神经网络和深度学习简史
深度学习掀起海啸
如今,深度学习浪潮拍打计算机语言的海岸已有好几年,但是,2015年似乎才是这场海啸全力冲击自然语言处理(NLP)会议的一年。——Dr. Christopher D. Manning, Dec 2015
整个研究领域的成熟方法已经迅速被新发现超越,这句话听起来有些夸大其词,就像是说它被「海啸」袭击了一样。但是,这种灾难性的形容的确可以用来描述深度学习在过去几年中的异军突起——显著改善人们对解决人工智能最难问题方法的驾驭能力,吸引工业巨人(比如谷歌等)的大量投资,研究论文的指数式增长(以及机器学习的研究生生源上升)。在听了数节机器学习课堂,甚至在本科研究中使用它以后,我不禁好奇:这个新的「深度学习」会不会是一个幻想,抑或上世纪80年代已经研发出来的「人工智能神经网络」扩大版?让我告诉你,说来话长——这不仅仅是一个有关神经网络的故事,也不仅仅是一个有关一系列研究突破的故事,这些突破让深度学习变得比「大型神经网络」更加有趣,而是一个有关几位不放弃的研究员如何熬过黑暗数十年,直至拯救神经网络,实现深度学习梦想的故事。
机器学习算法的百年历史
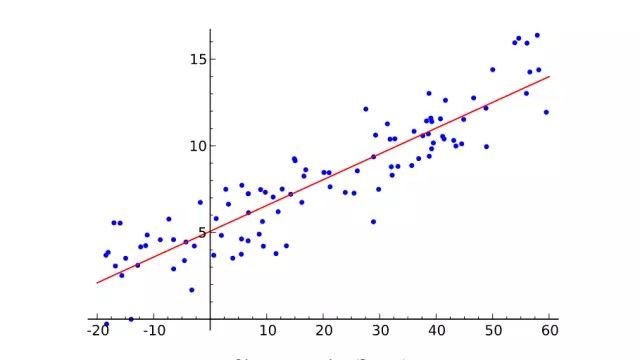
线性回归
首先简单介绍一下机器学习是什么。从二维图像上取一些点,尽可能绘出一条拟合这些点的直线。你刚才做的就是从几对输入值(x)和输出值(y)的实例中概括出一个一般函数,任何输入值都会有一个对应的输出值。这叫做线性回归,一个有着两百年历史从一些输入输出对组中推断出一般函数的技巧。这就是它很棒的原因:很多函数难以给出明确的方程表达,但是,却很容易在现实世界搜集到输入和输出值实例——比如,将说出来的词的音频作为输入,词本身作为输出的映射函数。
线性回归对于解决语音识别这个问题来说有点太无用,但是,它所做的基本上就是监督式机器学习:给定训练样本,「学习」一个函数,每一个样本数据就是需要学习的函数的输入输出数据(无监督学习,稍后在再叙)。尤其是,机器学习应该推导出一个函数,它能够很好地泛化到不在训练集中的输入值上,既然我们真的能将它运用到尚未有输出的输入中。例如,谷歌的语音识别技术由拥有大量训练集的机器学习驱动,但是,它的训练集也不可能大到包含你手机所有语音输入。
泛化能力机制如此重要,以至于总会有一套测试数据组(更多的输入值与输出值样本)这套数据组并不包括在训练组当中。通过观察有多少个正确计算出输入值所对应的输出值的样本,这套单独数据组可以用来估测机器学习技术有效性。概括化的克星是过度拟合——学习一个对于训练集有效但是却在测试数据组中表现很差的函数。既然机器学习研究者们需要用来比较方法有效性的手段,随着时间的推移,标准训练数据组以及测试组可被用来评估机器学习算法。
好了,定义谈得足够多了。重点是——我们绘制线条的联系只是一个非常简单的监督机器学习例子:要点在于训练集(X为输入,Y为输出),线条是近似函数,用这条线来为任何没有包含在训练集数据里的X值(输入值)找到相应的Y值(输出值)。别担心,接下来的历史就不会这么干巴巴了。让我们继续吧。
虚假承诺的荒唐
显然这里话题是神经网络,那我们前言里为何要扯线性回归呢?呃, 事实上线性回归和机器学习一开始的方法构想,弗兰克· 罗森布拉特(Frank Rosenblatt)的感知机, 有些许相似性。

Perceptron
心理学家Rosenblatt构想了感知机,它作为简化的数学模型解释大脑神经元如何工作:它取一组二进制输入值(附近的神经元),将每个输入值乘以一个连续值权重(每个附近神经元的突触强度),并设立一个阈值,如果这些加权输入值的和超过这个阈值,就输出1,否则输出0(同理于神经元是否放电)。对于感知机,绝大多数输入值不是一些数据,就是别的感知机的输出值。但有一个额外的细节:这些感知机有一个特殊的,输入值为1的,「偏置」输入,因为我们能补偿加权和,它基本上确保了更多的函数在同样的输入值下是可计算的。这一关于神经元的模型是建立在沃伦·麦卡洛克(Warren McCulloch)和沃尔特·皮兹(Walter Pitts)工作上的。他们曾表明,把二进制输入值加起来,并在和大于一个阈值时输出1,否则输出0的神经元模型,可以模拟基本的或/与/非逻辑函数。这在人工智能的早期时代可不得了——当时的主流思想是,计算机能够做正式的逻辑推理将本质上解决人工智能问题。
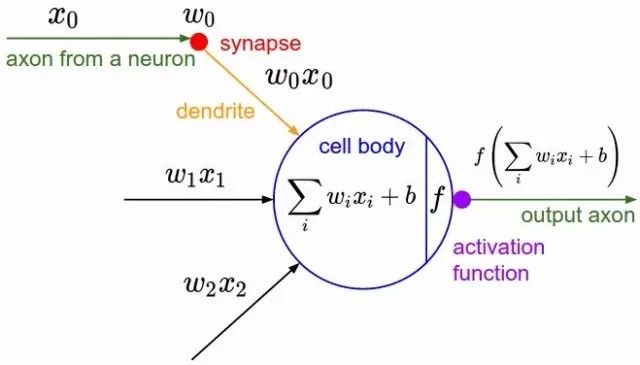
另一个图表,显示出生物学上的灵感。激活函数就是人们当前说的非线性函数,它作用于输入值的加权和以产生人工神经元的输出值——在罗森布拉特的感知机情况下,这个函数就是输出一个阈值操作
然而,麦卡洛克-皮兹模型缺乏一个对AI而言至关重要的学习机制。这就是感知机更出色的地方所在——罗森布拉特受到唐纳德·赫布(Donald Hebb) 基础性工作的启发,想出一个让这种人工神经元学习的办法。赫布提出了一个出人意料并影响深远的想法,称知识和学习发生在大脑主要是通过神经元间突触的形成与变化,简要表述为赫布法则:
当细胞A的轴突足以接近以激发细胞B,并反复持续地对细胞B放电,一些生长过程或代谢变化将发生在某一个或这两个细胞内,以致A作为对B放电的细胞中的一个,效率增加。
感知机并没有完全遵循这个想法,但通过调输入值的权重,可以有一个非常简单直观的学习方案:给定一个有输入输出实例的训练集,感知机应该「学习」一个函数:对每个例子,若感知机的输出值比实例低太多,则增加它的权重,否则若设比实例高太多,则减少它的权重。更正式一点儿的该算法如下:
从感知机有随机的权重和一个训练集开始。
对于训练集中一个实例的输入值,计算感知机的输出值。
如若感知机的输出值和实例中默认正确的输出值不同:(1)若输出值应该为0但实际为1,减少输入值是1的例子的权重。(2)若输出值应该为1但实际为0,增加输入值是1的例子的权重。
对于训练集中下一个例子做同样的事,重复步骤2-4直到感知机不再出错。
这个过程很简单,产生了一个简单的结果:一个输入线性函数(加权和),正如线性回归被非线性激活函数「压扁」了一样(对带权重求和设定阈值的行为)。当函数的输出值是一个有限集时(例如逻辑函数,它只有两个输出值True/1 和 False/0),给带权重的和设置阈值是没问题的,所以问题实际上不在于要对任何输入数据集生成一个数值上连续的输出(即回归类问题),而在于对输入数据做好合适的标签(分类问题)。

罗森布拉特用定制硬件的方法实现了感知机的想法(在花哨的编程语言被广泛使用之前),展示出它可以用来学习对20×20像素输入中的简单形状进行正确分类。自此,机器学习问世了——建造了一台可以从已知的输入输出对中得出近似函数的计算机。在这个例子中,它只学习了一个小玩具般的函数,但是从中不难想象出有用的应用,例如将人类乱糟糟的手写字转换为机器可读的文本。
很重要的是,这种方法还可以用在多个输出值的函数中,或具有多个类别的分类任务。这对一台感知机来说是不可能完成的,因为它只有一个输出,但是,多输出函数能用位于同一层的多个感知机来学习,每个感知机接收到同一个输入,但分别负责函数的不同输出。实际上,神经网络(准确的说应该是「人工神经网络(ANN,Artificial Neural Networks)」)就是多层感知机(今天感知机通常被称为神经元)而已,只不过在这个阶段,只有一层——输出层。所以,神经网络的典型应用例子就是分辨手写数字。输入是图像的像素,有10个输出神经元,每一个分别对应着10个可能的数字。在这个案例中,10个神经元中,只有1个输出1,权值最高的和被看做是正确的输出,而其他的则输出0。
多层输出的神经网络
也可以想象一个与感知机不同的人工神经网络。例如,阈值激活函数并不是必要的; 1960年,Bernard Widrow和Tedd Hoff很快开始探索一种方法——采用适应性的「自适应(ADALINE)」神经元来输出权值的输入,这种神经元使用化学「 存储电阻器」,并展示了这种「自适应线性神经元」能够在电路中成为「 存储电阻器」的一部分(存储电阻器是带有存储的电阻)。他们还展示了,不用阈值激活函数,在数学上很美,因为神经元的学习机制是基于将错误最小化的微积分,而微积分我们都很熟悉了。
如果我们多思考一下 「自适应(ADALINE)」,就会有进一步的洞见:为大量输入找到一组权重真的只是一种线性回归。再一次,就像用线性回归一样,这也不足以解决诸如语音识别或计算机视觉这样的人工智能难题。McCullough,Pitts和罗森布拉特真正感到兴奋的是联结主义(Connectionism)这个宽泛的想法:如此简单计算机单元构成的网络,其功能会大很多而且可以解决人工智能难题。而且罗森布拉特说的和(坦白说很可笑的)《纽约时报》这段引文的意思差不多:
海军披露了一台尚处初期的电子计算机,期待这台电子计算机能行走,谈话,看和写,自己复制出自身存在意识…罗森布拉特博士,康奈尔航空实验室的一位心理学家说,感知机能作为机械太空探险者被发射到行星上。
这种谈话无疑会惹恼人工领域的其他研究人员,其中有许多研究人员都在专注于这样的研究方法,它们以带有具体规则(这些规则遵循逻辑数学法则)的符号操作为基础。MIT人工智能实验室创始人Marvin Minsky和Seymour Paper就是对这一炒作持怀疑态度研究人员中的两位,1969年,他们在一本开创性著作中表达了这种质疑,书中严谨分析了感知机的局限性,书名很贴切,叫《感知机》。
他们分析中,最被广为讨论的内容就是对感知机限制的说明,例如,他们不能学习简单的布尔函数XOR,因为它不能进行线性分离。虽然此处历史模糊,但是,人们普遍认为这本书对人工智能步入第一个冬天起到了推波助澜的作用——大肆炒作之后,人工智能进入泡沫幻灭期,相关资助和出版都遭冻结。

感知机局限性的视觉化。找到一个线性函数,输入X,Y时可以正确地输出+或-,就是在2D图表上画一条从+中分离出-的线;很显然,就第三幅图显示的情况来看,这是不可能的
人工智能冬天的复苏
因此,情况对神经网络不利。但是,为什么?他们的想法毕竟是想将一连串简单的数学神经元结合在一起,完成一些复杂任务,而不是使用单个神经元。换句话说,并不是只有一个输出层,将一个输入任意传输到多个神经元(所谓的隐藏层,因为他们的输出会作为另一隐藏层或神经元输出层的输入)。只有输出层的输出是「可见」的——亦即神经网络的答案——但是,所有依靠隐藏层完成的间接计算可以处理复杂得多的问题,这是单层结构望尘莫及的。

有两个隐藏层的神经网络
言简意赅地说,多个隐藏层是件好事,原因在于隐藏层可以找到数据内在特点,后续层可以在这些特点(而不是嘈杂庞大的原始数据)基础上进行操作。以图片中的面部识别这一非常常见的神经网络任务为例,第一个隐藏层可以获得图片的原始像素值,以及线、圆和椭圆等信息。接下来的层可以获得这些线、圆和椭圆等的位置信息,并且通过这些来定位人脸的位置——处理起来简单多了!而且人们基本上也都明白这一点。事实上,直到最近,机器学习技术都没有普遍直接用于原始数据输入,比如图像和音频。相反,机器学习被用于经过特征提取后的数据——也就是说,为了让学习更简单,机器学习被用在预处理的数据上,一些更加有用的特征,比如角度,形状早已被从中提取出来。
因此,注意到这一点很重要:Minsky和Paper关于感知机的分析不仅仅表明不可能用单个感知机来计算XOR,而且特别指出需要多层感知机——亦即现在所谓的多层神经网络——才可以完成这一任务,而且罗森布拉特的学习算法对多层并不管用。那是一个真正的问题:之前针对感知机概括出的简单学习规则并不是适用于多层结构。想知道原因?让我们再来回顾一下单层结构感知机如何学习计算一些函数:
和函数输出数量相等的感知机会以小的初始权值开始(仅为输入函数的倍数)
选取训练集中的一个例子作为输入,计算感知机的输出
对于每一个感知机,如果其计算结果和该例子的结果不匹配,调整初始权值
继续采用训练集中的下一个例子,重复过程2到4次,直到感知机不再犯错。
这一规则并不适用多层结构的原因应该很直观清楚了:选取训练集中的例子进行训练时,我们只能对最终的输出层的输出结果进行校正,但是,对于多层结构来说,我们该如何调整最终输出层之前的层结构权值呢?答案(尽管需要花时间来推导)又一次需要依赖古老的微积分:链式法则。这里有一个重要现实:神经网络的神经元和感知机并不完全相同,但是,可用一个激活函数来计算输出,该函数仍然是非线性的,但是可微分,和Adaline神经元一样;该导数不仅可以用于调整权值,减少误差,链式法则也可用于计算前一层所有神经元导数,因此,调整它们权重的方式也是可知的。说得更简单些:我们可以利用微积分将一些导致输出层任何训练集误差的原因分配给前一隐藏层的每个神经元,如果还有另外一层隐藏层,我们可以将这些原因再做分配,以此类推——我们在反向传播这些误差。而且,如果修改了神经网络(包括那些隐藏层)任一权重值,我们还可以找出误差会有多大变化,通过优化技巧(时间长,典型的随机梯度下降)找出最小化误差的最佳权值。
反向传播的基本思想
反向传播由上世纪60年代早期多位研究人员提出,70年代,由Seppo Linnainmaa引入电脑运行,但是,Paul Werbos在1974年的博士毕业论文中深刻分析了将之用于神经网络方面的可能性,成为美国第一位提出可以将其用于神经网络的研究人员。有趣的是,他从模拟人类思维的研究工作中并没有获得多少启发,在这个案例中,弗洛伊德心理学理论启发了他,正如他自己叙述:
1968年,我提出我们可以多少模仿弗洛伊德的概念——信度指派的反向流动( a backwards flow of credit assignment,),指代从神经元到神经元的反向流动…我解释过结合使用了直觉、实例和普通链式法则的反向计算,虽然它正是将弗洛伊德以前在心理动力学理论中提出的概念运用到数学领域中!
尽管解决了如何训练多层神经网络的问题,在写作自己的博士学位论文时也意识到了这一点,但是,Werbos没有发表将BP算法用于神经网络这方面的研究,直到1982年人工智能冬天引发了寒蝉效应。实际上,Werbos认为,这种研究进路对解决感知机问题是有意义的,但是,这个圈子大体已经失去解决那些问题的信念。
Minsky的书最著名的观点有几个:(1)我们需要用MLPs[多层感知机,多层神经网络的另一种说法)来代表简单的非线性函数,比如XOR 映射;而且(2)世界上没人发现可以将MLPs训练得够好,以至于可以学会这么简单的函数的方法。Minsky的书让世上绝大多数人相信,神经网络是最糟糕的异端,死路一条。Widrow已经强调,这种压垮早期『感知机』人工智能学派的悲观主义不应怪在Minsky的头上。他只是总结了几百位谨慎研究人员的经验而已,他们尝试找出训练MLPs的办法,却徒劳无功。也曾有过希望,比如Rosenblatt所谓的backpropagation(这和我们现在说的 backpropagation并不完全相同!),而且Amari也简短表示,我们应该考虑将最小二乘(也是简单线性回归的基础)作为训练神经网络的一种方式(但没有讨论如何求导,还警告说他对这个方法不抱太大期望)。但是,当时的悲观主义开始变得致命。上世纪七十年代早期,我确实在MIT采访过Minsky。我建议我们合著一篇文章,证明MLPs实际上能够克服早期出现的问题…但是,Minsky并无兴趣(14)。事实上,当时的MIT,哈佛以及任何我能找到的研究机构,没人对此有兴趣。
我肯定不能打保票,但是,直到十年后,也就是1986年,这一研究进路才开始在David Rumelhart, Geoffrey Hinton和Ronald Williams合著的《Learning representations by back-propagating errors》中流行开来,原因似乎就是缺少学术兴趣。
尽管研究方法的发现不计其数(论文甚至清楚提道,David Parker 和 Yann LeCun是事先发现这一研究进路的两人),1986年的这篇文章却因其精确清晰的观点陈述而显得很突出。实际上,学机器学习的人很容易发现自己论文中的描述与教科书和课堂上解释概念方式本质上相同。
不幸的是,科学圈里几乎无人知道Werbo的研究。1982年,Parker重新发现了这个研究办法[39]并于1985年在M.I.T[40]上发表了一篇相关报道。就在Parker报道后不久,Rumelhart, Hinton和Williams [41], [42]也重新发现了这个方法, 他们最终成功地让这个方法家喻户晓,也主要归功于陈述观点的框架非常清晰。
但是,这三位作者没有止步于介绍新学习算法,而是走得更远。同年,他们发表了更有深度的文章《Learning internal representations by error propagation》。
文章特别谈到了Minsky在《感知机》中讨论过的问题。尽管这是过去学者的构想,但是,正是这个1986年提出的构想让人们广泛理解了应该如何训练多层神经网络解决复杂学习问题。而且神经网络也因此回来了!第二部分,我们将会看到几年后,《Learning internal representations by error propagation》探讨过的BP算法和其他一些技巧如何被用来解决一个非常重要的问题:让计算机识别人类书写。
神经网络获得视觉
随着训练多层神经网络的谜题被揭开,这个话题再一次变得空前热门,罗森布拉特的崇高雄心似乎也将得以实现。直到1989年另一个关键发现被公布,现在仍广为教科书及各大讲座引用。
多层前馈神经网络是普适模拟器( universal approximators)。」本质上,可以从数学证明多层结构使得神经网络能够在理论上执行任何函数表达,当然包括XOR(异或)问题。
然而,这是数学,你可以在数学中畅想自己拥有无限内存和所需计算能力——反向传播可以让神经网络被用于世界任何角落吗?噢,当然。也是在1989年,Yann LeCunn在AT&T Bell实验室验证了一个反向传播在现实世界中的杰出应用,即「反向传播应用于手写邮编识别(Backpropagation Applied to Handwritten Zip Code Recognition)」。
你或许会认为,让计算机能够正确理解手写数字并没有那么了不起,而且今天看来,这还会显得你太过大惊小怪,但事实上,在这个应用公开发布之前,人类书写混乱,笔画也不连贯,对计算机整齐划一的思维方式构成了巨大挑战。这篇研究使用了美国邮政的大量数据资料,结果证明神经网络完全能够胜任识别任务。更重要的是,这份研究首次强调了超越普通(plain)反向传播 、迈向现代深度学习这一关键转变的实践需求。
传统的视觉模式识别工作已经证明,抽取局部特征并且将它们结合起来组成更高级的特征是有优势的。通过迫使隐藏单元结合局部信息来源,很容易将这样的知识搭建成网络。一个事物的本质特征可以出现在输入图片的不同位置。因此,拥有一套特征探测器,可以探测到位于输入环节任何地方的某个具体特征实例,非常明智。既然一个特征的精准定位于分类无关,那么,我们可以在处理过程中适当舍弃一些位置信息。不过,近似的位置信息必须被保留,从而允许下面网络层能够探测到更加高级更加复杂的特征。(Fukushima1980,Mozer,1987)

一个神经网络工作原理的可视化过程
或者,更具体的:神经网络的第一个隐层是卷积层——不同于传统网络层,每个神经元对应的一个图片像素都相应有一个不同的权值(40*60=2400个权值),神经元只有很少一部分权值(5*5=25)以同样的大小应用于图像的一小个完整子空间。所以,比如替换了用四种不同的神经元来学习整个输入图片4个角的45度对角线探测,一个单独的神经元能通过在图片的子空间上学习探测45度对角线,并且照着这样的方法对整张图片进行学习。每层的第一道程序都以相类似的方式进行,但是,接收的是在前一隐藏层找到的「局部」特征位置而不是图片像素值,而且,既然它们正在结合有关日益增大的图片子集的信息,那么,它们也能「看到」其余更大的图片部分。最后,倒数的两个网络层利用了前面卷积抽象出来的更加高级更加明显的特征来判断输入的图像究竟该归类到哪里。这个在1989年的论文里提出的方法继续成为举国采用的支票读取系统的基础,正如LeCun在如下小视频中演示的:
这很管用,为什么?原因很直观,如果数学表述上不是那么清楚的话:没有这些约束条件,网络就必须学习同样的简单事情(比如,检测45°角的直线和小圆圈等),要花大把时间学习图像的每一部分。但是,有些约束条件,每一个简单特征只需要一个神经元来学习——而且,由于整体权值大量减少,整个过程完成起来更快。而且,既然这些特征的像素确切位置无关紧要,那么,基本上可以跳过图像相邻子集——子集抽样,一种共享池手段(a type of pooling)——当应用权值时,进一步减少了训练时间。多加了这两层——(卷积层和汇集层)——是卷积神经网络(CNNs/ConvNets)和普通旧神经网络的主要区别。
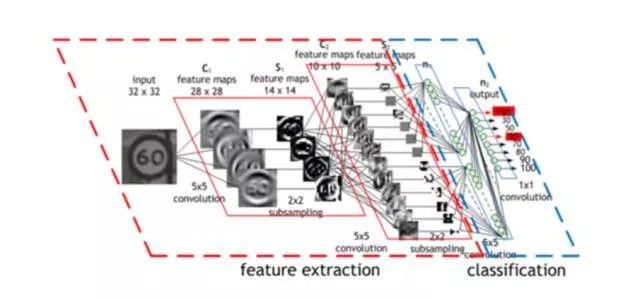
卷积神经网络(CNN)的操作过程
那时,卷积的思想被称作「权值共享」,也在1986年Rumelhart、Hinton和Williams关于反向传播的延伸分析中得到了切实讨论。显然,Minsky和Papert在1969年《感知机》中的分析完全可以提出激发这一研究想法的问题。但是,和之前一样,其他人已经独立地对其进行了研究——比如,Kunihiko Fukushima在1980年提出的 Neurocognitron。而且,和之前一样,这一思想从大脑研究汲取了灵感:
根据Hubel和Wiesel的层级模型,视觉皮层中的神经网络具有一个层级结构:LGB(外侧膝状体)→样品细胞→复杂细胞→低阶超复杂细胞->高阶超复杂细胞。低阶超复杂细胞和高阶超复杂细胞之间的神经网络具有一个和简单细胞与复杂细胞之间的网络类似的结构。在这种层状结构中,较高级别的细胞通常会有这样的倾向,即对刺激模式的更复杂的特征进行选择性响应,同时也具有一个更大的接收域,而且对刺激模式位置的移动更不敏感。因此,在我们的模型中就引入了类似于层级模型的结构。
LeCun也在贝尔实验室继续支持卷积神经网络,其相应的研究成果也最终在上世纪90年代中期成功应用于支票读取——他的谈话和采访通常都介绍了这一事实:「在上世纪90年代后期,这些系统当中的一个读取了全美大约10%到20%的支票。」
神经网络进入无监督学习时期
将死记硬背,完全无趣的支票读取工作自动化,就是机器学习大展拳脚的例子。也许有一个预测性小的应用? 压缩。即指找到一种更小体量的数据表示模式,并从其可以恢复数据原有的表示形态,通过机器学习找到的压缩方法有可能会超越所有现有的压缩模式。当然,意思是在一些数据中找到一个更小的数据表征,原始数据可以从中加以重构。学会压缩这一方案远胜于常规压缩算法,在这种情况下,学习算法可以找到在常规压缩算法下可能错失的数据特征。而且,这也很容易做到——仅用训练带有一个小隐藏层的神经网络就可以对输入进行输出。
自编码神经网络
这是一个自编码神经网络,也是一种学习压缩的方法——有效地将数据转换为压缩格式,并且自动返回到本身。我们可以看到,输出层会计算其输出结果。由于隐藏层的输出比输入层少,因此,隐藏层的输出是输入数据的一个压缩表达,可以在输出层进行重建。

更明确地了解自编码压缩
注意一件奇妙的事情:我们训练所需的唯一东西就是一些输入数据。这与监督式机器学习的要求形成鲜明的对比,监督式机器学习需要的训练集是输入-输出对(标记数据),来近似地生成能从这些输入得到对应输出的函数。确实,自编码器并不是一种监督式学习;它们实际上是一种非监督式学习,只需要一组输入数据(未标记的数据),目的是找到这些数据中某些隐藏的结构。换句话说,非监督式学习对函数的近似程度不如它从输入数据中生成另一个有用的表征那么多。这样一来,这个表征比原始数据能重构的表征更小,但它也能被用来寻找相似的数据组(聚类)或者潜在变量的其他推论(某些从数据看来已知存在但数值未知的方面)。

聚类,一种很常用的非监督式学习应用
在反向传播算法发现之前和之后,神经网络都还有其他的非监督式应用,最著名的是自组织映射神经网络(SOM,Self Organizing Maps)和自适应共振理论(ART,Adapative Resonance Theory)。SOM能生成低维度的数据表征,便于可视化,而ART能够在不被告知正确分类的情况下,学习对任意输入数据进行分类。如果你想一想就会发现,从未标记数据中能学到很多东西是符合直觉的。假设你有一个数据集,其中有一堆手写数字的数据集,并没有标记每张图片对应着哪个数字。那么,如果一张图片上有数据集中的某个数字,那它看起来与其他大多数拥有同样数字的图片很相似,所以,尽管计算机可能并不知道这些图片对应着哪个数字,但它应该能够发现它们都对应着同一个数字。这样,模式识别就是大多数机器学习要解决的任务,也有可能是人脑强大能力的基础。但是,让我们不要偏离我们的深度学习之旅,回到自编码器上。
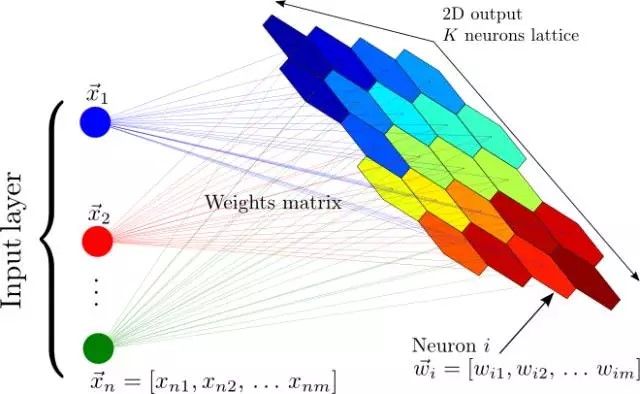
自组织映射神经网络:将输入的一个大向量映射到一个神经输出的网格中,在其中,每个输出都是一个聚类。相邻的神经元表示同样的聚类。
正如权重共享一样,关于自编码器最早的讨论是在前面提到过的1986年的反向传播分析中所进行。有了权重共享,它在接下来几年中的更多研究中重新浮出了水面,包括Hinton自己。这篇论文,有一个有趣的标题:《自编码器,最小描述长度和亥姆霍兹自由能》(Autoencoders, Minimum Description Length, and Helmholts Free Energy),提出「最自然的非监督式学习方法就是使用一个定义概率分布而不是可观测向量的模型」,并使用一个神经网络来学习这种模型。所以,还有一件你能用神经网络来做的奇妙事:对概率分布进行近似。
神经网络迎来信念网络
事实上,在成为1986年讨论反向传播学习算法这篇有重大影响力论文的合作者之前,Hinton在研究一种神经网络方法,可以学习1985年「 A Learning Algorithm for Boltzmann Machines」中的概率分布。
玻尔兹曼机器就是类似神经网络的网络,并有着和感知器(Perceptrons)非常相似的单元,但该机器并不是根据输入和权重来计算输出,在给定相连单元值和权重的情况下,网络中的每个单元都能计算出自身概率,取得值为1或0。因此,这些单元都是随机的——它们依循的是概率分布而非一种已知的决定性方式。玻尔兹曼部分和概率分布有关,它需要考虑系统中粒子的状态,这些状态本身基于粒子的能量和系统本身的热力学温度。这一分布不仅决定了玻尔兹曼机器的数学方法,也决定了其推理方法——网络中的单元本身拥有能量和状况,学习是由最小化系统能量和热力学直接刺激完成的。虽然不太直观,但这种基于能量的推理演绎实际上恰是一种基于能量的模型实例,并能够适用于基于能量的学习理论框架,而很多学习算法都能用这样的框架进行表述。
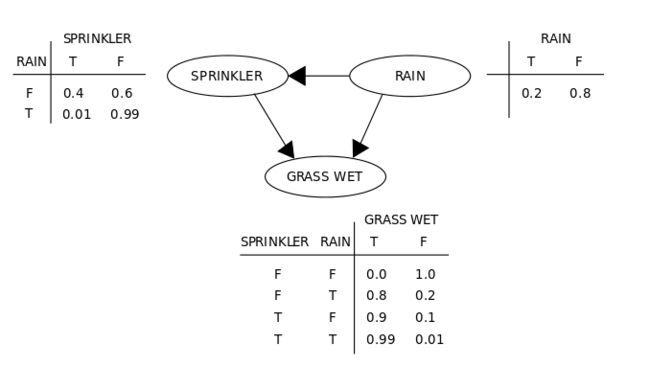
一个简单的信念,或者说贝叶斯网络——玻尔兹曼机器基本上就是如此,但有着非直接/对称联系和可训练式权重,能够学习特定模式下的概率。
回到玻尔兹曼机器。当这样的单元一起置于网络中,就形成了一张图表,而数据图形模型也是如此。本质上,它们能够做到一些非常类似普通神经网络的事:某些隐藏单元在给定某些代表可见变量的可见单元的已知值(输入——图像像素,文本字符等)后,计算某些隐藏变量的概率(输出——数据分类或数据特征)。以给数字图像分类为例,隐藏变量就是实际的数字值,可见变量是图像的像素;给定数字图像「1」作为输入,可见单元的值就可知,隐藏单元给图像代表「1」的概率进行建模,而这应该会有较高的输出概率。
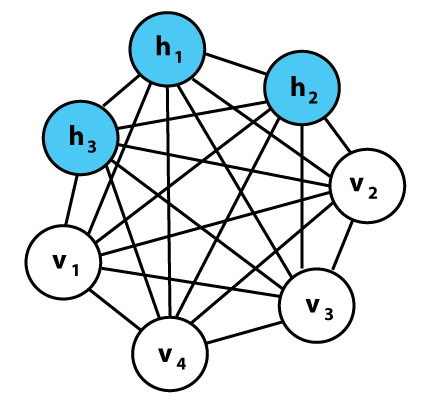
玻尔兹曼机器实例。每一行都有相关的权重,就像神经网络一样。注意,这里没有分层——所有事都可能跟所有事相关联。我们会在后文讨论这样一种变异的神经网络
因此,对于分类任务,现在有一种计算每种类别概率的好方法了。这非常类似正常分类神经网络实际计算输出的过程,但这些网络有另一个小花招:它们能够得出看似合理的输入数据。这是从相关的概率等式中得来的——网络不只是会学习计算已知可见变量值时的隐藏变量值概率,还能够由已知隐藏变量值反推可见变量值概率。所以,如果我们想得出一幅「1」数字图像,这些跟像素变量相关的单元就知道需要输出概率1,而图像就能够根据概率得出——这些网络会再创建图像模型。虽然可能能够实现目标非常类似普通神经网络的监督式学习,但学习一个好的生成模型的非监督式学习任务——概率性地学习某些数据的隐藏结构——是这些网络普遍所需要的。这些大部分都不是小说,学习算法确实存在,而使其成为可能的特殊公式,正如其论文本身所描述的:
或许,玻尔兹曼机器公式最有趣的方面在于它能够引导出一种(与领域无关的)一般性学习算法,这种算法会以整个网络发展出的一种内部模型(这个模型能够捕获其周围环境的基础结构)的方式修改单元之间的联系强度。在寻找这样一个算法的路上,有一段长时间失败的历史(Newell,1982),而很多人(特别是人工智能领域的人)现在相信不存在这样的算法。
我们就不展开算法的全部细节了,就列出一些亮点:这是最大似然算法的变体,这简单意味着它追求与已知正确值匹配的网络可见单元值(visible unit values)概率的最大化。同时计算每个单元的实际最有可能值 ,计算要求太高,因此,训练吉布斯采样(training Gibbs Sampling)——以随机的单元值网络作为开始,在给定单元连接值的情况下,不断迭代重新给单元赋值——被用来给出一些实际已知值。当使用训练集学习时,设置可见单位值( visible units)从而能够得到当前训练样本的值,这样就通过抽样得到了隐藏单位值。一旦抽取到了一些真实值,我们就可以采取类似反向传播的办法——针对每个权重值求偏导数,然后估算出如何调整权重来增加整个网络做出正确预测的概率。
和神经网络一样,算法既可以在监督(知道隐藏单元值)也可以在无监督方式下完成。尽管这一算法被证明有效(尤其是在面对自编码神经网络解决的「编码」问题时),但很快就看出不是特别有效。Redford M. Neal1992年的论文《Connectionist learning of belief networks》论证了需要一种更快的方法,他说:「这些能力使得玻耳兹曼机在许多应用中都非常有吸引力——要不是学习过程通常被认为是慢的要命。」因此,Neal引入了类似信念网络的想法,本质上就像玻耳兹曼机控制、发送连接(所以又有了层次,就像我们之前看过的神经网络一样,而不像上面的玻耳兹曼机控制机概念)。跳出了讨厌的概率数学,这一变化使得网络能以一种更快的学习算法得到训练。洒水器和雨水那一层上面可以视为有一个信念网络——这一术语非常严谨,因为这种基于概率的模型,除了和机器学习领域有着联系,和数学中的概率领域也有着密切的关联。
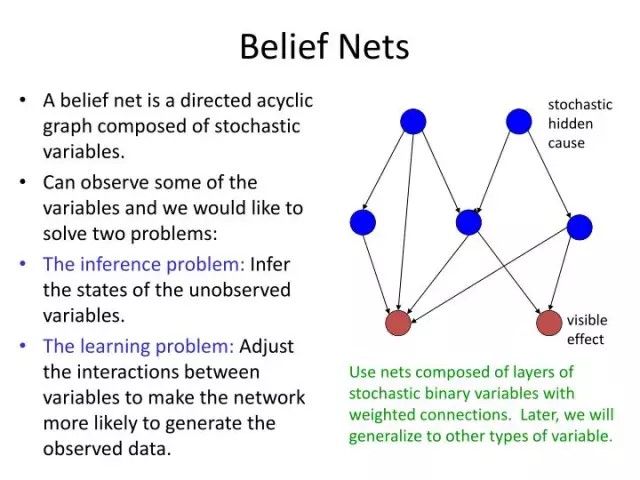
尽管这种方法比玻尔兹曼机进步,但还是太慢了,正确计算变量间的概率关系的数学需求计算量太大了,而且还没啥简化技巧。Hinton、Neal和其他两位合作者很快在1995年的论文《 The wake-sleep algorithm for unsupervised neural networks》中提出了一些新技巧。这次他们又搞出一个和上个信念网络有些不一样的网络,现在被叫做「亥姆霍兹机」。再次抛开细节不谈,核心的想法就是对隐含变量的估算和对已知变量的逆转生成计算采取两套不同的权重,前者叫做recognition weights,后者叫做generative weights,保留了Neal's信念网络的有方向的特性。这样一来,当用于玻尔兹曼机的那些监督和无监督学习问题时,训练就快得多。
最终,信念网络的训练多少会快些!尽管没那么大的影响力,对信念网络的无监督学习而言,这一算法改进是非常重要的进步,堪比十年前反向传播的突破。不过,目前为止,新的机器学习方法也开始涌现,人们也与开始质疑神经网络,因为大部分的想法似乎基于直觉,而且因为计算机仍旧很难满足它们的计算需求。正如我们将在第三部分中看到的,人工智能寒冬将在几年内到来。
神经网络做决定
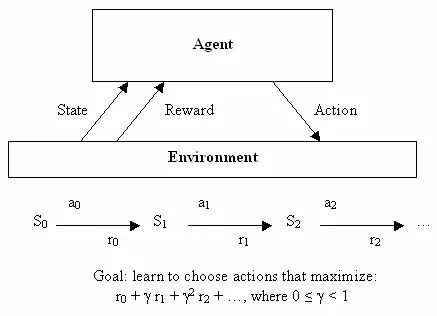
神经网络运用于无监督学习的发现之旅结束后,让我们也快速了解一下它们如何被用于机器学习的第三个分支领域:强化学习。正规解释强化学习需要很多数学符号,不过,它也有一个很容易加以非正式描述的目标:学会做出好决定。给定一些理论代理(比如,一个小软件),让代理能够根据当前状态做出行动,每个采取行动会获得一些奖励,而且每个行动也意图最大化长期效用。
因此,尽管监督学习确切告诉了学习算法它应该学习的用以输出的内容,但是,强化学习会过一段时间提供奖励,作为一个好决定的副产品,不会直接告诉算法应该选择的正确决定。从一开始,这就是一个非常抽象的决策模型——数目有限的状态,并且有一组已知的行动,每种状态下的奖励也是已知的。为了找到一组最优行动,编写出非常优雅的方程会因此变得简单,不过这很难用于解决真实问题——那些状态持续或者很难界定奖励的问题。
强化学习
这就是神经网络流行起来的地方。机器学习大体上,特别是神经网络,很善于处理混乱的连续性数据 ,或者通过实例学习很难加以定义的函数。尽管分类是神经网络的饭碗,但是,神经网络足够普适(general),能用来解决许多类型的问题——比如,Bernard Widrow和Ted Hoff的Adaline后续衍生技术被用于电路环境下的自适应滤波器。
因此,BP研究复苏之后,不久,人们就设计了利用神经网络进行强化学习的办法。早期例子之一就是解决一个简单却经典的问题:平衡运动着的平台上的棍子,各地控制课堂上学生熟知的倒立摆控制问题。
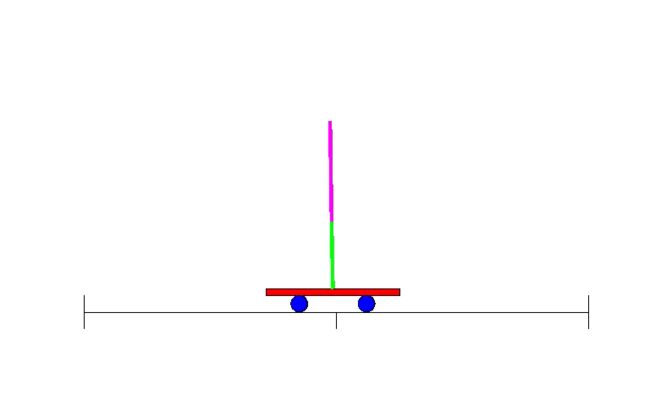
因为有自适应滤波,这项研究就和电子工程领域密切相关,这一领域中,在神经网络出现之前的几十年当中,控制论已经成为一个主要的子领域。虽然该领域已经设计了很多通过直接分析解决问题的办法,也有一种通过学习解决更加复杂状态的办法,事实证明这一办法有用——1990年,「Identification and control of dynamical systems using neural networks」的7000次高被引就是证明。或许可以断定,另有一个独立于机器学习领域,其中,神经网络就是有用的机器人学。用于机器人学的早期神经网络例子之一就是来自CMU的NavLab,1989年的「Alvinn: An autonomous land vehicle in a neural network」:
1. “NavLab 1984 - 1994”
正如论文所讨论的,这一系统中的神经网络通过普通的监督学习学会使用传感器以及人类驾驶时记录下的驾驶数据来控制车辆。也有研究教会机器人专门使用强化学习,正如1993年博士论文「Reinforcement learning for robots using neural networks」所示例的。论文表明,机器人能学会一些动作,比如,沿着墙壁行走,或者在合理时间范围内通过门,考虑到之前倒立摆工作所需的长得不切实际的训练时间,这真是件好事。
这些发生在其他领域中的运用当然很酷,但是,当然多数强化学习和神经网络的研究发生在人工智能和机器学习范围内。而且,我们也在这一范围内取得了强化学习史上最重要的成绩之一:一个学习并成为西洋双陆棋世界级玩家的神经网络。研究人员用标准强化学习算法来训练这个被称为TD-Gammon的神经网络,它也是第一个证明强化学习能够在相对复杂任务中胜过人类的证据。而且,这是个特别的加强学习办法,同样的仅采用神经网络(没有加强学习)的系统,表现没这么好。
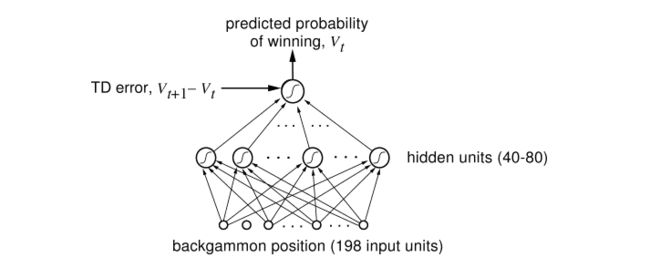
西洋双陆棋游戏中,掌握专家级别水平的神经网络
但是,正如之前已经看到,接下来也会在人工智能领域再次看到,研究进入死胡同。下一个要用TD-Gammnon办法解决的问题,Sebastian Thrun已经在1995年「Learning To Play the Game of Chess」中研究过了,结果不是很好..尽管神经网络表现不俗,肯定比一个初学者要好,但和很久以前实现的标准计算机程序GNU-Chess相比,要逊色得多。人工智能长期面临的另一个挑战——围棋,亦是如此。这样说吧,TD-Gammon 有点作弊了——它学会了精确评估位置,因此,无需对接下来的好多步做任何搜索,只用选择可以占据下一个最有利位置的招数。但是,在象棋游戏和围棋游戏里,这些游戏对人工智能而言是一个挑战,因为需要预估很多步,可能的行动组合如此之巨。而且,就算算法更聪明,当时的硬件又跟不上,Thrun称「NeuroChess不怎么样,因为它把大部分时间花在评估棋盘上了。计算大型神经网络函数耗时是评价优化线性评估函数(an optimized linear evaluation function),比如GNU-Chess,的两倍。」当时,计算机相对于神经网络需求的不足是一个很现实的问题,而且正如我们将要看到的,这不是唯一一个…
神经网络变得呆头呆脑
尽管无监督学习和加强学习很简洁,监督学习仍然是我最喜欢的神经网络应用实例。诚然,学习数据的概率模型很酷,但是,通过反向传播解决实际问题更容易让人兴奋。我们已经看到了Yann Lecun成功解决了识别手写的问题(这一技术继续被全国用来扫描支票,而且后来的使用更多),另一项显而易见且相当重要的任务也在同时进行着:理解人类的语音。
和识别手写一样,理解人类的语音很难,同一个词根据表达的不同,意思也有很多变化。不过,还有额外的挑战:长序列的输入。你看,如果是图片,你就可以把字母从图片中切出来,然后,神经网络就能告诉你这个字母是啥,输入-输出模式。但语言就没那么容易了,把语音拆成字母完全不切实际,就算想要找出语音中的单词也没那么容易。而且你想啊,听到语境中的单词相比单个单词,要好理解一点吧!尽管输入-输出模式用来逐个处理图片相当有效,这并不适用于很长的信息,比如音频或文本。神经网络没有记忆赖以处理一个输入能影响后续的另一个输入的情况,但这恰恰是我们人类处理音频或者文本的方式——输入一串单词或者声音,而不是单独输入。要点是:要解决理解语音的问题,研究人员试图修改神经网络来处理一系列输入(就像语音中的那样)而不是批量输入(像图片中那样)。
Alexander Waibel等人(还有Hinton)提出的解决方法之一,在1989年的「 Phoneme recognition using time-delay neural networks」中得到了介绍。这些时延神经网络和通常意义上的神经网络非常类似,除了每个神经元只处理一个输入子集,而且为不同类型的输入数据延迟配备了几套权重。易言之,针对一系列音频输入,一个音频的「移动窗口」被输入到神经网络,而且随着窗口移动,每个带有几套不同权重的神经元就会根据这段音频在窗口中位置,赋予相应的权重,用这种方法来处理音频。画张图就好理解了:
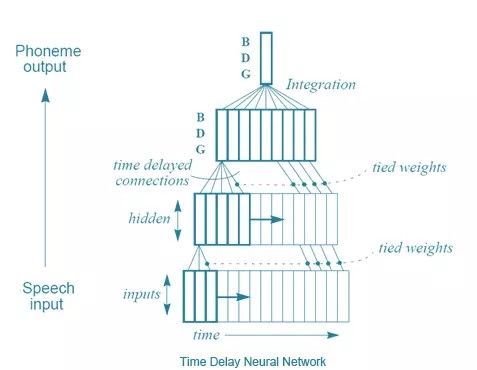
时延神经网络
从某种意义上来说,这和卷积神经网络差不多——每个单元一次只看一个输入子集,对每个小子集进行相同的运算,而不是一次性计算整个集合。不同之处在于,在卷积神经网络中不存在时间概念, 每个神经元的输入窗形成整个输入图像来计算出一个结果,而时延神经网络中有一系列的输入和输出。一个有趣的事实:据Hinton说,时延神经网络的理念启发了LeCun开发卷积神经网络。但是,好笑的是,积卷神经网络变得对图像处理至关重要,而在语音识别方面,时延神经网络则败北于另一种方法——递归神经网络(RNNs)。你看,目前为止讨论过的所有神经网络都是前归网络,这意味着某神经元的输出是下一层神经元的输入。但并不一定要这样,没有什么阻止我们勇敢的计算机科学家将最后一层的输出变成第一层的输入,或者将神经元的输出连接到神经元自身。将神经元回路接回神经网络,赋予神经网络记忆就被优雅地解决了。
递归神经网络图。还记得之前的玻尔兹曼机吗?大吃一惊吧!那些是递归性神经网络。
然而,这可没有那么容易。注意这个问题——如果反向传播需要依赖『正向传播』将输出层的错误反馈回来,那么,如果第一层往回连接到输出层,系统怎么工作?错误会继续传到第一层再传回到输出层,在神经网络中循环往复,无限次地。解决办法是,通过多重群组独立推导,通过时间进行反向传播。基本来说,就是将每个通过神经网络的回路做为另一个神经网络的输入,而且回路次数有限,通过这样的办法把递归神经网络铺开。
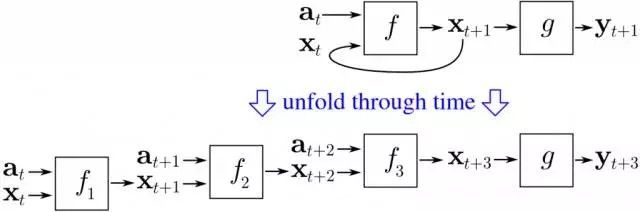
通过时间概念反向传播的直观图解。
这个很简单的想法真的起作用了——训练递归神经网络是可能的。并且,有很多人探索出了RNN在语言识别领域的应用。但是,你可能也听说过其中的波折:这一方法效果并不是很好。为了找出原因,让我们来认识另一位深度学习的巨人:Yoshua Bengion。大约在1986年,他就开始进行语言识别方向的神经网络研究工作,也参与了许多使用ANN和RNN进行语言识别的学术论文,最后进入AT&T BELL实验室工作,Yann LeCun正好也在那里攻克CNN。 实际上,1995年,两位共同发表了文章「Convolutional Networks for Images, Speech, and Time-Series」,这是他们第一次合作,后来他们也进行了许多合作。但是,早在1993年,Bengio曾发表过「A Connectionist Approach to Speech Recognition」。其中,他对有效训练RNN的一般错误进行了归纳:
尽管在许多例子中,递归网络能胜过静态网络,但是,优化训练起来也更有难度。我们的实验倾向于显示(递归神经网络)的参数调整往往收敛在亚优化的解里面,(这种解)只考虑了短效应影响因子而不计长效影响因子。例如,在所述实验中我们发现,RNN根本捕获不到单音素受到的简单时间约束…虽然这是一个消极的结果,但是,更好地理解这一问题可以帮助设计替代系统来训练神经网络,让它学会通过长效影响因子,将输出序列映射到输入序列(map input sequences to output sequences with long term dependencies ),比如,为了学习有限状态机,语法,以及其他语言相关的任务。既然基于梯度的方法显然不足以解决这类问题,我们要考虑其他最优办法,得出可以接受的结论,即使当判别函数(criterion function)并不平滑时。
新的冬日黎明
因此,有一个问题。一个大问题。而且,基本而言,这个问题就是近来的一个巨大成就:反向传播。卷积神经网络在这里起到了非常重要的作用,因为反向传播在有着很多分层的一般神经网络中表现并不好。然而,深度学习的一个关键就是——很多分层,现在的系统大概有20左右的分层。但是,二十世纪八十年代后期,人们就发现,用反向传播来训练深度神经网络效果并不尽如人意,尤其是不如对较少层数的网络训练的结果。原因就是反向传播依赖于将输出层的错误找到并且连续地将错误原因归类到之前的各个分层。然而,在如此大量的层次下,这种数学基础的归咎方法最终产生了不是极大就是极小的结果,被称为『梯度消失或爆炸的问题』,Jurgen Schmidhuber——另一位深度学习的权威,给出了更正式也更深刻的归纳:
一篇学术论文(发表于1991年,作者Hochreiter)曾经对深度学习研究给予了里程碑式的描述。文中第五、第六部分提到:二十世纪九十年代晚期,有些实验表明,前馈或递归深度神经网络是很难用反向传播法进行训练的(见5.5)。Horchreiter在研究中指出了导致问题的一个主要原因:传统的深度神经网络遭遇了梯度消失或爆炸问题。在标准激活状态下(见1),累积的反向传播错误信号不是迅速收缩,就是超出界限。实际上,他们随着层数或CAP深度的增加,以几何数衰减或爆炸(使得对神经网络进行有效训练几乎是不可能的事)。
通过时间顺序扁平化BP路径本质上跟具有许多层的神经网络一样,所以,用反向传播来训练递归神经网络是比较困难的。由Schmidhuber指导的Sepp Hochreiter及Yoshua Bengio都写过文章指出,由于反向传播的限制,学习长时间的信息是行不通的。分析问题以后其实是有解决办法的,Schmidhuber 及 Hochreiter在1997年引进了一个十分重要的概念,这最终解决了如何训练递归神经网络的问题,这就是长短期记忆(Long Short Term Memory, LSTM)。简言之,卷积神经网络及长短期记忆的突破最终只为正常的神经网络模型带来了一些小改动:
LSTM的基本原理十分简单。当中有一些单位被称为恒常误差木马(Constant Error Carousels, CECs)。每个CEC使用一個激活函数 f,它是一个恒常函数,並有一个与其自身的连接,其固定权重为1.0。由於 f 的恒常导数为1.0,通过CEC的误差反向传播将不会消失或爆炸(5.9节),而是保持原状(除非它们从CEC「流出」到其他一些地方,典型的是「流到」神经网络的自适应部分)。CEC被连接到许多非线性自适应单元上(有一些单元具有乘法的激活函数),因此需要学习非线性行为。单元的权重改变经常得益于误差信号在时间里通过CECs往后传播。为什么LSTM网络可以学习探索发生在几千个离散时间步骤前的事件的重要性,而之前的递归神经网络对于很短的时间步骤就已经失败了呢?CEC是最主要的原因。
但这对于解决更大的知觉问题,即神经网络比较粗糙、没有很好的表现这一问题是没有太大帮助的。用它们来工作是十分麻烦的——电脑不够快、算法不够聪明,人们不开心。所以在九十年代左右,对于神经网络一个新的AI寒冬开始来临——社会对它们再次失去信心。一个新的方法,被称为支持向量机(Support Vector Machines),得到发展并且渐渐被发现是优于先前棘手的神经网络。简单的说,支持向量机就是对一个相当于两层的神经网络进行数学上的最优训练。事实上,在1995年,LeCun的一篇论文,「 Comparison of Learning Algorithms For Handwritten Digit Recognition」,就已经讨论了这个新的方法比先前最好的神经网络工作得更好,最起码也表现一样。
支持向量机分类器具有非常棒的准确率,这是最显著的优点,因为与其他高质量的分类器比,它对问题不包含有先验的知识。事实上,如果一个固定的映射被安排到图像的像素上,这个分类器同样会有良好的表现。比起卷积网络,它依然很缓慢,并占用大量内存。但由于技术仍较新,改善是可以预期的。
另外一些新的方法,特别是随机森林(Random Forests),也被证明十分有效,并有强大的数学理论作为后盾。因此,尽管递归神经网络始终有不俗的表现,但对于神经网络的热情逐步减退,机器学习社区再次否认了它们。寒冬再次降临。在第四部分,我们会看到一小批研究者如何在这条坎坷的道路上前行,并最终让深度学习以今天的面貌向大众展现。
深度学习的密谋
当你希望有一场革命的时候,那么,从密谋开始吧。随着支持向量机的上升和反向传播的失败,对于神经网络研究来说,上世纪早期是一段黑暗的时间。Lecun与Hinton各自提到过,那时他们以及他们学生的论文被拒成了家常便饭,因为论文主题是神经网络。上面的引文可能夸张了——当然机器学习与AI的研究仍然十分活跃,其他人,例如Juergen Schmidhuber也正在研究神经网络——但这段时间的引用次数也清楚表明兴奋期已经平缓下来,尽管还没有完全消失。在研究领域之外,他们找到了一个强有力的同盟:加拿大政府。CIFAR的资助鼓励还没有直接应用的基础研究,这项资助首先鼓励Hinton于1987年搬到加拿大,然后一直资助他的研究直到九十年代中期。…Hinton 没有放弃并改变他的方向,而是继续研究神经网络,并努力从CIFAR那里获得更多资助,正如这篇例文(http://www.thestar.com/news/world/2015/04/17/how-a-toronto-professors-research-revolutionized-artificial-intelligence.html)清楚道明的:
「但是,在2004年,Hinton要求领导一项新的有关神经计算的项目。主流机器学习社区对神经网络兴趣寡然。」
「那是最不可能的时候」Bengio是蒙特利尔大学的教授,也是去年重新上马的CIFAR项目联合主管,「其他每个人都在做着不同的事。莫名其妙地,Geoff说服了他们。」
「我们应该为了他们的那场豪赌大力赞许CIFAR。」
CIFAR「对于深度学习的社区形成有着巨大的影响。」LeCun补充道,他是CIFAR项目的另一个联合主管。「我们像是广大机器学习社区的弃儿:无法发表任何文章。这个项目给了我们交流思想的天地。」
资助不算丰厚,但足够让研究员小组继续下去。Hinton和这个小组孕育了一场密谋:用「深度学习」来「重新命名」让人闻之色变的神经网络领域。接下来,每位研究人员肯定都梦想过的事情真的发生了:2006年,Hinton、Simon Osindero与Yee-Whye Teh发表了一篇论文,这被视为一次重要突破,足以重燃人们对神经网络的兴趣:A fast learning algorithm for deep belief nets(论文参见:https://www.cs.toronto.edu/~hinton/absps/fastnc.pdf)。
正如我们将要看到的,尽管这个想法所包含的东西都已经很古老了,「深度学习」的运动完全可以说是由这篇文章所开始。但是比起名称,更重要的是如果权重能够以一种更灵活而非随机的方式进行初始化,有着多层的神经网络就可以得以更好地训练。
「历史上的第一次,神经网络没有好处且不可训练的信念被克服了,并且这是个非常强烈的信念。我的一个朋友在ICML(机器学习国际会议)发表了一篇文章,而就在这不久之前,选稿编辑还说过ICML不应该接受这种文章,因为它是关于神经网络,并不适合ICML。实际上如果你看一下去年的ICML,没有一篇文章的标题有『神经网络』四个字,因此ICML不应该接受神经网络的文章。那还仅仅只是几年前。IEEE期刊真的有『不接收你的文章』的官方准则。所以,这种信念其实非常强烈。」
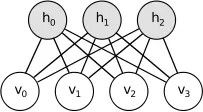
受限的玻尔兹曼机器
那么什么叫做初始化权重的灵活方法呢?实际上,这个主意基本就是利用非监督式训练方式去一个一个训练神经层,比起一开始随机分配值的方法要更好些,之后以监督式学习作为结束。每一层都以受限波尔兹曼机器(RBM)开始,就像上图所显示的隐藏单元和可见单元之间并没有连接的玻尔兹曼机器(如同亥姆霍兹机器),并以非监督模式进行数据生成模式的训练。事实证明这种形式的玻尔兹曼机器能够有效采用2002年Hinton引进的方式「最小化对比发散专家训练产品(Training Products of Experts by Minimizing Contrastive Divergence)」进行训练。
基本上,除去单元生成训练数据的可能,这个算法最大化了某些东西,保证更优拟合,事实证明它做的很好。因此,利用这个方法,这个算法如以下:
利用对比发散训练数据训练RBM。这是信念网络(belief net)的第一层。
生成训练后RBM数据的隐藏值,模拟这些隐藏值训练另一个RBM,这是第二层——将之「堆栈」在第一层之上,仅在一个方向上保持权重直至形成一个信念网络。
根据信念网络需求在多层基础上重复步骤2。
如果需要进行分类,就添加一套隐藏单元,对应分类标志,并改变唤醒-休眠算法「微调」权重。这样非监督式与监督式的组合也经常叫做半监督式学习。
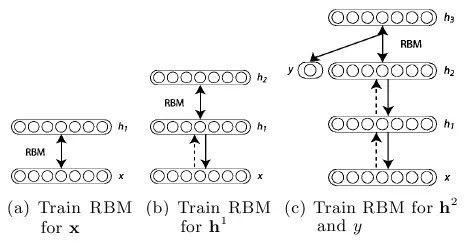
Hinton引入的层式预训练
这篇论文展示了深度信念网络(DBNs)对于标准化MNIST字符识别数据库有着完美的表现,超越了仅有几层的普通神经网络。Yoshua Bengio等在这项工作后于2007年提出了「深层网络冗余式逐层训练( “Greedy Layer-Wise Training of Deep Networks)」,其中他们表达了一个强有力的论点,深度机器学习方法(也就是有着多重处理步骤的方法,或者有着数据等级排列特征显示)在复杂问题上比浅显方法更加有效(双层ANNs或向量支持机器)。
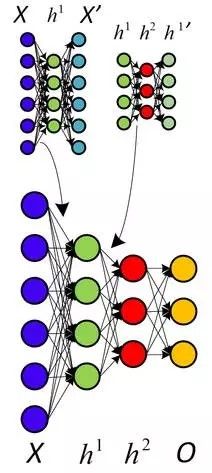
关于非监督式预训练的另一种看法,利用自动代码取代RBM。
他们还提出了为什么附加非监督式预训练,并总结这不仅仅以更优化的方式初始权重,而且更加重要的是导致了更有用的可学习数据显示,让算法可以有更加普遍化的模型。实际上,利用RBM并不是那么重要——普通神经网络层的非监督式预训练利用简单的自动代码层反向传播证明了其有效性。同样的,与此同时,另一种叫做分散编码的方法也表明,非监督式特征学习对于改进监督式学习的性能非常有力。
因此,关键在于有着足够多的显示层,这样优良的高层数据显示能够被学习——与传统的手动设计一些特征提取步骤并以提取到的特征进行机器学习方式完全不同。Hinton与Bengio的工作有着实践上的证明,但是更重要的是,展示了深层神经网络并不能被训练好的假设是错误的。LeCun已经在整个九十年代证明了CNN,但是大部分研究团体却拒绝接受。Bengio与Yann LeCun一起,在「实现AI的算法(Scaling Algorithms Towards AI)」研究之上证明了他们自己:
「直至最近,许多人相信训练深层架构是一个太过困难的优化问题。然而,至少有两个不同的方法对此都很有效:应用于卷积神经网络的简单梯度下降[LeCun et al., 1989, LeCun et al., 1998](适用于信号和图像),以及近期的逐层非监督式学习之后的梯度下降[Hinton et al., 2006, Bengio et al., 2007, Ranzato et al., 2006]。深层架构的研究仍然处于雏形之中,更好的学习算法还有待发现。从更广泛的观点来看待以发现能够引出AI的学习准则为目标这事已经成为指导性观念。我们希望能够激发他人去寻找实现AI的机器学习方法。」
他们的确做到了。或者至少,他们开始了。尽管深度学习还没有达到今天山呼海应的效果,它已经如冰面下的潜流,不容忽视地开始了涌动。那个时候的成果还不那么引人注意——大部分论文中证明的表现都限于MNIST数据库,一个经典的机器学习任务,成为了十年间算法的标准化基准。Hinton在2006年发布的论文展现出惊人的错误率,在测试集上仅有1.25%的错误率,但SVMs已经达到了仅1.4%的错误率,甚至简单的算法在个位数上也能达到较低的错误率,正如在论文中所提到的,LeCun已经在1998年利用CNNs表现出0.95%的错误率。
因此,在MNIST上做得很好并不是什么大事。意识到这一点,并自信这就是深度学习踏上舞台的时刻的Hinton与他的两个研究生,Abdel-rahman Mohamed和George Dahl,展现了他们在一个更具有挑战性的任务上的努力:语音识别( Speech Recognition)。
利用DBN,这两个学生与Hinton做到了一件事,那就是改善了十年间都没有进步的标准语音识别数据集。这是一个了不起的成就,但是现在回首来看,那只是暗示着即将到来的未来——简而言之,就是打破更多的记录。
蛮力的重要性
上面所描述的算法对于深度学习的出现有着不容置疑的重要性,但是自上世纪九十年代开始,也有着其他重要组成部分陆续出现:纯粹的计算速度。随着摩尔定律,计算机比起九十年代快了数十倍,让大型数据集和多层的学习更加易于处理。但是甚至这也不够——CPU开始抵达速度增长的上限,计算机能力开始主要通过数个CPU并行计算增长。为了学习深度模型中常有的数百万个权重值,脆弱的CPU并行限制需要被抛弃,并被具有大型并行计算能力的GPUs所代替。意识到这一点也是Abdel-rahman Mohamed,George Dahl与Geoff Hinton做到打破语音识别性能记录的部分原因:
「由Hinton的深度神经网络课堂之一所激发,Mohamed开始将它们应用于语音——但是深度神经网络需要巨大的计算能力,传统计算机显然达不到——因此Hinton与Mohamed招募了Dahl。Dahl是Hinton实验室的学生,他发现了如何利用相同的高端显卡(让栩栩如生的计算机游戏能够显示在私人计算机上)有效训练并模拟神经网络。」
「他们用相同的方法去解决时长过短的语音中片段的音素识别问题,」Hinton说道,「对比于之前标准化三小时基准的方法,他们有了更好的成果。」
在这个案例中利用GPU而不是CPU到底能变得有多快很难说清楚,但是同年《Large-scale Deep Unsupervised Learning using Graphics Processors》这篇论文给出了一个数字:70倍。是的,70倍,这使得数以周记的工作可以被压缩到几天就完成,甚至是一天。之前研发了分散式代码的作者中包括高产的机器学习研究者吴恩达,他逐渐意识到利用大量训练数据与快速计算的能力在之前被赞同学习算法演变愈烈的研究员们低估了。这个想法在2010年的《Deep Big Simple Neural Nets Excel on Handwritten Digit Recognition》(作者之一J. Schimidhuber正是递归LTSM网络(recurrent LTSM networks)的投资者)中也得到了大力支持,展示了MNIST数据库能够达到令人惊叹的0.35%错误率,并且除去大型神经网络、输入的多个变量、以及有效的反向传播GPU实现以外没有任何特殊的地方。这些想法已经存在了数十年,因此尽管可以说算法的改进并不那么重要,但是结果确实强烈表明大型训练数据集与快速腭化计算的蛮力方法是一个关键。
Dahl与Mohamed利用GPU打破记录是一个早期且相对有限的成功,但是它足以激励人们,并且对这两人来说也为他们带来了在微软研究室实习的机会。在这里,他们可以享受到那时已经出现的计算领域内另一个趋势所带来的益处:大数据。这个词语定义宽松,在机器学习的环境下则很容易理解——大量训练数据。大量的训练数据非常重要,因为没有它神经网络仍然不能做到很好——它们有些过拟合了(完美适用于训练数据,但无法推广到新的测试数据)。这说得通——大型神经网络能够计算的复杂度需要许多数据来使它们避免学习训练集中那些不重要的方面——这也是过去研究者面对的主要难题。因此现在,大型公司的计算与数据集合能力证明了其不可替代性。这两个学生在三个月的实习期中轻易地证明了深度学习的能力,微软研究室也自此成为了深度学习语音识别研究的前沿地带。
微软不是唯一一个意识到深度学习力量的大公司(尽管起初它很灵巧)。Navdeep Jaitly是Hinton的另一个学生,2011年曾在谷歌当过暑假实习生。他致力于谷歌的语音识别项目,通过结合深度学习能够让他们现存的设备大大提高。修正后的方法不久就加强了安卓的语音识别技术,替代了许多之前的解决方案。
除了博士实习生给大公司的产品带来的深刻影响之外,这里最著名的是两家公司都在用相同的方法——这方法对所有使用它的人都是开放的。实际上,微软和谷歌的工作成果,以及IBM和Hinton实验室的工作成果,在2012 年发布了令人印象深刻的名为「深层神经网络语音识别的声学建模:分享四个研究小组的观点」的文章。
这四个研究小组——有三个是来自企业,确定能从伤脑筋的深度学习这一新兴技术专利中获益,而大学研究小组推广了技术——共同努力并将他们的成果发布给更广泛的研究社区。如果有什么理想的场景让行业接受研究中的观念,似乎就是这一刻了。
这并不是说公司这么做是为了慈善。这是他们所有人探索如何把技术商业化的开始,其中最为突出的是谷歌。但是也许并非Hinton,而是吴恩达造成了这一切,他促使公司成为世界最大的商业化采用者和技术用户者。在2011年,吴恩达在巡视公司时偶遇到了传说中的谷歌人Jeff Dean,聊了一些他用谷歌的计算资源来训练神经网络所做的努力。
这使Dean着迷,于是与吴恩达一起创建了谷歌大脑(Google Brain)——努力构建真正巨大的神经网络并且探索它们能做什么。这项工作引发了一个规模前所未有的无监督式神经网络学习——16000个CPU核,驱动高达10亿权重的学习(作为比较,Hinton在2006年突破性的DBN大约有100万权重)。神经网络在YouTube视频上被训练,完全无标记,并且学着在这些视频中去辨认最平常的物体——而神经网络对于猫的发现,引起了互联网的集体欢乐。

谷歌最著名的神经网络学习猫。这是输入到一个神经元中最佳的一张。
它很可爱,也很有用。正如他们常规发表的一篇论文中所报道的,由模型学习的特征能用来记录标准的计算机视觉基准的设置性能。
这样一来,谷歌训练大规模的神经网络的内部工具诞生了,自此他们仅需继续发展它。深度学习研究的浪潮始于2006年,现在已经确定进入行业使用。
深度学习的上升
当深度学习进入行业使用时,研究社区很难保持平静。有效的利用GPU和计算能力的发现是如此重要,它让人们检查长久存疑的假设并且问一些也许很久之前被提及过的问题——也就是,反向传播到底为何没什么用呢?为什么旧的方法不起作用,而不是新的方法能奏效,这样的问题观点让Xavier Glort 和 Yoshua Bengio在2010年写了「理解训练深度前馈神经网络的难点」(Understanding the difficulty of training deep feedforward neural networks)一文。
在文中,他们讨论了两个有重大意义的发现:
为神经网络中神经元选取的特定非线性激活函数,对性能有巨大影响,而默认使用的函数不是最好的选择。
相对于随机选取权重,不考虑神经层的权重就随机选取权重的问题要大得多。以往消失的梯度问题重现,根本上,由于反向传播引入一系列乘法,不可避免地导致给前面的神经层带来细微的偏差。就是这样,除非依据所在的神经层不同分别选取不同的权重 ——否则很小的变化会引起结果巨大变化。
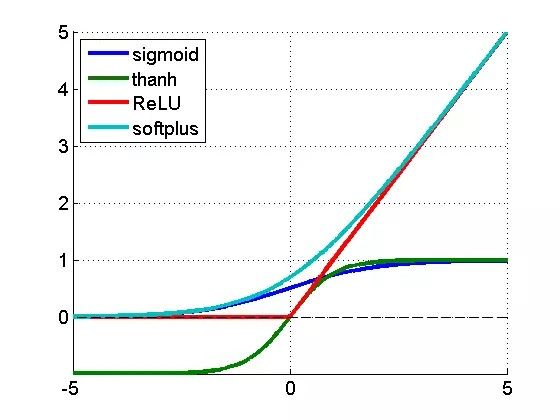
不同的激活函数。ReLU是**修正线性单元**
第二点的结论已经很清楚了,但是第一点提出了这样的问题:『然而,什么是最好的激活函数?』有三个不同的团队研究了这个问题:LeCun所在的团队,他们研究的是「针对对象识别最好的多级结构是什么?」;另一组是Hinton所在的团队,研究「修正的线性单元改善受限玻尔兹曼机器」;第三组是Bengio所在的团队——「深度稀缺的修正神经网络」。他们都发现惊人的相似结论:近乎不可微的、十分简单的函数f(x)=max(0,x)似乎是最好的。令人吃惊的是,这个函数有点古怪——它不是严格可微的,确切地说,在零点不可微,因此 就 数学而言论文看起来很糟糕。但是,清楚的是零点是很小的数学问题——更严重的问题是为什么这样一个零点两侧导数都是常数的简单函数,这么好用。答案还未揭晓,但一些想法看起来已经成型:
修正的激活导致了表征稀疏,这意味着在给定输入时,很多神经元实际上最终需要输出非零值。这些年的结论是,稀疏对深度学习十分有利,一方面是由于它用更具鲁棒性的方式表征信息,另一方面由于它带来极高的计算效率(如果大多数的神经元在输出零,实际上就可以忽略它们,计算也就更快)。顺便提一句,计算神经科学的研究者首次在大脑视觉系统中引入稀疏计算,比机器学习的研究早了10年。
相比指数函数或者三角函数,简单的函数及其导数,使它能非常快地工作。当使用GPU时,这就不仅仅是一个很小的改善,而是十分重要,因为这能规模化神经网络以很好地完成极具挑战的问题。
后来吴恩达联合发表的「修正的非线性改善神经网络的语音模型 」(Rectifier Nonlinearities Improve Neural Network Acoustic Models)一文,也证明了ReLU导数为常数0或1对学习并无害处。实际上,它有助于避免梯度消失的问题,而这正是反向传播的祸根。此外,除了生成更稀疏的表征,它还能生成更发散的表征——这样就可以结合多个神经元的多重值,而不局限于从单个神经元中获取有意义的结论。
目前,结合2006年以来的这些发现,很清楚的是非监督预训练对深度学习来说不是必要的。虽然,它的确有帮助,但是在某些情况下也表明,纯粹的监督学习(有正确的初始权重规模和激活函数)能超越含非监督训练的学习方式。那么,到底为什么基于反向传播的纯监督学习在过去表现不佳?Geoffrey Hinton总结了目前发现的四个方面问题:
带标签的数据集很小,只有现在的千分之一.
计算性能很慢,只有现在的百万分之一.
权重的初始化方式笨拙.
使用了错误的非线性模型。
好了,就到这里了。深度学习。数十年研究的积累,总结成一个公式就是:
深度学习=许多训练数据+并行计算+规模化、灵巧的的算法

我希望我是第一个提出这个赏心悦目的方程的,但是看起来有人走在我前面了。
更不要说这里就是希望弄清楚这点。差远了!被想通的东西刚好是相反的:人们的直觉经常出错,尤其是一些看似没有问题的决定及假设通常都是没有根据的。问简单的问题,尝试简单的东西——这些对于改善最新的技术有很大的帮助。其实这一直都在发生,我们看到更多的想法及方法在深度学习领域中被发掘、被分享。例如 G. E. Hinton等的「透过预防特征检测器的互相适应改善神经网络」( Improving neural networks by preventing co-adaptation of feature detectors)。
其构思很简单:为了避免过度拟合,我们可以随机假装在训练当中有些神经元并不在那儿。想法虽然非常简单——被称为丢弃法(dropout)——但对于实施非常强大的集成学习方法又非常有效,这意味着我们可以在训练数据中实行多种不同的学习方法。随机森林——一种在当今机器学习领域中占主导地位的方法——主要就是得益于集成学习而非常有效。训练多个不同的神经网络是可能的,但它在计算上过于昂贵,而这个简单的想法在本质上也可取得相同的结果,而且性能也可有显著提高。
然而,自2006年以来的所有这些研究发现都不是促使计算机视觉及其他研究机构再次尊重神经网络的原因。这个原因远没有看来的高尚:在现代竞争的基准上完全摧毁其他非深度学习的方法。Geoffrey Hinton召集与他共同写丢弃法的两位作家,Alex Krizhevsky 与 Ilya Sutskever,将他们所发现的想法在ILSVRC-2012计算机视觉比赛中创建了一个条目。
对于我来说,了解他们的工作是非常惊人的,他们的「使用深度卷积神经网络在ImageNet上分类」(ImageNet Classification with deep convolutional neural networks)一文其实就是将一些很旧的概念(例如卷积神经网络的池化及卷积层,输入数据的变化)与一些新的关键观点(例如十分高性能的GPU、ReLU神经元、丢弃法等)重新组合,而这点,正是这一点,就是现代深度网络的所有深意了。但他们如何做到的呢?
远比下一个最近的条目好:它们的误差率是15.3%,第二个最近的是26.2%。在这点上——第一个及唯一一个在比赛中的CNN条目——对于CNNs及深度学习整体来说是一个无可争议的标志,对于计算机视觉,它应该被认真对待。如今,几乎所有的比赛条目都是CNNs——这就是Yann LeCun自1989年以来在上面花费大量心血的神经网络模型。还记得上世纪90年代由Sepp Hochreiter 及 Jürgen Schmidhuber为了解决反向传播问题而开发的LSTM循环神经网络吗?这些在现在也是最新的连续任务比如语音处理的处理方法。
这就是转折点。一波对于其可能发展的狂欢在其无可否认的成绩中达到了高潮,这远远超过了其他已知方法所能处理的。这就是我们在第一部分开头所描写的山呼海应比喻的起点,而且它到如今还一直在增长,强化。深度学习就在这儿,我们看不到寒冬。
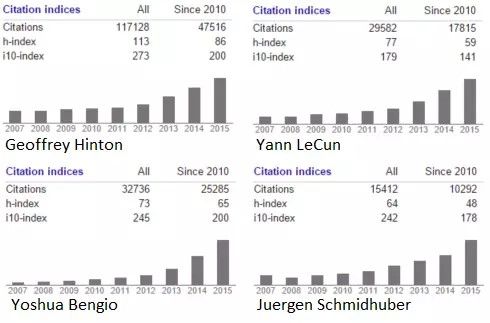
我们列举了对深度学习的发展做出重要贡献的人物。我相信我不需要再指出自从2012年以来其飞涨的趋势了。
后记:现状
如果这是一部电影,2012年ImageNet比赛将是其高潮,而现在在电影结束的时候,我们将会出现这几个字:「他们如今在哪里」。Yann Lecun:Facebook; Geoffrey Hinton: 谷歌; 吴恩达: Coursera、谷歌、百度; Bengi、Schmidhuber 及 Hochreiter 依然还留在学术界——但我们可以很容易推测,这个领域将会有更多的引用及毕业生。
虽然深度学习的理念及成绩令人振奋,但当我在写这几篇文章的时候,我也不由自主地被他们所感动,他们在一个几乎被人遗弃的领域里深耕数十年,他们现在富裕、成功,但重要的是他们如今更确信自己的研究。这些人的思想依然保持开放,而这些大公司也一直在开源他们的深度学习模型,犹如一个由工业界领导研究界的理想国。多美好的故事啊啊。
我愚蠢的以为我可以在这一部分写一个过去几年让人印象深刻的成果总结,但在此,我清楚知道我已经没有足够的空间来写这些。可能有一天我会继续写第五部分,那就可以完成这个故事了。但现在,让我提供以下一个简短的清单:
1.LTSM RNNs的死灰复燃以及分布式表征的代表

去年的结果。看看吧!
2.利用深度学习来加强学习
3.附加外部可读写存储