计算机如何大规模协作?

数据、算法和算力,被视为驱动人工智能发展的“三驾马车”,三者缺一不可。比如,关于AlphaGo的胜利,很多人喜欢把它归功于深度学习算法,这当然是原因之一。可如果只有算法,可以断言AlphaGo一定不会成功。其实早在2016年DeepMind就已经公开了AlphaGo的算法细节,可直到今天,我们并没有看到第二个与AlphaGo旗鼓相当的围棋人工智能出现。实际上,AlphaGo的胜利有很大一部分原因要归功于谷歌后台庞大的IT基础设施建设。过去,计算机下棋很难获胜,除了没有好的算法,计算机的算力也不够。就是说,计算机在有限的时间里算不出答案。AlphaGo真正让同行无法复制的,不是算法,而是它的数据中心。

01.今非昔比的算力
早期的计算机装置庞大到可以塞满整个房间,不仅布满电子管,还拖着长长的电线,它们的输入输出使用打孔的纸或磁带。这些贵重设备由技术专家来使用和维护。普通老百姓连看都没看过,更不用提使用它们。
20世纪最顶尖的技术专家,也难以预测IT技术的发展速度。IBM创始人托马斯·沃森曾说:“全世界只需要5台电脑就足够了”,如今一个家庭恐怕就有超过五台的智能设备。当时,微软的比尔·盖茨说:“无论对谁来说,640KB内存都足够了”,但在Windows 2000推出时,它最低的内存要求是64MB。
电子计算机发展至今还不到100年。我们看到的是,随着集成工艺提升,集成电路可以安装更多的晶体管。Intel创始人戈登·摩尔在19世纪提出了“摩尔定律”。这一定律精准预测了芯片行业未来30年的发展,揭示了信息技术发展初期指数级增长规律。直到芯片尺度达到它的物理极限前,摩尔定律会持续生效。
1958年第一代集成电路仅仅包含了两个晶体管,但是在1997年,奔腾II处理器的晶体管已经扩大到了750万个。如今,我们可以在一根头发丝大小的空间上集成上万个晶体管。《奇点临近》的作者雷·库兹韦尔(Ray Kurzweil)将这种科技发展增长规律称作加速回报法则,他还大胆预测,人类在21世纪的进步可能是20世纪的1000倍。
计算机刚被发明出来时,主要服务于军事科研领域。如今,它们已走入千家万户。过去,一个5MB硬盘的体积相当于两个冰箱大小,必须用飞机运送。如今,TB容量的固态硬盘只有手掌这么大,可以随身携带。
20世纪80年代,计算机每秒只能执行100万次操作,如今,计算机每秒能执行超过十亿次操作,一台超级计算机的每秒计算速度甚至可以轻松突破亿亿次,这种超强计算能力可以用于解决很多专业工程问题,比如天气预报、宇宙探索等。我国在设计天宫一号飞行器时就使用了自主研发的超级计算机神威·太湖之光。它的峰值运算性能达到每秒12.54亿亿次,是世界上首台每秒运算能超过10亿亿次的超级计算机。
02.举足轻重的三篇论文
计算机是一个物理装置,它能做什么、不能做什么,遵循物理法则。由于突破不了物理极限,很多大型计算任务无法只靠单台计算机来完成。这种情况就要想办法对目标进行拆解,把计算任务分摊到多台计算机上并行处理,然后再合并结果。此过程体现了一种分布式计算的思想。
把数据分散到不同的服务器上进行处理的技术,叫做分布式技术。分布式技术的发展很大程度上归功于谷歌发表的三篇论文:2003年的GFS(一种分布式文件存储系统)、2004年的MapReduce(一种分布式数据计算技术)以及2006年的BigTable(一种分布式数据存储技术)。虽然今天谷歌使用的相关技术早已更新换代,但不妨碍这三篇论文在分布式技术发展过程中起到的重要作用。这三篇论文分别阐述了当时人们很难处理的三个核心技术问题,并给出了解决方案。
第一个问题是如何存储海量文件数据。谷歌给出的答案是分布式文件系统(GFS),其核心思想是实现存储介质和数据的冗余。比如将一份数据分割成很多块,存储在多台服务器上,而且存多个副本。这样一来,任何一台服务器发生故障,都不会导致数据丢失,同时解决了传统文件系统无法存储超过硬盘容量的问题。
第二个技术难点是如何实现海量数据计算。一台计算机的计算能力是有上限的。普通服务器每秒能处理的交易量(TPS)在1万笔左右。无论怎么优化,性能也会达到瓶颈。但为何很多互联网电商能轻松处理每秒上亿笔交易呢?答案是把用户和系统分成多份,每个子系统为不同的用户服务。这样的话,有多少个子系统,总的计算能力就可以扩展多少倍。
要实现分布式计算,关键是如何将计算任务分解,再合并得到结果。这个过程称为MapReduce,它是一个先Map(映射)再Reduce(归集)的过程(见图)。比如,当搜索网站要定位某个网页时,它会把网页之间的关系转换成数学上的矩阵运算。但实际上网页总量是非常庞大的,单台计算机不可能用一个完整矩阵完成计算。此时MapReduce就派上用场了,它能把一个大矩阵拆分成若干个足够小的矩阵,只要计算这些小矩阵,就能得到最终结果。
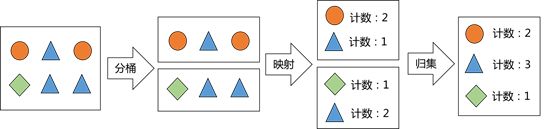
图 MapReduce的工作机制
第三个问题是如何存储大表数据。BigTable是处理“很大的表”的技术。这张大表是一张逻辑上的表,表里的数据会分别存储在不同服务器上。BigTable的基本思想是把所有数据都存入这张虚拟表,这张表非常宽,使用时能根据需要增减字段,它的数据模型虽然定义为结构化数据,但它不像传统数据库表有各种各样的约束。BigTable必须将数据存储在分布式文件存储系统GFS上。之所以这么做,是因为计算机把数据读入内存进行运算要比在物理磁盘上移动数据的开销小得多,而且搬运数据会耗费大量时间和IO资源。
谷歌发布三篇论文时,并没有公开全部的技术细节。后来,美国人卡廷(Doug Cutting)发起建立了一个开源项目Hadoop。他参照谷歌发表的论文,实现了一个大规模的分布式计算系统。Hadoop这个单词是卡廷的孩子给大象取的名字(Hadoop的标志旁就有一只欢快的大象),由于拼写简单,叫起来朗朗上口,所以被卡廷当作了项目名。由于Hadoop是开源项目,任何人都可以下载和安装,它也因此流行了起来。不过,谷歌的论文是在2006年或以前公布的,2008年的时候,Hadoop和谷歌公布的一些性能指标仍然有好几倍的差距。
03.不可兼得的CAP
人类文明的基石建立在大规模合作之上。从飞机制造到城市建设,从来不是靠一个人能完成的,靠的是分工和协作。计算机系统亦是如此,要完成庞大的计算任务,计算机之间就要相互合作。无论是互联网还是云计算,本质上它们都是一种大规模分布式处理系统。
分布式系统是一种在物理上分散、逻辑上集中的系统,它将分散在计算机网络中的多个节点连接起来,共同对外提供服务。既然是分散,就要考虑任意一处出现单点故障的情况。因此在分布式系统中,一份数据都会存储多个副本,所有节点可以做到在线扩缩容,以匹配业务负载。
无论是软件还是硬件,没有单一系统或组件可以保证不发生异常。就是说故障是常态。分布式系统要解决的是即使部分节点发生故障,也可以确保整个系统的高可用,从而保证对外服务。
在分布式系统中,有一个重要的定理——CAP定理。CAP定理也称布鲁尔定理,最初是由埃里克·布鲁尔在1998年提出的猜想。2002年,赛斯·吉尔伯特(SethGilbert)和南希·林奇(Nancy Lynch)证明了这个定理。
CAP定理指的是在一个分布式系统中,不能同时兼顾一致性、可用性、分区容错性,最多只能实现其中的两个。
CAP由三个单词的首字母组成:
C表示“一致性”(Consistency),即一旦某个操作完成,所有节点在同一时间的数据是保持完全一致的。
A表示“可用性”(Availability),即这个分布式系统提供的服务是一直可用的,对于请求都是正常响应的。
P表示“分区容错性”(Partition tolerance),即一旦某个节点或分区故障,仍然能够对外提供满足一致性和可用性的服务。
CAP理论的重要意义在于,它是设计和实现分布式系统时必须遵守的理论基础,它从一开始就否定了满足所有特性的可能性。这就好比当人们了解了热力学第一定律和第二定律后,就从源头上打消了制造永动机的念头。
在CAP(一致性、可用性、分区容错性)三者中,可用性是一项重要指标,只要系统对外服务,就必须关注到系统的可用性。那么,在确保可用性的情况下,分布式系统应该优先考虑一致性还是选择分区容错性?
分布式系统通过多台计算机组合而成的集群能力,解决了单台计算机无法处理的计算问题。这种架构最主要要解决的问题是,当系统某个分区故障时,它仍然可以对外服务。就是说,分布式系统更看重分区容错性,并适当放弃一致性。
理想情况下,如果各个服务节点严格遵循相同的处理协议,可以标准化运行,出故障后可以随时替换,那关于一致性的困扰也就不复存在。但这毕竟是理想情况,现实情况是,虽然计算机系统看似强大而健壮,但它实际很脆弱。比如网络是不可靠的,消息会丢失、延迟或被打乱。硬件是会坏的,无法保证每个运行节点都是可用的,随时可能发生宕机。要做到一致性,就代表了系统不能发生任何故障,所有节点之间的通信无需任何时间,这个时候整个系统等同于一台计算机。越强的一致性要求往往造成越弱的处理性能,以及越差可扩展性。技术上的投入也极大。
分布式系统的建设需要根据实际情况,适当放宽对一致性的要求。例如在一定约束下,让系统在经过一段时间后(而不是立刻)达到一致的状态。目前的大部分互联网应用都是这种实现方式。比如用户在浏览购物网站,后台可能会让A地区用户先看到某些信息,让B地区用户晚一点看到。当然,也不是说这种选择适用于所有的业务场景。比如对于银行来说,交易数据和账户数据是最关键的,绝对不能出现不一致的情况,所以银行系统在设计分布式架构时,宁可放弃一些分区容错性要求,也要优先保证账务数据是一致的。
关于作者:徐晟,高级工程师、毕业于上海交通大学,从业十余年,具备开发、架构、大数据、安全、运维等多领域技术从业经验,对科技发展、人工智能有自己独到的见解。现就职于某商业银行,主要负责智能运维(AIOps)、数据可视化、容量管理等方面工作;参与智能运维国家标准相关编制工作。
本文摘编自《大话机器智能:一书看透AI的底层运行逻辑》,转载请标明文章来源
转载请联系微信:Better_lydia
RECOMMEND
推荐阅读
![]()
大话机器智能:一书看透AI的底层运行逻辑

作者:徐晟
本书以通俗易懂的方式,勾勒人工智能的全貌,展现AI的底层运行逻辑。
告诉你AI是如何工作的!
![]()

一年一度的423读书日就要来了,华章科技在此期间为您带来7场不同主题的技术干货直播,直播内容及观看方式请点击上方链接查看。
![]()
更多精彩回顾
书讯 | 4月书讯(上)| 上新了,华章
书讯 | 4月书讯(下)| 上新了,华章
资讯 | 视频时代的大数据:问题、挑战与解决方案
书单 | 金三银四求职季,十道腾讯算法真题解析!
干货 | TypeScript 中的“类型”到底是个啥?
收藏 | 终于有人把Scrapy爬虫框架讲明白了
上新 | NLP大牛菲利普•科恩机器翻译权威著作
赠书 | 【第99期】边缘计算比云计算强在哪里?终于有人讲明白了


点击阅读全文购买