【菜菜的sklearn课堂笔记】数据预处理和特征工程-特征选择-Wrapper包装法
视频作者:菜菜TsaiTsai
链接:【技术干货】菜菜的机器学习sklearn【全85集】Python进阶_哔哩哔哩_bilibili
包装法也是一个特征选择和算法训练同时进行的方法,与嵌入法十分相似,它也是依赖于算法自身的选择,比如coef_属性或feature_importances_属性来完成特征选择。但不同的是,我们往往使用一个目标函数作为黑盒来帮助我们选取特征,而不是自己输入某个评估指标或统计量的阈值。
包装法在初始特征集上训练评估器,并且通过coef_属性或通过feature_importances_属性获得每个特征的重要性。然后,从当前的一组特征中修剪最不重要的特征。在修剪的集合上递归地重复该过程,直到最终到达所需数量的要选择的特征。
区别于过滤法和嵌入法的一次训练解决所有问题,包装法要使用特征子集进行多次训练,因此它所需要的计算成本是最高的。
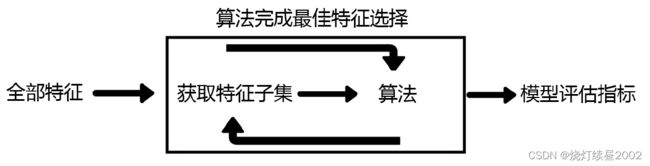
注意,在这个图中的“算法”,指的不是我们最终用来导入数据的分类或回归算法(即不是随机森林),而是专业的数据挖掘算法,即我们的目标函数。这些数据挖掘算法的核心功能就是选取最佳特征子集。
最典型的目标函数是递归特征消除法(Recursive feature elimination, 简写为RFE)。它是一种贪婪的优化算法,旨在找到性能最佳的特征子集。 它反复创建模型,并在每次迭代时保留最佳特征或剔除最差特征,下一次迭代时,它会使用上一次建模中没有被选中的特征来构建下一个模型,直到所有特征都耗尽为止。 然后,它根据自己保留或剔除特征的顺序来对特征进行排名,最终选出一个最佳子集。
包装法的效果是所有特征选择方法中最利于提升模型表现的,它可以使用很少的特征达到很优秀的效果。相比之下,包装法是最能保证模型效果的特征选择方法。
在特征数目相同时,包装法和嵌入法的效果能够匹敌,不过它比嵌入法算得更加缓慢,所以也不适用于太大型的数据。
RFE(estimator, n_features_to_select=None, step=1, verbose=0)
# estimator:实例化的模型
# n_features_to_select:想要选择的特征个数
# step:每次迭代中希望移除的特征个数
# 除此之外,RFE类有两个很重要的属性
# .support_:返回所有的特征的是否最后被选中的布尔array,选中的为True未选中为False
# .ranking_返回特征的按数次迭代中综合重要性的排名。排名也靠后的特征在迭代中越先被删除,对模型的贡献越小。.ranking为1的特征数量由n_features_to_select决定,也就是最终被选中的特征;.ranking为3-n的特征数量由step决定,n为迭代次数-1,;.ranking为2的特征数量为了保证.ranking为1的特征数量=n_features_to_select,因此可能会小于step的值
# 类feature_selection.RFECV会在交叉验证循环中执行RFE以找到最佳数量的特征,增加参数cv,其他用法都和RFE一模一样。
from sklearn.feature_selection import RFE
RFC_ = RFC(n_estimators=10,random_state=0)
selector = RFE(RFC_,n_features_to_select=340,step=50).fit(X,y)
len(selector.support_) # 返回所有特征的
---
784
selector.support_.sum()
---
340
len(selector.ranking_) # 返回所有特征的
---
784
(selector.ranking_ == 1).sum()
---
340
X_warpper = selector.transform(X)
cross_val_score(RFC_,X_warpper,y,cv=5).mean()
# 包装法和嵌入法谁好不是绝对的
---
0.9389522459432109
cross_val_score(RFC(n_estimators=100,random_state=0),X_warpper,y,cv=5).mean()
---
0.9637148832441458
到最后已经很接近嵌入法得到的0.9639525817795566
我们也可以对包装法画学习曲线:
score = []
for i in range(1,751,50):
X_wrapper = RFE(RFC_,n_features_to_select=i, step=50).fit_transform(X,y)
once = cross_val_score(RFC_,X_wrapper,y,cv=5).mean()
score.append(once)
plt.figure(figsize=[20,5])
plt.plot(range(1,751,50),score)
plt.xticks(range(1,751,50))
plt.show()

明显能够看出,在包装法下面,应用50个特征时,模型的表现就已经达到了90%以上,比嵌入法和过滤法都高效很多。
我们可以放大图像,寻找模型变得非常稳定的点来画进一步的学习曲线(就像我们在嵌入法中做的那样)。如果我们此时追求的是最大化降低模型的运行时间,我们甚至可以直接选择50作为特征的数目,这是一个在缩减了94%的特征的基础上,还能保证模型表现在90%以上的特征组合,不可谓不高效。
由于包装法效果和嵌入法相差不多,在更小的范围内使用学习曲线,我们也可以将包装法的效果调得很好
特征选择总结
至此,我们讲完了降维之外的所有特征选择的方法。每种方法的原理都不同,并且都涉及到不同调整方法的超参数。
经验来说,过滤法更快速,但更粗糙。包装法和嵌入法更精确,比较适合具体到算法去调整,但计算量比较大,运行时间长。当数据量很大的时候,优先使用方差过滤和互信息法调整,再上其他特征选择方法。
使用逻辑回归时,优先使用嵌入法。使用支持向量机时,优先使用包装法。迷茫的时候,从过滤法走起,看具体数据具体分析。
其实特征选择只是特征工程中的第一步。真正的高手,往往使用特征创造或特征提取来寻找高级特征。