李宏毅老师《机器学习》课程笔记-1深度学习简介
注:本文是我学习李宏毅老师《机器学习》课程 2021/2022 的笔记(课程网站 ),文中图片来自课程 PPT。欢迎交流和多多指教,谢谢!
Lecture 1 Introduction of Deep Learning
Machine Learning ≈ Looking for Function
我的理解:机器学习要找到输入和输出之间的关系,也可以理解为映射关系,建模也就是找到合适的(映射)函数。
本课程主要关注 深度学习 ,即 Function 是 Neural Network (神经网络) 的情况。
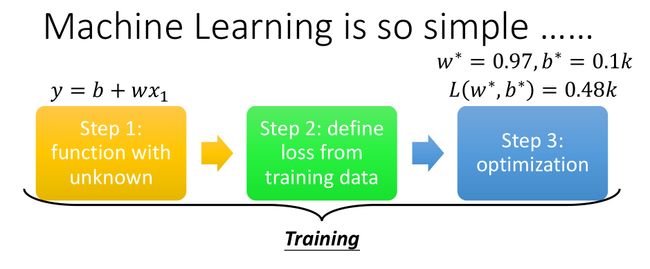
1. 机器学习三要素
1.选择一个 模型 ( model / function )。注意,模型包含一些未知参数 ( unknown parameters ) ,这些参数要根据训练集的输入、输出数据拟合得到,例如下图中线性模型的参数 w w w 和 b b b 。
2.确定模型的 评价标准 ( loss function ) ,也就是评价模型的估计效果,比如,模型估计的值是否接近真实值。
3.选择 优化算法 ( optimization ),就是快速找到最优参数的方法,就像编程里的算法一样。
确定这三个之后,就可以开始训练 ( training ) 了!看起来 so simple 有没有?(其实不然哈哈哈)
2.模型:线性–>非线性
线性模型对于复杂一点的曲线就无法拟合,那有没有别的模型呢?
有,比如说,我们可以把许多段折线“拼接”成一段复杂的曲线。例如,下图例子中红色的曲线可以用三段折线拼接得到:

由此推广:更复杂的曲线,也可以这样分段 ( piece-wise ) 拟合,只需要用更多的折线段。这里,sigmoid 函数起到了分段的作用,也是 把线性转换为非线性的重要单元 。 i i i 的个数就是折线段的数量,也就是说,把曲线分成几段拟合。
以下为从1个输入特征到多个输入特征时,输出 y y y 的表达式变化。注意: i i i 标识了折线段的数量, j j j 标识了输入特征的数量。

以下为模型结构示意图,我在图中做了一点标记。虽然看上去复杂,但是,我们可以把模型看成是由线性单元–>非线性单元–>线性单元组合而成。

那么,其中有哪些是未知参数呢?请看下图:

3. 评价标准(loss function)
用于估计给定一组参数时,模型估计得到的目标值与真实值之间的差距。例如:MSE, MAE, Cross-entropy。
4. 优化算法(optimization)
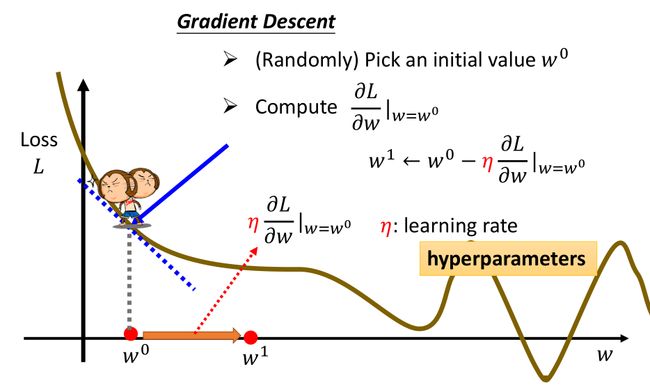
常用的一种方法:Gradient Descent(梯度下降法),以线性模型中对 w w w 的求解为例,如下图所示,L 表示 loss function。沿着梯度下降的方向改变 w w w,希望最终使 L 最小。改变参数 w w w 时,有时候希望步子迈大一点,这样引起的 L 变动大一点,有时候又希望小一点,这可以用图中公式里的 learning rate (学习率) η \eta η 调节。 η \eta η 是我们人为设定的,所以叫 hyperparameter。(比如你写代码训练模型时,在训练前可以自己设定的参数,如学习率 η \eta η,分组大小 batch size 等,是 hyperparameters。而由程序运算自动求解的模型参数,是 parameters。)
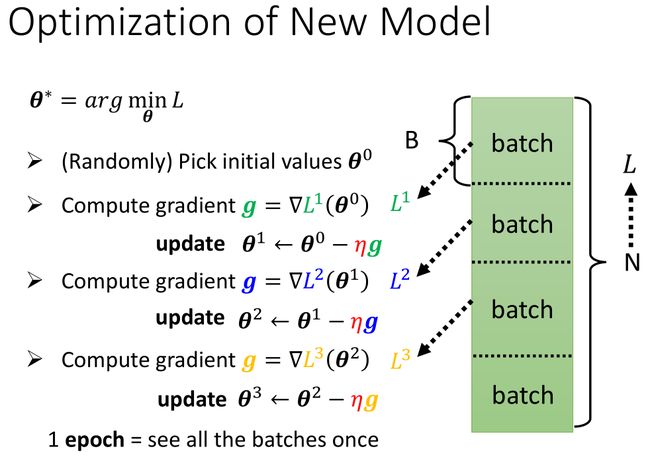
理论上说,Gradient Descent(梯度下降法)每一次计算 gradient 时,loss function 由所有的训练数据计算得到。当训练集数据量很大时,这样的计算很耗时,有没有更快一点的办法呢?
可以每次取一部分数据计算。如下图所示,把数据划分成一个个相同大小的 batch(分组)。
第 1 次:用第 1 个 batch 计算 L 和 gradient,更新参数 ( update );
第 2 次:用第 2 个 batch 计算 L 和 gradient,更新参数;
依此顺序进行更新,直到所有 batches 的数据看过一遍,这个过程就是 1个 epoch。
一般会把数据先打乱 (shuffle),再分组,我感觉这就有了采样的效果,相当于每次随机取了一部分数据用于计算更新参数。batch 的大小决定了 1 个epoch 中的更新参数 ( update ) 次数。
- batch-size 小,则 batches 的数量多,1 个 epoch 中 update 次数多。特别地,当 batch-size=1 时,每一个点都 update 1 次,1 个epoch 要 update N 次。
- 反之,batch-size 大,1 个 epoch 中 update 次数少。特别地,当 batch-size=N 时,也就是使用了全部数据、未分组的情况,1个 epoch 只 update 1 次。
5. Deep Learning
前面介绍的是一种简单的模型结构,我们还可以把 sigmoid 函数(也就是非线性单元)的输出,当成新的输入,再次经过一个相似的结构,如下图所示。此时,除了输入层和输出层之外,中间还有若干层网络结构,就称为 hidden layer(隐藏层)。因为类似于人脑神经结构,这个网络结构整体被称为 Neural Network。

深度学习 ( Deep Learning ) 为什么叫 Deep?就是因为有很多层 hidden layers,模型纵深发展。
思考:Why we want “Deep” network? not “Fat” network? 理论上说,只要折线段的数量无限多,是可以拟合任何曲线,也就是 sigmoid 函数的个数 i i i 取很大的值,这样的模型结构就是 “Fat” network。为什么要用 ”Deep“ 而不是 “Fat” Network 呢?
(想要知道原因,可以看这篇笔记:为什么是“深度”学习?)
听课收获
1.机器学习的三要素:model/function, loss, optimization,做作业时也有体会,每次训练之前,都要先定义这三项。
2.课程中介绍神经网络是从折线拟合的角度出发,这个角度很新颖,和我之前看的教程中从神经细胞结构(树突、轴突)出发不同。无论多么复杂的曲线,总可以通过许多的小折线拟合。
但是这种无限近似拟合法也可能存在过拟合的问题,因为我们是要寻找规律,而不是细节。当折线段的数量很多时(也就是一层有很多个神经元结构),就开始拟合细节或者说数据的抖动了,这是否就是 “Fat” Network 的弱点?
本文对您有帮助的话,请点赞支持一下吧,谢谢!
关注我 宁萌Julie,互相学习,多多交流呀!
阅读更多笔记,请点击 李宏毅老师《机器学习》笔记–合辑目录。
参考
李宏毅老师《机器学习 2022》:
课程网站:https://speech.ee.ntu.edu.tw/~hylee/ml/2022-spring.php
视频:https://www.bilibili.com/video/BV1Wv411h7kN