节点进行平滑
for (int i = 2; i < pathLength - 2; ++i) {
//0)取后面2个点,当前点,前面2个点
Vector2D xim2(newPath[i - 2].getX(), newPath[i - 2].getY());
Vector2D xim1(newPath[i - 1].getX(), newPath[i - 1].getY());
Vector2D xi(newPath[i].getX(), newPath[i].getY());
Vector2D xip1(newPath[i + 1].getX(), newPath[i + 1].getY());
Vector2D xip2(newPath[i + 2].getX(), newPath[i + 2].getY());
Vector2D correction; //梯度优化方向的总代价值
//1)如果这些点是尖点或与尖点相邻,则保持这些点固定
if (isCusp(newPath, i)) { continue; }//若为尖点,不做平滑
//2)障碍物优化项--梯度下降的方式
correction = correction - obstacleTerm(xi); //输入当前点,计算梯度优化方向代价值,并把障碍物项的代价值叠加到总的代价值上
if (!isOnGrid(xi + correction)) { continue; }//输入当前点,假如校正方向超出当前监视的网格范围,不做处理
//3)人工势场优化项(没有用到)
voronoiTerm();
//4)光滑度优化项--梯度下降的方式
correction = correction - smoothnessTerm(xim2, xim1, xi, xip1, xip2);//输入5个点进行优化,计算梯度优化方向代价值,并把障碍物项的代价值叠加到总的代价值上
if (!isOnGrid(xi + correction)) { continue; } //输入当前点,假如校正方向超出当前监视的网格范围,不做处理
//5)曲率优化项--梯度下降的方式
correction = correction - curvatureTerm(xim1, xi, xip1);//输入3个点进行优化,计算梯度优化方向代价值,并把障碍物项的代价值叠加到总的代价值上
if (!isOnGrid(xi + correction)) { continue; } //输入当前点,假如校正方向超出当前监视的网格范围,不做处理
//6)通过优化的代价值使节点的位置纠正过来
xi = xi + alpha * correction/totalWeight;
newPath[i].setX(xi.getX());
newPath[i].setY(xi.getY());
Vector2D Dxi = xi - xim1;
newPath[i - 1].setT(std::atan2(Dxi.getY(), Dxi.getX()));
}
iterations++;
}
//(8)返回一条优化的路径
path = newPath;
}
.
.
障碍物优化项
理论在上面已经写了
//###################################################
// 障碍物项OBSTACLE TERM
//输入:输入当前点
//输出:计算离最近障碍的梯度方向代价值
//###################################################
Vector2D Smoother::obstacleTerm(Vector2D xi) {
Vector2D gradient;//优化梯度方向的代价值
//voronoi图获取当前节点最近的障碍物的距离【仅仅需要输入当前点的位置,就可以拿到当前节点最近的障碍物的距离】
float obsDst = voronoi.getDistance(xi.getX(), xi.getY());
//确定障碍物位置的向量
int x = (int)xi.getX();
int y = (int)xi.getY();
// 如果节点在map内
if (x < width && x >= 0 && y < height && y >= 0) {
//从当前点xi到最近障碍点的向量
Vector2D obsVct(xi.getX() - voronoi.data[(int)xi.getX()][(int)xi.getY()].obstX,
xi.getY() - voronoi.data[(int)xi.getX()][(int)xi.getY()].obstY);
//最近的障碍物比预期的更近,请纠正该障碍物的路径
if (obsDst < obsDMax) {
return gradient = wObstacle * 2 * (obsDst - obsDMax) * obsVct / obsDst; //代价函数公式(这是一个迭代的形式)
//从公式可以看出,节点靠近障碍物的时候(obsDst - obsDMax),的值会增大,即靠近节点靠近障碍物的时候,代价值会变大
}
}
return gradient;//有潜在风险,前面没有赋值
}
.
.
Voronoi人工势场优化项(没有用到)
理论在上面已经写了
Vector2D Smoother::voronoiTerm(Vector2D xi) {
Vector2D gradient;
// alpha > 0 = falloff rate
// dObs(x,y) = distance to nearest obstacle
// dEge(x,y) = distance to nearest edge of the GVD
// dObsMax = maximum distance for the cost to be applicable
// distance to the closest obstacle
float obsDst = voronoi.getDistance(xi.getX(), xi.getY());
// distance to the closest voronoi edge
float edgDst; //todo
// the vector determining where the obstacle is
Vector2D obsVct(xi.getX() - voronoi.data[(int)xi.getX()][(int)xi.getY()].obstX,
xi.getY() - voronoi.data[(int)xi.getX()][(int)xi.getY()].obstY);
// the vector determining where the voronoi edge is
Vector2D edgVct; //todo
//calculate the distance to the closest obstacle from the current node
//obsDist = voronoiDiagram.getDistance(node->getX(),node->getY())
if (obsDst < vorObsDMax) {
//calculate the distance to the closest GVD edge from the current node
// the node is away from the optimal free space area
if (edgDst > 0) {
float PobsDst_Pxi; //todo = obsVct / obsDst;
float PedgDst_Pxi; //todo = edgVct / edgDst;
float PvorPtn_PedgDst = alpha * obsDst * std::pow(obsDst - vorObsDMax, 2) / (std::pow(vorObsDMax, 2)
* (obsDst + alpha) * std::pow(edgDst + obsDst, 2));
float PvorPtn_PobsDst = (alpha * edgDst * (obsDst - vorObsDMax) * ((edgDst + 2 * vorObsDMax + alpha)
* obsDst + (vorObsDMax + 2 * alpha) * edgDst + alpha * vorObsDMax))
/ (std::pow(vorObsDMax, 2) * std::pow(obsDst + alpha, 2) * std::pow(obsDst + edgDst, 2));
gradient = wVoronoi * PvorPtn_PobsDst * PobsDst_Pxi + PvorPtn_PedgDst * PedgDst_Pxi;
return gradient;
}
return gradient;
}
return gradient;
}
.
.
光滑度优化项
理论在上面已经写了
//###################################################
// 平滑项 SMOOTHNESS TERM
//###################################################
Vector2D Smoother::smoothnessTerm(Vector2D xim2, Vector2D xim1, Vector2D xi, Vector2D xip1, Vector2D xip2) {
return wSmoothness * (xim2 - 4 * xim1 + 6 * xi - 4 * xip1 + xip2); //平滑度的代价函数【约掉时间后求导的简化公式】
//原公式是差值平方差:(x1-x2)*(x1-x2)+ (x2-x3)*(x2-x3)+ (x3-x4)*(x3-x4)+ (x4-x5)*(x4-x5)
}
曲率优化项
理论在上面已经写了
//###################################################
// 曲率项 CURVATURE TERM
//###################################################
//返回梯度方向
Vector2D Smoother::curvatureTerm(Vector2D xim1, Vector2D xi, Vector2D xip1) {
Vector2D gradient;
//计算两节点之间的向量
Vector2D Dxi = xi - xim1;
Vector2D Dxip1 = xip1 - xi;
//正交补向量
Vector2D p1, p2;
//计算向量的距离
float absDxi = Dxi.length();
float absDxip1 = Dxip1.length();
//确保向量的距离绝对值不为空
if (absDxi > 0 && absDxip1 > 0) {
//计算节点处的角度变化--计算曲率
float Dphi = std::acos(Helper::clamp(Dxi.dot(Dxip1) / (absDxi * absDxip1), -1, 1));
float kappa = Dphi / absDxi;
//如果曲率较小,则最大值不起任何作用
if (kappa <= kappaMax) {
Vector2D zeros;
return zeros;
}
//如果曲率较大,则计算曲率项的代价
else {
//代入原文公式(2)与(3)之间的公式
//参考:
// Dolgov D, Thrun S, Montemerlo M, et al. Practical search techniques in path planning for
// autonomous driving[J]. Ann Arbor, 2008, 1001(48105): 18-80.
float absDxi1Inv = 1 / absDxi;
float PDphi_PcosDphi = -1 / std::sqrt(1 - std::pow(std::cos(Dphi), 2));
float u = -absDxi1Inv * PDphi_PcosDphi;
// calculate the p1 and p2 terms
p1 = xi.ort(-xip1) / (absDxi * absDxip1);//公式(4)
p2 = -xip1.ort(xi) / (absDxi * absDxip1);
// calculate the last terms
float s = Dphi / (absDxi * absDxi);
Vector2D ones(1, 1);
Vector2D ki = u * (-p1 - p2) - (s * ones);
Vector2D kim1 = u * p2 - (s * ones);
Vector2D kip1 = u * p1;
//计算曲率项的代价,瞬时曲率变化过大,代价就很高
gradient = wCurvature * (0.25 * kim1 + 0.5 * ki + 0.25 * kip1);
if (std::isnan(gradient.getX()) || std::isnan(gradient.getY())) {
std::cout << "nan values in curvature term" << std::endl;
Vector2D zeros;
return zeros;
}
// return gradient of 0
else {
return gradient;
}
}
}
// return gradient of 0
else {
std::cout << "abs values not larger than 0" << std::endl;
Vector2D zeros;
return zeros;
}
}
.
.
(4)hybird A*算法总结
规划用hybrid a 星(改成了rs曲线),hybrid A*的启发函数有两个,通过切换更好的引导启发效果!
(1)hybrid a*算法探索出来的是圆弧和直线连接的局部路径,后端经过轨迹优化后更加平滑了
(2)Hybrid a算法是在A的基础上考虑机器人的动力学约束,在autoware上有车的实例,高飞上有飞机的实例
(3)Hybrid A*算法是路径探索范畴,既可以用于全局规划,也可以用于局部规划
(4)Hybrid A的原生版本时不带RS曲线,加入RS曲线到hybrid A中仅仅为了加速路径探索的速度,如果地图上没有障碍物,则不需要 Hybrid A*,因为您可以使用 Reeds-Shepp 路径,如果汽车可以倒车,这是两辆车之间的最短距离
(5)Hybrid A也用到启发式A星搜索、梯度下降平滑【防盗标记–盒子君hzj】、代价函数、RS曲线的知识,Hybrid a 较优的一点式在A*算法的基础上,在路径探索部分考虑了动力学约束、采用了更好的启发函数进而提供了更好的探索方向、同时在search过程中使用了RS曲线和dubins曲线提高了搜索的速度;在优化过程中设计了曲率、光滑度、代价地图障碍物、voronoi图避障的四项目标函数进行500次的梯度下降对轨迹进行优化
(6)hybrid a算法用三维节点node3d(x,y,yaw)规划,A算法用二维节点dode2d(x,y)规划,两种算法都是路径探索的方法为什么hybrid a的节点会多一个航向yaw角呢?–因为A算法进行节点扩张仅仅需要位置(x,y)即可,但是hybrid A算法的启发式函数用到了dubins/RS曲线,这两种曲线做路径探索式需要起点朝向和目标点朝向的,因此hybrid A算法的节点要带有yaw航向信息
(7)hybrid A与A的实现流程很像的,只是实现原理思想改变了一点
.
(5)hybird A*算法参考论文、github源码、效果展示
1.参考论文
《Practical Search Techniques in Path Planning for Autonomous Driving》
《Path Planning in Unstructured Environments: A Real-time Hybrid A* Implementation for Fast and Deterministic Path Generation for the KTH Research Concept Vehicle》
Robust and Efficient Quadrotor Trajectory Generation for Fast Autonomous Flight, Boyu Zhou, Fei Gao
https://zhuanlan.zhihu.com/p/139489196
https://zhuanlan.zhihu.com/p/144815425
2.参考链接
https://zhuanlan.zhihu.com/p/161660932
https://zhuanlan.zhihu.com/p/77428431
https://blog.habrador.com/2015/11/explaining-hybrid-star-pathfinding.html
3.github的demo
官方仅仅适合阿克曼车模型,可以换个模型改在无人机或者其他机器人上
高飞相关
https://github.com/HKUST-Aerial-Robotics/Fast-Planner
https://github.com/karlkurzer/path_planner
https://github.com/gyq18/PythonRobotics/blob/master/PathPlanning/HybridAStar/hybrid_a_star.py
autoware的源码
https://zhuanlan.zhihu.com/p/166193636
https://zhuanlan.zhihu.com/p/163844578
官方代码注释版本
https://github.com/teddyluo/hybrid-a-star-annotation
4.视频展示
github的hybrid A*
https://www.bilibili.com/video/BV1rg411c7Ar?spm_id_from=333.999.0.0
autoware的hybrid A*
https://www.bilibili.com/video/BV1n44y117gM?spm_id_from=333.999.0.0
https://www.bilibili.com/video/BV1yf4y1m7to?spm_id_from=333.999.0.0
5.Kinodynamic A*算法
1、前端kinodynamic A*算法动力学路径搜索的功能
用于实现全局规划 ,主要调用函数为 “search()”,在已知地图的前提下,给定起点和终点状态(位置和速度)实现混合A搜索;如果搜索成功,返回一系列path_nodes_节点【防盗标记–盒子君hzj】
前端 kinodynamic a_star 路径搜索(在控制空间进行motion primitive)以及基于帕特利亚金最小值原理的两点边界值问题求解(解决控制空间稀疏采样无法抵达目标点的问题-在状态空间进行motion primitive)【防盗标记–盒子君hzj】
.
.
2、步骤一:进行实时采样,离散的获得一些轨迹点(节点point_set,即创建open_list)以及起始点的速度与加速度
【getSamples()】
1.功能
KinodynamicAstar进行实时采样,离散的获得一些轨迹点(节点point_set,即创建open_list)以及起始点的速度与加速度open_list
.
2.代码实现
//功能:
// KinodynamicAstar进行采样,离散的获得一些轨迹点以及起始点的速度与加速度,得到节点point_set,即open_list
void KinodynamicAstar::getSamples(
double& ts, vector<Eigen::Vector3d>& point_set,
std::vector<Eigen::Vector3d>& start_end_derivatives) {
/* ---------- 【计算最后的轨迹时间T_sum】final trajectory time ---------- */
double T_sum = 0.0;
if (is_shot_succ_) T_sum += t_shot_;
PathNodePtr node = path_nodes_.back();
while (node->parent != NULL) {
T_sum += node->duration;
node = node->parent;
}
// cout << "final time:" << T_sum << endl;
/* ---------- 【采样过程初始化】init for sampling ---------- */
int K = floor(T_sum / ts);
ts = T_sum / static_cast<double>(K + 1);
// cout << "K:" << K << ", ts:" << ts << endl;
bool sample_shot_traj = is_shot_succ_; //复位获取的轨迹点标志位
// Eigen::VectorXd sx(K + 2), sy(K + 2), sz(K + 2);
// int sample_num = 0;
node = path_nodes_.back();
//设置终点的速度、终点加速度
Eigen::Vector3d end_vel, end_acc;
double t;
if (sample_shot_traj) { //若能采样到轨迹点,使用运动约束计算终点的速度、终点加速度
t = t_shot_;
end_vel = end_vel_;
for (int dim = 0; dim < 3; ++dim) {
Vector4d coe = coef_shot_.row(dim);
end_acc(dim) = 2 * coe(2) + 6 * coe(3) * t_shot_;
}
}
else { //若不能采样到轨迹点,使用手动输入的参数设置终点的速度、终点加速度
t = node->duration;
end_vel = node->state.tail(3);
end_acc = node->input;
}
for (double ti = T_sum; ti > -1e-5; ti -= ts) {
/* ---------- 【开始采样轨迹点】---------- */
if (sample_shot_traj) { //若采样到轨迹点sample shot traj,把轨迹点存入point_set
Eigen::Vector3d coord;
Eigen::Vector4d poly1d, time;
for (int j = 0; j < 4; j++) time(j) = pow(t, j);
for (int dim = 0; dim < 3; dim++) {
poly1d = coef_shot_.row(dim);
coord(dim) = poly1d.dot(time);
}
// sx(sample_num) = coord(0), sy(sample_num) = coord(1), sz(sample_num) =
// coord(2);
// ++sample_num;
point_set.push_back(coord);
t -= ts;
/* 分段的结尾end of segment */
if (t < -1e-5) {
sample_shot_traj = false;
if (node->parent != NULL) t += node->duration;
}
}
else { //若没有采样得到轨迹点,进行状态传递,继续采样sample search traj
Eigen::Matrix<double, 6, 1> x0 = node->parent->state;
Eigen::Matrix<double, 6, 1> xt;
Eigen::Vector3d ut = node->input;
stateTransit(x0, xt, ut, t); //【终点】状态传递
// sx(sample_num) = xt(0), sy(sample_num) = xt(1), sz(sample_num) = xt(2);
// ++sample_num;
point_set.push_back(xt.head(3));
t -= ts;
// cout << "t: " << t << ", t acc: " << T_accumulate << endl;
if (t < -1e-5 && node->parent->parent != NULL) {
node = node->parent;
t += node->duration;
}
}
}
/* ---------- return samples ---------- */
// samples.col(K + 2) = start_vel_;
// samples.col(K + 3) = end_vel_;
// samples.col(K + 4) = node->input;
reverse(point_set.begin(), point_set.end());
start_end_derivatives.push_back(start_vel_);
start_end_derivatives.push_back(end_vel);
start_end_derivatives.push_back(node->input); // start acc
start_end_derivatives.push_back(end_acc); // end acc
}
.
.
3、步骤二:设置算法搜索参数setParam()
void KinodynamicAstar::setParam() {
max_tau_ = 1.0; // 最大时间 s
init_max_tau_ = 0.8; // 初始化时间 s
max_vel_ = 6.0; // 最大的速度 m/s
max_acc_ = 2.0; // 最大的加速度 m/s^2
w_time_ = 10.0; // 花费时间的权重
horizon_ = 50.0; // 搜索范围,在这里基本上是无用的,所以我们必须将它设置为一个大值
lambda_heu_ = 5.0;
resolution_ = 0.5; // 距离分辨率 m
time_resolution_ = 0.8; // 时间分辨率 s
margin_ = 0.2; // 边界
allocate_num_ = 100000; // 分配数量,设置了100000个节点到path_node_pool
check_num_ = 10; // 检查数量
}
nh.param("search/max_tau", max_tau_, -1.0); //如果考虑对时间维度进行划分才设置,这里未设置
nh.param("search/init_max_tau", init_max_tau_, -1.0);
nh.param("search/max_vel", max_vel_, -1.0); // 速度限制
nh.param("search/max_acc", max_acc_, -1.0); // 加速度限制
nh.param("search/w_time", w_time_, -1.0); //
nh.param("search/horizon", horizon_, -1.0); //限制全局规划的距离,保证实时性
nh.param("search/resolution_astar", resolution_, -1.0); //空间分辨率
nh.param("search/time_resolution", time_resolution_, -1.0); // 时间维度分辨率
nh.param("search/lambda_heu", lambda_heu_, -1.0); // 启发函数权重
nh.param("search/margin", margin_, -1.0); //检测碰撞
nh.param("search/allocate_num", allocate_num_, -1); //最大节点数目
nh.param("search/check_num", check_num_, -1); //对中间状态安全检查
.
.
.
4、步骤三:整体的搜索过程search()–包括进行节点扩张-剪枝
1.整体搜索的逻辑流程
手撕示例图
步骤详细解释
(1)步骤1:自己额外加的规划条件约束
1)记录一下规划时间,规划超时退出
2)据业务要求的不进行路径规划,放了一个启动plan标志位实现【防盗标记–盒子君hzj】
(2)步骤2:进行采样,离散的获得一些轨迹点以及起始点的速度与加速度,得到节点point_set,即创建open_list
getSamples()【基于控制空间采样的过程,我在后面分析】
(3)步骤3:将起始点及目标点的三维位置转化至栅格地图的index. 并计算第一个扩展点的Heuristic cost
【计算启发代价H函数的原理,我在后面分析】【防盗标记–盒子君hzj】
(4)步骤4:迭代循环搜索扩张节点,扩张节点的同时不断进行两点边界只的直达曲线计算
1)从open_list优先级队列中取出f(n) = g(n) + h(n)代价值最小的节点
2)【重点】判断当前节点是否超出horizon或是离终点较近了,并计算一条直达曲线,检查这条曲线上是否存在。若存在,则搜索完成,返回路径点即可
【computeShotTraj()计算直达曲线的原理,,我在后面分析】
3)【重点】若当前节点没有抵达终点,就要进行节点扩张-剪枝【重点!!!】
1、在open_list中删除节点,并在close_list中添加节点
2、初始化状态传递
3、判断节点是已经被扩展过
4、状态传递循环迭代,检查速度约束,检查碰撞,都通过的话,就计算当前节点的g_score以及f_score,并且对重复的扩展节点进行剪枝
判断节点若在不在close_list中
判断节点最大速度
判断节点不在同样的网格中
判断节点是否发生碰撞
状态传递,通过前向积分得到扩展节点的位置和速度stateTransit()【防盗标记–盒子君hzj】
计算当前节点的真实的代价G值
计算启发式代价H值
在循环中对比扩展节点,进行节点剪枝
【状态传递stateTransit()、计算当前节点的真实的代价G值、计算启发式代价H值、节点剪枝这四个过程比较重要,后面详细分析】
4)open_list已经遍历完成了,没有搜索到路径 open set empty, no path
(4)步骤4:获取规划得到的路径点getKinoTraj()
2.代码实现
核心原理:
search函数的参数包含起始点以及重点的位置,速度,加速度。以及两个标志位init 和dynamic,还有一个搜索起始时间
int KinodynamicAstar::search(Eigen::Vector3d start_pt, Eigen::Vector3d start_v,
Eigen::Vector3d start_a, Eigen::Vector3d end_pt,
Eigen::Vector3d end_v, bool init, bool dynamic,
double time_start) {
//【自己加的】记录一下规划时间
using Time = apollo::cyber::Time;
decideMapType(start_pt, end_pt); //判断使用什么地图类型
double search_starttime = Time::MonoTime().ToSecond();
//【自己加的】业务要求的不进行路径规划,放了一个标志位实现
if (not_to_plan_) {
return NO_PATH;
}
/* ---------- (1)将起始点及目标点的三维位置转化至栅格地图的index. 并计算第一个扩展点的Heuristic cost ---------- */
{
start_vel_ = start_v;
start_acc_ = start_a;
//设置第一个节点
PathNodePtr cur_node = path_node_pool_[0];
cur_node->parent = NULL;
cur_node->state.head(3) = start_pt;
cur_node->state.tail(3) = start_v;
cur_node->index = posToIndex(start_pt);
cur_node->g_score = 0.0;
//设置最后一个节点
Eigen::VectorXd end_state(6);
Eigen::Vector3i end_index;
double time_to_goal;
end_state.head(3) = end_pt;
end_state.tail(3) = end_v;
end_index = posToIndex(end_pt);
//【核心】计算启发代价值f
cur_node->f_score =
lambda_heu_ * estimateHeuristic(cur_node->state, end_state, time_to_goal);
cur_node->node_state = IN_OPEN_SET;
//把起点放入open_list和expanded_nodes_
open_set_.push(cur_node);
use_node_num_ += 1;
expanded_nodes_.insert(cur_node->index, cur_node);
PathNodePtr neighbor = NULL; //邻节点
PathNodePtr terminate_node = NULL; //终止节点
bool init_search = init; //判断hybrid A*有没有初始化成功
int tolerance1 = ceil(2 / resolution_);
int tolerance2 = ceil( 2.5 * end_v.norm() * 0.4 / resolution_);
int tolerance = 2; // 2 grids //std::max(tolerance1, tolerance2);
}
/* ---------- (2)搜索扩张节点迭代循环 ---------- */
while (!open_set_.empty()) { //在open_list中寻找节点,直到open_list为空
//【自己加的】规划超时退出
//计算规划到现在所耗的时间,规划到现在所耗的时间 = 现在的时刻 - 开始规划的时刻
double elapsed_time = Time::MonoTime().ToSecond() - search_starttime;
if (elapsed_time > 0.2) {
cout << "Searched for too long, abort!!!" << endl;
return NO_PATH;
}
/* --- 1)从open_list优先级队列中取出f(n) = g(n) + h(n)代价值最小的节点 get lowest f_score node ---------- */
cur_node = open_set_.top();//取出栈顶节点,栈顶节点就是代价值最小的节点
/* --- 2)判断当前节点是否超出horizon或是离终点较近了,并计算一条直达曲线,检查这条曲线上是否存在。若存在,则搜索完成,返回路径点即可 ---------- */
//判断是否距离终点比较近了
bool near_end = abs(cur_node->index(0) - end_index(0)) <= tolerance &&
abs(cur_node->index(1) - end_index(1)) <= tolerance &&
abs(cur_node->index(2) - end_index(2)) <= tolerance;
//判断当前节点有没有碰撞(通过地图)
bool has_collide = collide(cur_node->state.head(3), end_pt);
//判断当前角度是否正确
bool right_angle;
{
Eigen::Vector3d cur_v = cur_node->state.tail(3);
double angle = std::acos(cur_v.dot(end_v) / (cur_v.norm() * end_v.norm()));
if (angle < 45.0 / 180.0 * M_PI) {
right_angle = true;
} else {
right_angle = false;
}
if (end_v.norm() < 1.5) {
right_angle = true;
}
}
//若距离终点比较近了,并且没有发生碰撞,角度还是正确的,则计算一条直达曲线,检查这条曲线上是否存在。若存在,则搜索完成,返回路径点
//后来我们直接认为就到达终点了,不用这么严谨麻烦
if (near_end && !has_collide && right_angle) {
terminate_node = cur_node;
retrievePath(terminate_node);
has_path_ = true;
cout << "Kino AStar near end" << endl;
cout << "use node num" << endl;
cout << "iter num" << endl;
/* 计算一条直达曲线one shot trajectory */
//计算最优控制时间time_to_goal
// estimateHeuristic(cur_node->state, end_state, time_to_goal);
//计算并验证该轨迹是安全的,即不发生碰撞,速度、加速度不超限。
//computeShotTraj(cur_node->state, end_state, time_to_goal);
if (terminate_node->parent == NULL) { // TODO : fix the problem that the first point is already near end
// std::cout << " failed to shoot for the moon\n";
cout << "Failed to shoot for the moon" << endl;
return NO_PATH;
} else {
return REACH_END;
}
}
/* ---3)若当前节点没有抵达终点,就要进行节点扩张 ---------- */
//以上代码在当前节点的基础上,根据对输入、时间的离散进行扩展得到临时节点tmp
//首先判断节点是否已经被扩展过,即是否与当前节点在同一个节点
//检查速度约束,检查碰撞,都通过的话,就计算当前节点的g_score以及f_score.
//其中的state transit函数即通过前向积分得到扩展节点的位置和速度。接下来,就要进行节点剪枝
//1、在open_list中删除节点,并在close_list中添加节点
open_set_.pop();
cur_node->node_state = IN_CLOSE_SET;
iter_num_ += 1;
//2、初始化状态传递
double res = 1 / 2.0, time_res = 1 / 1.0, time_res_init = 1 / 8.0;
Eigen::Matrix<double, 6, 1> cur_state = cur_node->state;
Eigen::Matrix<double, 6, 1> pro_state;
vector<PathNodePtr> tmp_expand_nodes;
Eigen::Vector3d um;
double pro_t;
vector<Eigen::Vector3d> inputs;
vector<double> durations;
// //3、判断节点是已经被扩展过,弹出节点
// if (init_search) {
// inputs.push_back(start_acc_);
// for (double tau = time_res_init * init_max_tau_; tau <= init_max_tau_;
// tau += time_res_init * init_max_tau_)
// durations.push_back(tau);
// } else {
// for (double ax = -max_acc_; ax <= max_acc_ + 1e-3; ax += max_acc_ *
// res)
// for (double ay = -max_acc_; ay <= max_acc_ + 1e-3; ay += max_acc_ *
// res)
// for (double az = -max_acc_; az <= max_acc_ + 1e-3; az += max_acc_ *
// res) {
// um << ax, ay, az;
// inputs.push_back(um);
// }
// for (double tau = time_res * max_tau_; tau <= max_tau_; tau += time_res
// * max_tau_)
// durations.push_back(tau);
// }
// 3、判断节点没有被扩展过,把这个节点存下来
for (double ax = -max_acc_; ax <= max_acc_ + 1e-3; ax += 0.5) {
for (double ay = -max_acc_; ay <= max_acc_ + 1e-3; ay += 0.5) {
// for (double az = -max_acc_; az <= max_acc_ + 1e-3; az += max_acc_ *
// res)
{
um << ax, ay, 0; // az;
inputs.push_back(um);
}
}
}
// for (double tau = time_res * max_tau_; tau <= max_tau_;
// tau += time_res * max_tau_) { // actually there is only one single tau
// durations.push_back(tau);
// }
durations.push_back(max_tau_);
//4、状态传递循环迭代,检查速度约束,检查碰撞,都通过的话,就计算当前节点的g_score以及f_score.并且对重复的扩展节点进行剪枝
// cout << "cur state:" << cur_state.head(3).transpose() << endl;
for (int i = 0; i < inputs.size(); ++i)
for (int j = 0; j < durations.size(); ++j) {
init_search = false;
um = inputs[i];
double tau = durations[j];
stateTransit(cur_state, pro_state, um, tau);//状态传递,通过前向积分得到扩展节点的位置和速度
pro_t = cur_node->time + tau;
/* ---------- check if in free space ---------- */
//【自己加的】增加地图范围inside map range
if (pro_state(0) <= origin_(0) || pro_state(0) >= map_size_3d_(0) ||
pro_state(1) <= origin_(1) || pro_state(1) >= map_size_3d_(1) ||
pro_state(2) <= origin_(2) || pro_state(2) >= map_size_3d_(2)) {
// std::cout << "outside map" << endl;
// std::cout << "pro_state: " << pro_state(0) << " " << pro_state(1)
// << " " << pro_state(2) << std::endl; std::cout << "origin_: " <<
// origin_(0) << " " << origin_(1) << " " << origin_(2) << std::endl;
// std::cout << "map_size_3d_: " << map_size_3d_(0) << " " <<
// map_size_3d_(1) << " " << map_size_3d_(2) << std::endl;
continue;
}
// 判断节点若在不在close_list中
Eigen::Vector3i pro_id = posToIndex(pro_state.head(3));
int pro_t_id = timeToIndex(pro_t);
PathNodePtr pro_node = expanded_nodes_.find(pro_id);
if (pro_node != NULL && pro_node->node_state == IN_CLOSE_SET) {
// cout << "in closeset" << endl;
continue;
}
// 判断节点最大速度
// Eigen::Vector3d pro_v = pro_state.tail(3);
// if (fabs(pro_v(0)) > max_vel_ || fabs(pro_v(1)) > max_vel_ ||
// fabs(pro_v(2)) > max_vel_) {
// // cout << "vel infeasible" << endl;
// continue;
// }
Eigen::Vector3d pro_v = pro_state.tail(3);
if (pro_v.norm() > max_vel_) {
// cout << "vel infeasible" << endl;
continue;
}
// 判断节点不在同样的网格中 not in the same voxel
Eigen::Vector3i diff = pro_id - cur_node->index;
int diff_time = pro_t_id - cur_node->time_idx;
if (diff.norm() == 0 && ((!dynamic) || diff_time == 0)) {
cout << "Same voxel" << endl;
continue;
}
//判断节点是否发生碰撞 collision free
Eigen::Vector3d pos;
Eigen::Matrix<double, 6, 1> xt;
bool is_occ = false;
for (int k = 1; k <= check_num_; ++k) {
double dt =
tau * static_cast<double>(k) / static_cast<double>(check_num_);
stateTransit(cur_state, xt, um, dt);//状态传递,通过前向积分得到扩展节点的位置和速度
pos = xt.head(3);
double dist_no_inter = collision_detection_->minObstacleDistance(pos);
if (dist_no_inter <= SAFE_DISTANCE_) {
is_occ = true;
break;
}
if (pointHasGlobalCollision(pos)) {
is_occ = true;
break;
}
}
if (is_occ) {
// cout << "collision" << endl;
continue;
}
//计算代价值 compute cost
double time_to_goal, tmp_g_score, tmp_f_score;
//计算当前节点的真实的代价G值
tmp_g_score = (um.squaredNorm() + w_time_) * tau + cur_node->g_score;
//计算启发式代价H值
tmp_f_score = tmp_g_score +
1.0 * lambda_heu_ *
estimateHeuristic(pro_state, end_state, time_to_goal);
/* ----------5)在循环中对比扩展节点,进行节点剪枝---------- */
// 首先判断当前临时扩展节点与current node的其他临时扩展节点是否在同一个voxel中,如果是的话,就要进行剪枝。
// 如果不用剪枝的话,则首先判断当前临时扩展节点pro_node是否出现在open集中,
// 如果不是存在于open集的话,则可以直接将pro_node加入open集中。
// 如果是存在于open集但还未扩展的话,则比较当前临时扩展节点与对应VOXEL节点的fscore,若更小,则更新voxel中的节为当前临时扩展节点。
// 需要进行说明的是,在Fast planner的实现中,
// open集是通过两个数据结构实现的,
// 一个队列用来存储,弹出open集中的节点。
// 另一个哈希表NodeHashtable 用来查询节点是否已经存在于open集中。
// 而判断一个节点是否存在于close set中,则是通过Nodehashtable 与nodestate来决定的,
// 如果nodeState 是 InCloseSet, 且存在于NodeHashtable, 则说明该节点已经被扩展过了,存在于close set中。
bool prune = false; //剪枝标志位
for (int j = 0; j < tmp_expand_nodes.size(); ++j) {
PathNodePtr expand_node = tmp_expand_nodes[j];
// 首先判断当前临时扩展节点与current node的其他临时扩展节点是否在同一个voxel中,如果是的话就是扩展的节点多余了,就要进行剪枝。
if ((pro_id - expand_node->index).norm() == 0 &&
((!dynamic) || pro_t_id == expand_node->time_idx)) {
prune = true;
if (tmp_f_score < expand_node->f_score) {
expand_node->f_score = tmp_f_score;
expand_node->g_score = tmp_g_score;
expand_node->state = pro_state;
expand_node->input = um;
expand_node->duration = tau;
}
break;
}
}
if (!prune) {
if (pro_node == NULL) {
pro_node = path_node_pool_[use_node_num_];
pro_node->index = pro_id;
pro_node->state = pro_state;
pro_node->f_score = tmp_f_score;
pro_node->g_score = tmp_g_score;
pro_node->input = um;
pro_node->duration = tau;
pro_node->parent = cur_node;
pro_node->node_state = IN_OPEN_SET;
open_set_.push(pro_node);
expanded_nodes_.insert(pro_id, pro_node);
tmp_expand_nodes.push_back(pro_node);
use_node_num_ += 1;
if (use_node_num_ == allocate_num_) {
cout << "run out of memory." << endl;
return NO_PATH;
}
}
// 如果不用剪枝的话,则首先判断当前临时扩展节点pro_node是否出现在open集中
else if (pro_node->node_state == IN_OPEN_SET) {
// 如果是存在于open集但还未扩展的话,则比较当前临时扩展节点与对应VOXEL节点的fscore,若更小,则更新voxel中的节为当前临时扩展节点。
if (tmp_g_score < pro_node->g_score) {
// pro_node->index = pro_id;
pro_node->state = pro_state;
pro_node->f_score = tmp_f_score;
pro_node->g_score = tmp_g_score;
pro_node->input = um;
pro_node->duration = tau;
pro_node->parent = cur_node;
}
}
// 如果不是存在于open集的话,则可以直接将pro_node加入open集中
else {
cout << "error type in searching: " << pro_node->node_state << endl;
}
}
/* ---------- ---------- */
}
}
/* ----------5)open_list已经遍历完成了,没有搜索到路径 open set empty, no path ---------- */
// cout << "open set empty, no path!" << endl;
// cout << "use node num: " << use_node_num_ << endl;
// cout << "iter num: " << iter_num_ << endl;
// if(iter_num_ == 1) {
// int a;
// std::cin >> a;
// std::cout << a;
// }
return NO_PATH;
}
.
5、步骤四:获取规划得到的路径点getKinoTraj()
1、功能
【调用获取规划得到的路径点】
完成路径搜索后,按照预设的时间分辨率delta_t, 通过节点回溯和状态前向积分得到分辨率更高的路径点。 如果最后的shot trajectory存在的话,则还要加上最后一段shot trajectory(即通过computeshottraj)算出来得到的【防盗标记–盒子君hzj】
最终轨迹 = 前面节点扩张的回溯轨迹+后面两点边界只轨迹
当然,我们前后没有启动shot trajectory【防盗标记–盒子君hzj】
2、代码实现
//输入预设时间分辨率,获取对应的一段动力学轨迹state_list
std::vector<Eigen::Vector3d> KinodynamicAstar::getKinoTraj(double delta_t) {
std::vector<Vector3d> state_list;
/* ---------- 【获取搜索到的轨迹state_list】get traj of searching ---------- */
PathNodePtr node = path_nodes_.back();
Eigen::Matrix<double, 6, 1> x0, xt;
while (node->parent != NULL) {
Eigen::Vector3d ut = node->input;
double duration = node->duration;
x0 = node->parent->state;
for (double t = duration; t >= -1e-5; t -= delta_t) {
stateTransit(x0, xt, ut, t);
state_list.push_back(xt.head(3));
}
node = node->parent;
}
reverse(state_list.begin(), state_list.end());
/* ---------- 【获取一小段轨迹state_list】get traj of one shot ---------- */
if (is_shot_succ_) {
Eigen::Vector3d coord;
Eigen::VectorXd poly1d, time(4);
for (double t = delta_t; t <= t_shot_; t += delta_t) {
for (int j = 0; j < 4; j++) time(j) = pow(t, j);
for (int dim = 0; dim < 3; dim++) {
poly1d = coef_shot_.row(dim);
coord(dim) = poly1d.dot(time);
}
state_list.push_back(coord);
}
}
return state_list;
}
6、关键函数分析【重点】
(1)计算启发代价值H estimateHeuristic()
1、原理
estimateHeuristic()主要原理是利用庞特里亚金原理解决两点边值问题,得到最优解后用最优解的控制代价作为启发函数。

2、代码实现
首先通过设置启发函数对时间求导等于0,得到启发函数关于时间T的四次方程,再通过求解该四次方程,得到一系列实根,通过比较这些实根所对应的cost大小,得到最优时间。
这里需要注意,关于时间的一元四次方程是通过费拉里方法求解的,需要嵌套一个元三次方程进行求解,也就是代码中应的cubic()函数。【防盗标记–盒子君hzj】
//算法原理:对应文章中的III.B小节
//主要原理:
//利用庞特里亚金原理解决两点边值问题,得到最优解后用最优解的控制代价作为启发函数。
//具体步骤:
// 首先通过设置启发函数对时间求导等于0,得到启发函数关于时间T的四次方程,再通过求解该四次方程,
// 得到一系列实根,通过比较这些实根所对应的cost大小,得到最优时间。
//input :起点x1、终点x2
//return :optimal_time最优控制时间、启发值代价
double KinodynamicAstar::estimateHeuristic(Eigen::VectorXd x1,
Eigen::VectorXd x2,
double& optimal_time) {
const Eigen::Vector3d dp = x2.head(3) - x1.head(3);//两点间的距离
const Eigen::Vector3d v0 = x1.segment(3, 3); //起点速度
const Eigen::Vector3d v1 = x2.segment(3, 3); //终点速度
//(1)首先通过设置启发函数对时间求导等于0,得到启发函数关于时间T的四次方程
//dot()两个数组的点积
double c1 = -36 * dp.dot(dp);
double c2 = 24 * (v0 + v1).dot(dp);
double c3 = -4 * (v0.dot(v0) + v0.dot(v1) + v1.dot(v1));
double c4 = 0;
double c5 = w_time_;
//(2)求解一元四次方程,得到一系列实根,通过比较这些实根所对应的cost大小,得到最优时间。
//关于时间的一元四次方程是通过费拉里方法求解的,需要嵌套一个元三次方程进行求解,也就是代码中应的cubic()函数。
//一元四次方程的求解过程参见wikipedia中的费拉里方法:https://zh.wikipedia.org/wiki/%E5%9B%9B%E6%AC%A1%E6%96%B9%E7%A8%8B
//一元三次方程的求见过程参见wikipedia中的求根系数法。需要加以说明的是,代码中的判别式大于0及等于0的情况利用了求根公式,判别式小于0的情况则是使用了三角函数解法
//https://zh.wikipedia.org/wiki/%E4%B8%89%E6%AC%A1%E6%96%B9%E7%A8%8B
std::vector<double> ts = quartic(c5, c4, c3, c2, c1);
double v_max = max_vel_;
double t_bar = (x1.head(3) - x2.head(3)).lpNorm<Infinity>() / v_max;
ts.push_back(t_bar);
double cost = 100000000;
double t_d = t_bar;
//比较这些实根所对应的cost大小,得到最优时间
for (auto t : ts) {
if (t < t_bar) continue;
double c = -c1 / (3 * t * t * t) - c2 / (2 * t * t) - c3 / t + w_time_ * t;
if (c < cost) {
cost = c;
t_d = t;
}
}
optimal_time = t_d;
return 1.0 * (1 + tie_breaker_) * cost;
}
//求解一元四次方程
//ax^4 + bx^3 + cx^2 + dx + e = 0
std::vector<double> KinodynamicAstar::quartic(double a, double b, double c,
double d, double e) {
std::vector<double> dts;
double a3 = b / a;
double a2 = c / a;
double a1 = d / a;
double a0 = e / a;
//求解一元三次方程
std::vector<double> ys =
cubic(1, -a2, a1 * a3 - 4 * a0, 4 * a2 * a0 - a1 * a1 - a3 * a3 * a0);
double y1 = ys.front();
double r = a3 * a3 / 4 - a2 + y1;
if (r < 0) return dts;
double R = sqrt(r);
double D, E;
if (R != 0) {
D = sqrt(0.75 * a3 * a3 - R * R - 2 * a2 +
0.25 * (4 * a3 * a2 - 8 * a1 - a3 * a3 * a3) / R);
E = sqrt(0.75 * a3 * a3 - R * R - 2 * a2 -
0.25 * (4 * a3 * a2 - 8 * a1 - a3 * a3 * a3) / R);
} else {
D = sqrt(0.75 * a3 * a3 - 2 * a2 + 2 * sqrt(y1 * y1 - 4 * a0));
E = sqrt(0.75 * a3 * a3 - 2 * a2 - 2 * sqrt(y1 * y1 - 4 * a0));
}
if (!std::isnan(D)) {
dts.push_back(-a3 / 4 + R / 2 + D / 2);
dts.push_back(-a3 / 4 + R / 2 - D / 2);
}
if (!std::isnan(E)) {
dts.push_back(-a3 / 4 - R / 2 + E / 2);
dts.push_back(-a3 / 4 - R / 2 - E / 2);
}
return dts;
}
//求解一元三次方程
//ax^3 + bx^2 + cx + d = 0
std::vector<double> KinodynamicAstar::cubic(double a, double b, double c,
double d) {
std::vector<double> dts;
double a2 = b / a;
double a1 = c / a;
double a0 = d / a;
double Q = (3 * a1 - a2 * a2) / 9;
double R = (9 * a1 * a2 - 27 * a0 - 2 * a2 * a2 * a2) / 54;
double D = Q * Q * Q + R * R;
if (D > 0) {
double S = std::cbrt(R + sqrt(D));
double T = std::cbrt(R - sqrt(D));
dts.push_back(-a2 / 3 + (S + T));
return dts;
} else if (D == 0) {
double S = std::cbrt(R);
dts.push_back(-a2 / 3 + S + S);
dts.push_back(-a2 / 3 - S);
return dts;
} else {
double theta = acos(R / sqrt(-Q * Q * Q));
dts.push_back(2 * sqrt(-Q) * cos(theta / 3) - a2 / 3);
dts.push_back(2 * sqrt(-Q) * cos((theta + 2 * M_PI) / 3) - a2 / 3);
dts.push_back(2 * sqrt(-Q) * cos((theta + 4 * M_PI) / 3) - a2 / 3);
return dts;
}
}
.
.
(2)计算当前节点的真实的代价G值
tmp_g_score = (um.squaredNorm() + w_time_) * tau + cur_node->g_score;
.
(3)计算一条直达曲线computeShotTraj()
1.原理
计算出起始节点的启发项后,就基本进入搜索循环【防盗标记–盒子君hzj】,第一步是判断当前节点是否超出horizon或是离终点较近了,并计算一条直达曲线,检查这条曲线上是否存在。若存在,则搜索完成,返回路径点即可
利用庞特里亚金原理解一个两点边值问题。因为最优控制时间已经在estimateHeuristic中计算过了,所以这里只要引入该时间进行多项式计算即可。这部分的目的是为了验证该轨迹是安全的,即不发生碰撞,速度、加速度不超限
五次多项式优化就是mini_snap,这里本质就是通过多项式计算五次多项式两点边界问题,方法有很多,这里利用庞特里亚金原理解一个两点边值问题,其他方法看我另外体格博客
2.代码实现
//【重要函数】利用庞特里亚金原理解一个两点边值问题。
//因为最优控制时间time_to_goal已经在estimateHeuristic中计算过了
//所以这里只要引入该时间进行多项式计算即可
//目的:计算并验证该轨迹是安全的,即不发生碰撞,速度、加速度不超限。
//主要步骤:多项式计算
bool KinodynamicAstar::computeShotTraj(Eigen::VectorXd state1,
Eigen::VectorXd state2,
double time_to_goal) {
/* ---------- 获取系数get coefficient ---------- */
const Eigen::Vector3d p0 = state1.head(3);
const Eigen::Vector3d dp = state2.head(3) - p0;
const Eigen::Vector3d v0 = state1.segment(3, 3);
const Eigen::Vector3d v1 = state2.segment(3, 3);
const Eigen::Vector3d dv = v1 - v0;
double t_d = time_to_goal;
MatrixXd coef(3, 4);
end_vel_ = v1;
Eigen::Vector3d a =
1.0 / 6.0 *
(-12.0 / (t_d * t_d * t_d) * (dp - v0 * t_d) + 6 / (t_d * t_d) * dv);
Eigen::Vector3d b =
0.5 * (6.0 / (t_d * t_d) * (dp - v0 * t_d) - 2 / t_d * dv);
Eigen::Vector3d c = v0;
Eigen::Vector3d d = p0;
// 1/6 * alpha * t^3 + 1/2 * beta * t^2 + v0
// a*t^3 + b*t^2 + v0*t + p0
coef.col(3) = a, coef.col(2) = b, coef.col(1) = c, coef.col(0) = d;
Eigen::Vector3d coord, vel, acc;
Eigen::VectorXd poly1d, t, polyv, polya;
Eigen::Vector3i index;
Eigen::MatrixXd Tm(4, 4);
Tm << 0, 1, 0, 0, 0, 0, 2, 0, 0, 0, 0, 3, 0, 0, 0, 0;
/* ----------前进轨迹检查 forward checking of trajectory ---------- */
double t_delta = t_d / 10;
for (double time = t_delta; time <= t_d; time += t_delta) {
t = Eigen::VectorXd::Zero(4);
for (int j = 0; j < 4; j++) t(j) = pow(time, j);
for (int dim = 0; dim < 3; dim++) {
poly1d = coef.row(dim);
coord(dim) = poly1d.dot(t);
vel(dim) = (Tm * poly1d).dot(t);
acc(dim) = (Tm * Tm * poly1d).dot(t);
if (fabs(vel(dim)) > max_vel_ || fabs(acc(dim)) > max_acc_) {
// cout << "vel:" << vel(dim) << ", acc:" << acc(dim) << endl;
// return false;
}
}
if (coord(0) < origin_(0) || coord(0) >= map_size_3d_(0) ||
coord(1) < origin_(1) || coord(1) >= map_size_3d_(1) ||
coord(2) < origin_(2) || coord(2) >= map_size_3d_(2)) {
return false;
}
// if (edt_environment_->evaluateCoarseEDT(coord, -1.0) <= margin_) {
if (collision_detection_->minObstacleDistance(coord) <=
margin_) {
return false;
}
if (pointHasGlobalCollision(coord)) {
return false;
}
}
coef_shot_ = coef;
t_shot_ = t_d;
is_shot_succ_ = true;
return true;
}
(4)节点扩张、节点剪枝流程
这个过程就是A*搜索的套路,如步骤三所示
1.节点扩张
根据对输入、时间的离散进行扩展得到tmp临时节点,首先判断节点是否已经被扩展过,是否与当前节点在同一个节点,检查速度约束,检查碰撞,都通过的话,就计算当前节点的g_score以及f_score. 其中的state transit函数即通过前向积分得到扩展节点的位置和速度
.
2.节点剪枝
首先判断当前临时扩展节点与current node的其他临时扩展节点是否在同一个voxel中,如果是的话,就要进行剪枝。要判断当前临时扩展节点的fscore是否比同一个voxel的对比fscore小,如果是的话,则更新这一Voxel节点为当前临时扩展节点。【防盗标记–盒子君hzj】
如果不剪枝的话,则首先判断当前临时扩展节点pro_node是否出现在open集中,如果是不是的话,则可以直接将pro_node加入open集中。【防盗标记–盒子君hzj】如果存在于open集但还未扩展的话,则比较当前临时扩展节点与对应VOXEL节点的fscore,若更小,则更新voxel中的节点。
需要进行说明的是,在Fast planner的实现中,open集是通过两个数据结构实现的,一个队列用来存储,弹出open集中的节点。另一个哈希表NodeHashtable 用来查询节点是否已经存在于open集中。而判断一个节点是否存在于close set中,【防盗标记–盒子君hzj】则是通过Nodehashtable 与nodestate来决定的,如果nodeState 是 InCloseSet, 且存在于NodeHashtable, 则说明该节点已经被扩展过了,存在于close set中
7、总结
啃这个Kinodynamic A_star算法,建议先啃一啃高飞fast_planner那篇论文,把理论打好,如果还是比较迷,就先看Dijksta、再看A_star、再看hybrid A_star 三个的流程,因为往上资料比较多,再看这个Kinodynamic A_star算法,流程已经很相像了。如果。。。不没有如果了~【防盗标记–盒子君hzj】
8、参考资料
网站
https://blog.csdn.net/weixin_42284263/article/details/119204964
https://github-wiki-see.page/m/amov-lab/Prometheus/wiki/%E4%BD%BF%E7%94%A8FastPlanner%E8%BF%9B%E8%A1%8C%E8%BD%A8%E8%BF%B9%E4%BC%98%E5%8C%96
论文
Trajectory Replanning for Quadrotors Using Kinodynamic Search and Elastic Optimization
Robust and Efficient Quadrotor Trajectory Generation for Fast Autonomous Flight
Robust Real-time UAV Replanning Using Guided Gradient-based Optimization and Topological Paths
6.Kinodynamic RRT*算法
(1)Kinodynamic-RRT*的目的
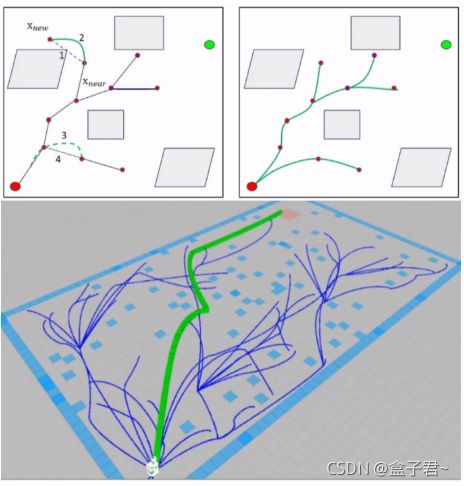
Kinodynamic-RRT*解决路径连接满足起点和终点的两个状态(位置、朝向、速度、加速度)最优控制的问题【如阿克曼模型不能直接横向平移,要纵向前进的时候才有横向平移】,【防盗标记–盒子君hzj】同时规划出来一条曲线路径可以绕开障碍物
(2)Kinodynamic-RRT*基本思路
RRT类算法(启发方向) 【只是和hybird A*的路径探索部分不一样而已】
(3)Kinodynamic-RRT*伪代码

核心步骤
(1)How to “Sample”
状态空间扩展,系统变量包含位置和速度
需要在整个状态空间里进行采样,因为考虑了动力学,因此不能仅仅采样位置p(x,y,z),也要进行速度的采样v,进而得到【防盗标记–盒子君hzj】
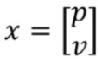
(2)How to define “Near”

如果没有运动约束,可以使用欧几里得距离或曼哈顿距离。
而在有运动约束的状态空间中,引入最优控制。
如果引入最优控制,我们可以得到状态间转移的代价函数。
通常考虑能量与时间最优,如果从一种状态转移到另一种状态的成本很小,则两种状态是接近的。(注意,如果反向转移,成本可能不同),如果我们知道到达时间(τ \tauτ)和控制策略u ( t ) u\left( t \right)u(t)的转移,我们可以计算成本。这些都是经典的最优控制解。
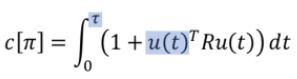


2)通过启发式公式寻找最近的节点“Near”,【防盗标记–盒子君hzj】再通过BVP和OBVP的方法连接两个节点
(3) How to “ChooseParent”
现在如果我们对一个随机状态进行抽样,我们就可以从树中的这些状态节点计算出控制策略和到抽样状态代价,选择一个以最小的成本和检查(x ( t ) x(t)x(t)]和(u ( t ) u(t)u(t)范围。
如果没有找到合格的父节点,则对另一个状态进行取样
(4)How to find near nodes efficiently


(5)How to “Rewire”

(4)参考资料
Kinodynamic-RRT*论文参考
Kinodynamic RRT*: Optimal Motion Planning for Systems with Linear Differential Constraints
Kinodynamic-RRT*视频展示
https://www.bilibili.com/video/BV1H64y1q7YS?spm_id_from=333.999.0.0
https://www.youtube.com/watch?v=RB3g_GP0-dU
https://blog.csdn.net/qq_37087723/article/details/113846316
.
.
三、采样的方法
1.在gridmap地图上构建一张图(graph)的思想
一、方法一:通过离散控制空间进行采样的方法【control space search】
【正向方法–以车当前控制状态为起点探索车可执行的路径】
(1)算法步骤
0)步骤0:栅格地图的4/8/16连接进行控制状态空间的离散【防盗标记–盒子君hzj】
【控制状态空间的方法】->【图搜索的方法】
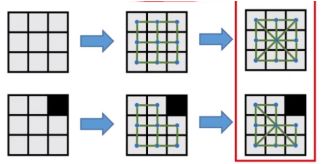
1)步骤一:建立机器人的模型【模型用状态方程表示】

其中s是机器人的当前状态(s可以包含x,y及其速度),u是机器人的控制输入
2)步骤二:清楚机器人的初始状态s0
3)步骤三:通过选择多个不同的控制输入量u与合适的控制周期T,【防盗标记–盒子君hzj】可以正向模拟仿真出机器人多条下一步的路径(状态s),最后选择一条符合约束的,代价最低的一条路径
【核心思想:给定多个采样的控制量u【控制量是有限幅的】 -> 模拟规划多条路径后选择一条 -> 正解机器人最终状态】
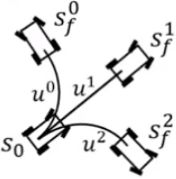
(2)算法优点
这种规划方法比较容易实现,知道机器人的模型就可以正解出多条轨迹
(3)算法缺点
(1)这种规划方法的控制量输入是随机的,没有到达目标点任务导向性的,【防盗标记–盒子君hzj】发散性的去搜索的,因此规划的效率较低
(2)这种规划方法的规划出来的路径比较集群,不能很好的覆盖到实际的场景,容易出现一条路径不可行是其他候选的路径也不可行的情况
(4)无人车的离散控制空间采样方法举例–DWA
基本思路:
先建立车底盘的动力学模型,再离散化车底盘的控制量(给不同方向的方向盘打角和油门大小),从而得到车的不同行驶轨迹
无人车的状态假设为:
无人车的控制输入假设为:

得到的无人车的状态方程为:

给定无人机的初始速度为(直往前走):
通过离散化速度输入,得到再控制周期T的无人机运动轨迹
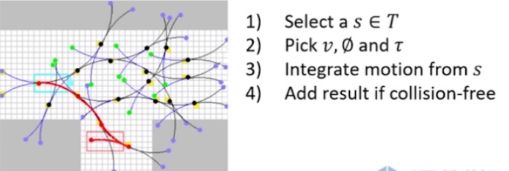
(5)无人机的离散控制空间采样方法举例
无人机的状态假设为:

无人机的控制输入假设为:
得到的无人机的状态方程为:
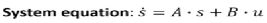
其中
给定无人机的初始速度为:
通过离散化加速度输入,得到再控制周期T的无人机运动轨迹如下:
无人机的运动轨迹可以通过状态转移方程计算得到:(状态转移方程包括了零输入响应和零状态响应两个部分)
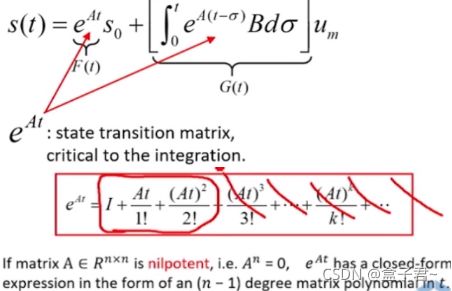
二、方法二:通过离散状态空间进行采样的方法【state space search】
【反向方法–以环境当前空间状态为起点探索车可执行的路径】
(1)算法步骤
(0)步骤0:PRM随机均匀采样进行状态空间的离散【防盗标记–盒子君hzj】
离散状态空间采样的方法当然也可以不使用PRM,举个例子用来在状态空间采样而已
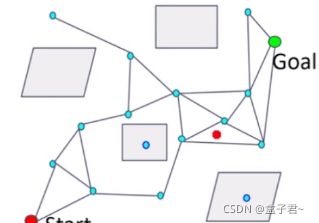
1)步骤一:建立机器人的模型【模型用状态方程表示】
其中s是机器人的当前状态(s可以包含x,y及其速度),u是机器人的控制输入
2)步骤二:清楚机器人的初始状态s0
3)步骤三:通过先确定机器人目标的状态Sf,再找到一条连接起点和目标点的路径,进而确定控制量u与控制周期T
【核心思想:给定多个采样的机器人最终状态 -> 探索规划多条路径后选择一条 -> 反解控制量u】
3.1)lattice graph生成图的方法
3.2)给定起始状态和最终状态,反解出可行轨迹【较核心,当然反解的方法也不止下面几种】
方法一:Boundary Value Problem(BVP)边界值的方法
【本质是解一个高维的线性方程A=BX–待定系数法求解】【防盗标记–盒子君hzj】
(1)目的:给定起始状x(0)=a 和最终状态x(T)=b,反解出可行轨迹x(t)

(2)步骤
1)假设可行轨迹可以用5阶的多项式函数进行拟合【当然可以用其他函数拟合】
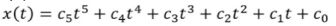
2)给定起始值和最终值的边界条件

3)通过待定系数法求解高维的线性方程B=AX【把C1~C5都解出来即可以得到可行轨迹的表达式】

方法二:Optimal Boundary Value Problem (OBVP)最优边界值方法
【本质是通过优化的方法进行轨迹反解–极小值原理(minimun principle)求解】【防盗标记–盒子君hzj】
(1)论文参考
Optimal Rough Terrain Trajectory Generation for Wheeled Mobile Robots, Thomas M. Howard Alonzo Kelly
(2)步骤
1)建模Modelling

2)通过优化的方法反解

其中:

3.3)给定可行轨迹,反解控制量u的方法
(1)纯跟踪算法的(pure_puresuit)
(2)MPC的方法
(2)算法优点
这种规划方法有比较好的目标点任务导向的,效率比较高
(3)算法缺点
这种规划方法需要根据起始点和目标点反解轨迹、【防盗标记–盒子君hzj】控制量u和控制周期T,相对控制空间control lattice search的方法来说没有那么容易实现。当然反解的方法也有很多
…
.
.
.
三、control space search和state lspace search两种算法的对比
放图就懂了~
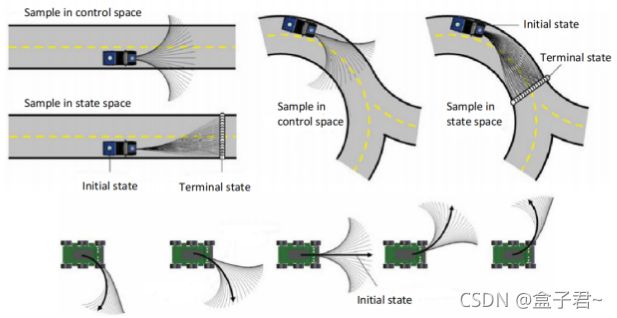
总结
采样方式:采样可以分为全局采样和局部采样,全局采样一般如PRM,局部采样一般还分为基于状态空间采样与基于控制空间采样

参考资料
论文参考
State Space Sampling of Feasible Motions for High-Performance Mobile Robot Navigation in Complex Environments, Thomas M. Howard, Colin J. Green, and Alonzo Kelly
2.Rapidly exploring Random Trees(RRT)类算法
(1)基于采样的普通路径规划算法–RRT(Rapidly Exploring Random Tree)
1.RRT图例
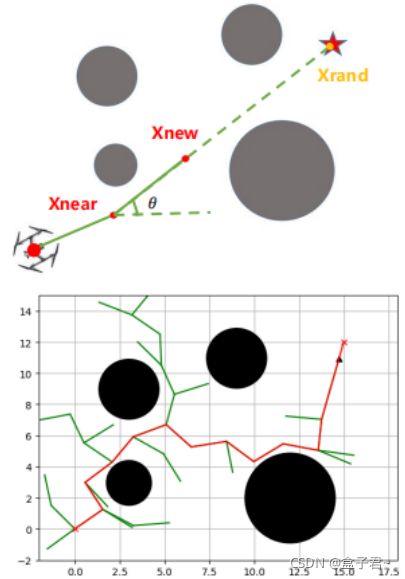
2.RRT原理
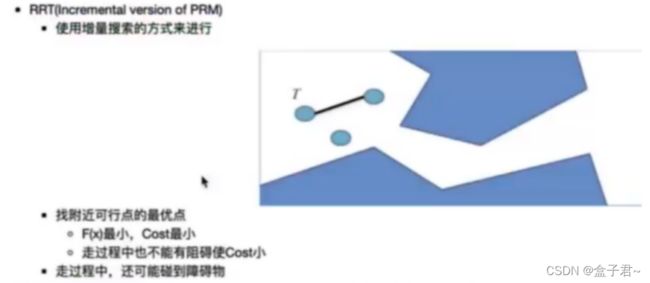

这是一种搜索算法,其实在采集样本的基础上进行路径规划,【防盗标记–盒子君hzj】一般适用于三维空间的目标搜寻。其设计原理是将空间中的某点作为起始点,然后规定一定原则,在原则约束下以起始点来确定一个新的节点,重复直至找到目标终止点。
点到直线的距离:
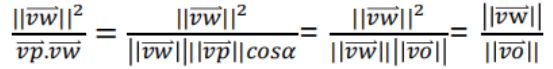
采样的方法和PRM类似,但是RRT的回溯搜索的方法是(盲目–改进版本)从自身节点起进行扩展的
3.RRT伪代码

(1)输入:地图、起始点、终止点
(2)输出:从起始点到终止点的路径
(3)核心关键函数实现
1)采样函数
2)Nearest函数
3)Collision-checking函数
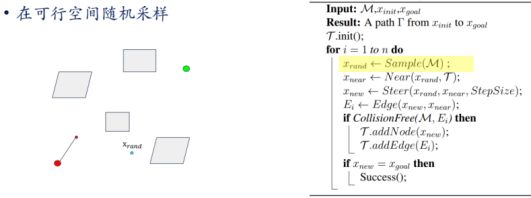

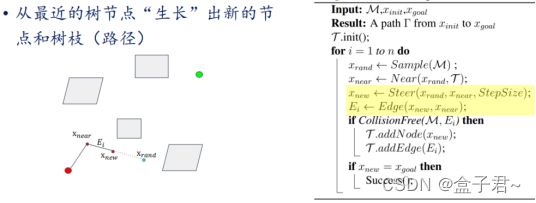
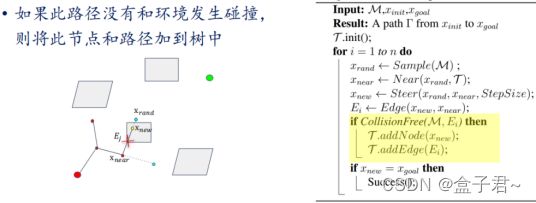
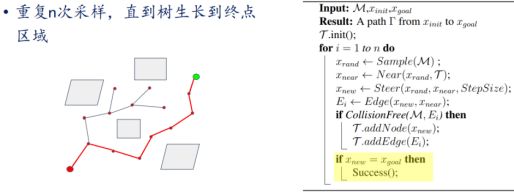
算法规程演示动图(大概能看出RRT效果)
https://www.youtube.com/watch?v=pOFtvZ_qVsA
4.RRT总结
(1)优点
快速随机树算法是一种较为迅捷搜索的方式,增量式的构建树其优点明显,主要体现在针对性的找一条从起点到终点的路径其较强较快的搜索能力,【防盗标记–盒子君hzj】并且运用快速拓展随机树的路径规划对路径运行环境没有限制要求。
(2)缺点
1)轨迹不是平滑的,不能够满足无人车运动的需求
2)规划出来的路径不是最短甚至不是最优的,只是达到了目标而已(折线路径不太满足动力学)
3)偏向于处理静态障碍物的问题,在动态环境中会有一定局限性。【防盗标记–盒子君hzj】
4)狭窄的环境下,RRT效果不太好
5.RRT实现的改进【节点搜索改进、节点连接改进】
(1)kd-tree算法(这个方法提高了RRT的节点搜索的效率)
节点搜索方向,Xrand -> Xnear -> Xnew
(2)Bidirection RRT/RRT Connect算法【防盗标记–盒子君hzj】(这个方法提高了RRT的节点连接的效率)
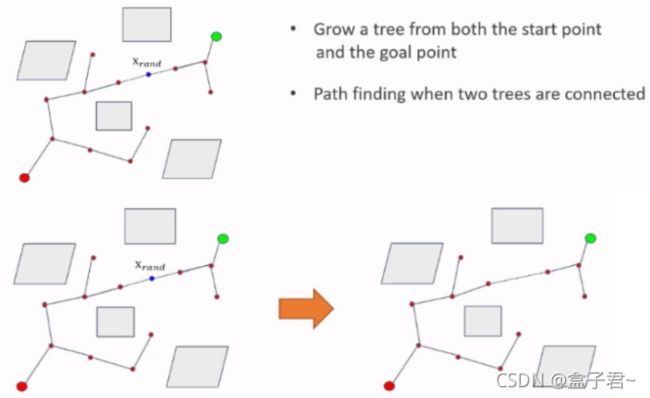
(2)基于采样的最优路径规划算法–RRT*(Rapidly Exploring Random Tree*)
1.RRT*的目的
RRT*解决了RRT生成的路径不是最优的问题,找到一条最优的路径
2.RRT*算法原理
通过把连续的空间离散化,在离散空间中撒一些点(Xrand),建立一个从起始点到目标点的树,在起始点开始,向目标点的方向,去盲目探索,【防盗标记–盒子君hzj】从树上找到离这些点(Xrand)最近的一些点(Xnear),确定下一个采样点(Xnew),只要不碰到障碍物就行,每次探索一小步,直到到达目标点,再对该路径进行改进(rewrite()函数剪枝)【好像一个盲人,靠着气味寻找目标一样】
(1)当前节点重新选择父节点
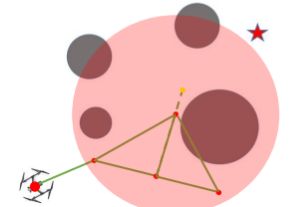
(2)范围内的节点重新连接(rewire)
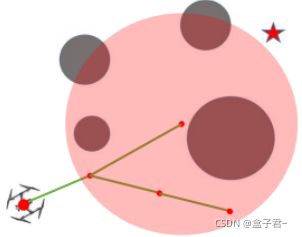
3.RRT*伪代码

4.RRT算法演示动图(大概能看出RRT效果)
https://www.youtube.com/watch?v=YKiQTJpPFkA
(3)RRT算法 VS RRT*算法
一张对比图说明问题
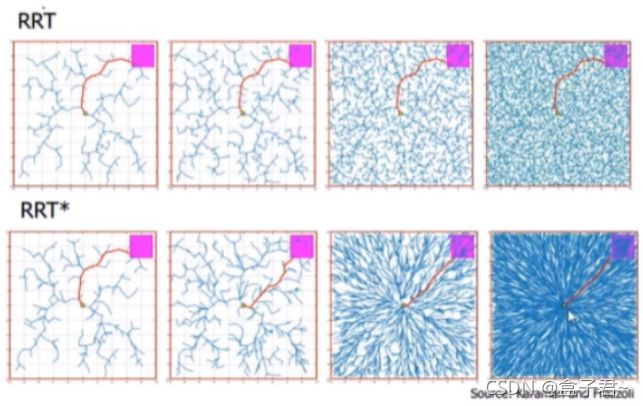
RRT、RRT*、informed RRT*是一个不断改进的路径搜索算法,【防盗标记–盒子君hzj】RRT算法的基本原理,包括Sampling、Nearest、Collision-Checking
(4)偏重于得到路径后的优化–informed RRT*算法

1.informed RRT*目的
informed RRT*得到可行路径后,把轨迹优化的范围限制在了一个椭圆内,【防盗标记–盒子君hzj】从而减少了很多优化的没必要的算力,改进采样方式提高路径搜索的效率(树的拓展效率)
2.informed RRT*算法原理
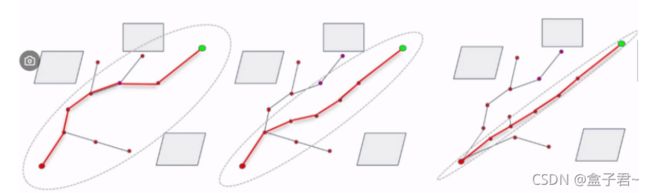
3.informed RRT*伪代码

4.informed RRT*缺点
(1)只能处理静态障碍物的问题
(2)轨迹还是不够平滑,扭来扭曲的,导数是平滑了但是数值变化也很大
5.RRT* VS informed RRT*
一张图说明优化的效果

(5)Cross-entropy motion planning算法
1.算法步骤
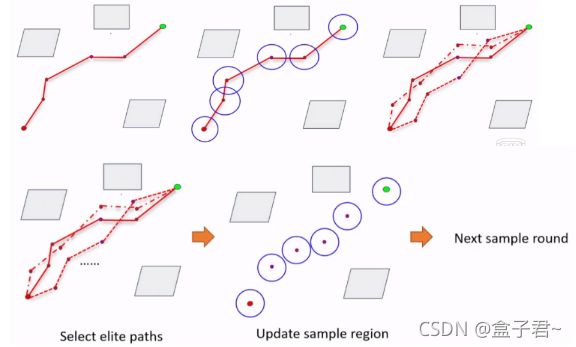
当一个路径(折线)生成之后,在路径的节点处进行采样【防盗标记–盒子君hzj】,经过采样之后就能得到很多路径,对每条路径对应的节点取均值作为新路径的节点,进而得到新的更平滑的路径;重复迭代上诉过程,直到得到符合要求的优化路径
2.论文参考
Cross-entropy motion planning、
3.算法效果
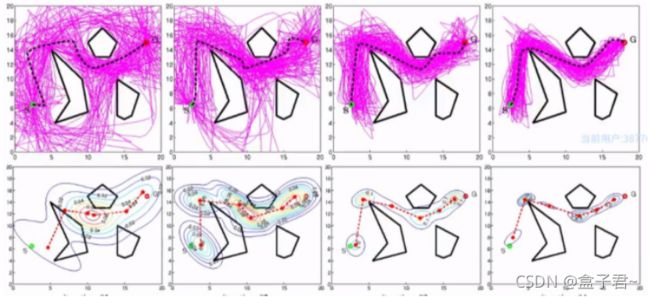
(6)RRT算法其他的变种
综述
[1] An Overview of the Class of Rapidly-Exploring Random Trees
[2]http://msl.cs.uiuc.edu/rrt/
(0)Anytime-RRT*算法
论文Anytime Motion Planning using the RRT∗
(1)Lower Bound Tree RRT (LBTRRT)
https://arxiv.org/pdf/1308.0189.pdf
(2)Sparse Stable RRT
http://pracsyslab.org/sst_software
(3)Transition-based RRT (T-RRT)
http://homepages.laas.fr/jcortes/Papers/jaillet_aaaiWS08.pdf
(4)Vector Field RRT
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=6606360
(5)Parallel RRT (pRRT)
https://robotics.cs.unc.edu/publications/Ichnowski2012_IROS.pdf
(6)Dynamic RRT
(7)RRT-Connect
(8)RRT-smart
更多的算法github
https://github.com/zychaoqun
https://zhuanlan.zhihu.com/p/133224593
总结
(1)轨迹不是平滑的,扭来扭曲的,导数是平滑了但是数值变化也很大,不能够满足无人车运动的需求,需要后端的轨迹优化
(2)大多数规划出来的路径不是最短甚至是最优的,只是达到了目标而已【防盗标记–盒子君hzj】
(3)大多数只能处理静态障碍物的问题
但是搜索的速度是非常快的!!
参考资料
https://github.com/RoboJackets/rrt
https://github.com/jeshoward/turtlebot_rrt
https://github.com/nikhilchandak/Rapidly-Exploring-Random-Trees
https://github.com/naiveHobo/RRTPlanner
3.概率路线图probabilistic Roadmap搜索
(1)PRM算法泛化过程

1.概率路线图
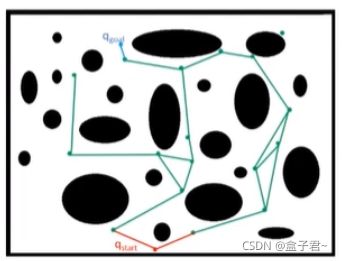
2.采样构建阶段


步骤如下:
(1)在机器人配置空间(C-Space)中均匀的撒上一堆采样点(N个点) 【防盗标记–盒子君hzj】
(2)删除一些与障碍物发生碰撞的采样点
(3)使用线把邻近的点连接起来(连接的线符合一定的长度要求的,还有其他高级的准则)
(4)删除和环境碰撞的路径段
学习链接
https://en.wikipedia.org/wiki/Probabilistic_roadmap
https://www.youtube.com/watch?v=8Dln3sS_p4Q
3.概率图搜索阶段
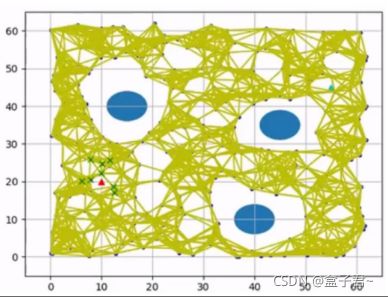

搜索阶段
在构建出的路标连接图中搜索一条起 点到终点的路径(使用Dijkstra或者 A算法 )
路标图可近似看作栅格图,可利用路标图进行多次搜索(multiquery)
使
用A和Dijkstra等图搜索的算法搜索一条从起点到终点的路径【防盗标记–盒子君hzj】
(2)lazy PRM懒惰障碍物检测算法过程(一种高效的算法)
步骤
(1)先均匀撒点,再仅仅根据距离准则把每个节点有连接起来(不考虑碰撞)
(2)根据节点图找到从起点到终点的最优路径(该路径可能会与障碍物发生碰撞)
(3)从规划出来的最优路径中删除与障碍物发生碰撞的部分节点和线
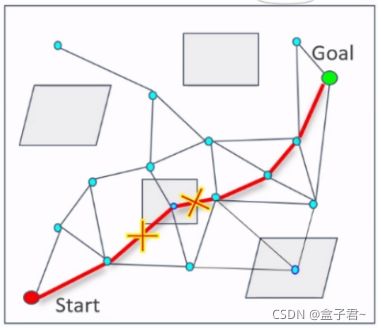
(4)再原有删除了部分节点和线的最优路径的基础上,【防盗标记–盒子君hzj】重新规划一条可行路径

(3)总结
核心思想:
随机撒点找到目标点,找连接最优的节点得到最优路径
优点:
用相对少量的路标点和局部路径来构建一个连接图以得到可行区域的连接情况,计算量少,搜索出来的路径具有整体的完备性
缺点:
没有太把精力放在基于当前状况去做路径搜索,采样的方法在第一步采样的时候就就决定了路径的最高绝对精度了
(4)参考资料
https://blog.csdn.net/Travis_X/article/details/114905475
https://github.com/idincern/prm_sim
https://github.com/dknetz/prm_planner
https://github.com/nishadg246/Probabilistic-Roadmap
4.
四、地图的方法
1.维诺图Voronoi的生成–避障路径Voronoi Planner
一、生成与更新代价地图costmap的方式
生成代价地图costmap的方式是对占据栅格地图occmap的障碍物进行边界膨胀
.
.
二、生成与更新Distance Map(DM)的方式
图1A是论文算法的输入——已知的二值占据栅格地图,其中外围的黑色是地图外部区域,中间的黑色是障碍物,白色是可行驶区域。因为有边界和障碍物的存在,使得内部白色栅格与最近障碍物点的距离会减小(初始化为正无穷),因此要从障碍物栅格开始,逐步向外扩散更新,计算新的最近障碍物坐标与距离,反映为图1B-D中灰色逐步扩展,距离越近颜色越深。当所有栅格都被更新后,DM建立完成。


当图1中的障碍物消失、新的障碍物出现时(图2B),相应的二值占据栅格地图会被更新,进而触发DM和GVD的更新。因为旧的障碍物(记为P)消失,那么周围以P为最近障碍物的栅格,暂时没有最近障碍物,其保存的最近障碍物距离也会被置为无效值(或正无穷,或初始值),所以这些栅格的状态更新是一个距离增大(raise)的过程。
类似的,因为新的障碍物(记为Q)出现,那么Q周围的栅格,其保存的最近障碍物距离被重新计算(可能是到Q的距离),所以这些栅格的状态更新是一个距离减小(lower)的过程。
当raise和lower的过程相遇,lower处理过的栅格不会受影响,但是raise处理过的栅格,这时就要考虑新出现的Q对其的影响,就要重新计算最近障碍物(可能是Q)的距离,所以raise过程结束,转变为lower过程(图2C)。
当raise和lower都不再进展,DM更新结束。
障碍物的移动,也可以分解为原位置的障碍物消失、新位置的障碍物出现的过程。因为更新不会遍历所有的栅格(比如最外层的栅格,其最近的障碍物一定是地图边界,无需更新也不会更新),所以这是一个增量更新的过程,访问栅格少,实时性好。
.
三、生成与更新Voronoi地图的方式
【二值OCC占据地图生成->距离地图DM->Voronoi地图】
1、Voronoi数据结构
// queues
//保存待考察的栅格
BucketPrioQueue<INTPOINT> open_;
//保存待剪枝的栅格
std::queue<INTPOINT> pruneQueue_;
//保存预处理后的待剪枝的栅格
BucketPrioQueue<INTPOINT> sortedPruneQueue_;
//保存移除的障碍物曾占据的栅格
std::vector<INTPOINT> removeList_;
//保存增加的障碍物要占据的栅格
std::vector<INTPOINT> addList_;
//保存上次添加的障碍物覆盖的栅格
std::vector<INTPOINT> lastObstacles_;
// maps
int sizeY_;
int sizeX_;
dataCell** data_; //保存了每个栅格与最近障碍物的距离、最近障碍物的坐标、是否Voronoi点的标志
bool** gridMap_; //true是被占用,false是没有被占用
bool allocatedGridMap_; //是否为gridmap分配了内存的标志位
2、DM和GVD的栅格用dataCell二维数组表示,gridMap_是输入的二值占据栅格地图
struct dataCell {
float dist;
char voronoi; //State的枚举值
char queueing; //QueueingState的枚举值
int obstX;
int obstY;
bool needsRaise;
int sqdist;
};
使用到的枚举型状态量如下,最终state是voronoiKeep 的点,便是Voronoi的边上的点,组成了Voronoi图。
typedef enum {voronoiKeep=-4, freeQueued = -3, voronoiRetry=-2, voronoiPrune=-1,
free=0, occupied=1} State;
//下面这几个枚举状态没搞懂
typedef enum {fwNotQueued=1, fwQueued=2, fwProcessed=3, bwQueued=4,
bwProcessed=1} QueueingState;
typedef enum {invalidObstData = SHRT_MAX/2} ObstDataState;
//表示剪枝操作时栅格的临时状态
typedef enum {pruned, keep, retry} markerMatchResult;
3、Voronoi地图数据初始化
//输入二值地图gridmap,根据元素是否被占用,更新data_
void DynamicVoronoi::initializeMap(int _sizeX, int _sizeY, bool** _gridMap) {
gridMap_ = _gridMap;
initializeEmpty(_sizeX, _sizeY, false);
for (int x=0; x<sizeX_; x++) {
for (int y=0; y<sizeY_; y++) {
if (gridMap_[x][y]) { //如果gridmap_中的(x,y)被占用了
dataCell c = data_[x][y];
if (!isOccupied(x,y,c)) { //如果c没有被占用,即data_中的(x,y)没被占用,需要更新
bool isSurrounded = true; //如果在gridmap_中的邻居元素全被占用
for (int dx=-1; dx<=1; dx++) {
int nx = x+dx;
if (nx<=0 || nx>=sizeX_-1) continue;
for (int dy=-1; dy<=1; dy++) {
if (dx==0 && dy==0) continue;
int ny = y+dy;
if (ny<=0 || ny>=sizeY_-1) continue;
//如果在gridmap_中的邻居元素有任意一个没被占用(就是障碍物边界点)
if (!gridMap_[nx][ny]) {
isSurrounded = false;
break;
}
}
}
if (isSurrounded) { //如果九宫格全部被占用
c.obstX = x;
c.obstY = y;
c.sqdist = 0;
c.dist=0;
c.voronoi=occupied;
c.queueing = fwProcessed;
data_[x][y] = c;
} else {
setObstacle(x,y); //不同之处在于:将(x,y)加入addList_
}
}
}
}
}
}
initializeEmpty()主要清空历史数据,为数组开辟内存空间,并赋初始值,将所有栅格设置为不被占用。然后,当gridMap_中的某栅格被占用,而data_中的该栅格却没被占用时,表示环境发生了变化,才需要更新栅格的信息。因为这是初始化操作,不会出现gridMap_中的某栅格不被占用、而data_中的该栅格却被占用的情况。如果一个栅格的8个邻居栅格全被占用,说明该栅格在障碍物内部,只需简单赋值,不会触发lower过程。如果8个邻居栅格没有全被占用,说明该栅格在障碍物边界上,调用setObstacle(),暂存会触发DM更新的点。
4、添加障碍物
//要同时更新gridmap和data_
void DynamicVoronoi::occupyCell(int x, int y) {
gridMap_[x][y] = 1; //更新gridmap
setObstacle(x,y);
}
//只更新data_
void DynamicVoronoi::setObstacle(int x, int y) {
dataCell c = data_[x][y];
if(isOccupied(x,y,c)) { //如果data_中的(x,y)被占用
return;
}
addList_.push_back(INTPOINT(x,y)); //加入addList_
c.obstX = x;
c.obstY = y;
data_[x][y] = c;
}

5、移除障碍物
//要同时更新gridmap和data_
void DynamicVoronoi::clearCell(int x, int y) {
gridMap_[x][y] = 0; //更新gridmap
removeObstacle(x,y);
}
//只更新data_
void DynamicVoronoi::removeObstacle(int x, int y) {
dataCell c = data_[x][y];
if(isOccupied(x,y,c) == false) { //如果data_中的(x,y)没有被占用,无需处理
return;
}
removeList_.push_back(INTPOINT(x,y)); //将(x,y)加入removeList_
c.obstX = invalidObstData;
c.obstY = invalidObstData;
c.queueing = bwQueued;
data_[x][y] = c;
}

commitAndColorize()分别处理addList_ 和 removeList_ 中的栅格,将它们加入open_优先队列。commitAndColorize()运行后,才算完成了图3-4所列的添加、移除障碍物。接下来才会更新DM。
//将发生状态变化(占用<-->不占用)的元素加入open_优先队列
void DynamicVoronoi::commitAndColorize(bool updateRealDist) {
//addList_和removeList_中是触发Voronoi更新的元素,因此都要加入open_
// ADD NEW OBSTACLES
//addList_中都是障碍物边界点
for (unsigned int i=0; i<addList_.size(); i++) {
INTPOINT p = addList_[i];
int x = p.x;
int y = p.y;
dataCell c = data_[x][y];
if(c.queueing != fwQueued){
if (updateRealDist) {
c.dist = 0;
}
c.sqdist = 0;
c.obstX = x;
c.obstY = y;
c.queueing = fwQueued; //已加入open_优先队列
c.voronoi = occupied;
data_[x][y] = c;
open_.push(0, INTPOINT(x,y)); //加入open_优先队列,加入open_的都是要更新的
}
}
// REMOVE OLD OBSTACLES
//removeList_中是要清除的障碍物栅格
for (unsigned int i=0; i<removeList_.size(); i++) {
INTPOINT p = removeList_[i];
int x = p.x;
int y = p.y;
dataCell c = data_[x][y];
//removeList_中对应的元素在data_中已经更新过,解除了占用
//如果这里又出现了该元素被占用,说明是后来加入的,这里不处理
if (isOccupied(x,y,c) == true) {
continue; // obstacle was removed and reinserted
}
open_.push(0, INTPOINT(x,y)); //加入open_优先队列
if (updateRealDist) {
c.dist = INFINITY;
}
c.sqdist = INT_MAX;
c.needsRaise = true; //因为清除了障碍物,最近障碍物距离要更新-增加
data_[x][y] = c;
}
removeList_.clear();
addList_.clear();
}
6、更新障碍物
//用新的障碍物信息替换旧的障碍物信息
//如果points为空,就是清除障碍物;
//初始时lastObstacles_为空,第一次调用exchangeObstacles()就是纯粹的添加障碍物
void DynamicVoronoi::exchangeObstacles(std::vector<INTPOINT>& points) {
for (unsigned int i=0; i<lastObstacles_.size(); i++) {
int x = lastObstacles_[i].x;
int y = lastObstacles_[i].y;
bool v = gridMap_[x][y];
if (v) { //如果(x,y)被占用了,不处理,怀疑这里逻辑反了。
continue; //要移除旧的障碍物,这里应该是(!v)表示没被占用就不处理,占用了就移除
}
removeObstacle(x,y);
}
lastObstacles_.clear();
for (unsigned int i=0; i<points.size(); i++) {
int x = points[i].x;
int y = points[i].y;
bool v = gridMap_[x][y];
if (v) { //如果(x,y)被占用了,不处理。否则,添加占用
continue;
}
setObstacle(x,y);
lastObstacles_.push_back(points[i]);
}
}
exchangeObstacles()用来使用新的障碍物替换旧的障碍物。当地图刚刚初始化,exchangeObstacles()第一次调用时,因为没有旧的障碍物需要移除,这就是纯粹的添加障碍物。当exchangeObstacles()的输入参数为空时,因为没有新的障碍物要添加,这就是纯粹的移除障碍物。所以,外界环境的变化通过exchangeObstacles()传入,这是更新DM的触发点。
7、更新DM图
这是论文和代码的核心环节,主要分为lower()和raise() 2部分

.

.

void DynamicVoronoi::update(bool updateRealDist) {
//将发生状态变化(占用<-->不占用)的元素加入open_优先队列
commitAndColorize(updateRealDist);
while (!open_.empty()) {
INTPOINT p = open_.pop();
int x = p.x;
int y = p.y;
dataCell c = data_[x][y];
if(c.queueing==fwProcessed) {
continue;
}
if (c.needsRaise) {
// RAISE
//2层for循环,考察8个邻居栅格
for (int dx=-1; dx<=1; dx++) {
int nx = x+dx;
if (nx<=0 || nx>=sizeX_-1) continue;
for (int dy=-1; dy<=1; dy++) {
if (dx==0 && dy==0) continue;
int ny = y+dy;
if (ny<=0 || ny>=sizeY_-1) continue;
dataCell nc = data_[nx][ny];
//nc有最近障碍物 且 不raise
if (nc.obstX!=invalidObstData && !nc.needsRaise) {
//如果nc原来的最近障碍物消失了
if(!isOccupied(nc.obstX, nc.obstY, data_[nc.obstX][nc.obstY])) {
open_.push(nc.sqdist, INTPOINT(nx,ny));
nc.queueing = fwQueued; //fwQueued表示刚加入open_排队?
nc.needsRaise = true; //需要raise,并清理掉原来的最近障碍物信息
nc.obstX = invalidObstData;
nc.obstY = invalidObstData;
if (updateRealDist) {
nc.dist = INFINITY;
}
nc.sqdist = INT_MAX;
data_[nx][ny] = nc;
} else { //如果nc原来的最近障碍物还存在
if(nc.queueing != fwQueued){
open_.push(nc.sqdist, INTPOINT(nx,ny));
nc.queueing = fwQueued;
data_[nx][ny] = nc;
}
}
}
}
}
c.needsRaise = false;
c.queueing = bwProcessed; //bwProcessed表示8个邻居元素raise处理完毕?
data_[x][y] = c;
}
else if (c.obstX != invalidObstData &&
isOccupied(c.obstX, c.obstY, data_[c.obstX][c.obstY])) {
//c是被占据的
// LOWER
c.queueing = fwProcessed; //fwProcessed表示8个邻居元素lower处理完毕?
c.voronoi = occupied;
for (int dx=-1; dx<=1; dx++) {
int nx = x+dx;
if (nx<=0 || nx>=sizeX_-1) continue;
for (int dy=-1; dy<=1; dy++) {
if (dx==0 && dy==0) continue;
int ny = y+dy;
if (ny<=0 || ny>=sizeY_-1) continue;
dataCell nc = data_[nx][ny];
if(!nc.needsRaise) {
int distx = nx-c.obstX;
int disty = ny-c.obstY;
int newSqDistance = distx*distx + disty*disty;
//nc到c的最近障碍物 比 nc到其最近障碍物 更近
bool overwrite = (newSqDistance < nc.sqdist);
if(!overwrite && newSqDistance==nc.sqdist) {
//如果nc没有最近障碍物,或者 nc的最近障碍物消失了
if(nc.obstX == invalidObstData ||
isOccupied(nc.obstX, nc.obstY, data_[nc.obstX][nc.obstY]) == false){
overwrite = true;
}
}
if (overwrite) {
open_.push(newSqDistance, INTPOINT(nx,ny));
nc.queueing = fwQueued; //fwQueued表示加入到open_等待lower()?
if (updateRealDist) {
nc.dist = sqrt((double) newSqDistance);
}
nc.sqdist = newSqDistance;
nc.obstX = c.obstX; //nc的最近障碍物 赋值为c的最近障碍物
nc.obstY = c.obstY;
} else {
checkVoro(x,y,nx,ny,c,nc);
}
data_[nx][ny] = nc;
}
}
}
}
data_[x][y] = c;
}
}
updata()先调用了commitAndColorize(),将状态发生了翻转变化(占用变成不占用、不占用变成占用)的栅格加入open_优先队列,然后遍历open_中的元素,并调用checkVoro()判断其是否属于Voronoi图边上的点。
8、检查Voronoi的条件
void DynamicVoronoi::checkVoro(int x, int y, int nx, int ny,
dataCell& c, dataCell& nc){
if ((c.sqdist>1 || nc.sqdist>1) && nc.obstX!=invalidObstData) {
if (abs(c.obstX-nc.obstX) > 1 || abs(c.obstY-nc.obstY) > 1) {
//compute dist from x,y to obstacle of nx,ny
int dxy_x = x-nc.obstX;
int dxy_y = y-nc.obstY;
int sqdxy = dxy_x*dxy_x + dxy_y*dxy_y;
int stability_xy = sqdxy - c.sqdist;
if (sqdxy - c.sqdist<0) return;
//compute dist from nx,ny to obstacle of x,y
int dnxy_x = nx - c.obstX;
int dnxy_y = ny - c.obstY;
int sqdnxy = dnxy_x*dnxy_x + dnxy_y*dnxy_y;
int stability_nxy = sqdnxy - nc.sqdist;
if (sqdnxy - nc.sqdist <0) return;
//which cell is added to the Voronoi diagram?
if(stability_xy <= stability_nxy && c.sqdist>2) {
if (c.voronoi != free) {
c.voronoi = free;
reviveVoroNeighbors(x,y);
pruneQueue_.push(INTPOINT(x,y));
}
}
if(stability_nxy <= stability_xy && nc.sqdist>2) {
if (nc.voronoi != free) {
nc.voronoi = free;
reviveVoroNeighbors(nx,ny);
pruneQueue_.push(INTPOINT(nx,ny));
}
}
}
}
}
这段代码基本是复现图8的算法,不同之处在于,在检测(x,y)、(nx,ny)是否Voronoi备选点的同时,也把这2个点的各自8个邻居栅格也进行了检测,通过reviveVoroNeighbors()实现。通过检测的备选点加入到pruneQueue_ 中。因为还会对pruneQueue_ 中的元素进行剪枝操作,以得到精细准确的、单像素宽度的Voronoi边,pruneQueue_ 只是中间过程的存储容器,所以无需使用优先队列,只是普通的std::queue就可以。
图8中使用了6个判断条件,分别是:
第1条:s和n至少有一个不紧邻其obs,若都紧邻,无法判断s和n是不是GVD
第2条:n的最近obs是存在的,若不存在,无法判断s和n是不是GVD
第3条:s和n的最近obs是不同的,若相同,无法判断s和n是不是GVD
第4条:s的最近obs和n的最近obs不紧邻,若紧邻,则同属一个obs,无法判断s和n是不是GVD
第5-6条:属于GVD的点,一定是距周边obs最近的,所以倾向于选择距obs更近的点作为候选。

//将符合条件的(x,y)的邻居栅格也添加到需剪枝的Voronoi备选中
void DynamicVoronoi::reviveVoroNeighbors(int &x, int &y) {
for (int dx=-1; dx<=1; dx++) {
int nx = x+dx;
if (nx<=0 || nx>=sizeX_-1) continue;
for (int dy=-1; dy<=1; dy++) {
if (dx==0 && dy==0) continue;
int ny = y+dy;
if (ny<=0 || ny>=sizeY_-1) continue;
dataCell nc = data_[nx][ny];
if (nc.sqdist != INT_MAX && !nc.needsRaise &&
(nc.voronoi == voronoiKeep || nc.voronoi == voronoiPrune)) {
nc.voronoi = free;
data_[nx][ny] = nc;
pruneQueue_.push(INTPOINT(nx,ny));
}
}
}
}
9、剪枝
prune()的主要目的是将2个栅格宽度的Voronoi边精简为1个栅格宽度,分为2步,对应代码中的2个while()循环。
第1,遍历pruneQueue_,用图9中的模式去匹配每个元素,及该元素上下左右紧邻的4个栅格。若匹配成功,就加入sortedPruneQueue_,等待剪枝。这一步的目的是将被2条相距很近的Voronoi边包裹的单个栅格加入到备选中。
第2,遍历sortedPruneQueue_,用图10中的左侧2个模式或者右侧2个模式去匹配每个元素,匹配的过程由markerMatch()完成。若匹配的结果是pruned,该栅格被剪枝;keep,该栅格就是Voronoi图上的点;retry,将该栅格重新加入到pruneQueue_。注意,第1步完成后,pruneQueue_已经空了。如果sortedPruneQueue_第一次遍历完毕,会将pruneQueue_中的需要retry的元素转移到sortedPruneQueue_中,继续执行第2步的遍历,直到sortedPruneQueue_为空。
void DynamicVoronoi::prune() {
// filler
//先遍历pruneQueue_中的元素,判断是否要加入到sortedPruneQueue_,
//这一步的目的是合并紧邻的Voronoi边,将2条边夹着的栅格也设置为备选
//再遍历sortedPruneQueue_中的元素,判断其是剪枝、保留、重试。
while(!pruneQueue_.empty()) {
INTPOINT p = pruneQueue_.front();
pruneQueue_.pop();
int x = p.x;
int y = p.y;
//如果(x,y)是occupied,无需处理,不可能是Voronoi
if (data_[x][y].voronoi==occupied) continue;
//如果(x,y)是freeQueued,已经加入到sortedPruneQueue_,略过
if (data_[x][y].voronoi==freeQueued) continue;
data_[x][y].voronoi = freeQueued;
sortedPruneQueue_.push(data_[x][y].sqdist, p);
/* tl t tr
l c r
bl b br */
dataCell tr,tl,br,bl;
tr = data_[x+1][y+1];
tl = data_[x-1][y+1];
br = data_[x+1][y-1];
bl = data_[x-1][y-1];
dataCell r,b,t,l;
r = data_[x+1][y];
l = data_[x-1][y];
t = data_[x][y+1];
b = data_[x][y-1];
//文章只提了对待考察栅格判断是否符合模式,这里为什么要对待考察栅格的上下左右4个邻居
//栅格都判断呢?我认为判断模式的目的就是将Voronoi边夹着的、包裹的栅格置为备选,因为
//待考察栅格是备选了,才使得周围栅格可能会被Voronoi边包裹,所以才要逐一检查。
if (x+2<sizeX_ && r.voronoi==occupied) {
// fill to the right
//如果r的上下左右4个元素都!=occupied,对应文章的P38模式
// | ? | 1 | ? |
// | 1 | | 1 |
// | ? | 1 | ? |
if(tr.voronoi!=occupied && br.voronoi!=occupied &&
data_[x+2][y].voronoi!=occupied){
r.voronoi = freeQueued;
sortedPruneQueue_.push(r.sqdist, INTPOINT(x+1,y));
data_[x+1][y] = r;
}
}
if (x-2>=0 && l.voronoi==occupied) {
// fill to the left
//如果l的上下左右4个元素都!=occupied
if(tl.voronoi!=occupied && bl.voronoi!=occupied &&
data_[x-2][y].voronoi!=occupied){
l.voronoi = freeQueued;
sortedPruneQueue_.push(l.sqdist, INTPOINT(x-1,y));
data_[x-1][y] = l;
}
}
if (y+2<sizeY_ && t.voronoi==occupied) {
// fill to the top
//如果t的上下左右4个元素都!=occupied
if(tr.voronoi!=occupied && tl.voronoi!=occupied &&
data_[x][y+2].voronoi!=occupied){
t.voronoi = freeQueued;
sortedPruneQueue_.push(t.sqdist, INTPOINT(x,y+1));
data_[x][y+1] = t;
}
}
if (y-2>=0 && b.voronoi==occupied) {
// fill to the bottom
//如果b的上下左右4个元素都!=occupied
if(br.voronoi!=occupied && bl.voronoi!=occupied &&
data_[x][y-2].voronoi!=occupied){
b.voronoi = freeQueued;
sortedPruneQueue_.push(b.sqdist, INTPOINT(x,y-1));
data_[x][y-1] = b;
}
}
}
while(!sortedPruneQueue_.empty()) {
INTPOINT p = sortedPruneQueue_.pop();
dataCell c = data_[p.x][p.y];
int v = c.voronoi;
if (v!=freeQueued && v!=voronoiRetry) {
continue;
}
markerMatchResult r = markerMatch(p.x,p.y);
if (r==pruned) {
c.voronoi = voronoiPrune; //对(x,y)即c剪枝
}
else if (r==keep) {
c.voronoi = voronoiKeep; //对(x,y)即c保留,成为Voronoi的边
}
else {
c.voronoi = voronoiRetry;
pruneQueue_.push(p);
}
data_[p.x][p.y] = c;
//把需要retry的元素由pruneQueue_转移到sortedPruneQueue_
//这样可以继续本while()循环,直到pruneQueue_和sortedPruneQueue_都为空
if (sortedPruneQueue_.empty()) {
while (!pruneQueue_.empty()) {
INTPOINT p = pruneQueue_.front();
pruneQueue_.pop();
sortedPruneQueue_.push(data_[p.x][p.y].sqdist, p);
}
}
}
}
10、栅格模式匹配
观察图10的4个模式 ,很容易理解为什么这样设计,因为在这4个模式中,栅格s有非常重要的联结作用,不可或缺,否则Voronoi边就会断掉。因此,符合模式的栅格会被保留,不符合的被剪枝。
//根据(x,y)邻居栅格的连接模式,判断是否要对(x,y)剪枝
DynamicVoronoi::markerMatchResult DynamicVoronoi::markerMatch(int x, int y) {
// implementation of connectivity patterns
bool f[8];
int nx, ny;
int dx, dy;
int i=0;
//voroCount是对所有邻居栅格的统计,voroCountFour是对上下左右4个邻居栅格的统计
int voroCount=0;
int voroCountFour=0;
for (dy=1; dy>=-1; dy--) {
ny = y+dy;
for (dx=-1; dx<=1; dx++) {
if (dx || dy) { //不考虑(x,y)点
nx = x+dx;
dataCell nc = data_[nx][ny];
int v = nc.voronoi;
//既不是occupied又不是voronoiPrune,即可能保留的栅格
bool b = (v<=free && v!=voronoiPrune);
f[i] = b;
if (b) {
voroCount++;
if (!(dx && dy)) { //对上下左右4个点
voroCountFour++;
}
}
i++;
}
}
}
// i和位置的对应关系如下:
// | 0 | 1 | 2 |
// | 3 | | 4 |
// | 5 | 6 | 7 |
//8个邻居栅格中最多有2个,上下左右只有1个可能保留的栅格
if (voroCount<3 && voroCountFour==1 && (f[1] || f[3] || f[4] || f[6])) {
return keep;
}
// 4-connected
// | 0 | 1 | ? | | ? | 1 | 0 | | ? | ? | ? | | ? | ? | ? |
// | 1 | | ? | | ? | | 1 | | 1 | | ? | | ? | | 1 |
// | ? | ? | ? | | ? | ? | ? | | 0 | 1 | ? | | ? | 1 | 0 |
//对应《Efficient Grid-Based Spatial Representations for Robot Navigation in
//Dynamic Environments》中的4-connected P14模式,旋转3次90度
if ((!f[0] && f[1] && f[3]) || (!f[2] && f[1] && f[4]) ||
(!f[5] && f[3] && f[6]) || (!f[7] && f[6] && f[4])) {
return keep;
}
// | ? | 0 | ? | | ? | 1 | ? |
// | 1 | | 1 | | 0 | | 0 |
// | ? | 0 | ? | | ? | 1 | ? |
//对应文章中的4-connected P24模式,旋转1次90度
if ((f[3] && f[4] && !f[1] && !f[6]) || (f[1] && f[6] && !f[3] && !f[4])) {
return keep;
}
// keep voro cells inside of blocks and retry later
//(x,y)周围可能保留的栅格很多,此时无法判断是否要对(x,y)剪枝
if (voroCount>=5 && voroCountFour>=3 && data_[x][y].voronoi!=voronoiRetry) {
return retry;
}
return pruned;
}
11、Voronoi图可视化
void DynamicVoronoi::visualize(const char *filename) {
FILE* F = fopen(filename, "w");
...
//fputc()执行3次,其实是依次对一个像素的RGB颜色赋值
for(int y = sizeY_-1; y >=0; y--){
for(int x = 0; x<sizeX_; x++){
unsigned char c = 0;
if (...) {
...
} else if(isVoronoi(x,y)){ //画Voronoi边
fputc( 0, F );
fputc( 0, F );
fputc( 255, F );
} else if (data_[x][y].sqdist==0) { //填充障碍物
fputc( 0, F );
fputc( 0, F );
fputc( 0, F );
} else { //填充Voronoi区块内部
float f = 80+(sqrt(data_[x][y].sqdist)*10);
if (f>255) f=255;
if (f<0) f=0;
c = (unsigned char)f;
fputc( c, F );
fputc( c, F );
fputc( c, F );
}
}
}
fclose(F);
}
依次对每个像素的RGB通道赋值,一个典型的二值图输入(图11)和Voronoi图输出(图12-13)如下。
二值地图输入

.
prune前的Voronoi图

.
prune后的Voronoi图

四、Voronoi Planner的理论详解–Voronoi Edge
Voronoi Planner规划的路径的特点是尽量的远离障碍物
https://zhuanlan.zhihu.com/p/135441089
将Voronoi Edge转化为Grahp结构,将机器人的起点位置和终点位置关联到最近的Voronoi Edge,然后通过图搜索算法(Dijkstra、Astar等)就可以生成一条从起点到终点的安全行驶路线
参考资料
https://blog.csdn.net/K346K346/article/details/52244123
https://github.com/nkuwenjian/voronoi_planner
https://github.com/Merkaster/Dynamic-Voronoi-Path-Planning
五、智能算法的方法
(1)蚁群算法
蚁群算法是在 20 世纪 90 年代由 Macro Dorigo 提出,这是一种利用随机搜索的方法,蚂蚁外出觅食总是会体现觅食路线趋向最优选择的趋向性。基本思路是研究发现蚂蚁在外出的时候会在行走的路线上,对路线进行标记,并发出信息素告示其他蚂蚁,蚂蚁会有对同类的信息素感知的能力,并会根据信息素的浓度高低进行选择,在众多路线中,蚂蚁会选择信息浓度最高的线路,形成正态反馈,从而浓度高的线路,信息素浓度会越来越高,浓度低的线路信息素会越来越少,最终蚁群由于正反馈机制,会选择最优的线路
提示:以下是本篇文章正文内容
一、算法简介的算法思想
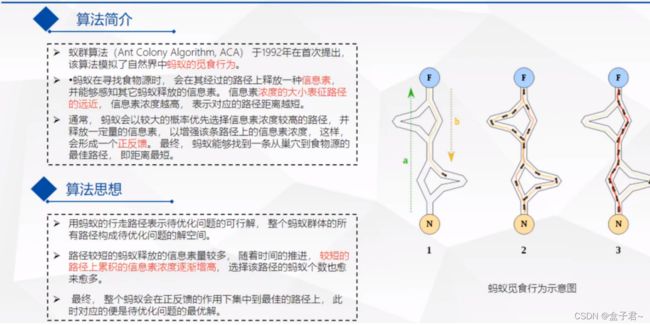
感性分析
蚂蚁走多了就有经验了!不断参考前车之鉴的思想进行迭代–是多只的蚂蚁去走【第一个循环】,走很多次【第二个循环】!
.
二、算法实现
1.计算信息素公式–第一只蚂蚁探索路径的时候的核心思想和计算公式

2.更新信息素公式–第二只以后的蚂蚁探索路径的时候的核心思想和计算公式
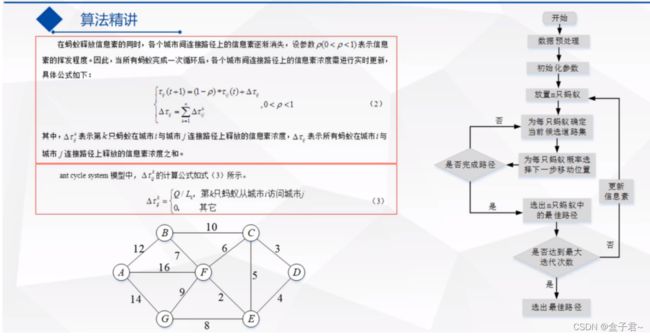
三、总结
蚁群算法常被用在全局路径探索,一方面是因为探索出来的路径比较粗糙,在复杂提点的场景一般不能直接用于执行。另一方面是只有在大地图(全局地图)中,蚁群算法的优势才能被显现出来
.
.
(2)动态规划DP算法
一、动态规划DP算法简介与核心思想

如上图所示,多阶段的决策过程又7个阶段,每个阶段又包含若干个状态(ABCDEFG),整体决策就是在每个阶段决策哪一种状态,把各个阶段的最优状态连接起来就是最优的决策序列
.
二、动态规划DP算法的适用范围
把多阶段的决策过程转化为一系列单阶段的最优化问题来解决
在任何问题中,只要能把问题划分为多个阶段,并得到每个阶段的多个状态,遇到这类问题都可以用动态规划算法
.
三、动态规划DP算法的步骤【正向求解-逆向寻优的过程】

1.先遍历最后一个阶段–求最优

2.遍历第3阶段–求最优

3.遍历第2阶段–求最优

4.遍历第1阶段–求最优【这个就是全局最优】
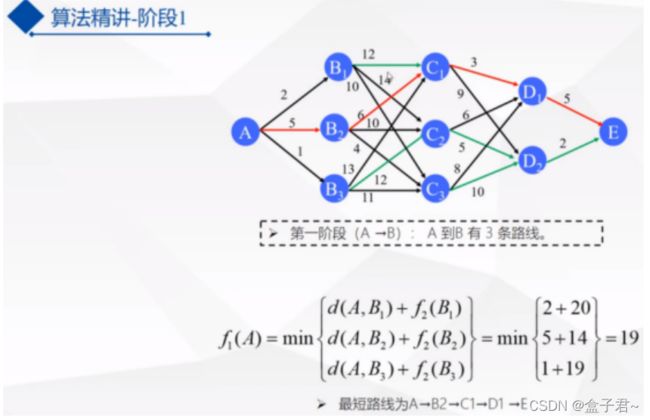
5.当从终点阶段开始,向起点阶段进行逆向遍历寻优的过程中,到达起点阶段时就能计算出来最优路径
四、动态规划DP算法的难点
一个问题难以划分为多个阶段,且每个阶段的状态不是先验的,而是需要约束体哦阿健实时计算出来的
这就意味着动态规划DP算法常用于全局规划,再先验的全局地图中进行规划,当然动态规划DP算法也九二一用在局部规划中,百度apollo中的em_planner也有用到DP的思想进行局部路径的搜索,再用QP的方式进行轨迹平滑。